
Lucene in action-08-sort 排序
排序
很多使用 Lucene 米实现搜索功能的应用程序都可以利用第三章中介绍的 API 来完成。
但是有些项目单靠前面介绍的基本搜索机制仍然无法实现其功能。
因此在本章中,我们将进一步介绍 Lucene 中更多更为复杂的内置搜索功能。
PhrasePrefixQuery 和 MultiFieldQueryParser这两个类为我们引出了本章要介绍的Lucene 附加的内置功能。
如果你使用 Lucene 的时间不长,就可能对这些特性的理解不够透彻。排序、跨度查询和项向量都是 Lucene1.4中引入的新特性,它们在很大程度上增强了 Lucene 的功能及其灵活性。
5.1 对搜索结果进行排序
在Lucene1.4之前,返回的搜索结果都是按照得分递减的顺序排列的,这样的排列顺序确保了将相关度最大的文档排在最前。假设我们要为一个名为 BookScene 的虚拟书店开发一个应用程序,要求它能够对搜索结果分类显示,并且在同一分类中的各种书籍要根据查询相关度进行排序。
要实现这个功能,可以在 Lucene 的外部附加一段对搜索结果进行搜集和分类的程序:但当结果的数目相当庞大时,这样的实现方法可能会成为制约应用程序性能的瓶颈。
不过值得庆幸的是,开发专家 Tim Jones 已经对 Lucene 做了有效的补充,他为 Lucene 加入了成熟且完善的搜索结果排序功能。
在本节中,我们将尝试用各种方法对搜索结果进行排序,例如使用一个或多个域的值对结果按升序或降序进行排列。
5.1.1 使用排序方法
IndexSearcher 类包含了几个可重载的 search 方法。
到目前为止,我们只讲述了基本的 search(Query)方法,它返回的是按相关性降序排列的结果。能够对结果排序的 search方法声明为 search(Query, Sort)。
程序5.1为我们示范了如何使用这个 search 方法对结果进行排序。
displayHits 方法使用 search(Query, Sort)方法并将命中的 Hits 对象显示出来。
下面的例子通过 displayHits 方法来说明不同排序方法的运行结果。
数据写入
public void createIndexTest() throws IOException {
final String indexDir = "index/chap05";
//1. 构建 writer
Directory directory = FSDirectory.open(Paths.get(indexDir));
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig iwConfig = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, iwConfig);
//2. 写入 document
List contentList = Arrays.asList("The quick brown fox jumped over the lazy dogs", "go with lucene", "go with java");
int id = 0;
for(String text : contentList) {
id++;
Document document = new Document();
document.add(new StringField("id", id+"", Field.Store.YES));
document.add(new TextField("content", text, Field.Store.YES));
indexWriter.addDocument(document);
}
//3. 关闭属性
indexWriter.commit();
indexWriter.close();
}数据排序查询
public void sortSearcherTest() throws IOException {
final String indexDir = "index/chap05";
//1. 构建 writer
// 得到读取索引文件的路径
Directory dir = FSDirectory.open(Paths.get(indexDir));
// 通过dir得到的路径下的所有的文件
IndexReader reader = DirectoryReader.open(dir);
// 建立索引查询器
IndexSearcher indexSearcher = new IndexSearcher(reader);
// 查询
Term term = new Term("content", "go");
Query query = new TermQuery(term);
// 指定排序策略
TopDocs hits = indexSearcher.search(query, 5, Sort.INDEXORDER);
// 结果展现
for (ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = indexSearcher.doc(scoreDoc.doc);
System.out.println(doc.get("content"));
System.out.println(indexSearcher.explain(query, scoreDoc.doc));
}
}日志:
go with lucene
0.5773649 = weight(content:go in 1) [BM25Similarity], result of:
0.5773649 = score(doc=1,freq=1.0 = termFreq=1.0
), product of:
0.47000363 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:
2.0 = docFreq
3.0 = docCount
1.2284265 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:
1.0 = termFreq=1.0
1.2 = parameter k1
0.75 = parameter b
3.6666667 = avgFieldLength
2.0 = fieldLength
go with java
0.5773649 = weight(content:go in 2) [BM25Similarity], result of:
0.5773649 = score(doc=2,freq=1.0 = termFreq=1.0
), product of:
0.47000363 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:
2.0 = docFreq
3.0 = docCount
1.2284265 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:
1.0 = termFreq=1.0
1.2 = parameter k1
0.75 = parameter b
3.6666667 = avgFieldLength
2.0 = fieldLengthSort 源码浅析
public class Sort {
/**
* Represents sorting by computed relevance. Using this sort criteria returns
* the same results as calling
* {@link IndexSearcher#search(Query,int) IndexSearcher#search()}without a sort criteria,
* only with slightly more overhead.
*/
public static final Sort RELEVANCE = new Sort();
/** Represents sorting by index order. */
public static final Sort INDEXORDER = new Sort(SortField.FIELD_DOC);
// internal representation of the sort criteria
SortField[] fields;
/**
* Sorts by computed relevance. This is the same sort criteria as calling
* {@link IndexSearcher#search(Query,int) IndexSearcher#search()}without a sort criteria,
* only with slightly more overhead.
*/
public Sort() {
this(SortField.FIELD_SCORE);
}
/** Sorts by the criteria in the given SortField. */
public Sort(SortField field) {
setSort(field);
}
/** Sets the sort to the given criteria in succession: the
* first SortField is checked first, but if it produces a
* tie, then the second SortField is used to break the tie,
* etc. Finally, if there is still a tie after all SortFields
* are checked, the internal Lucene docid is used to break it. */
public Sort(SortField... fields) {
setSort(fields);
}
/** Sets the sort to the given criteria. */
public void setSort(SortField field) {
this.fields = new SortField[] { field };
}
/** Sets the sort to the given criteria in succession: the
* first SortField is checked first, but if it produces a
* tie, then the second SortField is used to break the tie,
* etc. Finally, if there is still a tie after all SortFields
* are checked, the internal Lucene docid is used to break it. */
public void setSort(SortField... fields) {
if (fields.length == 0) {
throw new IllegalArgumentException("There must be at least 1 sort field");
}
this.fields = fields;
}
/**
* Representation of the sort criteria.
* @return Array of SortField objects used in this sort criteria
*/
public SortField[] getSort() {
return fields;
}
/**
* Rewrites the SortFields in this Sort, returning a new Sort if any of the fields
* changes during their rewriting.
*
* @param searcher IndexSearcher to use in the rewriting
* @return {@code this} if the Sort/Fields have not changed, or a new Sort if there
* is a change
* @throws IOException Can be thrown by the rewriting
* @lucene.experimental
*/
public Sort rewrite(IndexSearcher searcher) throws IOException {
boolean changed = false;
SortField[] rewrittenSortFields = new SortField[fields.length];
for (int i = 0; i
* If x fields are specified, this effectively constructs:
*
*
* (field1:query1) (field2:query2) (field3:query3)...(fieldx:queryx)
*
*
* @param queries Queries strings to parse
* @param fields Fields to search on
* @param analyzer Analyzer to use
* @throws ParseException if query parsing fails
* @throws IllegalArgumentException if the length of the queries array differs
* from the length of the fields array
*/
public static Query parse(String[] queries, String[] fields, Analyzer analyzer) throws ParseException {一个字段和一个查询对应。
当然,我们也可以查询多个 field,指定相同的查询条件。比如下面的方法:
/**
* Parses a query, searching on the fields specified.
* Use this if you need to specify certain fields as required,
* and others as prohibited.
*
* Usage:
*
*
* String[] fields = {"filename", "contents", "description"};
* BooleanClause.Occur[] flags = {BooleanClause.Occur.SHOULD,
* BooleanClause.Occur.MUST,
* BooleanClause.Occur.MUST_NOT};
* MultiFieldQueryParser.parse("query", fields, flags, analyzer);
*
*
*
* The code above would construct a query:
*
*
* (filename:query) +(contents:query) -(description:query)
*
*
*
* @param query Query string to parse
* @param fields Fields to search on
* @param flags Flags describing the fields
* @param analyzer Analyzer to use
* @throws ParseException if query parsing fails
* @throws IllegalArgumentException if the length of the fields array differs
* from the length of the flags array
*/
public static Query parse(String query, String[] fields,
BooleanClause.Occur[] flags, Analyzer analyzer)5.4 跨度查询:
Lucene 新的隐藏法宝在Lucene 1.4中,包含了一个建立在SpanQuery 基础上的新的查询体系。本书中的span 表示的是一个域里面的某一对首尾位置。
回顾4.2.1节,分析过程中会产生一个新的且包含位置增量的语汇单元,它来自于分析前对应的语汇单元。
将这些位置信息与新的SpanQuery 子类结合在一起,可以为我们提供更强的查询辨别功能和精确度:
例如:我们可以查询到在“quick fox”相邻位置上存在着“lazy dog”的那些文档。
迄今为止,我们讨论过的查询类型都不适用于对上述句子的查询。你可能会使用"quick fox" AND "lazy dog"这样的搜索条件,不过由这个搜索条件搜索到的结果可能并不是我们所需要的,因为在这些结果中的两个短语可能会隔得很远。
值得庆幸的是,DougCutting 再一次向我们展示了他过人的智慧,他为 Lucene 的内核添加了跨度查询的功能。这种查询方式所跟踪的文档比匹配到的文档要多得多:每个单独的跨度(span)(每个域可包含多个跨度)都可能会被其跟踪。
与 TermQuery 只是简单地匹配文档形成鲜明对比的是, SpanTermQuery 能够跟踪到每个匹配项的位置。
表5.1列出了 SpanQuery 的5个子类:
- 表5.1SpanQuery 类家族
| SpanQuery 类型 | 描述 |
|---|---|
| SpanTermQuery | 和其他跨度查询类型结合使用。单独使用使相当于TermQuery |
| SpanFirstQuery | 用来匹配域中的第一个部分内的各个 spans |
| SpanNextQuery | 用来匹配临近的 spans |
| SpanNotQuery | 用来匹配不重叠的 spans |
| SpanOrOuery | Span 查询的聚合匹配 |
我们将在一个 JUnit 测试用例 SpanQueryTest 中分别讨论这些 SpanQuery类。
为了说明每种SpanQuery 类型,我们需要进行一些设置并声明一些更有帮助的 assert方法,从而使我们的代码看起来更有条理,如程序5.3所示。
我们把在一个域f内的两个同义词作为独立的文档进行索引,然后在测试函数中,我们为几个项创建了 SpanTermQuery 对象,以备后用。
此外,我们还添加了三个有用的 assert 方法以便例子更易于理解。
5.5 搜索过滤
过滤(Filtering) 是 Lucene 中用于缩小搜索空间的一种机制,它把可能的搜索匹配结果仅限制在所有文档的一个子集中。它们可以被用来对己得到的搜索匹配结果进行进一步搜索,以实现在搜索结果中继续搜索(search-within-search) 的特性。此外,基于安全或外部数据的原因,它们还可以被用来限制文档搜索空间。安全过滤器就是一个很好的例子,它使得用户能看到的搜索结果仅限于他们所拥有的文档,即使这些查询实际上还匹配了其他的文档。我们将在5.5.3节中列举一个安全过滤器的例子。
通过使用一个带有 Filter 参数的 search()方法,你可以对任何一个 Lucene 搜索进行过滤。
下面介绍三个内置的 Filter 子类:
DateFliter 使搜索只限于指定的日期域的在某一时间范围内的文档空间里。
QueryFilter 把查询结果作为另一个新查询可搜索的文档空间。
CachingWrappperFilter 是其他过滤器的装饰器(decorator),它将结果缓存起来以便再次使用,从而提高性能。
在你需要使用缓存结果之前,要确定它是由一个微小的数据结构(a BitSet) 完成的,在这个数据结构里的每一个比特代表一个文档。
同样,除了使用过滤器,我们还可以通过其它方法实现同样的功能:例如,把逻辑与的条件子句合并到 Booleanquery 对象中。
在这一节中,我们将会讨论每个内置的过滤器及作为其替代品的 BooleanQuery 对象。
V7.2.1 没有看到这几个类,暂时跳过。
5.6 对多个索引的搜索
如果你的应用程序构架由多个 Lucene 索引组成,但你又需要通过单个查询去搜索它们,且搜索结果的文档是分别从这些不同的索引中提取出来的。这时,使用 MultiSearcher就可以帮你达到这个目的。在使用 Lucene 处理海量数据时,你的应用体系构架可能需要切分文档集,并将这些不同的文档集存储到不同的索引中去。
5.6.1 使用 MultiSearcher
使用 MultiSearcher 可以把所有的索引都搜索到,搜索结果会以一种指定的顺序(或者是以评分递减的顺序)合并起来。
多索引搜索(MultiSearcher)的使用是相对于单索引搜索(IndexSearcher)而言的,除非你通过一组 IndexSearcher 对象去搜索一个以上的日录(因而这是一个高效的装饰器模式 (decorator pattern), 它将大部分工作都委托给了子搜索器)。
程序5.8为我们示范了如何去搜索两个索引,这两个索引是按照关键字的字母顺序划分的。该索引由动物的名称(名称的开头字母正好排列成字母表的顺序)组成。
这些动物名称中的半在其中个索引中,而另外一半则在另外一个索引中。下面的搜索程序执行了跨越两个索引范围的查询,并说明搜索结果已经被合并为个整体。
5.6.2 使用 ParallelMultiSearcher 进行多线程搜索
Lucene 1.4里新增了一个名为 ParallelMultiSearcher的多线程版本的多索引搜索器(MultiSearcher):搜索操作为每个 Searchable 接口分配一个线程,直到所有这些线程都完成其搜索。基本搜索和进行过滤的搜索是并行执行的,但是基于 HitCollector 的搜索暂时还不能被并行化处理。
使用 ParallelMultiSearcher 是否能获得性能上的收益,很大程度上取决于应用程序的体系架构。假设索引文件存放在不同的物理磁盘上,并且你可以利用多 CPU 的优势,在这种情况下,使用该类可能会改善系统的性能。但是,我们在单个 CPU, 单个物理磁盘和多个索引的环境下得到的测试结果是: MultiSearcher 的性能比 ParallelMultiSearchcr 还要稍微好一些。
ParallelMultiSearcher 的使用方法与 MultiSearcher 相同。我们将在程序5.9中向读者展示如何远程使用 ParallelMultiSearcher 进行搜索。
对多个索引进行远程搜索
Lucene通过远程方法调用 (Remote Method Invocation--RMI)为用户提供搜索远程索引的功能。
还有其他大量的替代方法可以支持远程搜索,比如通过 web 服务等。
本小节只把重点集中于 Lucene 内置的功能上,其他功能的实现留给读者自己去尝试(你也可以借鉴其他项目的设计思想,例如 Nutch 等,请查看10.1小节)。
RMI (远程方法调用)服务器绑定了一个 RemoteSearchable 的实例,它和IndexSearcher、MultiSearcher 一样,都实现了Searchable 接口。
服务器端的 RemoteSearchable 实例代表 Searchable 接口的一个具体实现,就像一个常规的 IndexSearcher 实例一样。
V7.2.1 也没找到这几个类,暂时跳过。
5.7 使用项向量
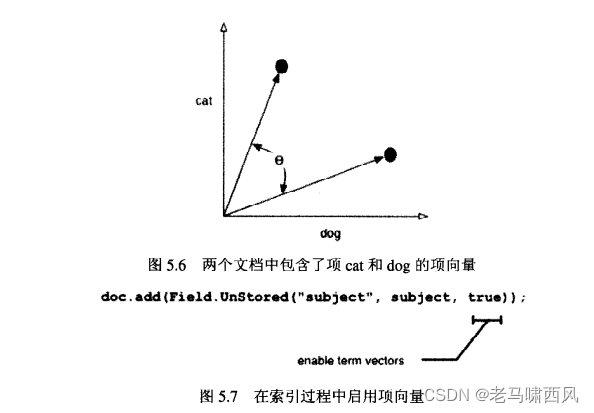
项向量 (term vectors) 是 Lucene 1.4中的一个新功能,但是它在信息检索领域里并不是新的概念。一个项向量是一组由项-频率对组成的集合。我们之中的大部分人可能很难在多维空间中想像向量的样子,为了将向量的概念可视化,我们来看一下只包含 cat和 dog这两个项的两个文档。这两个单词在每个文档中都出现了很多次。我们在二维空间的X, Y坐标上标记出这两个项出现的频率,如图5.6所示。我们感兴趣的是项向量之间的夹角,相关内容将在5.7.2小节详细地讲解。
为了启用项向量存储器,就必须在索引过程中启用相应字段中的存储项向量属性。
Field.Text 和 Field.Unstored 类型的域有一些额外的重载方法,在这些方法的声明中带有一个布尔类型的 storeTermVector 标记。
把这个标记值设置为 true, 就启用了这些域中支持项向量的可选功能,正如我们在索引书籍数据的例子中处理 subject 域的方法一样(详见图5.7)。
如果需要通过文档ID在给定的文档中获得某个域的项向量时,必须调用 IndexReader的 getTermFreqVector 方法:
实现 TermFreqVector接口的类的实例具有几个可用于检索向量信息的方法,这些方法主要用于返回一些字符串和整形数组(它们分别表示域中某个项的值以及该项出现频率)。你可以使用项向量实现一些有趣的功能,例如查找与特定文档相类似的文挡,这是一个对潜在语义进行分析的例子。
为此,我们编写了一个与概念验证 (proof-of-concept)分类器相似的名为 BooksLikeThis 的程序,该分类器可以告诉我们一本新书隶属于哪一个最恰当的类别,这些内容将在下一小节中向读者介绍。
参考资料
《Lucene in Action II》