
mysql(6)Index 从数据页的角度看 B+ 树
从数据页的角度看 B+ 树
大家背八股文的时候,都知道 MySQL 里 InnoDB 存储引擎是采用 B+ 树来组织数据的。
这点没错,但是大家知道 B+ 树里的节点里存放的是什么呢?查询数据的过程又是怎样的?
这次,我们从数据页的角度看 B+ 树,看看每个节点长啥样。
InnoDB 是如何存储数据的?
MySQL 支持多种存储引擎,不同的存储引擎,存储数据的方式也是不同的,我们最常使用的是 InnoDB 存储引擎,所以就跟大家图解下InnoDB 是如何存储数据的。
记录是按照行来存储的,但是数据库的读取并不以「行」为单位,否则一次读取(也就是一次 I/O 操作)只能处理一行数据,效率会非常低。
因此,InnoDB 的数据是按「数据页」为单位来读写的,也就是说,当需要读一条记录的时候,并不是将这个记录本身从磁盘读出来,而是以页为单位,将其整体读入内存。
数据库的 I/O 操作的最小单位是页,InnoDB 数据页的默认大小是 16KB,意味着数据库每次读写都是以 16KB 为单位的,一次最少从磁盘中读取 16K 的内容到内存中,一次最少把内存中的 16K 内容刷新到磁盘中。
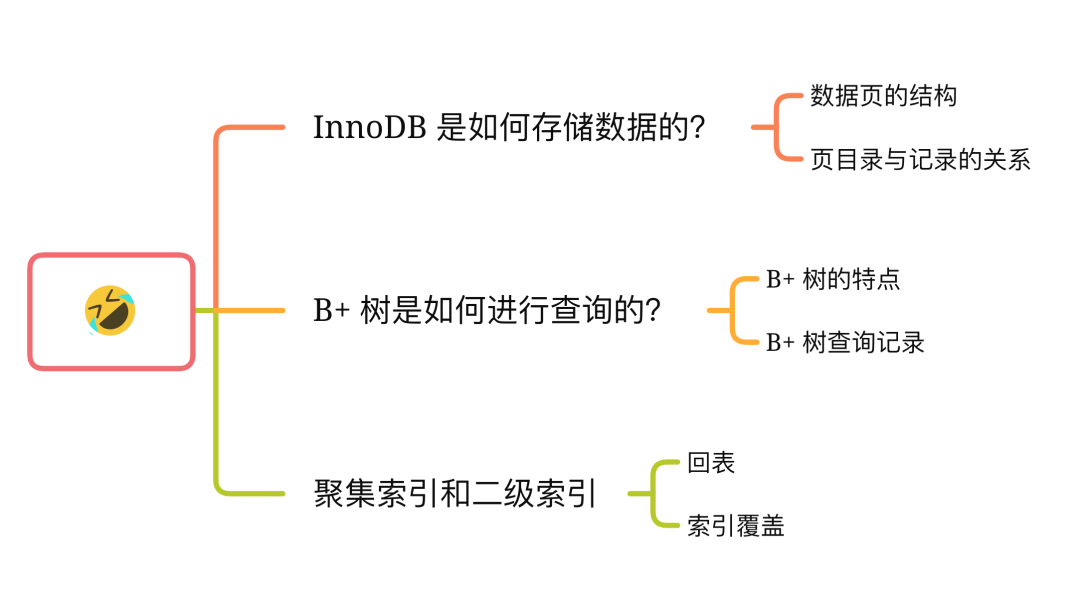
数据页包括七个部分,结构如下图:
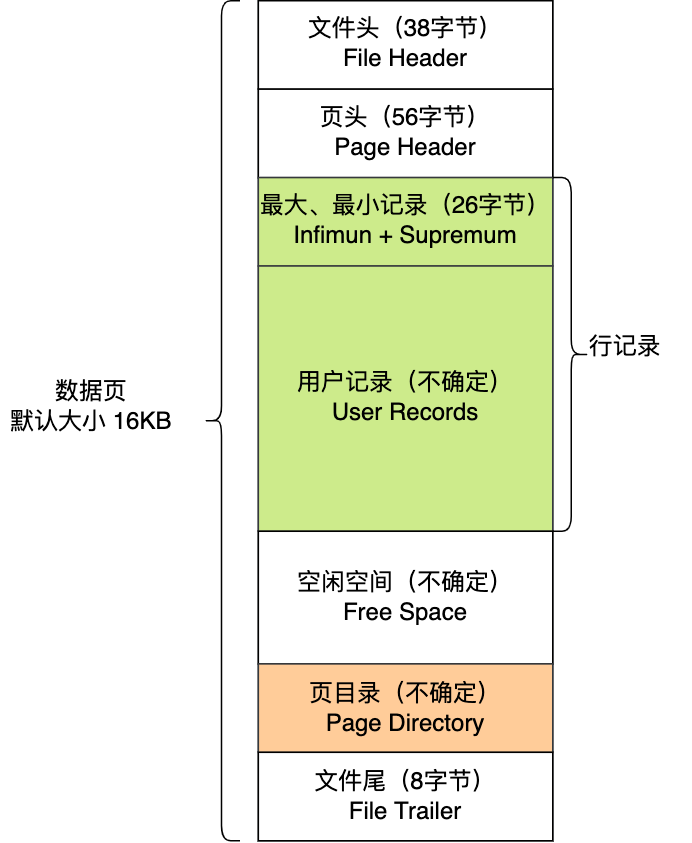
这 7 个部分的作用如下图:
在 File Header 中有两个指针,分别指向上一个数据页和下一个数据页,连接起来的页相当于一个双向的链表,如下图所示:
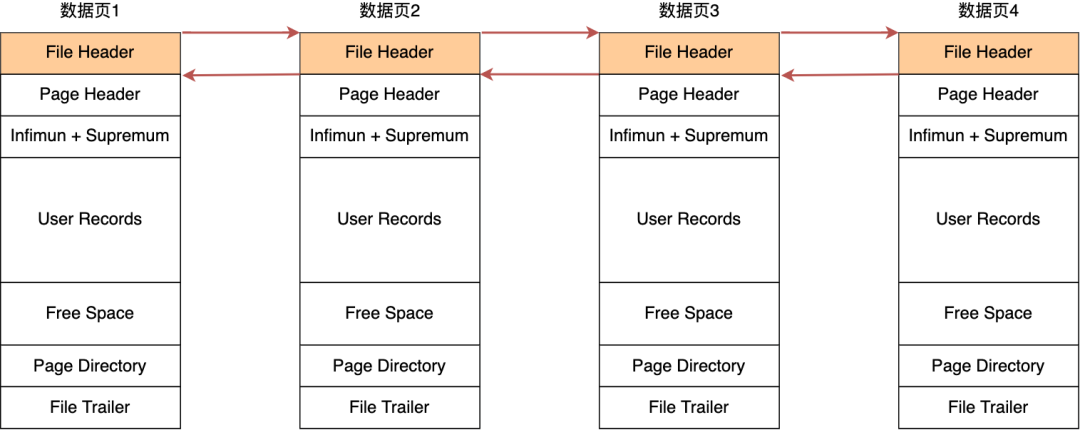
采用链表的结构是让数据页之间不需要是物理上的连续的,而是逻辑上的连续。
数据页的主要作用是存储记录,也就是数据库的数据,所以重点说一下数据页中的 User Records 是怎么组织数据的。
数据页中的记录按照「主键」顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。
因此,数据页中有一个页目录,起到记录的索引作用,就像我们书那样,针对书中内容的每个章节设立了一个目录,想看某个章节的时候,可以查看目录,快速找到对应的章节的页数,而数据页中的页目录就是为了能快速找到记录。
那 InnoDB 是如何给记录创建页目录的呢?
页目录与记录的关系如下图:
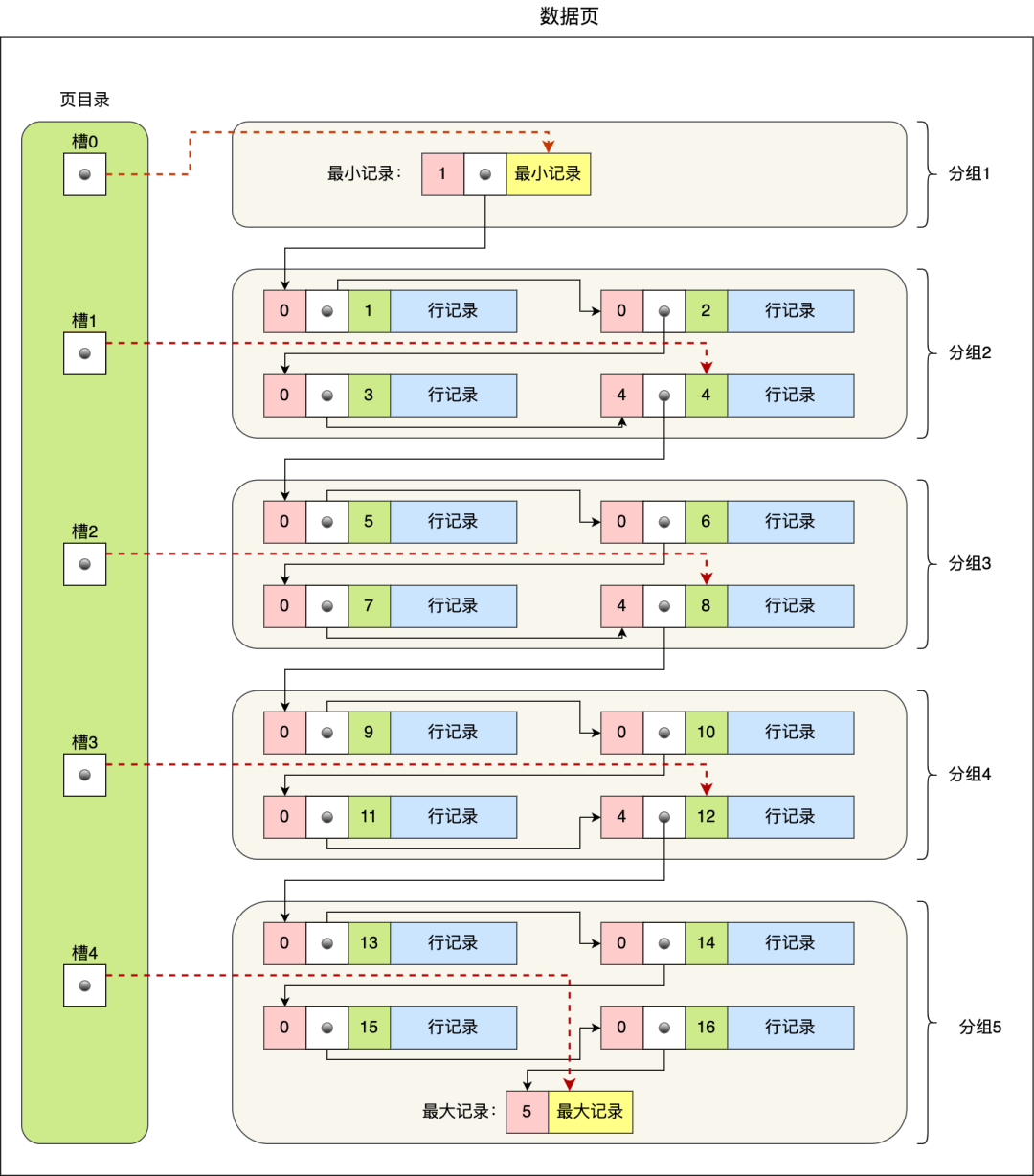
页目录创建的过程如下:
将所有的记录划分成几个组,这些记录包括最小记录和最大记录,但不包括标记为“已删除”的记录;
每个记录组的最后一条记录就是组内最大的那条记录,并且最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段(上图中粉红色字段)
页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录。
从图可以看到,页目录就是由多个槽组成的,槽相当于分组记录的索引。然后,因为记录是按照「主键值」从小到大排序的,所以我们通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到对应的记录,无需从最小记录开始遍历整个页中的记录链表。
以上面那张图举个例子,5 个槽的编号分别为 0,1,2,3,4,我想查找主键为 11 的用户记录:
先二分得出槽中间位是 (0+4)/2=2 ,2号槽里最大的记录为 8。因为 11 > 8,所以需要从 2 号槽后继续搜索记录;
再使用二分搜索出 2 号和 4 槽的中间位是 (2+4)/2= 3,3 号槽里最大的记录为 12。因为 11 5, 那按照二分法查找的规则,肯定就往右侧节点继续查找;
找到页号 30 的节点后,发现这个节点还有子节点(非叶子节点),那就继续比对,同理,6>5 && 6 X =?
在文章的开头已经介绍了页的结构,索引也也不例外,都会有 File Header (38 byte)、Page Header (56 Byte)、Infimum + Supermum(26 byte)、File Trailer(8byte), 再加上页目录,大概 1k 左右。
我们就当做它就是 1K, 那整个页的大小是 16K, 剩下 15k 用于存数据,在索引页中主要记录的是主键与页号,主键我们假设是 Bigint (8 byte), 而页号也是固定的(4Byte), 那么索引页中的一条数据也就是 12byte。
所以 x=15*1024/12≈1280 行。
Y=?
叶子节点和非叶子节点的结构是一样的,同理,能放数据的空间也是 15k。
但是叶子节点中存放的是真正的行数据,这个影响的因素就会多很多,比如,字段的类型,字段的数量。每行数据占用空间越大,页中所放的行数量就会越少。
这边我们暂时按一条行数据 1k 来算,那一页就能存下 15 条,Y = 15*1024/1000 ≈15。
算到这边了,是不是心里已经有谱了啊。
根据上述的公式,Total =x^(z-1) *y,已知 x=1280,y=15:
假设 B+ 树是两层,那就是 z = 2, Total = (1280 ^1 )*15 = 19200
假设 B+ 树是三层,那就是 z = 3, Total = (1280 ^2) *15 = 24576000 (约 2.45kw)
哎呀,妈呀!这不是正好就是文章开头说的最大行数建议值 2000W 嘛!对的,一般 B+ 数的层级最多也就是 3 层。
你试想一下,如果是 4 层,除了查询的时候磁盘 IO 次数会增加,而且这个 Total 值会是多少,大概应该是 3 百多亿吧,也不太合理,所以,3 层应该是比较合理的一个值。
到这里难道就完了?
我们刚刚在说 Y 的值时候假设的是 1K ,那比如我实际当行的数据占用空间不是 1K , 而是 5K, 那么单个数据页最多只能放下 3 条数据。
同样,还是按照 z = 3 的值来计算,那 Total = (1280 ^2) *3 = 4915200 (近 500w)
所以,在保持相同的层级(相似查询性能)的情况下,在行数据大小不同的情况下,其实这个最大建议值也是不同的,而且影响查询性能的还有很多其他因素,比如,数据库版本,服务器配置,sql 的编写等等。
MySQL 为了提高性能,会将表的索引装载到内存中,在 InnoDB buffer size 足够的情况下,其能完成全加载进内存,查询不会有问题。
但是,当单表数据库到达某个量级的上限时,导致内存无法存储其索引,使得之后的 SQL 查询会产生磁盘 IO,从而导致性能下降,所以增加硬件配置(比如把内存当磁盘使),可能会带来立竿见影的性能提升哈。
总结
MySQL 的表数据是以页的形式存放的,页在磁盘中不一定是连续的。
页的空间是 16K, 并不是所有的空间都是用来存放数据的,会有一些固定的信息,如,页头,页尾,页码,校验码等等。
在 B+ 树中,叶子节点和非叶子节点的数据结构是一样的,区别在于,叶子节点存放的是实际的行数据,而非叶子节点存放的是主键和页号。
索引结构不会影响单表最大行数,2000W 也只是推荐值,超过了这个值可能会导致 B + 树层级更高,影响查询性能。
参考资料
https://xiaolincoding.com/mysql/index/page.html#innodb-是如何存储数据的