
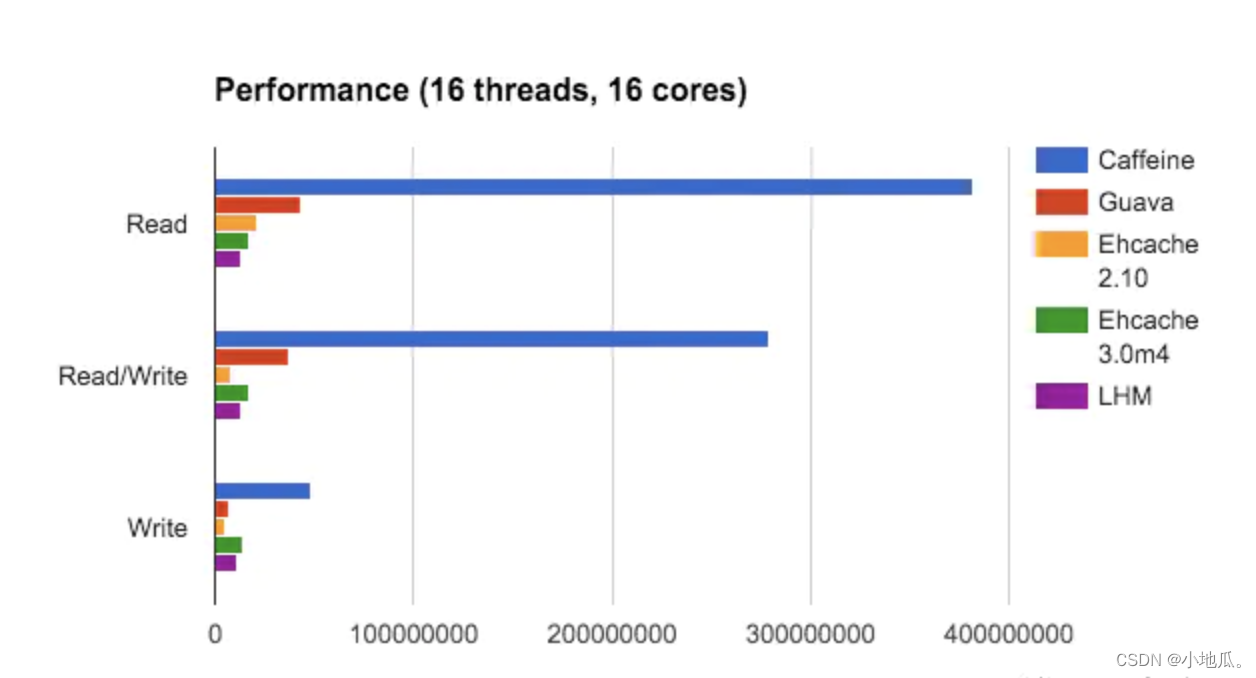
Caffeine 是一个基于Java 8的高性能本地缓存框架,采用了W-TinyLFU(LUR和LFU的优点结合)算法,实现了缓存高命中率、内存低消耗。
缓存性能接近理论最优,属于是Guava Cache的增强版。
在并发读、并发写、并发读写三个场景下Caffeine的性能最优。
2018年9月10日大约 13 分钟
Caffeine 是一个基于Java 8的高性能本地缓存框架,采用了W-TinyLFU(LUR和LFU的优点结合)算法,实现了缓存高命中率、内存低消耗。
缓存性能接近理论最优,属于是Guava Cache的增强版。
在并发读、并发写、并发读写三个场景下Caffeine的性能最优。
FIFO是类似队列的算法,如果空间满了需要加入新数据先进入缓存的数据会被优先被淘汰。
淘汰过程:
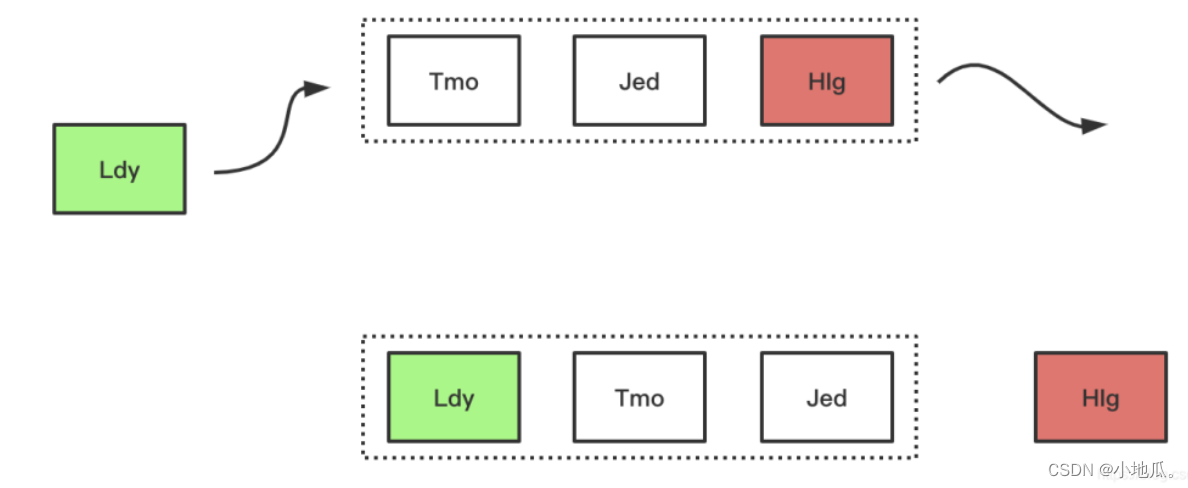
优点:最简单,最公平的一种数据淘汰算法,逻辑简单,易于实现。
缺点:缓存命中率低。
摘要
本文提出了一种基于频率的缓存准入策略,以提高受访问分布偏差影响的缓存的有效性。给定一个新访问的项目和缓存中的一个驱逐候选项,我们的方案基于最近的访问历史来决定,是否值得以驱逐候选项为代价将新项目纳入缓存。
实现这一概念是通过一种新颖的近似LFU(最近最少使用)结构,称为TinyLFU,它维护了一个最近访问的大样本项目的访问频率的近似表示。TinyLFU非常紧凑和轻量级,因为它建立在布隆过滤器理论之上。
我们通过模拟合成工作负载以及多个来源的多个真实跟踪来研究TinyLFU的属性。这些模拟展示了通过增强各种替换策略与TinyLFU驱逐策略所获得的性能提升。此外,还介绍了一种新的组合替换和驱逐策略方案,昵称为W-TinyLFU。W-TinyLFU被证明在这些跟踪上获得等于或优于其他最先进替换策略的命中率。它是唯一在所有跟踪上都能获得如此好结果的方案。
Caffeine Cache 作为高性能 Java 本地缓存库,提供了四类核心缓存实例,每种类型对应不同的加载策略和方法。
以下是其核心方法分类说明:
Cache)通过 Caffeine.newBuilder().build() 创建,需显式管理缓存条目。
getIfPresent(K key):若缓存存在 key,返回值;否则返回 null。get(K key, Function loader):若 key 不存在,通过 loader 函数计算值并缓存,原子操作避免竞争。put(K key, V value):添加或覆盖键值对。invalidate(K key):移除指定 key 的缓存项。invalidateAll():清空所有缓存。asMap():返回 ConcurrentMap 视图,支持标准 Map 操作(如 putIfAbsent())。Caffeine is a high performance, near optimal caching library based on Java 8.
Caffeine 提供灵活的结构,以创建一个缓存与下列功能的组合:
自动将条目加载到缓存中,可选异步加载
当基于频率和最近度超过最大值时,基于尺寸的驱逐
基于时间的条目过期,从上次访问或上次写入开始计算
当出现第一个过时的条目请求时,异步刷新
自动封装在弱引用中的键
自动封装在弱引用或软引用中的值
退出(或以其他方式删除)条目的通知
传播到外部资源的写
缓存访问统计数据的积累
缓存在很多场景下都是相当有用的。例如,计算或检索一个值的代价很高,并且对同样的输入需要不止一次获取值的时候,就应当考虑使用缓存。
Guava Cache与ConcurrentMap很相似,但也不完全一样。
最基本的区别是ConcurrentMap会一直保存所有添加的元素,直到显式地移除。相对地,Guava Cache为了限制内存占用,通常都设定为自动回收元素。在某些场景下,尽管LoadingCache 不回收元素,它也是很有用的,因为它会自动加载缓存。
你愿意消耗一些内存空间来提升速度。
你预料到某些键会被查询一次以上。
缓存中存放的数据总量不会超出内存容量。
上节内容讲到log文件在LevelDb中的主要作用是系统故障恢复时,能够保证不会丢失数据。
因为在将记录写入内存的Memtable之前,会先写入Log文件,这样即使系统发生故障,Memtable中的数据没有来得及Dump到磁盘的SSTable文件,LevelDB也可以根据log文件恢复内存的Memtable数据结构内容,不会造成系统丢失数据,在这点上LevelDb和Bigtable是一致的。
下面我们带大家看看log文件的具体物理和逻辑布局是怎样的,LevelDb对于一个log文件,会把它切割成以32K为单位的物理Block,每次读取的单位以一个Block作为基本读取单位,下图展示的log文件由3个Block构成,所以从物理布局来讲,一个log文件就是由连续的32K大小Block构成的。
SSTable是Bigtable中至关重要的一块,对于LevelDb来说也是如此,对LevelDb的SSTable实现细节的了解也有助于了解Bigtable中一些实现细节。
本节内容主要讲述SSTable的静态布局结构,我们曾在“LevelDb日知录之二:整体架构”中说过,SSTable文件形成了不同Level的层级结构,
至于这个层级结构是如何形成的我们放在后面Compaction一节细说。
本节主要介绍SSTable某个文件的物理布局和逻辑布局结构,这对了解LevelDb的运行过程很有帮助。
LevelDb不同层级有很多SSTable文件(以后缀.sst为特征),所有.sst文件内部布局都是一样的。
上节介绍Log文件是物理分块的,SSTable也一样会将文件划分为固定大小的物理存储块,但是两者逻辑布局大不相同,
根本原因是:Log文件中的记录是Key无序的,即先后记录的key大小没有明确大小关系,
而.sst文件内部则是根据记录的Key由小到大排列的,从下面介绍的SSTable布局可以体会到Key有序是为何如此设计.sst文件结构的关键。