
2020年1月9日大约 7 分钟
2020年1月9日大约 7 分钟
2020年1月9日大约 3 分钟
2020年1月9日大约 3 分钟
2020年1月9日大约 3 分钟
这里的拼音一般不带声调。
将汉字作为隐藏状态,拼音作为观测值,使用viterbi算法可以将多个拼音转换成合理的汉字。
例如给出ti,chu,le,jie,jue,fang,an,viterbi算法会认为提出了解决方案是最合理的状态序列。
HMM 需要三个分布,分别是:
-
初始时各个状态的概率分布
-
各个状态互相转换的概率分布
-
状态到观测值的概率分布
这个3个分布就是三个矩阵,根据一些文本库统计出来即可。
2020年1月9日大约 1 分钟
拼音转换工具的思路不难:
(1)词语分词
(2)基于词库进行拼音的映射
(3)拼接最后的结果
可以认为主要下面的部分值得留意
准确性
作为拼音转换算法,准确性优先级应该是在性能之前的。
如果我们能保证高准确性,应该尽可能的去提高准确性。
词库来源
这里的词库,不包括分词的词库,仅仅指拼音的词库。
指拼音的词库,收集可以在各种优秀词库的基础上,不应该在收集上耗费太多时间。
分词算法
分词有许多优秀的算法,其中的学问也比较多。
2020年1月9日大约 16 分钟
B+ tree 实际上是一颗m叉平衡查找树(不是二叉树)
平衡查找树定义:树中任意一个节点的左右子树的高度相差不能大于 1
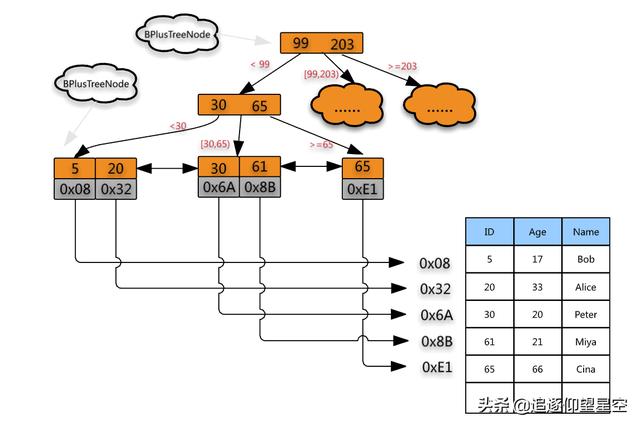
/**
* 这是B+树非叶子节点的定义。
*
* 假设keywords=[3, 5, 8, 10]
* 4个键值将数据分为5个区间:(-INF,3), [3,5), [5,8), [8,10), [10,INF)
* 5个区间分别对应:children[0]...children[4]
*
* m值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:
* PAGE_SIZE = (m-1)*4[keywordss大小]+m*8[children大小]
*/
public class BPlusTreeNode {
// 5叉树
public static int m = 5;
// 键值,用来划分数据区间
public int[] keywords = new int[m-1];
// 保存子节点指针
public BPlusTreeNode[] children = new BPlusTreeNode[m];
}
/**
* 这是B+树中叶子节点的定义。
*
* B+树中的叶子节点跟内部结点是不一样的,
* 叶子节点存储的是值,而非区间。
* 这个定义里,每个叶子节点存储3个数据行的键值及地址信息。
*
* k值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:
* PAGE_SIZE = k*4[keyw..大小]+k*8[dataAd..大小]+8[prev大小]+8[next大小]
*/
public class BPlusTreeLeafNode {
public static int k = 3;
// 数据的键值
public int[] keywords = new int[k];
// 数据地址
public long[] dataAddress = new long[k];
// 这个结点在链表中的前驱结点
public BPlusTreeLeafNode prev;
// 这个结点在链表中的后继结点
public BPlusTreeLeafNode next;
}2018年12月11日大约 10 分钟
建议学习方式:
烂笔头是个好东西
现在学的无论多么好,3年后估计也会忘掉。
整理下来,理论成为博客,实战成为代码。
java-driver
基础的入门整合。
至于细节,则不用展开。
理论上 API 和实际是一一对应的。
spring 整合
2018年12月11日小于 1 分钟
需要兼容云上云下的代码。
在云下,用的时 v3.4.6 比较老的版本,为了上云方便,云上申请的也是 v3.4 版本。
阿里云没有小版本,经验证 db.version() 也是 v3.4.6
以为一切都没有问题之后,结果遇到一个坑:
云下的验证方式,默认是 MONGODB-CR 方式,但是云上是 SCRAM-SHA-1 方式。
为什么不通
因为 MONGODB-CR 是不够安全的,出于产品角度的考虑,云上将不对其进行支持。
如何解决
修改云下版本
2018年12月11日大约 4 分钟