
日志开源组件(六)Adaptive Sampling 自适应采样
业务背景
有时候日志的信息比较多,怎么样才可以让系统做到自适应采样呢?
拓展阅读
日志开源组件(一)java 注解结合 spring aop 实现自动输出日志
日志开源组件(二)java 注解结合 spring aop 实现日志traceId唯一标识
日志开源组件(三)java 注解结合 spring aop 自动输出日志新增拦截器与过滤器
日志开源组件(四)如何动态修改 spring aop 切面信息?让自动日志输出框架更好用
日志开源组件(五)如何将 dubbo filter 拦截器原理运用到日志拦截器中?
自适应采样
是什么?
系统生成的日志可以包含大量信息,包括错误、警告、性能指标等,但在实际应用中,处理和分析所有的日志数据可能会对系统性能和资源产生负担。
自适应采样在这种情况下发挥作用,它能够根据当前系统状态和日志信息的重要性,智能地决定哪些日志需要被采样记录,从而有效地管理和分析日志数据。
采样的必要性
日志采样系统会给业务系统额外增加消耗,很多系统在接入的时候会比较排斥。
给他们一个百分比的选择,或许是一个不错的开始,然后根据实际需要选择合适的比例。
自适应采样是一个对用户透明,同时又非常优雅的方案。

如何通过 java 实现自适应采样?
接口定义
首先我们定义一个接口,返回 boolean。
根据是否为 true 来决定是否输出日志。
/**
* 采样条件
* @author binbin.hou
* @since 0.5.0
*/
public interface IAutoLogSampleCondition {
/**
* 条件
*
* @param context 上下文
* @return 结果
* @since 0.5.0
*/
boolean sampleCondition(IAutoLogContext context);
}百分比概率采样
我们先实现一个简单的概率采样。
0-100 的值,让用户指定,按照百分比决定是否采样。
public class InnerRandomUtil {
/**
* 1. 计算一个 1-100 的随机数 randomVal
* 2. targetRatePercent 值越大,则返回 true 的概率越高
* @param targetRatePercent 目标百分比
* @return 结果
*/
public static boolean randomRateCondition(int targetRatePercent) {
if(targetRatePercent = 100) {
return true;
}
// 随机
ThreadLocalRandom threadLocalRandom = ThreadLocalRandom.current();
int value = threadLocalRandom.nextInt(1, 100);
// 随机概率
return targetRatePercent >= value;
}
}实现起来也非常简单,直接一个随机数,然后比较大小即可。
自适应采样
思路
我们计算一下当前日志的 QPS,让输出的概率和 QPS 称反比。
/**
* 自适应采样
*
* 1. 初始化采样率为 100%,全部采样
*
* 2. QPS 如果越来越高,那么采样率应该越来越低。这样避免 cpu 等资源的损耗。最低为 1%
* 如果 QPS 越来越低,采样率应该越来越高。增加样本,最高为 100%
*
* 3. QPS 如何计算问题
*
* 直接设置大小为 100 的队列,每一次在里面放入时间戳。
* 当大小等于 100 的时候,计算首尾的时间差,currentQps = 100 / (endTime - startTime) * 1000
*
* 触发 rate 重新计算。
*
* 3.1 rate 计算逻辑
*
* 这里我们存储一下 preRate = 100, preQPS = ?
*
* newRate = (preQps / currentQps) * rate
*
* 范围限制:
* newRate = Math.min(100, newRate);
* newRate = Math.max(1, newRate);
*
* 3.2 时间队列的清空
*
* 更新完 rate 之后,对应的队列可以清空?
*
* 如果额外使用一个 count,好像也可以。
* 可以调整为 atomicLong 的计算器,和 preTime。
*代码实现
public class AutoLogSampleConditionAdaptive implements IAutoLogSampleCondition {
private static final AutoLogSampleConditionAdaptive INSTANCE = new AutoLogSampleConditionAdaptive();
/**
* 单例的方式获取实例
* @return 结果
*/
public static AutoLogSampleConditionAdaptive getInstance() {
return INSTANCE;
}
/**
* 次数大小限制,即接收到多少次请求更新一次 adaptive 计算
*
* TODO: 这个如何可以让用户可以自定义呢?后续考虑配置从默认的配置文件中读取。
*/
private static final int COUNT_LIMIT = 1000;
/**
* 自适应比率,初始化为 100.全部采集
*/
private volatile int adaptiveRate = 100;
/**
* 上一次的 QPS
*
* TODO: 这个如何可以让用户可以自定义呢?后续考虑配置从默认的配置文件中读取。
*/
private volatile double preQps = 100.0;
/**
* 上一次的时间
*/
private volatile long preTime;
/**
* 总数,请求计数器
*/
private final AtomicInteger counter;
public AutoLogSampleConditionAdaptive() {
preTime = System.currentTimeMillis();
counter = new AtomicInteger(0);
}
@Override
public boolean sampleCondition(IAutoLogContext context) {
int count = counter.incrementAndGet();
// 触发一次重新计算
if(count >= COUNT_LIMIT) {
updateAdaptiveRate();
}
// 直接计算是否满足
return InnerRandomUtil.randomRateCondition(adaptiveRate);
}
}每次累加次数超过限定次数之后,我们就更新一下对应的日志概率。
最后的概率计算和上面的百分比类似,不再赘述。
/**
* 更新自适应的概率
*
* 100 计算一次,其实还好。实际应该可以适当调大这个阈值,本身不会经常变化的东西。
*/
private synchronized void updateAdaptiveRate() {
//消耗的毫秒数
long costTimeMs = System.currentTimeMillis() - preTime;
//qps 的计算,时间差是毫秒。所以次数需要乘以 1000
double currentQps = COUNT_LIMIT*1000.0 / costTimeMs;
// preRate * preQps = currentRate * currentQps; 保障采样均衡,服务器压力均衡
// currentRate = (preRate * preQps) / currentQps;
// 更新比率
int newRate = 100;
if(currentQps > 0) {
newRate = (int) ((adaptiveRate * preQps) / currentQps);
newRate = Math.min(100, newRate);
newRate = Math.max(1, newRate);
}
// 更新 rate
adaptiveRate = newRate;
// 更新 QPS
preQps = currentQps;
// 更新上一次的时间内戳
preTime = System.currentTimeMillis();
// 归零
counter.set(0);
}自适应代码-改良
问题
上面的自适应算法一般情况下都可以运行的很好。
但是有一种情况会不太好,那就是流量从高峰期到低峰期。
比如凌晨11点是请求高峰期,我们的输出日志概率很低。深夜之后请求数会很少,想达到累计值就会很慢,这个时间段就会导致日志输出很少。
如何解决这个问题呢?
思路
我们可以通过固定时间窗口的方式,来定时调整流量概率。
java 实现
我们初始化一个定时任务,1min 定时更新一次。
public class AutoLogSampleConditionAdaptiveSchedule implements IAutoLogSampleCondition {
private static final ScheduledExecutorService EXECUTOR_SERVICE = Executors.newSingleThreadScheduledExecutor();
/**
* 时间分钟间隔
*/
private static final int TIME_INTERVAL_MINUTES = 5;
/**
* 自适应比率,初始化为 100.全部采集
*/
private volatile int adaptiveRate = 100;
/**
* 上一次的总数
*
* TODO: 这个如何可以让用户可以自定义呢?后续考虑配置从默认的配置文件中读取。
*/
private volatile long preCount;
/**
* 总数,请求计数器
*/
private final AtomicLong counter;
public AutoLogSampleConditionAdaptiveSchedule() {
counter = new AtomicLong(0);
preCount = TIME_INTERVAL_MINUTES * 60 * 100;
//1. 1min 后开始执行
//2. 中间默认 5 分钟更新一次
EXECUTOR_SERVICE.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
updateAdaptiveRate();
}
}, 60, TIME_INTERVAL_MINUTES * 60, TimeUnit.SECONDS);
}
@Override
public boolean sampleCondition(IAutoLogContext context) {
counter.incrementAndGet();
// 直接计算是否满足
return InnerRandomUtil.randomRateCondition(adaptiveRate);
}
}其中更新概率的逻辑和上面类似:
/**
* 更新自适应的概率
*
* QPS = count / time_interval
*
* 其中时间维度是固定的,所以可以不用考虑时间。
*/
private synchronized void updateAdaptiveRate() {
// preRate * preCount = currentRate * currentCount; 保障采样均衡,服务器压力均衡
// currentRate = (preRate * preCount) / currentCount;
// 更新比率
long currentCount = counter.get();
int newRate = 100;
if(currentCount != 0) {
newRate = (int) ((adaptiveRate * preCount) / currentCount);
newRate = Math.min(100, newRate);
newRate = Math.max(1, newRate);
}
// 更新自适应频率
adaptiveRate = newRate;
// 更新 QPS
preCount = currentCount;
// 归零
counter.set(0);
}小结
让系统自动化分配资源,是一种非常好的思路,可以让资源利用最大化。
实现起来也不是很困难,实际要根据我们的业务量进行观察和调整。
开源地址
auto-log https://github.com/houbb/auto-log
其他
Q2-为什么需要?
自适应采样在不同领域中有多种应用,这是因为它可以解决许多问题和优化资源利用。以下是一些需要自适应采样的情况:
大数据处理: 在大数据环境中,处理和分析所有数据可能是不切实际的,因为它可能会占用大量计算资源和存储空间。自适应采样可以帮助识别和保留关键数据,从而减少分析和处理的成本。
日志监控: 系统产生的日志可能非常庞大,但并非所有日志都是关键的。自适应采样可以帮助捕获重要的错误和事件,而忽略不重要的信息,以便更好地进行故障排查和系统监控。
传感器数据采集: 在传感器网络中,大量传感器可能会产生大量数据。自适应采样可以帮助选择哪些传感器的数据需要被采集,以优化资源使用和数据分析。
优化问题: 在优化问题中,可能需要对不同参数或变量进行采样以寻找最优解。自适应采样可以帮助调整采样策略,集中在可能获得更好结果的区域。
资源限制: 当资源有限时,如计算资源、存储空间或网络带宽,自适应采样可以帮助最大程度地利用有限资源,同时仍然获取足够多的信息。
实验设计: 在科学实验中,自适应采样可以帮助选择哪些实验条件或参数设置需要被测试,从而更有效地探索问题空间。
网络流量分析: 在网络安全领域,自适应采样可以帮助捕获潜在的攻击流量,而减少不相关的数据。
综上所述,自适应采样的需求源于资源有限和数据的不均匀性。
它可以帮助优化资源利用、提高数据分析效率、捕获关键信息,并在各种领域中提供更好的结果。
Q3-如何实现?给出思路
实现自适应采样涉及多个步骤和决策,具体方法可以根据应用领域和需求的不同而有所调整。
以下是一个一般性的思路,可以用来实现自适应采样:
定义初始策略: 首先,你需要定义一个初始的采样策略,可以根据经验、数据分布等设定初始的采样率或规则。这个策略将在开始阶段使用。
收集样本: 开始收集数据样本,并根据初始策略进行采样。这个阶段可以帮助你获取初始数据来进行后续的分析和优化。
分析样本: 对已采样的数据样本进行分析。这可以包括计算关键事件的出现频率、错误率、性能指标等。分析将帮助你了解数据的特点和分布。
重要性评估: 对不同类型的数据或事件进行重要性评估。这可以基于业务需求、风险等因素。你可以确定哪些数据或事件对系统或任务的影响更大。
动态调整: 根据分析和重要性评估的结果,调整采样策略。这可能包括增加关键事件的采样率,降低不重要数据的采样率,或者更精细地设定采样规则。
实时监控: 在运行时,实时监控系统状态和数据流。根据实际情况动态地调整采样策略。例如,当系统负载上升时,可以减少日志采样率以减轻系统压力。
迭代优化: 根据实际效果不断迭代优化采样策略。分析新的采样数据,评估是否达到了预期的目标,然后根据需要进行调整。
记录和分析结果: 记录采样策略的调整和实际效果。这将有助于你在未来优化自适应采样策略,甚至可以用于建立模型来预测何时需要调整策略。
根据实际情况不断优化和调整策略,以达到更好的数据分析效果。
自适应采样算法在全链路跟踪中的应用
在实际生产环境中,全链路跟踪框架如果对每个请求都开启跟踪,必然会对系统的性能带来一定的压力。
与此同时,庞大的数据量也会占用大量的存储资源,使用全量采样的场景很有限,大部分应用接入链路跟踪的初衷是错误异常分析或者样本查看。
为了消除全量采样给系统带来的影响,设置采样率是一个很好的办法。
采样率通常是一个概率值,取值在0到1之间,例如设置采样率为0.5的话表示只对50%的请求进行采样。
在之前的采样算法之蓄水池算法,描述了一种常用的采样算法实现。
但是采用固定采样率的算法仍然有2个明显的问题:
应用无法很好的评估采样率。从中间件的角度来说,这个对于应用最好能做到透明
应用在不同的时间段,流量或者负载等会有很大的差别。如果采用统一的采样率,可能导致样本不均衡或者不充足
所以,比较理想的方式是提供自适应采样。最初的思想可追溯到Dapper的Coping with aggressive sampling。
QPS-采样数-采样率函数
首先,我们拟根据应用qps作为变量来构建qps-每秒采样数函数,从而可算出采样率,即每秒采样数/qps。
接着,我们需要确定一些目标值,根据对这些值的逼近来得出我们的最终函数。
最小阈值。为了对低流量的应用尽可能公平,保证样本的充分,我们约定小于等于最小阈值qps的时候,采样率为百分百。假定最小阈值为10,即qps 99);
return res;
}private int calAdaptiveRateInHundred(long interval) {
double qps = (double) (100 * 1000) / interval;
if (qps MAX_SAMPLE_LIMIT) {
qps = MAX_SAMPLE_LIMIT;
}
double num = -0.00015 * Math.pow(qps, 2) + 0.611 * qps + 3.905;
return (int) Math.round((num / qps) * 100.0f);
}
}
}
# 一文搞懂 Jaeger 的自适应采样
Hello folks,在之前的文章中,我们介绍了有关 Jaeger 的数据采样率,在实际的业务场景中,其主要支持以下 5 种采样率设置,具体如下:
1、固定采样(sampler.type=const)sampler.param=1 全采样, sampler.param=0 不采样。
2、按百分比采样(sampler.type=probabilistic)sampler.param=0.1 则随机采十分之一的样本。
3、采样速度限制(sampler.type=ratelimiting)sampler.param=2.0 每秒采样两个 traces。
4、动态获取采样率 (sampler.type=remote) 此策略为默认配置,可以通过配置从 Agent 中获取采样率的动态设置。
5、自适应采样(Adaptive Sampling)开发计划中。
目前,在 Jaeger V1.27.0 版本中开始支持自适应采样模式。
基于此模式,在 Jaeger 收集器中,通过观察从服务接收到的跨度并重新计算每个服务/端点组合的采样概率,以确保收集的跟踪量与 --sampling.target-samples-per-second 匹配。
当检测到新服务或端点时,最初会使用 --sampling.initial-sampling-probability 对其进行采样,直到收集到足够的数据来计算适合通过端点的流量的速率。
自适应采样需要一个存储后端来存储观察到的流量数据和计算的概率。
目前支持内存(用于一体式部署)和 Cassandra 作为采样存储后端。据官网所述,其正在开发以实现对其他后端的支持(问题跟踪)。
在分布式跟踪中,经常使用“采样”模型来减少后端收集和存储的跟踪数量,这通常是可取的,因为它很容易产生比有效存储和查询更多的数据。
毕竟,采样允许我们只存储所产生的总轨迹的一个子集。
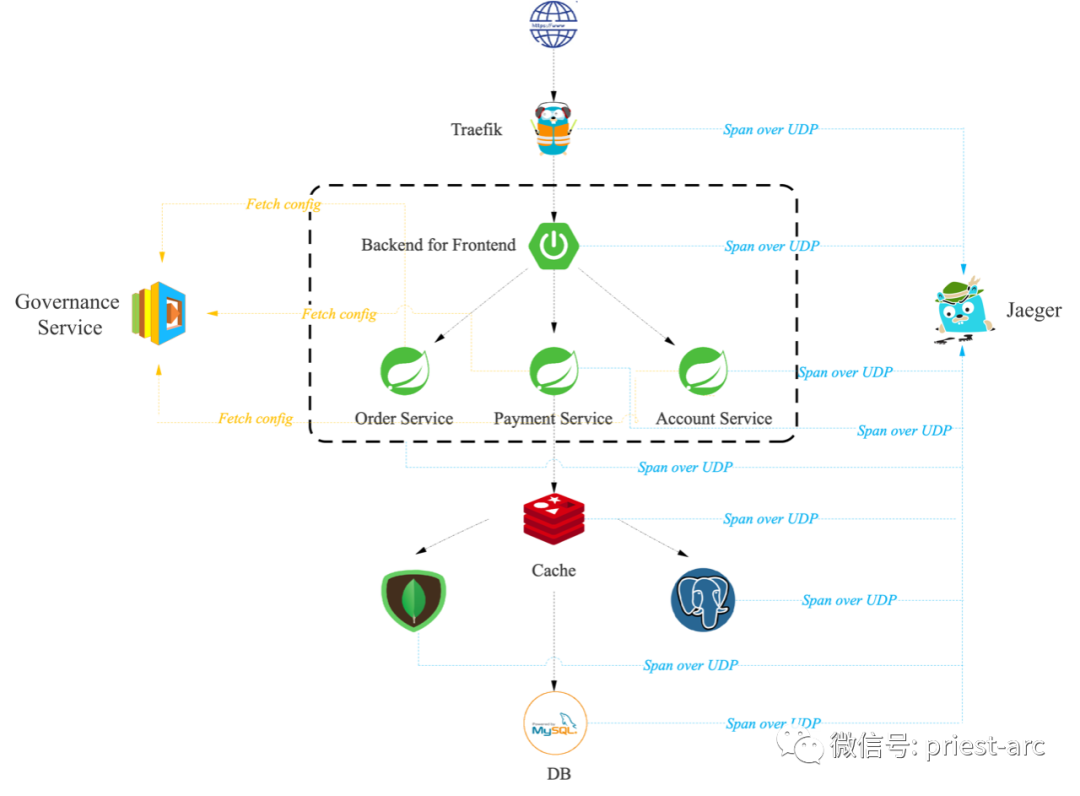
传统上,Jaeger SDK 支持多种采样技术。但最具有革新性的便是所谓的远程采样,这是 Jaeger 项目在开源中率先推出的一项功能。
在此设置中,Jaeger SDK 将查询 Jaeger 后端以检索给定服务的采样规则配置,直至单个端点的粒度。
这可能是一种非常强大的采样方法,因为它可以让操作员集中控制整个组织的采样率。
直到最近,在远程采样模式下控制后端返回那些采样规则的唯一方法是使用通过 --sampling.strategies-file 标志提供给收集器的配置文件。
通常,运营商必须手动更新此文件以推出不同的采样规则。
V1.27.0 中添加的自适应采样允许收集器通过观察系统中的当前流量和收集的跟踪数量来自动调整采样率以满足预先配置的目标。
此功能已在 Uber 生产多年,最终在 Jaeger 的开源版本上可用。
## 自适应采样的革新
为什么我们需要远程和自适应采样?
始终可以将 SDK 配置为应用非常简单的采样策略,例如掷硬币决策,也称为概率采样。
这在小型应用程序中可能工作得很好,但是当您的架构以 100 甚至 1000 个服务来衡量时,这些服务都具有不同的流量,每个服务的单个采样概率并不能很好地工作,并且为每个服务单独配置它服务是部署的噩梦。
远程采样通过将所有采样配置集中在 Jaeger 收集器中解决了这个问题,其中可以将更改快速推送到任何服务。
但是,手动为每个服务配置采样规则,即使集中配置,仍然非常繁琐。自适应采样更进一步,并将其转换为声明式配置,其中操作员只需设置跟踪收集的目标速率,自适应采样引擎会为每个服务和每个端点动态调整采样率。
自适应采样的另一个好处是它可以自动对流量的变化做出反应。许多在线服务在白天表现出流量波动,例如 Uber 在高峰时段会有更多的请求。
自适应采样引擎会自动调整采样率,以保持跟踪数据量稳定并在我们的采样预算范围内。
## 自适应采样原理
那么,自适应采样到底是如何工作的呢?我们来看一下。
我们从分配给每个端点的一些默认采样概率 p 和我们想要收集的跟踪的目标速率 R 开始,例如每个端点每秒 1 个跟踪。
收集器监视通过它们的跨度,寻找以该采样策略开始的迹线的根跨度,并计算被收集的迹线 R' 的实际速率。
如果 R' > R,那么我们当前对该端点的概率太高,需要降低。
相反,如果 R' R + k 且R'通常情况下,默认设置为与本地 Jaeger 代理一起使用,作为主机代理或 Sidecar 运行,Jaeger SDK 配置实际上默认为:
JAEGER_SAMPLER_TYPE=remote
JAEGER_SAMPLING_ENDPOINT=http://127.0.0.1:5778/sampling配置客户端后,我们需要确保正确配置收集器以存储自适应采样信息。
目前,Jaeger 使用与跨度存储相同的存储进行自适应采样,并且唯一支持的自适应采样存储选项是 Cassandra(自 V1.27 起)和内存(自 V1.28 起)。
使用环境变量配置的收集器可参考如下参数:
SPAN_STORAGE_TYPE=cassandra
SAMPLING_CONFIG_TYPE=adaptive接下来,我们来看一下简单的 jaeger-docker-compose.yml 示例,该 Demo 以支持自适应采样的配置启动 Jaeger。
具体如下所示:
[leonli@192 ~] % less jaeger-docker-compose.yml
version: '2'
services:
hotrod:
image: jaegertracing/example-hotrod:latest
ports:
- '8080:8080'
- '8083:8083'
command: ["-m","prometheus","all"]
environment:
- JAEGER_AGENT_HOST=jaeger-agent
- JAEGER_AGENT_PORT=6831
- JAEGER_SAMPLER_TYPE=remote
- JAEGER_SAMPLING_ENDPOINT=http://jaeger-agent:5778/sampling
depends_on:
- jaeger-agent
jaeger-collector:
image: jaegertracing/jaeger-collector
command:
- "--cassandra.keyspace=jaeger_v1_dc1"
- "--cassandra.servers=cassandra"
- "--collector.zipkin.host-port=9411"
- "--sampling.initial-sampling-probability=.5"
- "--sampling.target-samples-per-second=.01"
environment:
- SAMPLING_CONFIG_TYPE=adaptive
ports:
- "14269:14269"
- "14268:14268"
- "14250"
- "9411:9411"
restart: on-failure
depends_on:
- cassandra-schema
jaeger-query:
image: jaegertracing/jaeger-query
command: ["--cassandra.keyspace=jaeger_v1_dc1", "--cassandra.servers=cassandra"]
ports:
- "16686:16686"
- "16687"
restart: on-failure
depends_on:
- cassandra-schema
jaeger-agent:
image: jaegertracing/jaeger-agent
command: ["--reporter.grpc.host-port=jaeger-collector:14250"]
ports:
- "5775:5775/udp"
- "6831:6831/udp"
- "6832:6832/udp"
- "5778:5778"
restart: on-failure
depends_on:
- jaeger-collector
cassandra:
image: cassandra:4.0
cassandra-schema:
image: jaegertracing/jaeger-cassandra-schema
depends_on:
- cassandra当然,自适应采样算法可以使用一些官方给定的相关参数来定义基于当前的业务场景需求,我们可以通过 “help” 命令进行自定义配置及启动,具体如下所示:
[leonli@192 ~] % docker run --rm \
-e SAMPLING_CONFIG_TYPE=adaptive \
jaegertracing/jaeger-collector:1.30 \
help | grep -e '--sampling.'
--sampling.aggregation-buckets int 要保存在内存中的历史数据量。(默认 10)
--sampling.buckets-for-calculation int 这决定了在计算加权 QPS 时使用了多少先前的数据,即。如果 BucketsForCalculation 为 1,则仅最新数据将用于计算加权 QPS。(默认 1)
--sampling.calculation-interval duration 计算新采样概率的频率。建议大于客户端的轮询间隔。(默认 1m0s)
--sampling.delay 持续时间确定最近的状态有多远。如果您想为聚合完成添加一些缓冲时间,请使用此选项。(默认 2m0s)
--sampling.delta-tolerance float 每秒观察到的样本与每秒所需(目标)样本之间可接受的偏差量,以比率表示。(默认 0.3)
--sampling.follower-lease-refresh-interval duration 如果此处理器是跟随者,则休眠的持续时间。(默认 1m0s)
--sampling.initial-sampling-probability float 所有新操作的初始采样概率。(默认 0.001)
--sampling.leader-lease-refresh-interval duration 如果此处理器被选为领导者,则在尝试更新领导者锁的租约之前休眠的持续时间。这应该小于 follower-lease-refresh-interval 以减少锁抖动。(默认 5s)
--sampling.min-samples-per-second float 每秒采样的最小跟踪数。(默认 0.016666666666666666)
--sampling.min-sampling-probability float 所有操作的最小采样概率。(默认 1e-05)
--sampling.target-samples-per-second float 每个操作的全局目标采样率。(默认 1)其实,在实际的业务场景中,我们往往期望有一些功能可以使自适应采样效果更好。
其一是能够计算跨度总数而非跟踪总数,不同的端点可能导致非常不同的迹线大小,甚至相差几个数量级。
然而,当前的实现仅围绕跟踪计数而构建。
它可以通过其他启发式方法进行扩展,例如离线计算每个端点的平均跟踪大小,并为自适应采样引擎提供权重矩阵,以便在计算实际吞吐量时加以考虑。
另一个不错的功能,实际上需要更改远程采样配置,是使用来自跟踪数据的其他维度,除了当前在模式中硬编码的服务名称和端点名称。
除此之外,还有一种配置机制,允许覆盖特定服务/端点的目标吞吐率 R,而不是使用单个全局参数,因为某些服务可能对我们的业务更重要,我们可能希望收集更多数据用于他们,或者可能是因一些查看而临时设置。
作为 Jaeger 社区发布第一个开源端到端的自适应采样实现版本,我们期望在后续的版本中,能够在以下几个方面获得改进:
1、支持 ElasticSearch / OpenSearch 作为存储自适应采样数据的后端。
2、解耦 Jaeger 存储配置,以便不同的存储后端可用于跨度存储和自适应采样。
玩转高性能日志库ZAP (6)-采样
前言
uber开源的高性能日志库zap, 除了性能远超logrus之外,还有很多诱人的功能,比如支持日志采样、支持通过HTTP服务动态调整日志级别。本文简单聊一下日志采样。
使用说明
Sampling:Sampling实现了日志的流控功能,或者叫采样配置,主要有两个配置参数,Initial和Thereafter,实现的效果是在1s的时间单位内,如果某个日志级别下同样内容的日志输出数量超过了Initial的数量,那么超过之后,每隔Thereafter的数量,才会再输出一次。是一个对日志输出的保护功能。
注意 这里画个重点
仅对"同样内容" 的日志做采样
默认1s的时间单位内
示例
package main
import (
"go.uber.org/zap"
)
func main() {
config := zap.NewProductionConfig()
// 默认值:Initial:100 Thereafter:100
config.Sampling = &zap.SamplingConfig{
Initial: 5, // 从第6条数据开始
Thereafter: 3, // 每3条打印一条
}
// 可以置为nil 来关闭采样
//config.Sampling = nil
config.Encoding = "console"
logger, _ := config.Build()
defer logger.Sync()
// 打印的消息要**重复**才会被执行采样动作
for i := 0; i s.first && (n-s.first)%s.thereafter != 0 {
return ce
}
return s.Core.Check(ent, ce)
}注意: 这里有个比较有意思的的地方是,zap使用消息的Hash值来判断内容是否重复
显然hash函数有一定的几率碰撞的,但是在较小的时间区间(默认1秒)的情况下,萌叔认为还是可以接受的。
func (cs *counters) get(lvl Level, key string) *counter {
i := lvl - _minLevel
j := fnv32a(key) % _countersPerLevel
return &cs[i][j]
}
// fnv32a, adapted from "hash/fnv", but without a []byte(string) alloc
func fnv32a(s string) uint32 {
const (
offset32 = 2166136261
prime32 = 16777619
)
hash := uint32(offset32)
for i := 0; i Github:
> Gitee:
# 小结
dubbo filter 模式非常的优雅,以前一直只是学习,没有将其应用到自己的项目中。
提供的便利性是非常强大的,值得学习运用。
# 参考资料
> [auto-log](https://github.com/houbb/auto-log)
自适应采样思维
https://mp.weixin.qq.com/s/Mu9ie-nSRYN-uU3jgcSxrg
https://mp.weixin.qq.com/s/B2ZJXf-WdiibSSU8ixEZKw
玩转高性能日志库ZAP (6)-采样: https://mp.weixin.qq.com/s/Busa7_R8GasBfLf4ehmSyA
利用哈希值判断是否重复
可以再添加一个长度的优先判断,减少哈希值计算的消耗。
如何自动淘汰这些数据?
如何保证日志完备性?
https://mp.weixin.qq.com/s/rxyuxScPUYML-f5FhgNBpw
http://www.cims-journal.cn/CN/10.13196/j.cims.2022.10.012
LogRank 采样技术
日志采样和存储
https://mp.weixin.qq.com/s/cgDzA0cvUQJETL_fa8gGSQ
6个开源日志工具
https://mp.weixin.qq.com/s/6KVzR3JQzTnXNNUwwcZIPw
日志演尽之旅
https://mp.weixin.qq.com/s/D9dUPQk4ghz86yL5BTcIUw
日志收集器
https://mp.weixin.qq.com/s/8mCVk3gvXPOijTlcRjUR_w