
NLP 可以做很多事情,可以非常的简单,但是效果却非常的好。
概率
SA 情感分析
文本分类
性别推断
垃圾邮件识别
基本语料(chinese-basic)
字
词
成语
相关基础工具
拼音
繁简体
形近字
词语拓展
同义词、近义词、反义词、否定词、停顿词
敏感词
【汉字拆字】
【汉字词语缩写】
应用
2020年1月20日大约 4 分钟
NLP 可以做很多事情,可以非常的简单,但是效果却非常的好。
SA 情感分析
文本分类
性别推断
垃圾邮件识别
字
词
成语
拼音
繁简体
形近字
同义词、近义词、反义词、否定词、停顿词
敏感词
【汉字拆字】
【汉字词语缩写】
我们知道声音实际上是一种波。
常见的mp3、wmv等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如Windows PCM文件,也就是俗称的wav文件。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。
下图是一个波形的示例。
语音是人类最自然的交互方式。
计算机发明之后,让机器能够“听懂”人类的语言,理解语言中的内在含义,并能做出正确的回答就成为了人们追求的目标。
我们都希望像科幻电影中那些智能先进的机器人助手一样,在与人进行语音交流时,让它听明白你在说什么。
语音识别技术将人类这一曾经的梦想变成了现实。
语音识别就好比“机器的听觉系统”,该技术让机器通过识别和理解,把语音信号转变为相应的文本或命令。
语音识别技术,也被称为自动语音识别Automatic Speech RecogniTIon,(ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。
如果你知道神经机器翻译是如何工作的,那么你可能会猜到,我们可以简单地将声音送入神经网络中,并训练使之生成文本:
一个大问题是语速不同。
一个人可能很快地说出「hello!」而另一个人可能会非常缓慢地说「heeeelllllllllllllooooo!」。
这产生了一个更长的声音文件,也产生了更多的数据。
这两个声音文件都应该被识别为完全相同的文本「hello!」而事实证明,把各种长度的音频文件自动对齐到一个固定长度的文本是很难的一件事情。
为了解决这个问题,我们必须使用一些特殊的技巧,并进行一些深度神经网络以外的特殊处理。让我们看看它是如何工作的吧!
声音是模拟信号,声音的时域波形只代表声压随时间变化的关系,不能很好的代表声音的特征,因此,必须将声音波形转换为声学特征向量。
目前有许多声音特征提取方法,如梅尔频率倒谱系数MFCC、线性预测倒谱系数LPCC、多媒体内容描述接口MPEG7等,其中MFCC是基于倒谱的,更符合人的听觉原理,因而是最普遍、最有效的声音特征提取算法。
在提取MFCC前,需要对声音做前期处理,包括模数转换、预加重和加窗。
模数转换就是把模拟信号转换为数字信号,包括两个步骤:采样和量化,即以一定的采样率和采样位数把声音连续波形转换为离散的数据点。
由于日常生活中的声音一般都在8kHz以下,根据Nyquist定律,16kHz采样率足以使得采样出来的数据包含大多数声音信息。
这这一篇博客中,将系统介绍中文文本分类的流程和相关算法。
先从文本挖掘的大背景开始,以文本分类算法为中心,介绍中文文本分类项目的流程以及相关知识,知识点涉及中文分词,向量空间模型,TF-IDF方法,几个典型的文本分类算法和评价指标等。
本篇主要有:
朴素的贝叶斯算法
KNN最近邻算法。
简单来说,文本挖掘就是从已知的大量文本数据中提取一些未知的最终可能用过的知识的过程,也就是从非结构化的文本中寻找知识的过程。
文本挖掘主要领域有:
将一篇文档分到其中一个或者多个类的过程,例 :判断分类出垃圾邮件
类型:包括类别数目(Binary、multi-class)、每篇文章赋予的标签数目(Single label、Multi label)
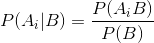
文本分类问题: 给定文档p(可能含有标题t),将文档分类为n个类别中的一个或多个
文本分类应用: 常见的有垃圾邮件识别,情感分析
文本分类方向: 主要有二分类,多分类,多标签分类
文本分类方法: 传统机器学习方法(贝叶斯,svm等),深度学习方法(fastText,TextCNN等)
本文的思路: 本文主要介绍文本分类的处理过程,主要哪些方法。致力让读者明白在处理文本分类问题时应该从什么方向入手,重点关注什么问题,对于不同的场景应该采用什么方法。
文本分类的处理大致分为文本预处理、文本特征提取、分类模型构建等。和英文文本处理分类相比,中文文本的预处理是关键技术。
笠翁对韵 全部韵脚系列
词库中优先使用
结合算法:无论这个算法是深度学习还是其他。
词库中的长词要想被使用,首先就需要对【上联】进行中文分词,然后查询词典,获取对应映射关系。
比如对联的训练集合有 70w 的对联,将这些数据都存储起来,显然不现实。
中文到英文的翻译有一些比较重要的作用:
作为基础的语料
作为后期翻译的字典
计算机相关命名等等。
使用已有的字典
结合相关列表,进行扩充(爬虫)
Free English to Chinese Dictionary Database 算是比较全的一个字典。