
Qoder 从长期记忆到自我进化
从长期记忆到自我进化
长期记忆让智能体能够自我学习。
在许多 AI 编码助手中,一个常见的痛点是 缺乏长期记忆。
每一次新会话都像从零开始——偏好、编码规范和历史记录都会被遗忘,迫使开发者不断重复解释和返工。
这不仅降低了开发效率,也削弱了 AI 作为协作伙伴的价值。
那么,如何突破无状态交互的限制,构建能够记忆、学习并与开发者共同进化的 AI 编码智能体呢?
为什么长期记忆很重要
传统的 AI 编码助手是“孤立运行”的,对用户和环境没有持久理解,这带来了几个关键问题:
- 缺乏个性化:无法记住你的编码风格、命名规范或工作习惯。
- 重复犯错:因为无法从过去的修正中学习,相同错误反复出现。
- 没有经验积累:每次交互都从零开始,没有连续性和上下文。
- 缺乏代码库意识:每次使用都要重新分析代码库,浪费时间和算力。
如果没有记忆,AI 只能是被动的工具,而不是主动的协作者。
长期记忆与自我优化
为了解决这些问题,我们引入了一个 长期记忆框架,使 AI 智能体能够随着时间推移保留、回忆和优化知识。
智能体会持续分析开发者的交互,提取有价值的洞见,并将其存储为语义笔记。当相关任务出现时,它会检索这些记忆来指导决策,从而提供更快、更精准、更个性化的帮助。
记忆被分为三类:
个人偏好
- 编码风格(缩进、命名规范)
- 工作习惯(例如“测试优先开发”)
- 用户自定义规则(如“完成任务后必须生成单元测试”)
历史经验
- 常见错误的解决方案
- 常见的排错步骤
- 构建和部署的指令
- 过去重构或调试的经验教训
项目知识
- 代码库结构和架构
- 技术栈与依赖关系概览
- API 文档与集成模式
这种结构化的记忆使得 AI 不仅依赖 Prompt,而是带着上下文去行动。
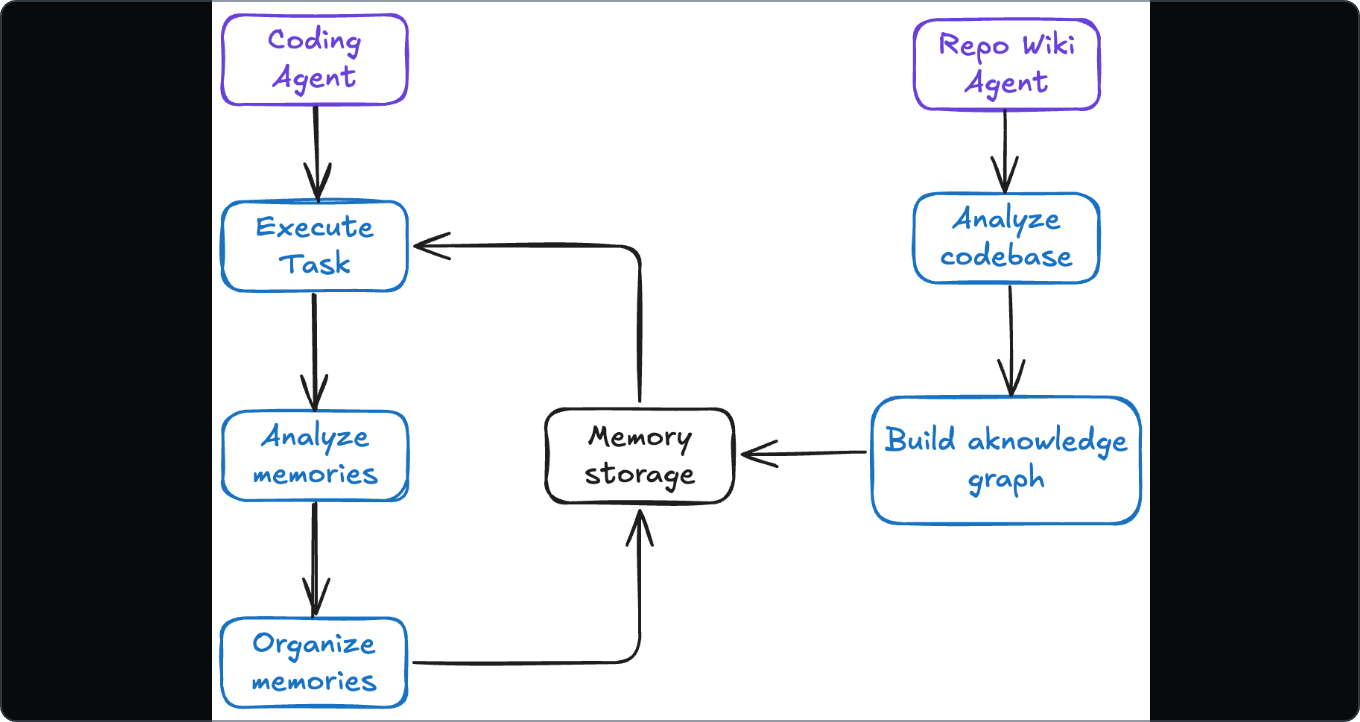
记忆提取与分析
记忆系统从多个来源收集信息,构建全面且动态更新的知识库:
- 用户查询:捕捉显式偏好和隐式任务描述模式。
- 智能体执行:记录命令、环境变化和结果,总结哪些有效、哪些无效。
- 项目结构与文档:分析代码、README 和配置文件,生成项目的语义地图。
通过整合这些输入,系统确保记忆既深度又可操作。
记忆评估
并非所有记忆都同等有价值。为保持质量,系统会基于以下标准评估每条记忆:
- 与未来任务的相关性
- 信息的准确性
- 对任务完成的影响力
每次任务完成后,智能体会评估回忆的记忆是否真正有帮助。价值低或过时的条目会被自动标记并移除,确保记忆库始终精简、准确、实用。
记忆组织
如果不加管理,记忆会很快碎片化、冗余化。为避免这种情况,系统会定期维护:
- 去重:合并相似或重复的记忆。
- 冲突解决:处理矛盾(如不同的风格偏好)。
- 遗忘机制:根据使用频率和时间移除过时信息。
持续的记忆组织让智能体的记忆库高效且一致,像一个维护良好的知识库。
完整的记忆循环
AI 智能体通过 回忆 → 执行 → 提取 → 评估 → 组织 的循环不断进化:
- 回忆:根据上下文(项目、任务、用户)检索相关记忆。
- 执行:利用检索到的知识完成任务。
- 提取:分析交互,识别新的洞见。
- 评估:衡量新记忆的价值与质量。
- 组织:去重、合并、清理存储。
随着时间推移,这个循环让智能体不断自我进化——变得更准确、更高效、更个性化。
效果
我们的内部评估显示,长期记忆系统显著提升了智能体效率,并减少了重复性错误。
未来展望
我们才刚刚开始探索自进化型 AI 助手的潜力。未来的增强包括:
- 持续的记忆优化:系统会学习哪些记忆最有效,并动态调整存储策略。
- 多维度知识图谱:借鉴人类记忆,将代码、对话、文档,甚至会议记录整合为统一知识图谱,实现更深层的推理与洞察。
结论
为 AI 编码助手赋予长期记忆和自我优化能力,我们就能超越“一次性代码生成”,实现 持续协作。
结果不仅是更快的编码,而是更聪明、更自适应的开发方式——AI 真正做到 向你学习、为你进化。
欢迎进入 自我进化 AI 助手的时代。