回顾
大家好,我是老马。
最近 dubbo3.x 在公司内部分享,于是想系统梳理一下。
总体思路是官方文档入门+一些场景的问题思考+源码解析学习。
https://cn.dubbo.apache.org/zh-cn/blog/2023/02/20/%E6%8C%87%E6%A0%87%E5%9F%8B%E7%82%B9/
应用级服务发现设计
Objective
- 显著降低服务发现过程的资源消耗,包括提升注册中心容量上限、降低消费端地址解析资源占用等,使得 Dubbo3 框架能够支持更大规模集群的服务治理,实现无限水平扩容。
- 适配底层基础设施服务发现模型,如 Kubernetes、Service Mesh 等。
Background
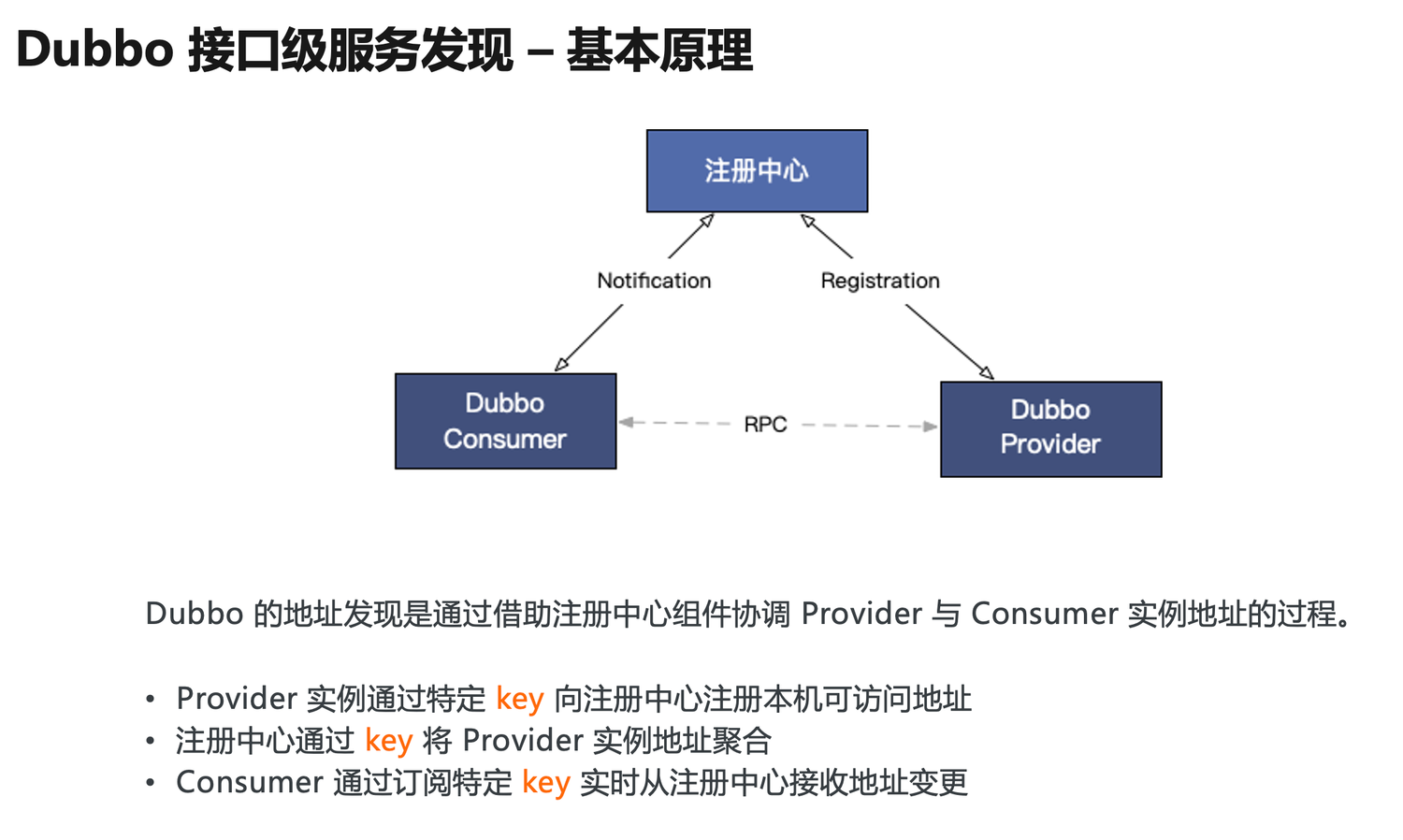
我们从 Dubbo 最经典的工作原理图说起,Dubbo 从设计之初就内置了服务地址发现的能力,Provider 注册地址到注册中心,Consumer 通过订阅实时获取注册中心的地址更新,在收到地址列表后,consumer 基于特定的负载均衡策略发起对 provider 的 RPC 调用。
在这个过程中:
- 每个 Provider 通过特定的 key 向注册中心注册本机可访问地址;
- 注册中心通过这个 key 对 provider 实例地址进行聚合;
- Consumer 通过同样的 key 从注册中心订阅,以便及时收到聚合后的地址列表;
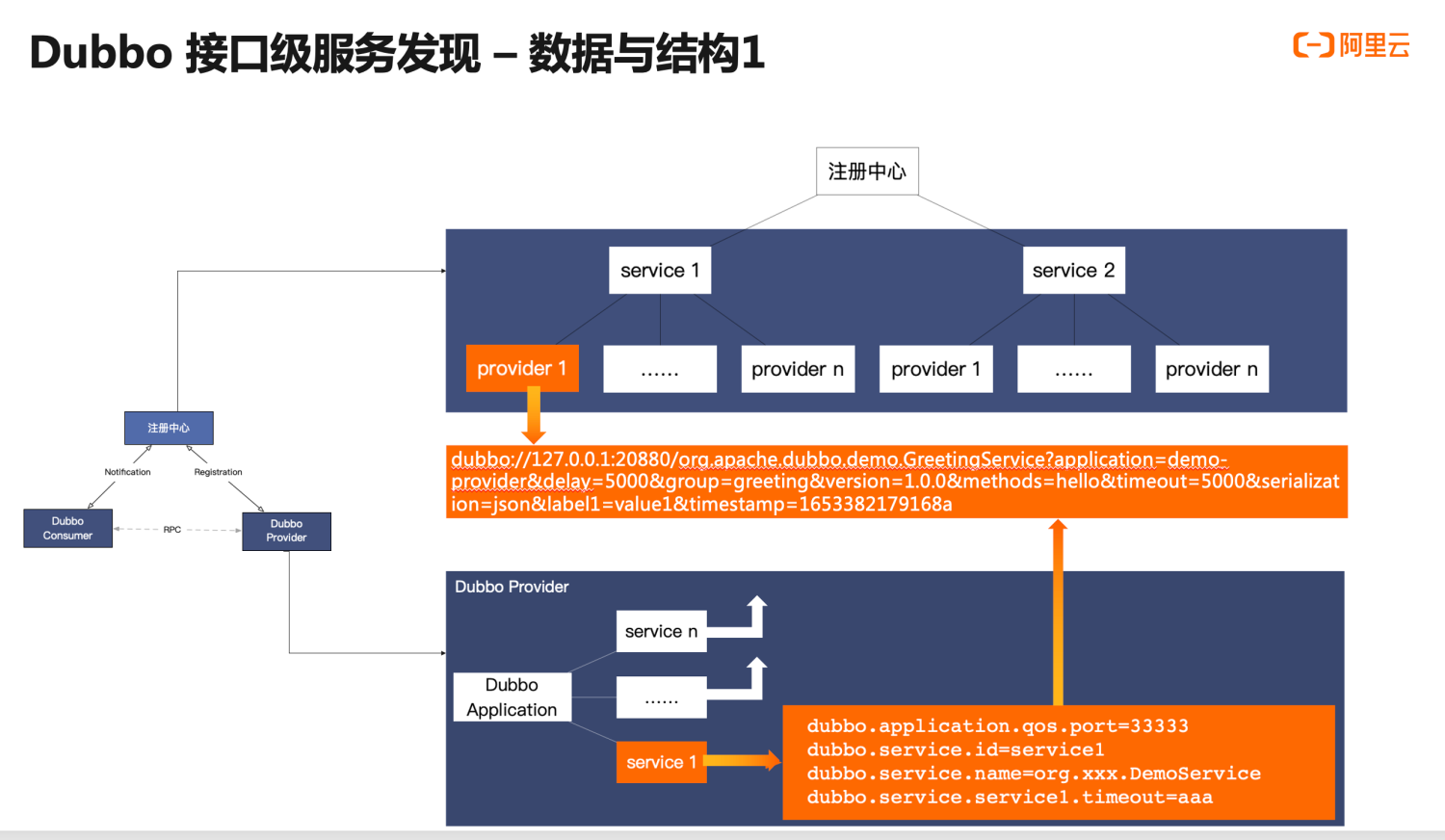
这里,我们对接口级地址发现的内部数据结构进行详细分析。
首先,看右下角 provider 实例内部的数据与行为。Provider 部署的应用中通常会有多个 Service,也就是 Dubbo2 中的服务,每个 service 都可能会有其独有的配置,我们所讲的 service 服务发布的过程,其实就是基于这个服务配置生成地址 URL 的过程,生成的地址数据如图所示;同样的,其他服务也都会生成地址。
然后,看一下注册中心的地址数据存储结构,注册中心以 service 服务名为数据划分依据,将一个服务下的所有地址数据都作为子节点进行聚合,子节点的内容就是实际可访问的ip地址,也就是我们 Dubbo 中 URL,格式就是刚才 provider 实例生成的。

这里把 URL 地址数据划分成了几份:
- 首先是实例可访问地址,主要信息包含 ip port,是消费端将基于这条数据生成 tcp 网络链接,作为后续 RPC 数据的传输载体
- 其次是 RPC 元数据,元数据用于定义和描述一次 RPC 请求,一方面表明这条地址数据是与某条具体的 RPC 服务有关的,它的版本号、分组以及方法相关信息,另一方面表明
- 下一部分是 RPC 配置数据,部分配置用于控制 RPC 调用的行为,还有一部分配置用于同步 Provider 进程实例的状态,典型的如超时时间、数据编码的序列化方式等。
- 最后一部分是自定义的元数据,这部分内容区别于以上框架预定义的各项配置,给了用户更大的灵活性,用户可任意扩展并添加自定义元数据,以进一步丰富实例状态。
结合以上两页对于 Dubbo2 接口级地址模型的分析,以及最开始的 Dubbo 基本原理图,我们可以得出这么几条结论:
- 第一,地址发现聚合的 key 就是 RPC 粒度的服务
- 第二,注册中心同步的数据不止包含地址,还包含了各种元数据以及配置
- 得益于 1 与 2,Dubbo 实现了支持应用、RPC 服务、方法粒度的服务治理能力
这就是一直以来 Dubbo2 在易用性、服务治理功能性、可扩展性上强于很多服务框架的真正原因。
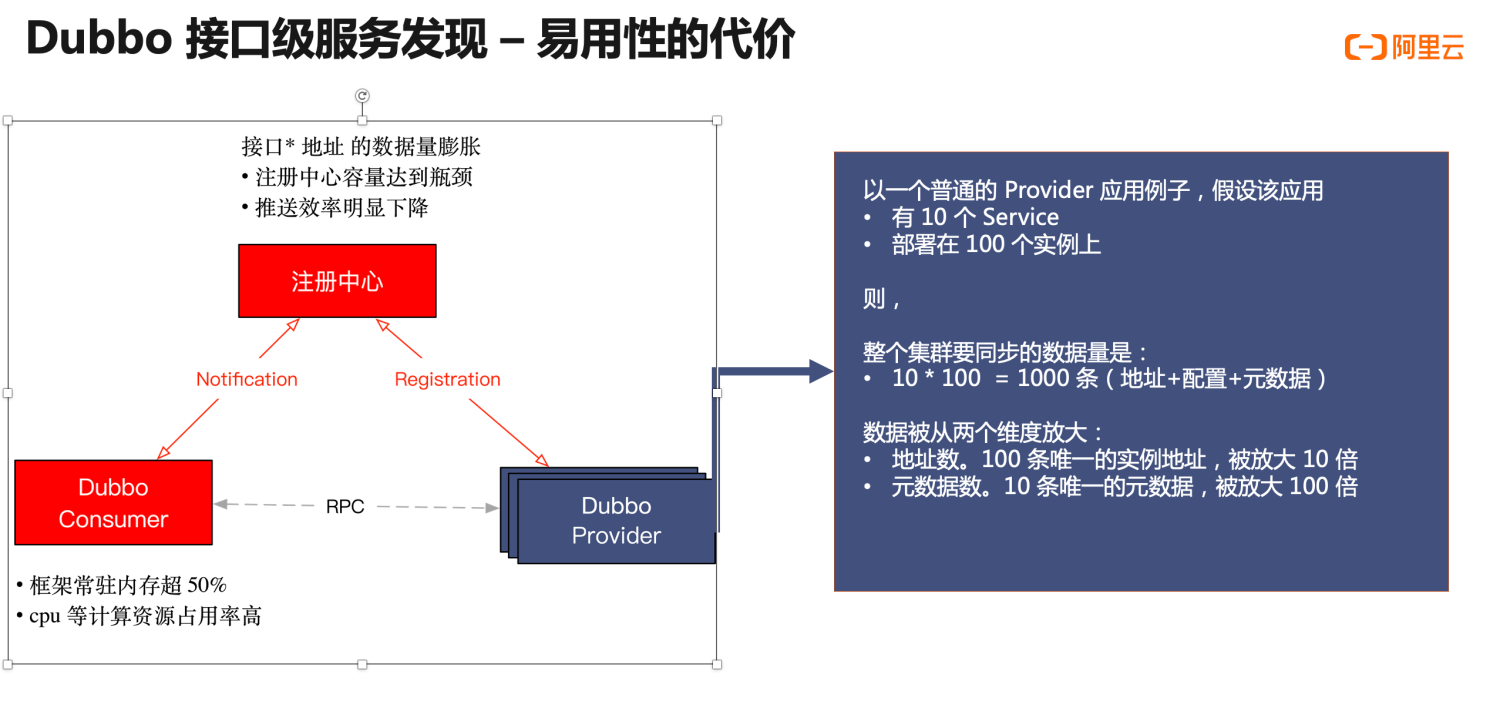
一个事物总是有其两面性,Dubbo2 地址模型带来易用性和强大功能的同时,也给整个架构的水平可扩展性带来了一些限制。这个问题在普通规模的微服务集群下是完全感知不到的,而随着集群规模的增长,当整个集群内应用、机器达到一定数量时,整个集群内的各个组件才开始遇到规模瓶颈。在总结包括阿里巴巴、工商银行等多个典型的用户在生产环境特点后,我们总结出以下两点突出问题(如图中红色所示):
- 首先,注册中心集群容量达到上限阈值。由于所有的 URL 地址数据都被发送到注册中心,注册中心的存储容量达到上限,推送效率也随之下降。
- 而在消费端这一侧,Dubbo2 框架常驻内存已超 40%,每次地址推送带来的 cpu 等资源消耗率也非常高,影响正常的业务调用。
为什么会出现这个问题?我们以一个具体 provider 示例进行展开,来尝试说明为何应用在接口级地址模型下容易遇到容量问题。 青蓝色部分,假设这里有一个普通的 Dubbo Provider 应用,该应用内部定义有 10 个 RPC Service,应用被部署在 100 个机器实例上。这个应用在集群中产生的数据量将会是 “Service 数 * 机器实例数”,也就是 10 * 100 = 1000 条。数据被从两个维度放大:
- 从地址角度。100 条唯一的实例地址,被放大 10 倍
- 从服务角度。10 条唯一的服务元数据,被放大 100 倍
Proposal
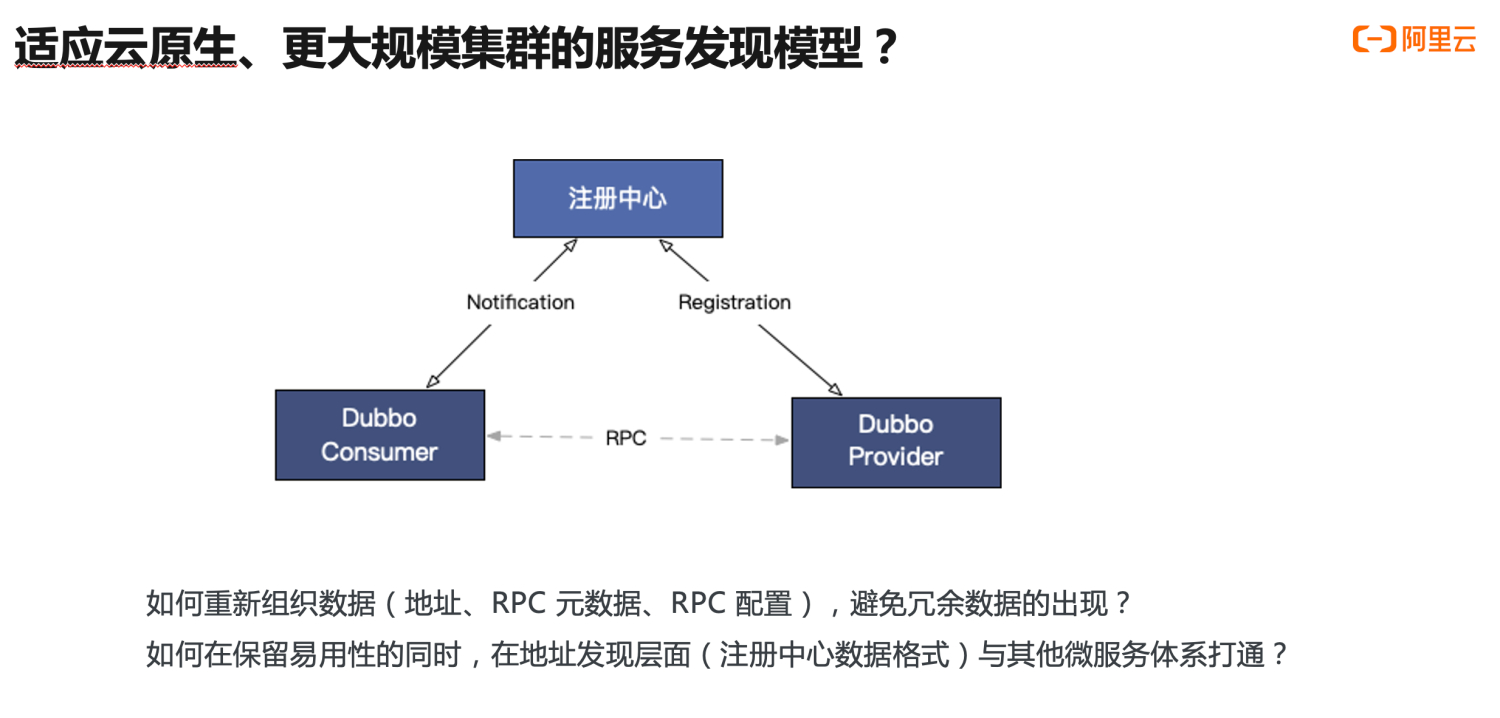
面对这个问题,在 Dubbo3 架构下,我们不得不重新思考两个问题:
- 如何在保留易用性、功能性的同时,重新组织 URL 地址数据,避免冗余数据的出现,让 Dubbo3 能支撑更大规模集群水平扩容?
- 如何在地址发现层面与其他的微服务体系如 Kubernetes、Spring Cloud 打通?

Dubbo3 的应用级服务发现方案设计本质上就是围绕以上两个问题展开。其基本思路是:地址发现链路上的聚合元素也就是我们之前提到的 Key 由服务调整为应用,这也是其名称叫做应用级服务发现的由来;另外,通过注册中心同步的数据内容上做了大幅精简,只保留最核心的 ip、port 地址数据。
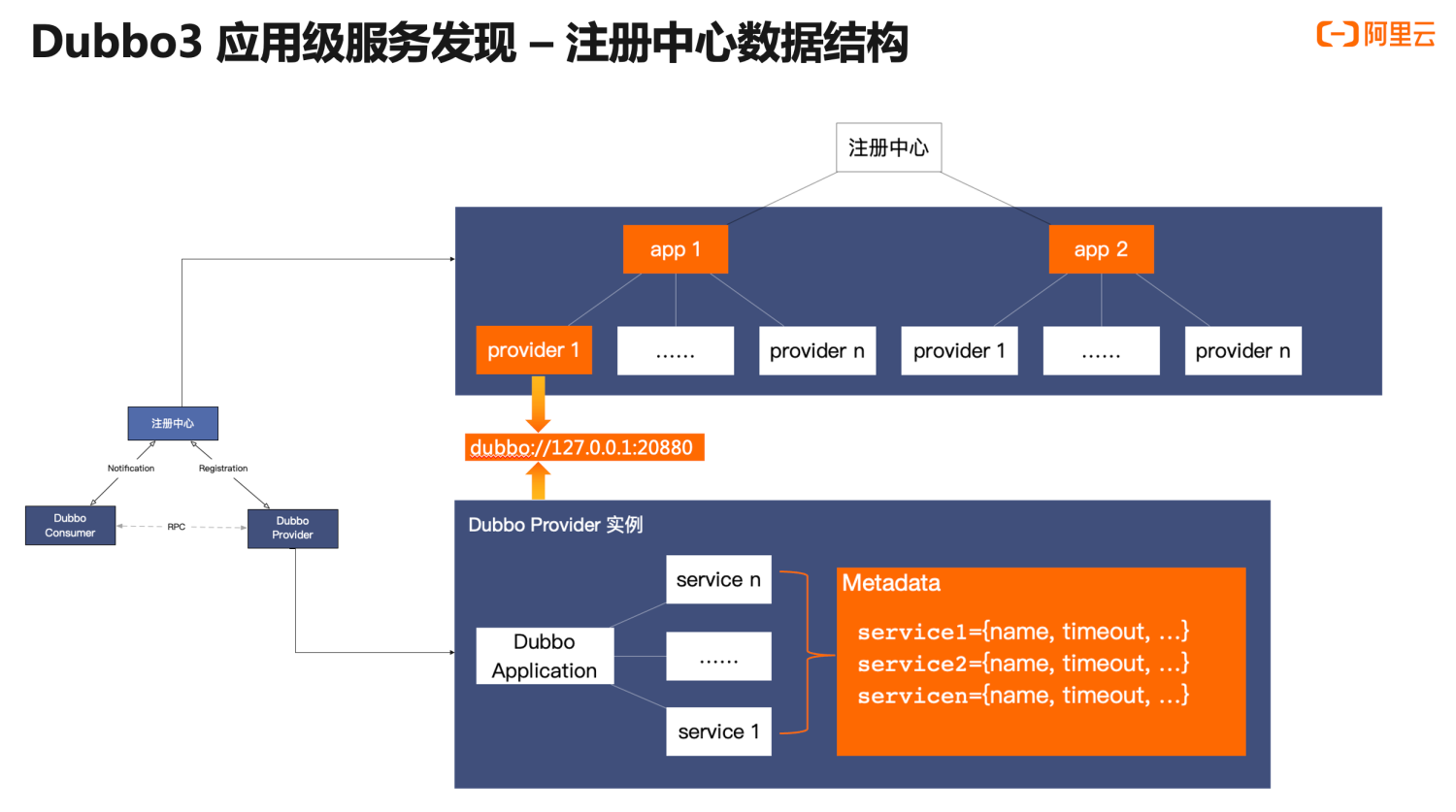
这是升级之后应用级地址发现的内部数据结构进行详细分析。 对比之前接口级的地址发现模型,我们主要关注橙色部分的变化。首先,在 provider 实例这一侧,相比于之前每个 RPC Service 注册一条地址数据,一个 provider 实例只会注册一条地址到注册中心;而在注册中心这一侧,地址以应用名为粒度做聚合,应用名节点下是精简过后的 provider 实例地址;

应用级服务发现的上述调整,同时实现了地址单条数据大小和总数量的下降,但同时也带来了新的挑战:我们之前 Dubbo2 强调的易用性和功能性的基础损失了,因为元数据的传输被精简掉了,如何精细的控制单个服务的行为变得无法实现。
针对这个问题,Dubbo3 的解法是引入一个内置的 MetadataService 元数据服务,由中心化推送转为 Consumer 到 Provider 的点对点拉取,在这个模式下,元数据传输的数据量将不在是一个问题,因此可以在元数据中扩展出更多的参数、暴露更多的治理数据。
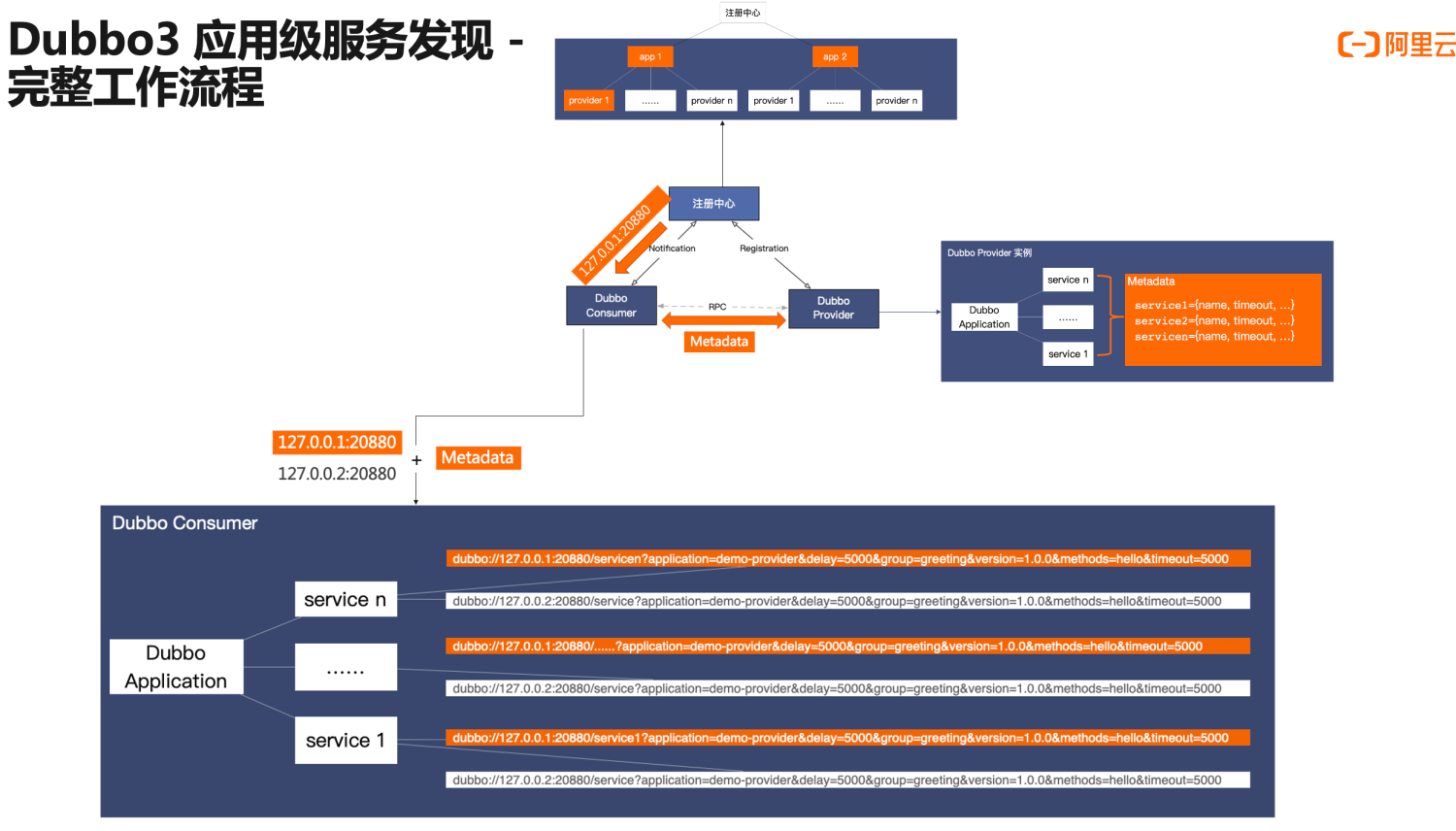
这里我们个重点看消费端 Consumer 的地址订阅行为,消费端从分两步读取地址数据,首先是从注册中心收到精简后的地址,随后通过调用 MetadataService 元数据服务,读取对端的元数据信息。在收到这两部分数据之后,消费端会完成地址数据的聚合,最终在运行态还原出类似 Dubbo2 的 URL 地址格式。因此从最终结果而言,应用级地址模型同时兼顾了地址传输层面的性能与运行层面的功能性。
以上就是的应用级服务发现背景、工作原理部分的所有内容,接下来我们看一下饿了么升级到 Dubbo3 尤其是应用级服务发现的过程。
chat
凡事都有两面性,dubbo3 这样设计,缺点是什么?
Dubbo3 应用级服务发现设计的局限性分析
Dubbo3 应用级服务发现通过地址模型重构和元数据分离解决了 Dubbo2 接口级模型的容量瓶颈,但其设计也存在多方面的权衡与局限性。
以下从架构复杂性、兼容性、运维成本、功能限制、性能隐患等角度展开分析,并结合实际案例说明影响:
一、架构复杂性显著增加
- 元数据服务成为核心依赖
Dubbo3 通过引入 MetadataService 将元数据从注册中心剥离,转为消费端主动拉取(点对点模式)。这一设计虽然减少了注册中心压力,但导致:- 强依赖链路:元数据服务的高可用性直接影响服务发现完整性。若 MetadataService 不可用,消费端无法获取完整的服务配置信息。
- 网络开销分散化:原本集中在注册中心的元数据推送压力转移为消费端与所有 Provider 的交互,大规模集群下可能产生海量点对点请求。
- 多组件协同维护成本
应用级模型需依赖元数据中心存储接口与应用的映射关系(如 Nacos 的dubbo/mapping目录),增加了以下运维负担:- 需独立维护元数据中心的可用性和数据一致性。
- 接口拆分或迁移时需手动更新映射关系,否则可能引发订阅冲突(如多个应用发布同一接口)。
二、兼容性与迁移成本问题
- 版本间协议不兼容
Dubbo3 应用级地址格式与 Dubbo2 接口级格式存在根本性差异,导致:- 跨版本调用阻断:Dubbo3 Provider 的地址无法被 Dubbo2 Consumer 识别,反之亦然,必须全集群升级。
- 双注册机制的副作用:默认开启的双注册模式(同时注册接口级和应用级地址)虽保障平滑过渡,但会短暂增加注册中心数据量,可能触发存储瓶颈。
- 配置迁移与适配成本
- 存量系统需重构服务发现逻辑,例如调整服务订阅粒度、适配 MetadataService 调用链。
- 部分治理规则需重新设计(如服务路由规则需从接口级调整为应用级)。
三、功能与治理能力的妥协
- 服务治理粒度受限
接口级模型支持方法级治理(如按方法设置超时、限流),而应用级模型以应用为最小治理单元,导致:- 精细控制能力下降:需通过 MetadataService 间接补充元数据,但动态更新效率低于注册中心推送。
- 治理规则适配困难:例如在 Kubernetes 中,Service 与应用绑定后,无法直接针对单个接口配置策略。
- 异构系统互通局限性
虽然应用级模型理论上支持与 Spring Cloud、Kubernetes Service 互通,但实际存在约束:- 协议差异:需额外适配 HTTP/JSON 与 Dubbo 序列化协议(如 Triple 协议)。
- 元数据不匹配:Spring Cloud 的 Eureka 元数据模型与 Dubbo MetadataService 字段需手动映射。
四、潜在性能隐患
- 冷启动延迟增加
消费端首次调用需先拉取应用级地址,再通过 MetadataService 获取元数据,导致:- 启动耗时延长:尤其在大规模集群中,初始化阶段的元数据拉取可能成为瓶颈。
- 首次调用失败率上升:若元数据未及时加载,可能触发超时异常。
- 大规模集群的扩展挑战
- 元数据服务压力:单个 Provider 的 MetadataService 需响应所有消费者的元数据请求,实例扩容时可能成为性能瓶颈。
- 地址聚合复杂度:消费端需本地合并应用级地址与元数据,内存占用虽降低,但 CPU 消耗可能因频繁解析而上升。
五、实际案例中的挑战(以饿了么升级为例)
根据阿里巴巴公开的迁移经验:
- 增量迁移风险:在逐步替换 Dubbo2 节点的过程中,曾出现因双注册机制导致地址混乱,触发局部服务不可用。
- 元数据一致性维护:部分历史接口因未及时更新元数据中心映射关系,导致消费端订阅到错误的应用实例。
- 治理规则重构成本:原有基于接口的熔断策略需全部调整为应用级,耗费大量测试资源验证有效性。
总结:设计权衡与应对建议
Dubbo3 应用级服务发现通过牺牲部分功能粒度和引入新组件,换取了容量扩展性与异构互通能力。
其缺点本质上是技术选型中的必然权衡。
对于采用者,建议:
- 评估集群规模:中小规模集群可能无需强制升级,优先利用 Dubbo2 的成熟性。
- 分阶段迁移:通过
dubbo.application.service-discovery.migration参数控制迁移节奏,避免全量切换风险。 - 强化监控:针对 MetadataService 和元数据中心设计独立监控指标,及时预警性能瓶颈。
- 预研异构互通场景:若需对接 Kubernetes 或 Spring Cloud,需提前验证协议兼容性与治理规则适配性。
(注:本文分析基于截至 2025-03-22 的公开技术文档与实践案例,实际局限性可能随版本迭代动态变化。)
参考资料
https://cn.dubbo.apache.org/zh-cn/blog/2023/01/30/dubbo3-%E5%BA%94%E7%94%A8%E7%BA%A7%E6%9C%8D%E5%8A%A1%E5%8F%91%E7%8E%B0%E8%AE%BE%E8%AE%A1/
