前言
https://github.com/cubefs/cubefs
DAOS
架构
DAOS(分布式异步对象存储)是一个开源的软件定义的可扩展对象存储系统,旨在为应用程序提供高带宽和高 IOPS 存储容器,并支持结合仿真、数据分析和机器学习的下一代数据中心工作流。
与传统存储堆栈(主要为旋转介质设计)不同,DAOS 从一开始就为新一代非易失性内存(NVM)技术设计,采用极简的架构,完全在用户空间内端到端(E2E)操作,实现全操作系统绕过。DAOS 提供了一种不同于块存储和高延迟存储的 I/O 模型,能够本质上支持细粒度数据访问并释放下一代存储技术的性能。
DAOS 是一个高性能、独立、容错的存储层,不依赖第三方层来管理元数据和数据的可靠性。
DAOS 特性
DAOS 依赖于开放的 fabric 接口(OFI)来实现低延迟通信,数据存储在存储类内存(SCM)和 NVMe 存储中。DAOS 提供一个原生的键-数组-值存储接口,并在其上端口了多种领域特定的数据模型,如 HDF5、MPI-IO 和 Apache Hadoop。DAOS 还提供了一个 POSIX I/O 模拟层,通过原生 DAOS API 实现文件和目录。
DAOS 的 I/O 操作首先记录到日志中,然后插入到存储在 SCM 中的持久索引中。每个 I/O 操作都标记有特定的时间戳(称为 epoch),并与数据集的特定版本相关联。内部不会执行读取-修改-写入操作。写操作是非破坏性的,且不受对齐的影响。在读取请求时,DAOS 服务会遍历持久索引,创建一个复杂的散布-收集远程直接内存访问(RDMA)描述符,从而直接在应用程序提供的缓冲区中重构数据。
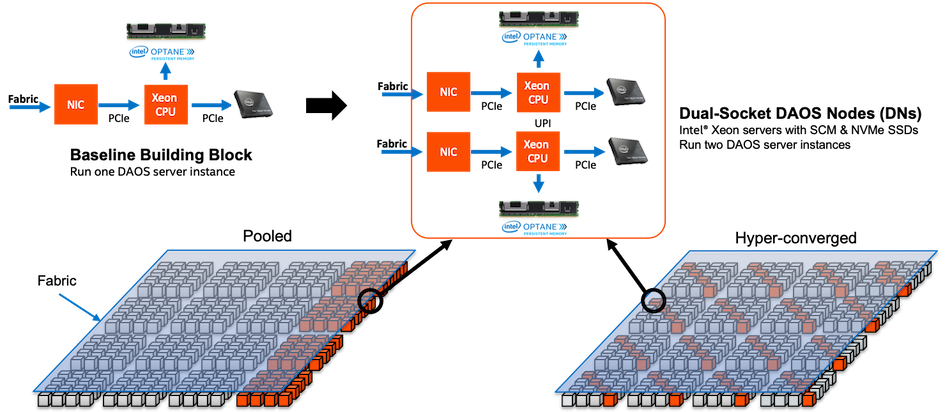
SCM 存储直接映射到 DAOS 服务的地址空间中,通过直接加载/存储管理持久索引。根据 I/O 特性,DAOS 服务可以决定将 I/O 存储在 SCM 或 NVMe 存储中。如图 2-1 所示,像应用程序元数据和字节级数据这样的低延迟 I/O 通常存储在前者中,而检查点和大数据则存储在后者中。这种方法通过将数据流式传输到 NVMe 存储并在 SCM 中保持内部元数据索引,允许 DAOS 为大数据提供原始 NVMe 带宽。持久内存开发工具包(PMDK)允许管理对 SCM 的事务访问,存储性能开发工具包(SPDK)支持用户空间 I/O 到 NVMe 设备。
图 2-1. DAOS 存储
DAOS 旨在提供:
- 高吞吐量和 IOPS,支持任意对齐和大小
- 细粒度 I/O 操作,真正的零拷贝 I/O 到 SCM
- 支持通过可扩展的集体通信在存储服务器之间进行大规模分布式 NVM 存储
- 非阻塞数据和元数据操作,允许 I/O 和计算重叠
- 高级数据放置,考虑故障域
- 软件管理的冗余,支持复制和纠删码,以及在线重建
- 端到端数据完整性
- 可扩展的分布式事务,保证数据一致性和自动恢复
- 数据集快照
- 安全框架,管理存储池的访问控制
- 软件定义存储管理,通过 COTS 硬件配置、修改和监控存储池
- 原生支持 HDF5、MPI-IO 和 POSIX 命名空间
- 灾难恢复工具
- 与 Lustre 并行文件系统的无缝集成
- 数据集迁移代理,支持在 DAOS 池之间以及 DAOS 和并行文件系统之间迁移数据集
DAOS 系统
一个数据中心可能有数十万个计算实例,通过可扩展的高性能网络互连,其中所有或一部分实例(称为存储节点)直接访问 NVM 存储。DAOS 的安装包含多个组件,这些组件可以是共置的或分布式的。
DAOS 系统通过系统名称来标识,由一组连接到相同网络的 DAOS 存储节点组成。每个 DAOS 存储节点运行一个 DAOS 服务器实例,并为每个物理插槽启动一个 DAOS 引擎进程。DAOS 服务器的成员信息记录在系统地图中,给每个引擎进程分配一个唯一的整数编号。两个不同的 DAOS 系统由两组不相交的 DAOS 服务器组成,且它们之间不进行协调。
DAOS 服务器是一个多租户守护进程,运行在每个存储节点的 Linux 实例(可以是物理节点上的本地实例,或在虚拟机或容器中运行)。其引擎子进程通过网络导出本地附加的 SCM 和 NVM 存储。它监听一个管理端口(由 IP 地址和 TCP 端口号指定),以及一个或多个 fabric 端点(通过网络 URI 指定)。DAOS 服务器通过 /etc/daos 中的 YAML 文件进行配置,包括其引擎子进程的配置。DAOS 服务器的启动可以与不同的守护进程管理或编排框架集成(例如 systemd 脚本、Kubernetes 服务,甚至通过并行启动器如 pdsh 或 srun)。
在 DAOS 引擎内部,存储被静态划分到多个目标上,以优化并发性。为了避免竞争,每个目标都有其私有存储、自己的服务线程池和专用的网络上下文,可以独立于同一存储节点上托管的其他目标,通过 fabric 直接访问。
SCM 模块配置为 AppDirect 交错模式。它们因此作为每个插槽的单个 PMem 名称空间呈现给操作系统(以 fsdax 模式)。
注意
当使用 dax 选项挂载 PMem 设备时,dmesg 中将记录以下警告:
EXT4-fs (pmem0): DAX enabled. Warning: EXPERIMENTAL, use at your own risk
此警告可以安全忽略:它的发出是因为 DAX 尚不支持 reflink 文件系统特性,但 DAOS 并未使用该特性。
当为每个引擎配置 N 个目标时,每个目标将使用该插槽 fsdax SCM 容量的 1/N,独立于其他目标。
每个目标还使用附加到该插槽的 NVMe 驱动器的 NVMe 容量的一部分。例如,在一个拥有 4 个 NVMe 磁盘和 16 个目标的引擎中,每个目标将管理 1/4 的单个 NVMe 磁盘。
一个目标没有实现任何内部数据保护机制以防止存储介质故障。因此,目标是单点故障,也是故障单元。每个目标关联一个动态状态:其状态可以是“运行中”或“关闭且不可用”。
目标是性能的单位。与目标相关的硬件组件,如后端存储介质、CPU 核心和网络,都具有有限的能力和容量。
DAOS 引擎实例导出的目标数量是可配置的,取决于底层硬件(特别是该引擎实例所服务的 SCM 模块数量和 NVMe SSD 数量)。作为最佳实践,引擎的目标数量应是所服务 NVMe 驱动器数量的整数倍。
SDK 和工具
应用程序、用户和管理员可以通过两种不同的客户端 API 与 DAOS 系统交互。管理 API 提供了管理 DAOS 系统的能力,并计划与供应商特定的存储管理和开源编排框架集成。dmg CLI 工具是建立在 DAOS 管理 API 之上的。另一方面,DAOS 库(libdaos)实现了 DAOS 存储模型,主要面向希望将数据集存储在 DAOS 系统中的应用程序和 I/O 中间件开发人员。像 daos 命令这样的用户工具也构建在该 API 上,以便用户通过 CLI 管理数据集。
应用程序可以直接通过原生 DAOS API、通过 I/O 中间件库(例如 POSIX 模拟、MPI-IO、HDF5)或通过已与 DAOS 存储模型集成的框架(如 Spark 或 TensorFlow)访问存储在 DAOS 中的数据集。
代理
DAOS 代理是驻留在客户端节点上的守护进程,负责与 DAOS 库交互以对应用程序进程进行身份验证。
它是一个受信任的实体,可以使用证书签署 DAOS 库凭证。该代理支持不同的身份验证框架,并通过 Unix域套接字与 DAOS 库通信。
参考资料
https://docs.daos.io/v2.6/overview/architecture/
