JsonIter
jsoniter(json-iterator)是一款快且灵活的 JSON 解析器,同时提供 Java 和 Go 两个版本。
从 dsljson 和 jsonparser 借鉴了大量代码。
性能对比
主流的 JSON 解析器是非常慢的。
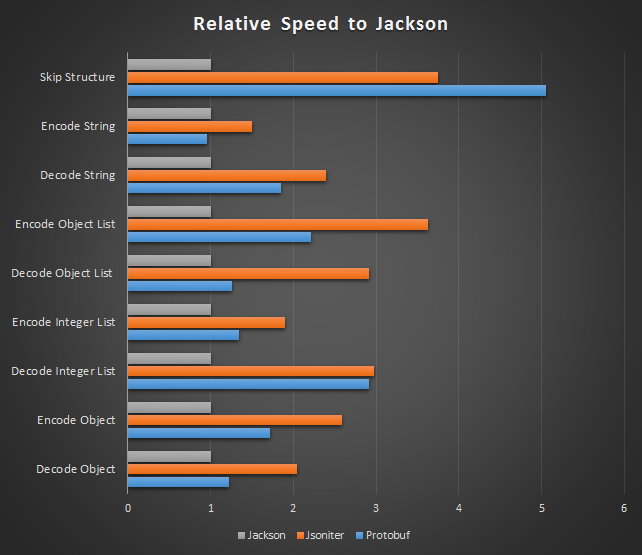
Jsoniter Java 版本可以比常用的 jackson/gson/fastjson 快 3 倍。
如果你需要处理大量的 JSON 格式的日志,你应该考虑一下用 dsl-json 或者 Jsoniter 来节约可观的成本。
根据 dsl-json 的性能评测,JSON 格式序列化和反序列化的速度其实一点都不慢,甚至比 thrift/avro 还要快。
噱头
实际作者也承认,比 fastjson 快多少,更多只是一个噱头。
更多的是 API 的设计,值得学习。
API 设计
目标
Jsoniter 的目标就是帮你把事搞定,越快越好。
最常见的用法只需要一行:
JsonStream.serialize(new int[]{1,2,3}); // from object to JSON
JsonIterator.deserialize("[1,2,3]", int[].class); // from JSON to object, with class specif
更进一步
如果这就是 Jsoniter 的一切本领,那么它不过是个平庸之辈而已。
然而 Jsoniter 源于作者使用现有解析器时的不满与愤怒,它绝不会别人的老路的。
想要体会到 Jsoniter 的独特体验能带来什么,我们来比较一下现有常规的 JSON API 的使用体验。
根据过去的老经验,你一定知道下面这种用法是效率很低而且笨拙的,但是有些时候又不得不这么用:
Map<String, Object> obj = deserialize(input);
Object firstItem = ((List<Object>)obj.get("items")).get(0);
想要最佳的性能以及代码工整,你最好定义一个类来指定数据的格式:
public class Order {
public List<OrderEntry> items;
}
Order order = deserialize(input, Order.class);
OrderEntry firstItem = obj.items.get(0);
在写正式的业务逻辑的代码时,这当然是很好的实践。
但是如果你只是想从一个JSON嵌套结构里取一个内部的字符串的值的时候,必须提前定义每层数据结构未免有点太费周章了。
能一行搞定的,就别费那么些话了:
Jsoniter.deserialize(input).get("items", 0); // the first item
Any 类型
deserialize 的返回值类型是“Any”,它有点类似于 Map<String, Object>。
两者都是通用的数据容器,但是和 Map<String, Object> 不同,Any 有通过 api 使得数据获取上更方便:
Any any = Jsoniter.deserialize(input); // deserialize 返回 "Any",实际的解析是延迟在读取时才做的
any.get("items", '*', "name", 0); // 抽取所有 items 的第一个 name
any.get("size").toLong(); // 不管是 "100" 还是 100,都给转成 long 类型,就像弱类型一样
any.bindTo(Order.class); // 把 JSON 绑定到对象
for (Any element : any) {} // 遍历集合,Any 实现了 iterable 接口
更好的消息是,这种 schema-less 的体验在延迟解析技术的帮助下,做到了性能上的无损。
所有没有必要读取的字段,仍然会以 JSON 的原始格式保留。
使用 Any 的性能要比使用 Map<String, Object> 好得多。
现在,在 Java 语言中,你也体会到 Javascript 或者 PHP 解析 JSON 时那种丝滑般体验。
JSON 与 any,乐趣多多。
Jsoniter 不仅仅在运行时要做最快的解析器,也同时非常努力地变成代码写起来最方便的解析器。
为什么这么快
Single pass scan
所有解析都是在字节数组流中直接在一次传递中完成的。
单程有两个含义:
在大规模:迭代器api只是前进,你从当前点获得你需要的。 没有回头路。
在微观尺度上:readInt或readString一次完成。
例如,解析整数不是通过剪切字符串,然后解析字符串来完成的。
相反,我们使用字节流直接计算int值。
甚至readFloat或readDouble都以这种方式实现,但有例外。
最低分配
通过一切必要手段避免复制。
例如,解析器有一个内部字节数组缓冲区,用于保存最近的字节。
在解析对象的字段名称时,我们不会分配新字节来保存字段名称。
相反,如果可能,缓冲区将重新用作切片。
Iterator实例本身保留了它使用的各种缓冲区的副本,并且可以通过使用新输入重置迭代器而不是创建全新迭代器来重用它们。
Pull from stream
输入可以是InputStream或io.Reader,我们不会将所有字节读入大数组。
相反,解析是以块的形式完成的。
当我们需要更多时,我们从流中拉出来。
Take string seriously
如果处理不当,字符串解析就是性能杀手。
我从jsonparser和dsljson学到的技巧是为没有转义字符的字符串采用快速路径。
对于golang,字符串是utf-8字节。
构造字符串的最快方法是从byte[]直接转换为字符串,如果可以确保byte[]不会消失或被修改。
对于java,字符串是基于utf-16 char的。
将utf8字节流解析为utf16 char数组是由解析器直接完成的,而不是使用UTF8字符集。
构造字符串的成本,简单地是char数组副本。
Schema based
与tokenizer api相比,Iterator api是主动的而不是被动的。
它不解析令牌,然后分支。
相反,在给定模式的情况下,我们确切地知道我们前面有什么,所以我们只是将它们解析为我们认为它应该是什么。
如果输入不一致,那么我们会提出正确的错误。
Skip takes different path
跳过一个对象或数组应该采用从jsonparser学到的不同路径。 当我们跳过整个对象时,我们不关心嵌套字段名称。
Table lookup
一些计算,例如char’5’的int值可以提前完成。
Java only optimization
Java 解析器是使用javassist动态生成的。
因为我们实际上正在生成真正的java源代码,所以生成器可以很容易地实现为静态注释处理器。
由于生成了源代码,我们不怕让它繁琐但具体:
public Object decode(java.lang.reflect.Type type, com.jsoniter.Jsoniter iter) {
com.jsoniter.SimpleObject obj = new com.jsoniter.SimpleObject();
for (com.jsoniter.Slice field = iter.readObjectAsSlice(); field != null; field = iter.readObjectAsSlice()) {
switch (field.len) {
case 6:
if (field.at(0)==102) {
if (field.at(1)==105) {
if (field.at(2)==101) {
if (field.at(3)==108) {
if (field.at(4)==100) {
if (field.at(5)==49) {
obj.field1 = iter.readString();
continue;
}
if (field.at(5)==50) {
obj.field2 = iter.readString();
continue;
}
}
}
}
}
}
break;
}
iter.skip();
}
return obj;
}
}
或者这样:
public Object decode(java.lang.reflect.Type type, com.jsoniter.Jsoniter iter) {
if (!iter.readArray()) {
return new int[0];
}
int a1 = iter.readInt();
if (!iter.readArray()) {
return new int[]{ a1 };
}
int a2 = iter.readInt();
if (!iter.readArray()) {
return new int[]{ a1, a2 };
}
int a3 = iter.readInt();
if (!iter.readArray()) {
return new int[]{ a1, a2, a3 };
}
int a4 = (int) iter.readInt();
int[] arr = new int[8];
arr[0] = a1;
arr[1] = a2;
arr[2] = a3;
arr[3] = a4;
int i = 4;
while (iter.readArray()) {
if (i == arr.length) {
int[] newArr = new int[arr.length * 2];
System.arraycopy(arr, 0, newArr, 0, arr.length);
arr = newArr;
}
arr[i++] = iter.readInt();
}
int[] result = new int[i];
System.arraycopy(arr, 0, result, 0, i);
return result;
}
}
