MVCC
Version 保存了当前磁盘以及内存中所有的文件信息,一般只有一个Version叫做”current” version(当前版本)。
Leveldb还保存了一系列的历史版本,这些历史版本有什么作用呢?
当一个Iterator创建后,Iterator就引用到了current version(当前版本),只要这个Iterator不被delete那么被Iterator引用的版本就会一直存活。
这就意味着当你用完一个Iterator后,需要及时删除它。
当一次Compaction结束后(会生成新的文件,合并前的文件需要删除),Leveldb会创建一个新的版本作为当前版本,原先的当前版本就会变为历史版本。
VersionSet 是所有Version的集合,管理着所有存活的Version。
VersionEdit 表示Version之间的变化,相当于delta 增量,表示有增加了多少文件,删除了文件。下图表示他们之间的关系。
Version0 +VersionEdit–>Version1
VersionEdit会保存到MANIFEST文件中,当做数据恢复时就会从MANIFEST文件中读出来重建数据。
leveldb的这种版本的控制,让我想到了双buffer切换,双buffer切换来自于图形学中,用于解决屏幕绘制时的闪屏问题,在服务器编程中也有用处。
比如我们的服务器上有一个字典库,每天我们需要更新这个字典库,我们可以新开一个buffer,将新的字典库加载到这个新buffer中,等到加载完毕,将字典的指针指向新的字典库。
leveldb的version管理和双buffer切换类似,但是如果原version被某个iterator引用,那么这个version会一直保持,直到没有被任何一个iterator引用,此时就可以删除这个version。
Iterable
看过leveldb代码的同学应该对Iterator这个词不陌生,代码中从基类继承出各种各样的Iterator,满眼看去全是Iterator,前期学习不免眼花缭乱,本篇对这些Iterator进行总结,通过捋清它们之间的关系来绘制出全局的Iterator实现
作用
为什么leveldb需要Iterator呢?我觉得主要用在两个地方:
-
对外:用在整个DB的迭代,暴露给用户NewIterator接口,方便用户进行整个DB的迭代
-
对内:用在Compact,需要一个Iterator可以对指定文件集合进行迭代从而完成Compact
全局图
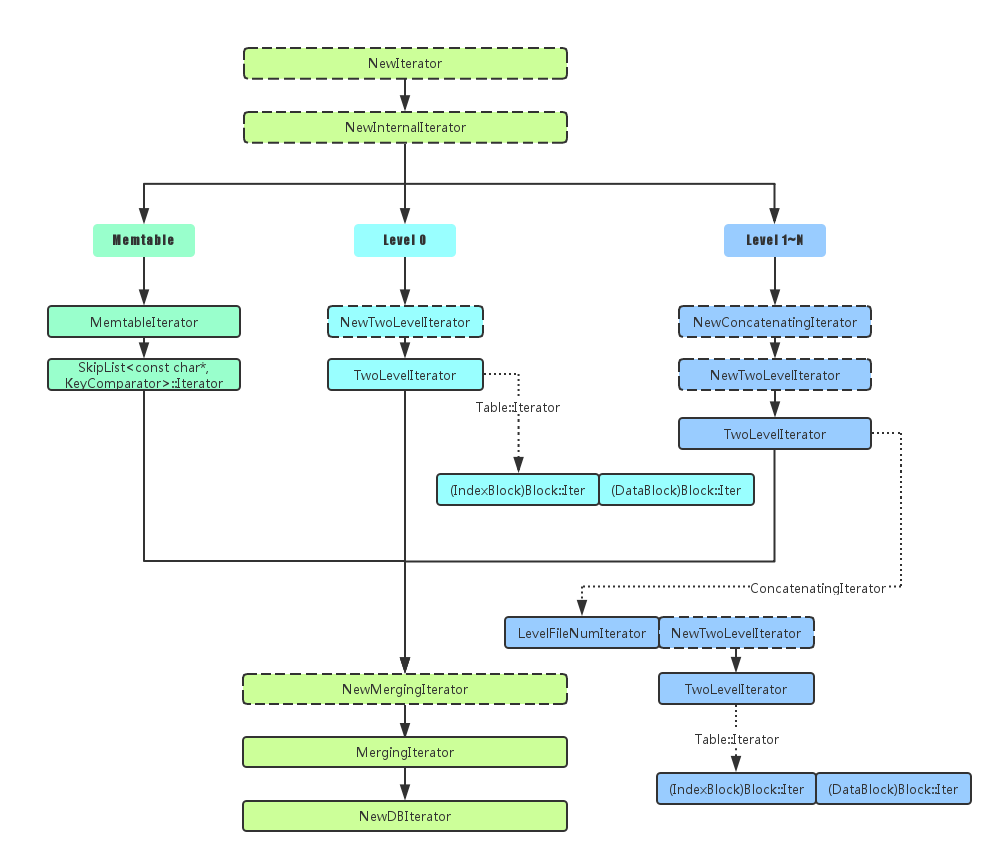
首先给出leveldb中主要Iterator的关系图,这个图是当用户调用NewIterator接口后的过程图, 其中虚线方块是调用接口名,实线方块则是各个Iterator了,先粗略看一下,结合下面的讲述, 再回过头来看这个图就能有更深的理解:
分类
按照它们的作用,我将它们分成两类,第一类是最底层的Iterator,它们直接和底层的数据结构打交道,在具体的数据结构上完成迭代,本篇称之为底层Iterator,第二类是基于底层封装而来,它们通过对底层Iterator进行封装,来完成符合leveldb特性相关的迭代,本篇称之为封装Iterator
底层Iterator:leveldb有3个底层Iterator,它们位于最底层,不依赖于其他Iterator,它们分别是MemtableIterator、Block::Iter及LevelFileNumIterator MemtableIterator:它负责完成对单个memtable或者immutable memtable的迭代,其实就是一个基于SkipList的迭代器
Block::Iter:每个sst文件(table)都包含若干Block,数据都存在于这些Block之中,Block::Iter则是基于Block的格式实现对Block的迭代
LevelFileNumIterator:leveldb每一层都包含许多sst文件,除level 0之外,其他每一层层内sst文件的keyrange互不覆盖,因此每层内的sst文件之间按keyrange有序保存在Version的std::vector<FileMetaData*> files_[config::kNumLevels]中,每层说白了就是一个vector,由于vector中的每个sst文件之间按keyrange有序,所以LevelFileNumIterator的Next和Prev的实现只需要简单的将vector中的index加1减1便可来完成有序sst文件的切换,Seek接口可以通过vector中每个sst的keyrange信息进行二分查找来确定目标key在哪个sst文件中,这个LevelFileNumIterator虽然是一个底层迭代器,但他没有对数据进行迭代,仅仅用作下面要讲的TwoLevelIterator的第一级迭代而已
封装Iterator:leveldb有3个封装迭代器,它们其实是对底层迭代器或封装迭代器进行的封装,来完成leveldb特性相关的迭代,它们分别是TwoLevelIterator、MergingIterator及NewDBIterator
TwoLevelIterator:顾名思义,它是一个两层迭代器,leveldb总共有两个TwoLevelIterator:
第一个称之为Table::Iterator,它是实现单个sst文件(table)内的迭代,sst文件包含若干Block,主要有DataBlock和IndexBlock,他们的结构一样只是存的内容不同,DataBlock里存的是真正的数据,而IndexBlock里存的是对sst文件中所有DataBlock的索引信息,如每个DataBlock在sst文件中的偏移及它里面最大的key,假设现在要对某个sst文件进行迭代器Seek操作,那么先通过对IndexBlock来建立一个底层迭代器Block::Iter,然后对这个Block::Iter进行seek操作,它会在IndexBlock中找到目标key所对应的DataBlock的索引信息,然后通过这个索引在sst文件指定偏移量读出对应的DataBlock,再对这个DataBlock建立一个底层迭代器Block::Iter,然后对这个Block::Iter进行seek操作,就可以在DataBlock中找到目标Key了,这样便完成了对单个sst文件的迭代器Seek操作;所以这里的TwoLevel指的是(Index)Block::Iter -> (Data)Block::Iter
第二个称之为ConcatenatingIterator,它主要是在对某一层内所有sst文件的迭代中用到,上面说过,除了level 0,其他层的sst文件keyrange互不覆盖并且层内文件间有序,这里就要用到上面讲的LevelFileNumeIterator了,同样,假设现在要对某层进行迭代器Seek操作,首先对该层所有的sst文件生成一个LevelFileNameIterator,然后调用它的Seek便可以找到目标key在本层哪个sst文件中,然后在对该sst建立一个上面说的Table::Iterator,对其Seek便可找在该sst文件中找到目标key;所以这里的TwoLevel指的是LevelFileNumIterator -> Table::Iterator,将后者展开,其实更像是一个__Three__LevelIterator:LevelFileNumIterator -> (Index)Block::Iter -> (Data)Block::Iter
MergingIterator:从名字便可看出它的主要作用是Merge,那么都Merge什么东西呢?要对整个DB进行迭代,首先少不了对memtable及每一层都进行迭代,memtable和immutable memtable的迭代可以通过底层迭代器MemtableIterator来完成,level 1及其以上层可以通过对每一层建立一个封装迭代器ConcatenatingIterator来完成,那level 0为什么不可以通过ConcatenatingIterator来迭代呢?原因是level 0是直接从immutable memtable Dump而来,该层每个sst之间的keyrange可能会有覆盖,所以对level 0不能像其他层一样通过一个ConcatenatingIterator来迭代,而是需要为该层每个sst文件单独建立各自的Table::Iterator来实现,所以一个MergingIterator包含:
1个对于memtable的MemtableIterator 1个对于immutable memtable的MemtableIterator level 0层对于每个__文件__各自的Table::Iterator level 1及其以上层对于每一__层__各自的ConcatenatingIterator 这里面每个Iterator内部自己都是有序的,那么MergingIterator的作用就是对这些Interator进行归并,类似于归并排序一样,来建立一个全局有序的Iterator,既然全局有序的Iterator都建立起来了,那么DB的迭代也就可以实现了,使用MergingIterator,简单概括如下:
Seek:对每个迭代器内部seek到目标key,然后通过比较每个迭代器此时的cur_key来确定哪个是目标key要的结果 Next:对每一个迭代器cur_key进行比较,然后对此时有最小cur_key的迭代器调用其自身Next,此时哪个迭代器对应的cur_key最小,这个cur_key就是Next的结果 Prev:对每一个迭代器cur_key进行比较,然后对此时有最大cur_key的迭代器调用其自身Prev,此时哪个迭代器对应的cur_key最大,这个cur_key就是Prev的结果 NewDBIterator:它是对MergingIterator做了封装,在Merge迭代的基础上完成对快照、Delete或重复写key的过滤等操作,是最终返回给用户使用的Iterator 好了,所有的Iterator说完了,这里再回过头去看上面的图,是不是清晰多了?
总结
Iterator在leveldb中还是很有分量的,学习它对于更好的理解leveldb及compact实现有很大帮助, 本篇是为了描绘各个Itertor关系,对底层迭代器(MemtableIterator和Block::Iter)的实现点到为止, 因为他们的实现涉及Memtable,Table及Block的实现,扩展开来又是很大的三块内容,这些以后有时间了再单写几篇来总结吧^^
