MySQL–DB实现分布式锁思路
无论是单机锁还是分布式锁,原理都是基于共享的数据,判断当前操作的行为。
对于单机则是共享RAM内存,对于集群则可以借助Redis,ZK,DB等第三方组件来实现。
Redis,ZK对分布式锁提供了很好的支持,基本上开箱即用,然而这些组件本身要高可用,系统也需要强依赖这些组件,额外增加了不少成本。
DB对于系统来说本身就默认为高可用组件,针对一些低频的业务使用DB实现分布式锁也是一个不错的解决方案,比如控制多机器下定时任务的起调,针对审批回调处理等,本文将给出DB实现分布式锁的一些场景以及解决方案,希望对你启发。
表设计
首先要明确DB在系统中仍然需要认为是最脆弱的一环,因此在设计时需要考虑压力问题,即能应用实现的逻辑就不要放到DB上实现,也就是尽量少使用DB提供的锁能力,如果是高并发业务则要避免使用DB锁,换成Redis等缓存锁更加有效。
如清单1所示,该表中唯一的约束为lock_name,timestamp,version三者组合主键,下文会利用这三者实现悲观锁,乐观锁等业务场景。
- 清单1: 分布式锁表结构
CREATE TABLE `lock` (
`lock_name` varchar(32) NOT NULL DEFAULT '' COMMENT '锁名称',
`resource` bigint(20) NOT NULL COMMENT '业务主键',
`version` int(5) NOT NULL COMMENT '版本',
`gmt_create` datetime NOT NULL COMMENT '生成时间',
PRIMARY KEY (`lock_name`,`resource`,`version`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
悲观锁实现
对于悲观锁业务中常见的操作有以下两种:
针对A:
A场景当一台机器获取到锁后,其他机器处于排队状态,锁释放后其他机器才能够继续下去,这种应用层面解决是相当麻烦,因此一般使用DB提供的行锁能力,即select xxx from xxx for update。
A场景一般都和业务强关联,比如库存增减,使用业务对象作为行锁即可。
需要注意的是,该方案本质上锁压力还是在数据库上,当阻塞住的线程过多,且操作耗时,最后会出现大量锁超时现象。
针对B:
针对B场景(tryLock)举个具体业务,在集群下每台机器都有定时任务,但是业务上要求同一时刻只能有一台能正常调度。
解决思路是利用唯一主键约束,插入一条针对TaskA的记录,版本则默认为1,插入成功的算获取到锁,继续执行业务操作。这种方案当机器挂掉就会出现死锁,因此还需要有一个定时任务,定时清理已经过期的锁,清理维度可以根据lock_name设置不同时间清理策略。
定时任务清理策略会额外带来复杂度,假设机器A获取到了锁,但由于CPU资源紧张,导致处理变慢,此时锁被定时任务释放,因此机器B也会获取到锁,那么此时就出现同一时刻两台机器同时持有锁的现象,解决思路:把超时时间设置为远大于业务处理时间,或者增加版本机制改成乐观锁。
insert into lock set lock_name='TaskA' , resource='锁住的业务',version=1,gmt_create=now()
success: 获取到锁
failed:放弃操作
释放锁
悲观锁思想
除了可以通过增删操作数据库表中的记录以外,我们还可以借助数据库中自带的锁来实现分布式锁。
在查询语句后面增加FOR UPDATE,数据库会在查询过程中给数据库表增加悲观锁,也称排他锁。当某条记录被加上悲观锁之后,其它线程也就无法再该行上增加悲观锁。
在使用悲观锁的同时,我们需要注意一下锁的级别。
MySQL InnoDB引起在加锁的时候,只有明确地指定主键(或索引)的才会执行行锁 (只锁住被选取的数据),否则MySQL 将会执行表锁(将整个数据表单给锁住)。
在使用悲观锁时,我们必须关闭MySQL数据库的自动提交属性(参考下面的示例),因为MySQL默认使用autocommit模式,也就是说,当你执行一个更新操作后,MySQL会立刻将结果进行提交。
mysql> SET AUTOCOMMIT = 0;
Query OK, 0 rows affected (0.00 sec)
这样在使用FOR UPDATE获得锁之后可以执行相应的业务逻辑,执行完之后再使用COMMIT来释放锁。
我们不妨沿用前面的database_lock表来具体表述一下用法。假设有一线程A需要获得锁并执行相应的操作,那么它的具体步骤如下:
STEP1 - 获取锁:SELECT * FROM database_lock WHERE id = 1 FOR UPDATE; STEP2 - 执行业务逻辑; STEP3 - 释放锁:COMMIT。
如果另一个线程B在线程A释放锁之前执行STEP1,那么它会被阻塞,直至线程A释放锁之后才能继续。注意,如果线程A长时间未释放锁,那么线程B会报错,参考如下(lock wait time可以通过innodb_lock_wait_timeout来进行配置):
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
上面的示例中演示了指定主键并且能查询到数据的过程(触发行锁),如果查不到数据那么也就无从“锁”起了。
如果未指定主键(或者索引)且能查询到数据,那么就会触发表锁,比如STEP1改为执行以下两种情况,都会触发表锁:
SELECT * FROM database_lock WHERE description='lock' FOR UPDATE;
或者
SELECT * FROM database_lock WHERE id>0 FOR UPDATE;
在悲观锁中,每一次行数据的访问都是独占的,只有当正在访问该行数据的请求事务提交以后,其他请求才能依次访问该数据,否则将阻塞等待锁的获取。
悲观锁可以严格保证数据访问的安全。但是缺点也明显,即每次请求都会额外产生加锁的开销且未获取到锁的请求将会阻塞等待锁的获取,在高并发环境下,容易造成大量请求阻塞,影响系统可用性。
另外,悲观锁使用不当还可能产生死锁的情况。
乐观锁实现
针对乐观锁场景,举个具体业务,在后台系统中经常使用大json扩展字段存储业务属性,在涉及部分更新时,需要先查询出来,合并数据,写入到DB,这个过程中如果存在并发,则很容易造成数据丢失,因此需要使用锁来保证数据一致性,相应操作如下所示,针对乐观锁,不存在死锁,因此这里直接存放业务id字段,保证每一个业务id有一条对应的记录,并且不需要对应的定时器清除。
select * from lock where lock_name='业务名称', resource='业务id';
不存在: insert into lock set lock_name='业务名称', resource='业务id' , version=1;
获取版本: version
业务操作: 取数据,合并数据,写回数据
写回到DB: update lock set version=version+1 where lock_name='业务名称' and resource='业务id' and version= #{version};
写回成功: 操作成功
写回失败: 回滚事务,从头操作
乐观锁写入失败会回滚整个事务,因此如果写入冲突很频繁的场景不适合使用乐观锁,大量的事务回滚会给DB巨大压力,最终影响到具体业务系统。
乐观锁思想
顾名思义,系统认为数据的更新在大多数情况下是不会产生冲突的,只在数据库更新操作提交的时候才对数据作冲突检测。如果检测的结果出现了与预期数据不一致的情况,则返回失败信息。
乐观锁大多数是基于数据版本(version)的记录机制实现的。何谓数据版本号?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表添加一个 “version”字段来实现读取出数据时,将此版本号一同读出,之后更新时,对此版本号加1。
在更新过程中,会对版本号进行比较,如果是一致的,没有发生改变,则会成功执行本次操作;如果版本号不一致,则会更新失败。
为了更好的理解数据库乐观锁在实际项目中的使用,这里就列举一个典型的电商库存的例子。
一个电商平台都会存在商品的库存,当用户进行购买的时候就会对库存进行操作(库存减1代表已经卖出了一件)。
我们将这个库存模型用下面的一张表optimistic_lock来表述,参考如下:
CREATE TABLE `optimistic_lock` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`resource` int NOT NULL COMMENT '锁定的资源',
`version` int NOT NULL COMMENT '版本信息',
`created_at` datetime COMMENT '创建时间',
`updated_at` datetime COMMENT '更新时间',
`deleted_at` datetime COMMENT '删除时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uiq_idx_resource` (`resource`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='数据库分布式锁表';
在使用乐观锁之前要确保表中有相应的数据(如果没有此资源则可变相说明是无锁状态,可以进行插入操作,插入成功则代表获取锁成功),比如:
INSERT INTO optimistic_lock(resource, version, created_at, updated_at) VALUES(20, 1, CURTIME(), CURTIME());
如果只是一个线程进行操作,数据库本身就能保证操作的正确性。主要步骤如下:
STEP1 - 获取资源:SELECT resource FROM optimistic_lock WHERE id = 1; STEP2 - 执行业务逻辑; STEP3 - 更新资源:UPDATE optimistic_lock SET resource = resource -1 WHERE id = 1。
然而在并发的情况下就会产生一些意想不到的问题:比如两个线程同时购买一件商品,在数据库层面实际操作应该是库存(resource)减2,但是由于是高并发的情况,第一个线程执行之后(执行了STEP1、STEP2但是还没有完成STEP3),第二个线程在购买相同的商品(执行STEP1),此时查询出的库存并没有完成减1的动作,那么最终会导致2个线程购买的商品却出现库存只减1的情况。
在引入了version字段之后,那么具体的操作就会演变成下面的内容:
STEP1 - 获取资源: SELECT resource, version FROM optimistic_lock WHERE id = 1; STEP2 - 执行业务逻辑; STEP3 - 更新资源:UPDATE optimistic_lock SET resource = resource -1, version = version + 1 WHERE id = 1 AND version = oldVersion。
乐观锁的优点比较明显,由于在检测数据冲突时并不依赖数据库本身的锁机制,不会影响请求的性能,当产生并发且并发量较小的时候只有少部分请求会失败。
缺点是需要对表的设计增加额外的字段,增加了数据库的冗余,另外,当应用并发量高的时候,version值在频繁变化,则会导致大量请求失败,影响系统的可用性。
我们通过上述sql语句还可以看到,数据库锁都是作用于同一行数据记录上,这就导致一个明显的缺点,在一些特殊场景,如大促、秒杀等活动开展的时候,大量的请求同时请求同一条记录的行锁,会对数据库产生很大的写压力。
所以综合数据库乐观锁的优缺点,乐观锁比较适合并发量不高,并且写操作不频繁的场景。
总结
分布式锁的原理实际上很容易理解,难的是如何在具体业务场景上选择最合适的方案。
无论是哪一种锁方案都是与业务密切关联,总之没有完美的分布式锁方案,只有最适合当前业务的锁方案。
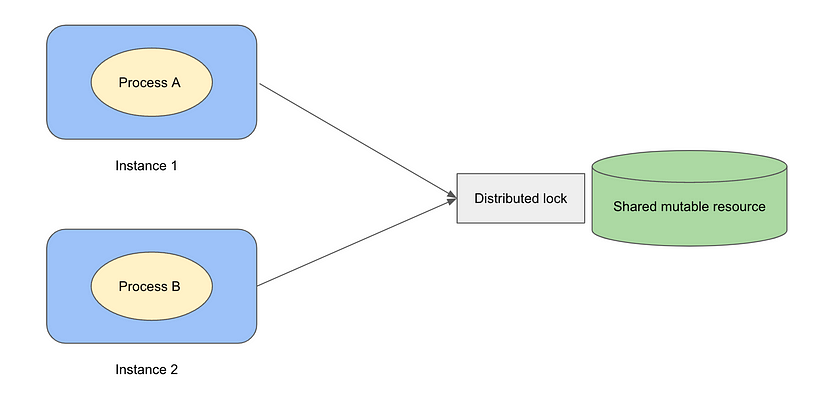
为什么我们需要分布式锁?
我们中的许多人可能遇到或听说过这些问题:
重试导致的数据损坏:从程序UI提交数据,该程序用户界面在你看不见的地方将数据插入后端MySQL数据库。偶尔用户界面没有响应,因此用户单击了几次提交按钮,这损坏了数据库中的数据。 缓存过期:使用Redis作为读透缓存,缓存中的密钥都同时过期。然后,所有流量都击中底层MySQL,该MySQL无法处理如此高的负载,并返回超时错误。 幽灵库存:假设我们是电子商务卖家,我们的库存中总共有4部iPhone。爱丽丝提交了购买3部iPhone的订单,鲍勃也订购了2部iPhone。理论上,只有第一个订单应该成功,第二个订单应该因为库存不足而失败。然而,实际上,两个用户都可能看到一个用户界面,显示大约同时还剩下4部iPhone并提交了订单,但实际上,第二个订单成功了,而第一个订单失败,或者更糟糕的是,两个订单都成功了,订购了5部 iPhone!
所有这些问题都有一个共同的特点:多个用户试图在同一时间读取/更新同一资源。如果我们所有的服务和数据库都在一台大型整体超级计算机上运行,我们可以使用通常与编程语言一起附带的锁或互斥来序列化任何并发读/写操作。例如,Java中的synchronized关键字和ReentrantLock,或在Go中sync包。
然而,分布式系统通常在数千台机器上运行数十个微服务,我们需要协调许多机器的读/写。这就是分布式锁的用途。
分布式锁的设计目标
锁定实体的存储
单台机器上的静音或锁定通常带有编程语言本身或广泛使用的库。在自然界中,它们在内存中作为整数实现。
例如,Go中的Mutex和RWMutex使用不同的整数来指示不同的锁状态。由于分布式系统不共享内存,我们需要将此表示锁定状态的整数存储在存储中间件中。
分布式锁常用的存储中间件是:
-
MySQL
-
Redis
-
ZooKeeper
-
ETCD
你可以看到分布式锁没有魔力,因为它们也使用相同的熟悉数据存储系统,如MySQL、Redis等。
现在,让我们深入了解设计细节,特别是如何在这些不同的存储系统之上构建分布式锁,以及权衡和区别是什么。
功能要求
1) 相互排斥。
必要时,不同机器上许多进程/线程中只有一个可以访问特定资源,其他进程/线程应该等到锁被释放并可用。
2) TTL或租赁机制。
提供分布式锁和其他请求分布式锁定的服务位于许多不同的机器上。这些服务通过网络进行通信。从CAP理论来看,我们知道网络总是不可靠,任何服务器都可能停机一段时间。因此,当我们设计分布式锁定服务时,我们需要考虑持有锁的客户端可能关闭并且无法释放锁的可能性,从而阻止了等待获得相同锁的所有其他客户端。因此,我们需要一个“上帝”机制,在这种情况下可以自动释放锁,以解除对其他客户端的封锁。
3) 锁定服务的API:
锁定:获取锁定
解锁:松开锁
TryLock(可选)。例如,更高级的API:客户端可以指定获取锁的最大等待时间。如果无法在窗口内获得锁定,请返回时出现错误,而不是继续等待。
4) 高性能。
低延迟:在正常情况下,锁定和解锁应该会很快。例如,假设实际的业务逻辑只需要1ms来处理,但只需在处理每个请求时简单地获取和释放锁,只需再获得100ms,那么最大QPS只能达到10,这对于当今标准中的许多服务来说都非常低。在这种情况下,服务器可以处理的最大QPS受到锁定性能的限制。
通知机制:分布式锁最好提供通知机制。如果服务器进程A由于被另一个服务器进程B持有而无法获得锁,那么A不应该继续等待并占用CPU。相反,A应该闲置,以避免浪费CPU周期。然后,当锁可用时,锁服务会通知A,A将加载到CPU并恢复运行。
避免雷鸣般的牛群。假设有100个进程想要获得相同的锁。当锁可用时,理想情况下,只应通知排队的“下一个”进程,而不是突然调用所有100个进程来竞争锁,结果发现100个进程中有1个可以获得锁并继续,而其他99个需要回到他们之前正在做的事情。
5) 公平。
先到先得。无论谁等了最久,接下来都应该拿到锁。如果是这样,锁被视为公平的锁。
否则,这是一把不公平的锁。这两种类型的锁实际上都在现实中使用(嗯,生活不公平🤔)
6) 重新进入锁。
想象一下,一个节点或服务器进程获得了锁,开始处理业务逻辑,然后遇到了一个代码片段,要求再次获得相同的锁!
在这种情况下,节点或进程不应该死锁,相反,它应该能够再次获得相同的锁,因为它已经持有锁。
使用MySQL的分布式锁
在实际生产环境中,MySQL通常在RC(已读提交)隔离级别配置。因此,我们随后的讨论将侧重于RC,而不是RR(可重复阅读)。
实施 1. 使用唯一的密钥约束
MySQL允许创建对键或索引具有唯一密钥约束的表。我们可以使用此内置的唯一性约束来实现分布式锁。
假设我们在MySQL中创建了一个名为lock的表,那么分布式锁的代码路径应该是:
客户端A正试图获得锁。目前没有其他客户端持有锁,因此客户端A成功获得了锁,并将一行插入MySQLlock表中。
现在客户端B想要获得相同的锁。它首先查询数据库,并发现客户端A插入的行已经存在。在这种情况下,客户端B无法获取锁,并将返回错误。
然后,客户端B将等待一段时间并重试。通常,我们将在这里使用带有TTL的重试循环。
客户端B将在指定的TTL窗口内继续重试几次,最终要么在客户端A释放锁后成功获取锁,要么因TTL而失败。
一旦客户端A完成任务,它只需删除DBlock表中的行即可释放锁。现在,其他客户可以获得锁。
以下是SQL片段示例,用于在lock_key列上创建一个名为lock的具有唯一密钥约束的表:
CREATE TABLE `lock` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`lock_key` varchar(256) NOT NULL,
`holder` varchar(256) NOT NULL,
`creation_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_lock_key` (`lock_key`)
);
在上面的SQL中,
lock_key是锁的唯一名称。我们可以在这里使用任何字符串。
例如,我们可以使用串联字符串project_name + resource_id作为锁的名称。命名应该一致,并给出足够的粒度。
持有人:当前持有锁的客户端的ID。例如,我们可以使用串联字符串service_name + IP地址+ thread_id来识别分布式环境中的客户端。
Once the table with unique key constraint on lock_key is defined, acquire & release lock are merely two additional SQL snippets:
Aquire锁:
INSERT INTO `lock`(`lock_key`, `holder`) VALUES ('project1_uid1', 'server1_ip1_tid1');
释放锁:
DELETE FROM `lock` WHERE `lock_key` = 'project1_uid1';
这种简单的实现满足了基本的功能要求。
现在,让我们考虑几种故障模式,看看它是否对分布式系统中的常见故障具有鲁棒性。
如果客户端A获取锁,将一行插入数据库,但后来客户端A崩溃,或者网络分区和客户端A无法到达数据库,该怎么办?
在这种情况下,该行将保留在数据库中,并且不会被删除。
换句话说,对其他客户端来说,就好像客户端A仍然持有锁(即使A已经崩溃了!)。其他客户端将无法获得锁,并将返回时出错。
常用的方法是为每个锁分配一个TTL。这个想法很简单:如果客户端A崩溃并且无法释放锁,那么其他人应该做这项工作,删除DB中的行,从而释放锁。假设客户端A通常需要3分钟才能完成任务。我们可以将TTL设置为5分钟。
然后,我们需要构建另一个服务来不断扫描lock表,并删除超过5分钟前创建的任何行。然而,还有其他问题:
如果A没有崩溃,它只需要比平时更长的时间来完成任务呢?
如果我们为扫描lock桌本身而构建的新服务崩溃了怎么办?
第一个问题将很难用MySQL完全解决。
然而,实际上,对于大多数业务案例,我们总是可以设置足够大的TTL,因此这种情况很少发生,以至于对公司业务的任何影响几乎不明显。
或者我们可以使用ZooKeeper,它附带了另一组权衡,稍后将讨论。
现在,让我们解决实施2中的第二个问题。
实现2.使用时间戳+唯一密钥约束
我们可以在lock表中添加一列,以存储上次获取锁的时间戳。
通过这种方式,我们可以继续使用MySQL的内置功能,而无需构建其他服务。
CREATE TABLE `lock` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`lock_key` varchar(128) NOT NULL,
`holder` varchar(128) NOT NULL DEFAULT '',
`creation_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`last_lock_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_lock_key` (`lock_key`)
);
首先,我们需要确定一个合适的TTL ${timeout},如前所述。TTL应该足够大。
Aquire锁:
当客户端B尝试获取锁时,我们可以添加last_lock_time < ${now} — ${timeout}作为过滤器。
UPDATE `lock` SET `holder` = 'server1_ip1_tid1', `last_lock_time` = ${now} WHERE `lock_key` = 'project1_uid1' and `last_lock_time` < ${now} - ${timeout};
在这种情况下,只有当last_lock_time < ${now} — ${timeout},客户端B才能获取锁,将持有人更改为其ID,并将last_lock_time重置为当前时间戳。假设后来的客户端B崩溃,无法释放锁,在等待${timeout}后,其他客户端将能够获得锁。
释放锁:
我们可以定义一个min时间戳,例如‘1970–01–01 00:00:01.000000’
UPDATE `lock` SET `holder` = '', `last_lock_time` = ${min_timestamp} WHERE `lock_key` = 'project1_uid1' and `holder` = 'server1_ip1_tid1';
在WHERE语句中,除了lock_key我们还添加了holder = ‘server1_ip1_tid1’这是为了避免其他客户端意外释放当前客户端持有的锁。
成功释放锁后,holder设置为空,last_lock_time设置为最小虚拟时间戳,以便其他客户端可以轻松获取锁。
总之,基于MySQL的实现实现了以下设计目标:
-
相互排斥
-
避免死锁的TTL机制
用于锁定和解锁的API界面。API的逻辑备份使用SQL实现。
如果您对如何用Go等编程语言包装SQL感兴趣,请使用sqlc阅读我在Go ORM上的帖子。
如何实现我们功能要求中的项目4、5和6?
在上面的实现中,如果持有锁,其他客户端需要循环重试,等待锁释放,然后获取锁。
如果分布式锁定服务能够通知等待的客户端锁定可用,那就更好了。让我们在实施3中解决这些问题。
实现3.使用FOR UPDATE实现锁定释放通知
MySQL本身(也包括PostgresSQL)为每个表提供行级锁。
在RC隔离级别下,当我们使用FOR UPDATE时,MySQL将为与过滤器条件匹配的所有行添加行级锁。
MySQL中行级锁的实现支持功能要求5和6。当客户端会话获得锁时,所有其他客户端都将等待锁。此外,等待客户端唤醒并获得锁的顺序与他们首次尝试获取锁时相同。
此外,只要持有锁的客户端在SQL事务中执行逻辑,FOR UPDATE就可以多次执行。换句话说,锁是再入锁。
此外,MySQL支持另外两个选项来指定FOR UPDATE的行为:NOWAIT和SKIP LOCKED。
这两个选项的设计行为是:
NOWAIT:不要等待锁的释放。如果锁由另一个客户端持有,因此无法获得,请立即返回锁冲突消息。
跳过锁定:读取数据时,跳过其他客户端持有行级锁定的行。
通过这两个选项,我们可以实现TryLock行为,即客户端尝试获取锁,并在无法获得锁时立即返回,而不是等待。
我们可以简化lock表,只包含两个字段:
CREATE TABLE `lock` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`lock_key` varchar(128) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_lock_key` (`lock_key`)
);
获取锁:
BEGIN;
SELECT * FROM `demo`.`lock` WHERE `lock_key` = 'project1_uid1' FOR UPDATE;
关于开始新交易的BEGIN的快速说明:只有在首次获取锁时才需要它。
对于后续的重新进入,不要执行BEGIN,否则新事务将开始,现有事务将结束,从而在事务结束时实际释放锁。
非阻塞尝试锁定:
BEGIN;
SELECT * FROM `demo`.`lock` WHERE `lock_key` = 'project1_uid1' FOR UPDATE NOWAIT;
释放锁:
COMMIT;
实施3实现了所有设计目标:
相互排斥
-
TTL机制:MySQL原生管理客户端会话。如果客户端因机器故障或网络故障而断开连接,MySQL将自动释放行级锁。
-
支持所有3个API:获取/尝试/释放锁定。
-
高性能:当锁被释放时,MySQL将只通知队列中等待的下一个客户端,而不是一次性通知所有客户端,从而避免雷鸣般的羊群问题。
-
公平。MySQL行锁原生支持。
-
重新进入。MySQL行锁也原生支持。请记住在首次获取锁时开始交易,并且不要在随后的重新进入中开始新的事务。
这种方法的权衡是,我们需要先将代表所有可能锁的行插入到lock表中,只有获取/尝试/释放锁的API才能正常工作。每个锁都需要在lock表中排一行。
原文作者:BB8 StaffEngineer
1.使用场景
在分布式系统里,我们有时执行定时任务,或者处理某些并发请求,需要确保多点系统里同时只有一个执行线程进行处理。
分布式锁就是在分布式系统里互斥访问资源的解决方案。
通常我们会更多地使用Redis分布式锁、Zookeeper分布式锁的解决方案。
本篇文章介绍的是基于MySQL实现的分布式锁方案,性能上肯定是不如Redis、Zookeeper。
所以,基于Mysql实现分布式锁,适用于对性能要求不高,并且不希望因为要使用分布式锁而引入新组件。
2.基于唯一索引(insert)实现
2.1 实现方式
获取锁时在数据库中insert一条数据,包括id、方法名(唯一索引)、线程名(用于重入)、重入计数
获取锁如果成功则返回true
获取锁的动作放在while循环中,周期性尝试获取锁直到结束或者可以定义方法来限定时间内获取锁
释放锁的时候,delete对应的数据
2.2 优点:
实现简单、易于理解
2.3 缺点
没有线程唤醒,获取失败就被丢掉了;
没有超时保护,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁;
这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用;
并发量大的时候请求量大,获取锁的间隔,如果较小会给系统和数据库造成压力;
这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错,没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作;
这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁,因为数据中数据已经存在了;
这把锁是非公平锁,所有等待锁的线程凭运气去争夺锁。
2.4 简单实现方案
新建一张表,用于存储锁的信息,需要加锁的时候就插入一条记录,释放锁的时候就删除这条记录
新建一张最简单的表
CREATE TABLE `t_lock` (
`lock_key` varchar(64) NOT NULL COMMENT '锁的标识',
PRIMARY KEY (`lock_key`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='分布式锁'
根据插入sql返回受影响的行数,大于0表示成功占有锁
insert ignore into t_lock(lock_key) values(:lockKey)
释放锁的时候就删除记录
delete from t_lock where lock_key = :lockKey
2.5 完善实现方案
上面这种简单的实现有以下几个问题:
-
这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
-
这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
-
这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
-
这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
当然,我们也可以有其他方式解决上面的问题。
-
数据库是单点?搞两个数据库,数据之前双向同步。一旦挂掉快速切换到备库上。
-
没有失效时间?只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。
-
非阻塞的?搞一个while循环,直到insert成功再返回成功。
-
非重入的?在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就 可以了。
3.基于排他锁(for update)实现
3.1 实现方式
获取锁可以通过,在select语句后增加for update,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁,我们可以认为获得排它锁的线程即可获得分布式锁;
其余实现与使用唯一索引相同;
释放锁通过 connection.commit(); 操作,提交事务来实现。
for update具体可参考数据库-MySQL中for update的作用和用法一文。
3.2 优点
实现简单、易于理解。
3.3 缺点
-
排他锁会占用连接,产生连接爆满的问题;
-
如果表不大,可能并不会使用行锁;
-
同样存在单点问题、并发量问题。
3.4 伪代码
CREATE TABLE `methodLock` (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT COMMENT '主键',
`method_name` VARCHAR ( 64 ) NOT NULL DEFAULT '' COMMENT '锁定的方法名',
`desc` VARCHAR ( 1024 ) NOT NULL DEFAULT '备注信息',
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '保存数据时间,自动生成',
PRIMARY KEY ( `id` ),
UNIQUE KEY `uidx_method_name` ( `method_name ` ) USING BTREE
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '锁定中的方法';
/**
* 加锁
*/
public boolean lock() {
// 开启事务
connection.setAutoCommit(false);
// 循环阻塞,等待获取锁
while (true) {
// 执行获取锁的sql
result = select * from methodLock where method_name = xxx for update;
// 结果非空,加锁成功
if (result != null) {
return true;
}
}
// 加锁失败
return false;
}
/**
* 解锁
*/
public void unlock() {
// 提交事务,解锁
connection.commit();
}
4.乐观锁实现
一般是通过为数据库表添加一个 version 字段来实现读取出数据时,将此版本号一同读出.
之后更新时,对此版本号加1,在更新过程中,会对版本号进行比较,如果是一致的,没有发生改变,则会成功执行本次操作;如果版本号不一致,则会更新失败。
实际就是个CAS过程。
缺点:
这种操作方式,使原本一次的update操作,必须变为2次操作: select版本号一次;update一次。增加了数据库操作的次数。
如果业务场景中的一次业务流程中,多个资源都需要用保证数据一致性,那么如果全部使用基于数据库资源表的乐观锁,就要让每个资源都有一张资源表,这个在实际使用场景中肯定是无法满足的。而且这些都基于数据库操作,在高并发的要求下,对数据库连接的开销一定是无法忍受的。
乐观锁机制往往基于系统中的数据存储逻辑,因此可能会造成脏数据被更新到数据库中。
5.总结
数据库锁现在使用较多的就上面说的3种方式,排他锁(悲观锁),版本号(乐观锁),记录锁,各有优缺点。
注意点:
使用mysql分布式锁,必须保证多个服务节点使用的是同一个mysql库。
优点
-
直接借助DB简单易懂。
-
方便快捷,因为基本每个服务都会连接数据库,但是不是每个服务都会使用redis或者zookeeper;
-
如果客户端断线了会自动释放锁,不会造成锁一直被占用;
-
mysql分布式锁是可重入锁,对于旧代码的改造成本低;
缺点
-
加锁直接打到数据库,增加了数据库的压力;
-
加锁的线程会占用一个session,也就是一个连接数,如果并发量大可能会导致正常执行的sql语句获取不到连接;
-
服务拆分后如果每个服务使用自己的数据库,则不合适;
-
锁的可用性和数据库强关联,一旦数据库挂了,则整个分布式锁不可用;
-
如果需要考虑极限情况,会有超时等各种问题,在解决问题的过程中会使整个方案变得越来越复杂;
-
数据库的性能瓶颈相较于redis、zk要低很多,当调用量大的时候,性能问题将成为关键;
-
还需要考虑超时等问题。
一种基于mysql实现分布式锁的方式
介绍
分布式锁,即分布式系统中的锁。在单体应用中我们通过锁解决的是控制共享资源访问的问题,而分布式锁,就是解决了分布式系统中控制共享资源访问的问题。与单体应用不同的是,分布式系统中竞争共享资源的最小粒度从线程升级成了进程。
目前比较常见的实现分布式锁的方式主要有三种:基于数据库实现、基于Zookeeper实现、基于redis实现。本文主要介绍了一种基于mysql数据库实现分布式锁的方式,从最简单的实现方式开始,一步步构造一个拥有基本分布式锁条件的程序。
版本1
mysql有两种实现分布式锁的思路,乐观锁和悲观锁,本文利用悲观锁方式实现。
select * from tableName where key = " " for update
在InnoDB下如果key为索引,则会为该行加上排他锁,若其它线程想获得排他锁则会阻塞。
伪代码:
where(true){
select ... for update
if(记录存在)
//业务逻辑
return;
else
inset ...
}
commit;
如上的版本会产生两个问题:
-
insert时通过唯一键重复报错,处理错误形式不和
-
由于间隙锁原因,并发插入会引发死锁
版本2
为了解决上一版本的问题,本文引入中央锁的概念,也同时加入了数据库锁表和状态位。
- 创建数据库锁表,插入中央锁记录
-- 锁表,单库单表
CREATE TABLE IF NOT EXISTS credit_card_user_tag_db.t_tag_lock (
-- 记录index
Findex INT NOT NULL AUTO_INCREMENT COMMENT '自增索引id',
-- 锁信息(key、计数器、过期时间、记录描述)
Flock_name VARCHAR(128) DEFAULT '' NOT NULL COMMENT '锁名key值',
Fcount INT NOT NULL DEFAULT 0 COMMENT '计数器',
Fdeadline DATETIME NOT NULL DEFAULT '1970-01-01 00:00:00' COMMENT '锁过期时间',
Fdesc VARCHAR(255) DEFAULT '' NOT NULL COMMENT '值/描述',
-- 记录状态及相关事件
Fcreate_time DATETIME NOT NULL DEFAULT '1970-01-01 00:00:00' COMMENT '创建时间',
Fmodify_time DATETIME NOT NULL DEFAULT '1970-01-01 00:00:00' COMMENT '修改时间',
Fstatus TINYINT NOT NULL DEFAULT 1 COMMENT '记录状态,0:无效,1:有效',
-- 主键(PS:总索引数不能超过5)
PRIMARY KEY (Findex),
-- 唯一约束
UNIQUE KEY uniq_Flock_name(Flock_name),
-- 普通索引
KEY idx_Fmodify_time(Fmodify_time)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
- 伪代码:
select from tableName where key = "中央所名字" for update;
select ... fro update;
if(记录存在)
//返回记录
else
insert ...
//返回记录
//判断状态位
//更新状态位
//执行业务逻辑
目前版本存在的一个问题是应用的所有记录共享一个中央锁,并发并不高。
版本3
为了解决上一版本的问题,本文提出了解决办法,即:
在数据库锁表中插入多条中央锁数据记录
获取中央锁时根据key的哈希值来选择一个中央锁
伪代码:见文章最后完整代码
经测试,版本3相较于版本2性能提升近一倍。
但是目前还存在两个问题:
-
锁无法 重入
-
没有超时解锁机制
版本4
为了解决版本3中的问题,本文做出以下措施
-
数据库中加入请求ID、过期时间和加锁次数字段
-
获取锁时校验请求ID,若相同则获取到锁且加锁次数+1
-
获取到锁时校验过期时间,若已过期则可以获取到该锁。
完整代码:
static ThreadLocal<String> requestIdTL = new ThreadLocal<>();
public List<TTagLock> selectAll() {
return testMapper.selectAll();
}
/**
** 获取当前线程requestid
** @return
**/
public static String getRequestId() {
String requestId = requestIdTL.get();
if (requestId == null || "".equals(requestId)) {
requestId = UUID.randomUUID().toString();
requestIdTL.set(requestId);
}
System.out.println("requestId: "+requestId);
return requestId;
}
/**
* 初始化记录,如果有记录update,如果没有记录insert
*/
private TTagLock initTTagLock(String key){
// 查询记录是否存在
TTagLock tTagLock = testMapper.queryRecord(key);
if (null == tTagLock) {
// 记录不存在,创建
tTagLock = new TTagLock();
tTagLock.setFlockName(key);
tTagLock.setFcount(0);
tTagLock.setFdesc("");
tTagLock.setFdeadline(new Date(0));
tTagLock.setFstatus(1);
tTagLock.setFRequestId(getRequestId());
testMapper.insertRecord(tTagLock);
}
return tTagLock;
}
/**
* 获取中央锁Key
*/
private boolean getCenterLock(String key){
String prefix = "center_lock_";
CRC32 crc32 = new CRC32();
crc32.update(key.getBytes());
Long hash = crc32.getValue();
if (null == hash){
return false;
}
Integer len = hash.toString().length();
String slot = hash.toString().substring(len-2);
String centerLockKey = prefix + slot;
testMapper.queryRecord(centerLockKey);
return true;
}
/**
* 获取锁,代码片段
*/
@Transactional
public boolean getLock(String lockName,String desc,Long expireTime) throws InterruptedException {
// 检测参数
if(StringUtils.isEmpty(lockName)) {
System.out.println("参数为空");
return false;
}
// 获取中央锁,初始化记录
Long nowTime = new Date().getTime();
getCenterLock(lockName);
TTagLock tTagLock = initTTagLock(lockName);
// 未释放锁或未过期,获取失败
if (tTagLock.getFstatus() == 1
&& tTagLock.getFdeadline().getTime() > nowTime && !getRequestId().equals(tTagLock.getFRequestId())){
Thread.sleep(50);
return false;
}
if(getRequestId().equals(tTagLock.getFRequestId())){//重入锁
int num = testMapper.updateRecord(lockName, tTagLock.getFdeadline(), tTagLock.getFcount()+1,
tTagLock.getFdesc(), 1,getRequestId());
return true;
}
// 获取锁
Date deadline = new Date(nowTime + expireTime);
int num = testMapper.updateRecord(lockName, deadline, 1, desc, 1,getRequestId());
return true;
}
public void unLock(String lockName) {
//获取当前线程requestId
String requestId = getRequestId();
TTagLock tTagLock = testMapper.queryRecord(lockName);
//当前线程requestId和库中request_id一致 && lock_count>0,表示可以释放锁
if (Objects.nonNull(tTagLock) && requestId.equals(tTagLock.getFRequestId()) && tTagLock.getFcount() > 0) {
if (tTagLock.getFcount() == 1) {
//重置锁
resetLock(tTagLock);
} else {
testMapper.updateRecord(lockName,tTagLock.getFdeadline(),tTagLock.getFcount()-1,tTagLock.getFdesc(),1,getRequestId());
}
}
}
public int resetLock(TTagLock tTagLock) {
tTagLock.setFRequestId("");
tTagLock.setFcount(0);
tTagLock.setFdeadline(new Date());
//todo 修改update
return testMapper.updateRecord(tTagLock.getFlockName(),new Date(),0,"",0,"");
}
Mysql分布式锁设计
最近开发电商库存相关项目,其中最为重要的一个功能之一是分布式锁的实现。本文就项目组中用到的基于MySQL实现的分布式锁,做一些思考和总结。
1、常见的分布式锁实现方案
基于数据库实现的分布式锁 基于Redis实现的分布式锁 基于Zookeeper实现的分布式锁
在讨论使用分布式锁的时候往往首先排除掉基于数据库的方案,本能的会觉得这个方案不够“高级”。
从性能的角度考虑,基于数据库的方案性能确实不够优异,但就目前笔者所在项目组来说,几乎所有项目的项目都是基于MySQL实现的分布式锁,所以采用哪种方案是要基于使用场景来看的,选择哪种方案,合适最重要,本文也仅就MySQL实现分布式锁展开讨论。
2、一把极为简单的MySQL分布式锁
最容易想到的基于MySQL的分布式锁就是通过数据库的唯一键约束,来达到抢占锁资源的目的,本文也从这把最为简单的分布式锁讲起。
在MySQL中创建一张表如下,为资源ID设置唯一键约束。
CREATE TABLE `distribute_lock` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`resource_id` varchar(64) NOT NULL DEFAULT '' COMMENT '资源id',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_resourceId` (`resource_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='分布式锁';
当需要获取锁时,往数据库中一条记录,因为有唯一键约束,插入成功则代表获取到了锁。
INSERT INTO distribute_lock(`resource_id`) VALUES ( 'resource_01');
释放锁时删除这条记录即可。
DELETE FROM distribute_lock WHERE resource_id = 'resource_01';
显然,这把锁因为太过简单,所以存在很多问题。
-
没有锁失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
-
不可重入,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
-
非阻塞,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
当然还有比如锁可靠性完全依赖于数据库,这是基于MySQL分布式锁的必然缺陷,这里不做讨论。下面将一步步优化这把最为简单的锁。
3、锻造一把好锁
3.1、锁超时失效
通常想到的方法是做一个定时清理过期资源的程序,每隔一定时间把数据库中的超时数据清理一遍。
这种做法最为简单直接,但也有一些相应的弊端,比如增加了程序复杂性(需要专门实现并配置定时任务),锁的超时时间也不方便灵活配置。本文试图说明一种笔者认为更为合理的方式。
前文所述的拿锁方式非常简单粗暴,数据插入不成功则拿锁失败,但此时数据库中的锁记录可能已经超时,所以需要在插数失败之后做进一步动作,以判断之前拿锁的线程是否已经超时。
只需取出当前锁记录,比较锁记录时间与当前时间差值是否已超出锁等待时间,如未超出,获取锁失败,如超出,修改锁记录时间为当前时间,拿锁成功。
代码如下:
boolean tryLock(String resourceId) throws SQLException {
//插入数据,插入成功则成功获取锁
if (ensureLockExist(null, resourceId)) {
return true;
}
//数据插入失败,判断锁是否超时,超时则修改锁记录时间
return tryUpdateLockTime(resourceId);
}
protected boolean ensureLockExist(Connection connection, String resourceId) throws SQLException {
try {
createLock(connection, resourceId); // 插入锁记录
} catch (MySQLIntegrityConstraintViolationException ex) {
return false;
}
return true;
}
private boolean tryUpdateLockTime(String resourceId) throws SQLException {
LockModel entity = getLock(null, resourceId);//查询已有记录
if (entity != null && isLeaseExpired(entity)) {//记录存在并且已过期
//基于乐观锁CAS修改锁记录时间,修改成功就拿到锁
return trySetLockTime(null, resourceId, entity.createTime) > 0;
}
return false;
}
这里需要强调,修改锁记录时间必须通过CAS操作,因为可能存在多个线程同时争抢一把已经过期的锁,如果不通过CAS操作,可能多个线程同时获取到锁。
上述只是代码片段,程序中可以提供方法给调用者灵活修改锁的超时等待时间,同时也不再需要专门配置定时清理过期记录的任务。
3.2、锁可重入
有了前面解决超时失效问题的思路,很容易想到的方案是在表中加个字段记录当前获得锁的机器和线程信息,当线程再次获取锁的时候先查询数据库,如果当前机器和线程信息在数据库可以查到的话,直接把锁分配给该线程即可。
这种方式多了一步查询操作,对锁性能有一定影响,是否可以把成功获取锁的线程和其获取到的锁放到一个容器里呢?
当某个线程需要拿锁时,先在容器中找下自己是否已经拿到过锁,拿到了那就不必和数据库打交道了。
那就这么干,代码如下:
class State {
private Thread exclusiveOwner;//拿到锁的线程
private volatile int state; //重入次数
}
//为保证线程安全,采用ConcurrentHashMap盛放成功获取锁的线程
ConcurrentHashMap<String/* resourceId*/, State> states = new ConcurrentHashMap<>();
public boolean tryLock(String resourceId) {
Thread current = Thread.currentThread();
State state = states.get(resourceId);//从容器中拿出锁记录
if (Objects.nonNull(state)) {
//锁记录不为空,且为当前线程,则重入获取锁成功
if (state.exclusiveOwner == current) {
state.state++;//重入次数+1
return true;
}
return false;
} else {
try {
State newState = new State(current, 1);
if (states.putIfAbsent(resourceId, newState) == null) {//第一个往容器中放入锁记录成功
if (node.tryLock(resourceId)) {
return true;
} else {
states.remove(resourceId);
}
}
return false;
} catch (Exception ex) {
throw new DLockException(true, resourceId, ex);
}
}
}
3.3、阻塞式获取锁
阻塞?搞一个while循环,直到tryLock成功?其实这也不失为一种解决方式,emm……总觉得不够优雅。而且通过轮训的方式,会占用较多的CPU资源。
能否借助MySQL的悲观锁实现呢?借助 for update 关键字来给被查询的记录添加行锁中悲观锁,这样别的线程就没有办法对这条记录进行任何操作,从而达到保护共享资源的目的。
select * from distribute_lock where resource_id = ? for update
采用这种方式需要注意:
-
MySQL默认是会自动提交事务的,应该手动禁止一下: SET AUTOCOMMIT = 0;
-
行锁是建立在索引的基础上的,如果查询时候不是走的索引的话,行锁会升级为表锁进行全表扫描;
-
申请锁操作:先往数据库中插入一条锁记录,然后select * from distribute_lock where resource_id = ? for update; 只要可以查的出来就是申请成功的,没有获取到的会被阻塞,阻塞的超时时可 以- 通过设置 MySQL 的 innodb_lock_wait_timeout 来进行设置。
-
释放锁操作:COMMIT; 事务提交之后别的线程就可以查询到这条记录。
boolean lock(String resourceId) throws SQLException {
ensureLockExist(null, resourceId);//插入一条锁记录
connection = dataSource.getConnection();
autoCommit = connection.getAutoCommit();
lockResource(connection, resourceId);
return true;
}
boolean unlock(String resourceId) throws SQLException {
if (connection != null) {
connection.commit();//提交事务达到释放锁的目的
connection.setAutoCommit(autoCommit);
connection.close();
connection = null;
return true;
}
return false;
}
protected void lockResource(Connection connection, String resourceId) throws SQLException {
PreparedStatementCreator creator = (conn) -> {
conn.setAutoCommit(false);//关闭事务自动提交
PreparedStatement ps = conn.prepareStatement("select * from distribute_lock where resource_id = ? for update");
ps.setString(1, resourceId);
return ps;
};
PreparedStatementCallback<Void> action = ps -> {
ResultSet rs = ps.executeQuery();
if (rs != null) {
rs.close();
}
return null;
};
execute(connection, creator, action);
}
虽然在此提出了这种阻塞式获取锁的方式,但笔者并不推荐,这种方式实际应用中造成过生产事故,因为MySQL数据库会做查询优化,即便使用了索引,优化时发现全表扫效率更高,则可能会将行锁升级为表锁,此时会造成其他资源锁也无法获取。
难道真的只能通过while循环的方式以达到阻塞式获取锁吗?笔者在库存系统开发过程中,接触到了一种更为巧妙的MySQL阻塞式获取锁的方式。
4、基于MySQL阻塞式分布式锁
通过在事务中插入或更新一条带唯一索引的记录,在事务未提交之前,其他线程事务会处于阻塞等待的状态,以达到阻塞式获取锁的目的。
@Transactional(rollbackFor = Exception.class)
public void executeWithLock(String resourceId) throws OspException {
//获取锁
tryLock(resourceId);
// do something
}
<insert id="tryLock">
INSERT INTO distribute_lock
(resource_id)
VALUES
(#{resourceId})
ON DUPLICATE key UPDATE update_time = NOW()
</insert>
其原理笔者查阅了下MySQL(RR事务级别)插入一条记录的执行流程如下:
首先对插入的间隙加插入意向锁(Insert Intension Locks)如果该间隙已被加上了间隙锁或 Next-Key 锁,则加锁失败进入等待;如果没有,则加锁成功,表示可以插入;
然后判断插入记录是否有唯一键,如果有,则进行唯一性约束检查如果不存在相同键值,则完成插入。如果存在相同键值,则判断该键值是否加锁,如果没有锁, 判断该记录是否被标记为删除,如果标记为删除,说明事务已经提交,还没来得及 purge,这时加 S 锁等待;如果没有标记删除,则报 duplicate key 错误;如果有锁,说明该记录正在处理(新增、删除或更新),且事务还未提交,加 S 锁等待;
这种方式是否会造成死锁呢?欢迎留言,避免笔者在项目中踩坑。
基于 MySQL 唯一索引的分布式锁(一):设计
本文提出的分布式锁方案源于我的实际生产经验。在生产环境验证了两年,自认为比网络上那些基于 MySQL 悲观锁、乐观锁实现的分布式锁好很多,他们的方案繁杂,性能又低。
本文提出的方案简单又好用,性能也高一点。
老实说,用 MySQL 实现分布式锁并不是最好的选择,用 Redis、ZooKeeper 实现可能会更好。
但我当初没得选,不得不用 MySQL。如果你确定要用 MySQL 实现分布式锁,可以参考一下本文。
本文只讲设计,但你看完就可以自己照着实现一个基于 MySQL 唯一索引的分布式锁了。
核心逻辑
如果为某个表创建了唯一索引(即 UNIQUE 约束),MySQL 可以保证表中每条记录的唯一索引列都是唯一的。
如果表中已经存在一条唯一索引列为特定值的记录,如果再次尝试插入一条索引值为特定值的新的记录会插入失败,并触发 duplicate entry 错误。如果多个并发事务尝试向表中插入索引字段值相同的记录,则只有一个事务会插入成功,其他事务都会失败并触发 duplicate entry 错误。
所以我们可以利用 MySQL 的唯一索引实现分布式锁。
将插入一条唯一索引列为特定值的记录当成加锁,如果插入成功,则视为成功获取到了锁,如果遇到 duplicate entry 错误,则说明加锁失败;将删除唯一索引列为特定值的记录视为释放操作,删除记录后,其他请求就可以插入记录(获得锁)了。
具体方案
虽然核心逻辑很简单,但接着往下看,你会发现一些续约考虑和衡量的问题。
设计表
现在考虑一下,我们需要哪些字段。基于 MySQL 唯一索引实现分布式锁,最重要的字段当然是唯一索引所在字段。我们可以用一个表示锁名称的字段 name 来充当唯一索引,每个使用分布式锁的业务可以根据用途来给锁命名,不同用途的分布式
锁一般不会有同名冲突,如果同名了,可以加上业务、团队、级别信息作为前缀。
按照惯例,还需要一个自增的主键 id 字段。后面我们会见到这个 id 字段大有用途。
再加一个 created_at 字段,表示记录的创建时间。后面会讲解它的用途。
CREATE TABLE lock (
id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY COMMENT '主键',
name VARCHAR(128) NOT NULL UNIQUE COMMENT '锁名',
created_at INT UNSIGNED NOT NULL COMMENT '秒级时间戳,表示记录被插入的时间',
)ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
获取锁
加锁操作即插入一条记录。每个想要获取锁的客户端应该执行如下 SQL 语句:
SET SESSION innodb_lock_wait_timeout=1;
INSERT INTO lock (name, created_at) VALUES('hello-dis-lock', UNIX_TIMESTAMP())
SELECT LAST_INSERT_ID();
SET SESSION innodb_lock_wait_timeout=1 将获取锁的超时时间设为设为 1 秒,是为了给加锁操作设置一个兜底的超时时间,避免长时间等待。
通过执行 INSERT INTO lock (name, created_at) VALUES('hello-dis-lock', UNIX_TIMESTAMP()) 插入记录后应该马上提交事务,如果某个事务执行了完该语句,但是不提交,其他事务执行该语句时不会报错,也不会成功,而是一直阻塞等待。为了避免阻塞其他尝试获得锁的客户端,执行完插入语句后应该马上提交。
现在很多 生产环境的 MySQL 服务都打开了自动提交( set autocommit=1),每条语句默认是一个事务,在执行完后会自动提交,不需要客户端主动 COMMIT。
如果你使用的 MySQL 服务没有打开自动提交,你可以创建数据库连接后执行 set autocommit=1,或者执行完插入语句前主动用 START TRANSACTION 开启事务,执行完插入语句后马上执行 COMMIT。 SELECT LAST_INSERT_ID() 是获取插入记录的主键 id,客户端需要记住这个返回的 id,后面释放锁时用得上。
如果上面的语句执行成功,也就是获取锁成功,客户端就可以执行自己需要分布式锁保护的业务逻辑了,执行完记得释放锁。
如果插入语句返回 duplicate entry错误,则说明其他客户端已经持有了该锁。获取锁失败,则需要关闭事务,随机休眠一段时间后再重试。如果你的业务特点决定了客户端持有锁的时间比较长(达到了秒级),则需要随机休眠的时间也是秒级,可以断开数据库连接后再休眠。
如果插入语句返回 Lock wait timeout exceeded 说明尝试加锁超时了,可能是当前竞争锁的客户端比较多,关闭事务,随机休眠一段时间后再重试。
如果多次遇到 duplicate entry 错误,则可能是持有锁的客户端出了故障,不能顺利释放锁。则需要进行帮其强行释放。
随机休眠一段时间,而不是休眠一段固定的时间,是为了避免所有客户同时竞争锁,加入随机因素将客户端的获取锁的时间打散。
超时检测和强制释放
客户端在持有锁后可能会因为故障而长时间甚至永远都不释放锁。
是程序就有故障的可能,客户端程序可能会意外退出、断网、进入死循环等,从而导致持有的锁无法释放,其他客户端就只能饿死。
我们可以给分布式锁加入超时检测和强制释放功能,避免因为某个客户端故障而导致分布式锁不可用。
我们可以给锁的持有时间设置一个过期时间,规定客户端最多只能持有锁多长时间。
在客户端获取锁时连续收到 duplicate entry 错误的次数达到次数上限后,可以认为可能是某个客户端持有锁的时间超过了规定的过期时间。
执行一条删除语句帮其强制释放锁。
DELETE * FROM lock WHERE name='hello-dis-lock' and UNIX_TIMESTAMP()-created_at > [超时限制];
如果该删除语句返回 Query OK, 1 row affected,说确实发现锁超时了,而且已经删除成功。
如果删除语句返回 Query OK, 0 row affected,说明删除失败,可能时锁没超时,也可能是锁刚被持有它的客户释放了,也可能是其他客户端将其强制释放了。
不管是哪种返回结果,客户端可以回到获取锁的阶段了。
随机休眠时长、次数上限、过期时间怎么确定?
建议根据客户端业务规律来设置这三个参数。
客户端一般是依赖分布式锁保护某些关键操作。如果在大多数情况下,关键操作都能能在 3~5 完成,则可以将随机休眠时长的下限设为 3 秒,上限设为 5 秒。
如果客户端最多也只需要 10 秒就能完成关键操作,则可以将过期时间设为 20 秒或 30 秒(即将过期时间设为预估的最长持有时间的两倍或三倍)。
执行强制删除前的重试次数上限设为 [超时限制 / 随机休眠时长的下限]。
本文假设竞争同一把锁的所有客户端都使用相同的过期时间。如果你需要每个客户端使用单独的过期时间,可以给表加一列 timeout,表示本条记录对应锁的过期时间。
对应的强制释放语句也要相应改为:
DELETE * FROM lock WHERE name='hello-dis-lock' and UNIX_TIMESTAMP()-created_at > timeout;
超时检测和强制释可以封装成一个单独的定时任务
如果不想客户端逻辑太复杂,可以单独创建一个任务,定时查询表中的所有记录,将超时的记录删除。
表中每把锁需要的过期时间可能不一样,所以需要加一列 timeout 表示每条锁记录的过期时间。
定时任务的运行间隔必须小于等于表中 timeout 列的最小值。
而且这个定时任务不能挂了,如果挂了,所有的锁都将失去超时检测和强制释放功能。
释放锁
释放锁即删除当前客户端之前插入的记录。
之前插入记录时,客户端特意用 SELECT LAST_INSERT_ID() 语句查询并保存了插入记录的主键 id,假设主键 id 值为 lock_id,则需要执行的删除语句如下:
DELETE FROM lock WHERE id=lock_id;
如果删除语句返回 Query OK, 1 row affected,说明删除成功。
如果删除语句返回 Query OK, 0 row affected,说明主键为 lock_id 的记录因为超时被强制删除了。
为什么要根据 id 而不是根据 name 释放锁?
因为存在极小的可能,在客户端主动删除自己的锁记录时,其他客户都已经将其强制删除了,并创建了新的锁记录(即获取了锁)。
如果客户端在释放锁时根据 name 删除,可能会错误的删除其他客户端创建的锁记录。
而 id 是自增的,每次创建的锁记录的 id 都不一样,所以根据 id 不会错误地释放非当前客户端持有的锁。
可选功能:租期续约
分布式锁中一个常见的功能就是租期续约,即在客户端持有的锁快到期时增加其过期时间。
只要客户端还活着就给其不停的续约。
判断客户端是否活着者有两种常见方案:
-
在有的实现方案中,客户本身就和锁服务端一直连着,可以根据连接是否断开来判断客户都是否或者。
-
客户端实现健康检查接口,服务定期查询客户端的监控状态。
这两种服务端给客户都主动续约的方案都有一个问题,即客户端可能陷入了某种故障,导致其连接还在、健康检查接口也能正常调用,但是释放锁的逻辑却无法再执行。
服务端却一直认为客户端还活着,给其无限续约,相当于没有过期时间。
本文秉着能在客户端搞定的事就在客户端搞定的原则,建议将租期续约逻辑放入到客户端代码中。客户端可以根据自己的逻辑判断关键操作是否会在超时前完成,如果不能则主动给自己持有的锁记录增大过期时间。即在过期时间前执行以下修改语句:
UPDATE lock SET created_at = UNIX_TIMESTAMP() WHERE id=[lock_id];
lock_id 是客户都之前获取锁时报错的锁记录 id。将锁记录的 created_at 简单的设为当前时间,相重新获取了一次锁。如果想做的更好一点,你可以根据具体想要续约的时长来设置 created_at 值。
更好的方案是给表增加一个单独 timeout 字段表示过期时间,则续约就是修改 timeout 字段。
UPDATE lock SET timeout = timeout+[续约时长] WHERE id=[lock_id];
这样就不用破坏 created_at 的语义。
客户端主动续约的好处是,客户都最知道自己的状态,如果释放锁的逻辑无法正常运行了,续约逻辑大概率也无法运行,不会造成无限续约的问题。
优缺点分析
- 优点:
依赖小,只需要有能正常访问的 MySQL 服务就行。
实现也简单,所有逻辑都在客户端代码中,可以用一个单独的库提供。
相比其他基于 MySQL 的方案,出现无限续约的概率更小。
- 缺点:
和所有基于 MySQL 的方案一样,存在单点故障,如果依赖的 MySQL 服务出现问题,则加锁、释放锁都会失败。
小结
分布式锁的思想是一样的。他山之石。
我们可以开源一个锁实现。知行合一。
参考资料
https://www.jianshu.com/p/f01f0fca6cd0
https://www.51cto.com/article/684974.html
https://juejin.cn/post/7217810344696725560
MySQL–DB实现分布式锁思路: https://cloud.tencent.com/developer/article/1580632
https://www.modb.pro/db/1681977087702425600
