Zookeeper
ZooKeeper的架构通过冗余服务实现高可用性。
因此,如果第一次无应答,客户端就可以询问另一台ZooKeeper主机。
ZooKeeper节点将它们的数据存储于一个分层的命名空间,非常类似于一个文件系统或一个前缀树结构。客户端可以在节点读写,从而以这种方式拥有一个共享的配置服务,更新是全序的。
系统架构
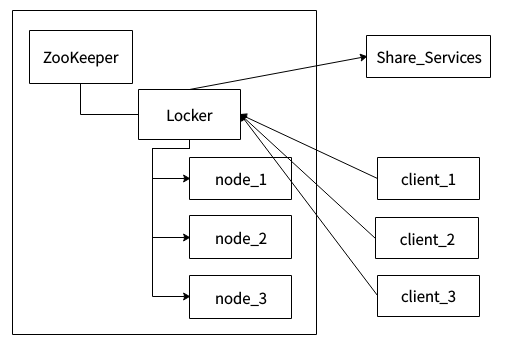
上图为系统架构,左边区域表示一个ZooKeeper集群,locker是ZooKeeper的一个持久节点,node_1、node_2、node_3是locker这个持久节点下面的临时顺序节点。client_1、client_2、client_3表示多个客户端,Share_Service表示需要互斥访问的共享资源。
实现思路
-
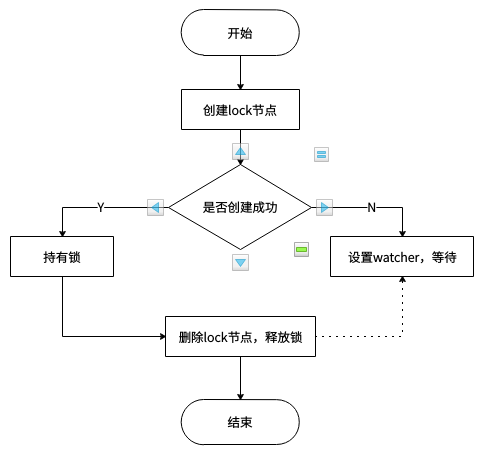
多个客户端竞争创建 lock 临时节点;
-
其中某个客户端成功创建 lock 节点,其他客户端对 lock 节点设置 watcher;
-
持有锁的客户端删除 lock 节点或该客户端崩溃,由 Zookeeper 删除 lock 节点;
-
其他客户端获得 lock 节点被删除的通知;
-
重复上述 4 个步骤,直至无客户端在等待获取锁了。
流程图
框架
Curator 提供的 InterProcessMutex 是分布式锁的实现。
acquire方法获取锁,release方法释放锁。
另外,锁释放、阻塞锁、可重入锁等问题都可以有有效解决。
优缺点
最后,Zookeeper 实现的分布式锁其实存在一个缺点,那就是性能上可能并没有缓存服务那么高。
因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。
ZK 中创建和删除节点只能通过 Leader 服务器来执行,然后将数据同不到所有的 Follower 机器上。
并发问题,可能存在网络抖动,客户端和 ZK 集群的 session ZK 集群以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了。
参考资料
https://juejin.im/entry/5a502ac2518825732b19a595
https://runnerliu.github.io/2018/05/06/distlock/
