webank 系列
| 智能运维系列(一) | AIOps 的崛起与实践:https://www.infoq.cn/article/fqUfkjhecOla1zKUKycN |
| 智能运维系列(二) | 智能化监控领域探索:https://www.infoq.cn/article/Qta6VCyjvHdoiJg5wKze |
| 智能运维系列(三) | 浅析智能异常检测:“慧识图”核心算法:https://www.infoq.cn/article/mryjNLXOlujV7fkQFUaL |
| 智能运维系列(四) | 曝光交易路径:https://www.infoq.cn/article/a72WeEMuM1O63iX1w0ZK |
| 智能运维系列(五) | 浅析基于知识图谱的根因分析系统:https://www.infoq.cn/article/cUYWKqYxrBamV7GwVVjM |
| 智能运维系列(六) | 如何通过智能化手段将运维管理要求落地?:https://www.infoq.cn/article/Wj4PJBg41SlA0fl6glIv |
| 智能运维系列(七) | 化繁为简:业务异常的根因定位方法概述:https://cloud.tencent.com/developer/news/665441 |
| 智能运维系列(八) | 事件指纹库:构建异常案例的“博物馆” https://www.infoq.cn/article/4hxfwtcfonjz7jjrfxzq |
| 智能运维系列(九) | 基于交易树的根因告警定位方法 https://www.infoq.cn/article/t1ytbqmbkp7xxdajkv1p |
| 智能运维系列(十) | 浅析根因告警的系统分析法 https://www.infoq.cn/article/m78zwql2nc4sdpapcxpg |
| 智能运维系列(十一) | 日志文本异常聚类及相似度检测 https://www.infoq.cn/article/kynuvjmfxhtommvdo35t |
前言
互联网公司在实际运营过程中,所维护的各项业务随时可能会遇到各种各样的问题,将各系统的运行日志记录在文件中,从而方便排查和定位问题,是目前普遍采用的做法。
但是,在目前已经广泛流行的分布式架构的系统中,复杂的配置仍然缺乏灵活性,很难形成统一的标准,且对运维人员不够友好。
因此,微众技术团队提出了基于机器学习算法进行日志分类、聚类、并转化为时间序列的日志异常检测解决方案。
本文收录在专题《智能时代下的运维》系列 。
互联网公司在实际运营过程中,所维护的各项业务随时可能会遇到各种各样的问题,将各系统的运行日志记录在文件中,从而方便排查和定位问题,是目前普遍采用的做法。
但是,在实际应用过程中,日志中有用的信息隐藏在冗余的日志文本中,目前常用的处理机制很难从中提炼有价值的信息。
为了解决以上痛点,目前业界较为良好的开源日志处理框架 ELK 可以解决了部分需求。
总的来讲,ELK 的解决方案是通过在采集端配置预设的日志正则表达式模板,将匹配到的日志解析成各种范式,然后在后台进行时间、日志级别、主机 ip 地址等维度的汇总,从而实现日志的解析和统计功能。
图 1 ELK 的处理方案,采用配置模板进行日志解析
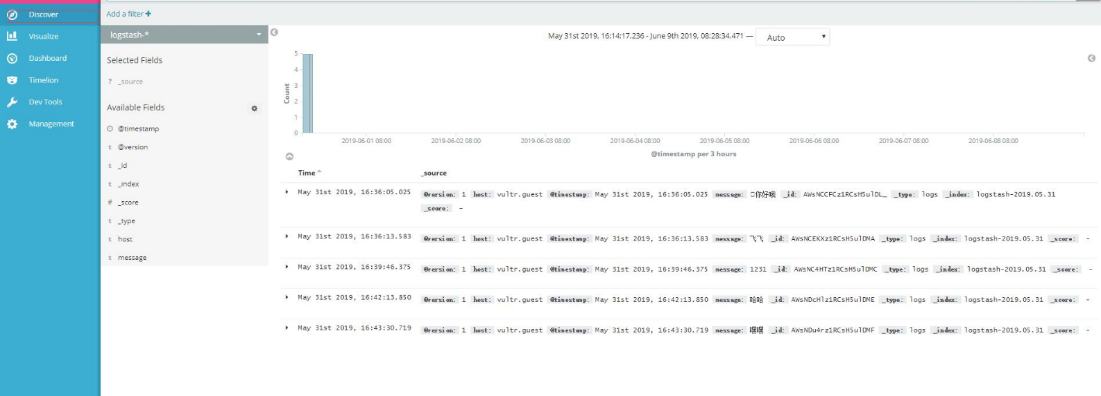
另外,阿里云也有类似的解决方案。
阿里云的解决方案在 ELK 中更进了一步,即通过设置一个“日志分类灵敏度”的功能控件,来决定应该以什么样的粒度来进行日志的聚类和收敛。
图 2 阿里云 LiveTail 日志聚类解决方案
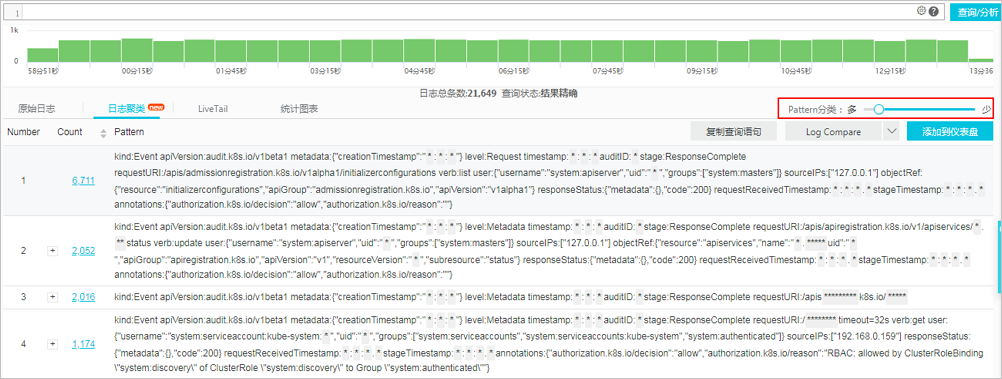
但是,无论是 ELK 还是阿里云,仍然需要用户配置日志模板。在目前已经广泛流行的分布式架构的系统中,复杂的配置仍然缺乏灵活性,很难形成统一的标准,且对运维人员不够友好。
另一方面,根据模板生成的日志汇总数据仍然缺乏很好的自说明性,即汇总的数据除非有良好的注释信息,否则对代码逻辑缺乏详细了解的开发运维人员在看到信息时,仍然很难判断此时系统是否处于异常状态。
基于此,我们提出了基于机器学习算法进行日志分类、聚类、并转化为时间序列的日志异常检测解决方案,下面为大家详细介绍。
基于 TF-IDF 的模型
首先,考虑到日志的量级较大,我们先对日志进行聚类处理,将相似的文本收敛到可以处理的量级。
这里我们将所有重要子系统的日志进行文本清洗,并引入词频和逆文档频率(TF-IDF)的建模方法对文档信息进行数学建模,得到一个语料库。
然后将清洗后的日志信息在语料库中映射得到其对应的 TF-IDF 向量。
这时,我们便得到了每条日志在系统中的唯一数字化表达。
图 3 TF-IDF 原理示意图
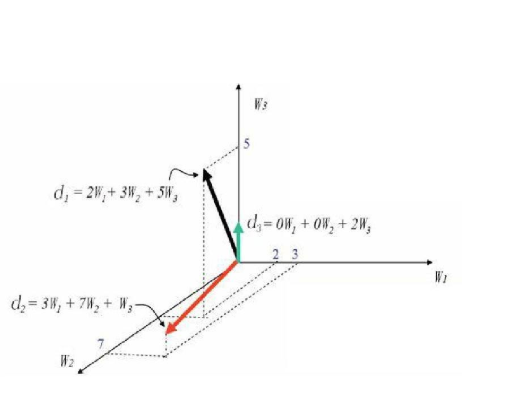
文本相似性算法
但是,此时系统中仍有上百万条这样的日志,我们需要对这些信息进行收敛。
这时,我们需要采用一种文本相似度算法来检测每条信息的相似性,从而将日志文本中结构相同、但信息不同的语素归为一类。
例如,我们在代码中,记录了一条这样一条日志:
logger.info(“你有新的订单,订单 id:{}, 订单编号:{}, 订单金额:{}”, id, No, money)
要想解析并统计该日志,传统的做法是,对该类日志配置一条解析模板,然后通过正则表达式进行解析,然后归为同类日志,再进行统计汇总。
但是出于灵活性和简化配置的目标,我们希望系统能够自动将这样两条信息识别为一类。
我们的做法是:采用文本相似度算法进行相似度计算。
首先采用的方案是编辑距离。编辑距离是 Levenshtein 提出的用于计算字符串相似度的算法。
编辑距离是指由原字符串 S 变化到目标字符串 D 所需的最少操作次数,其中涉及的操作有:针对单个字符的插入、删除、替换。
图 4 evenshtein 算法原理图

但是,在生产实践中,编辑距离仍然存在一定的问题,性能消耗过大。
在生产环境实时检测的场景中,由于日志量巨大, 且需要与库中已有的语料库进行一一比对,所以不能满足实时性的要求。
所以我们又引入了 Jaccard 距离检测算法。
- 图 5 Jaccard 距离公式
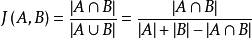
Jaccard 算法的优点在于简洁高效,每检测万条日志文本的平均耗时大概在 300ms 左右,能够极大的满足实时性要求。
然而,它同时带来的问题是算法过于简单,容易产生一定概率的误判。
所以,在最终使用的过程中,我们用 Jaccard 距离进行一次初步的筛选,将相似度相差较大的日志筛选掉;然后再使用编辑距离进行判断,即可大大减少其算法带来的性能消耗,又保证了最终结果的准确性。
- 图 6 文本比对算法流程图
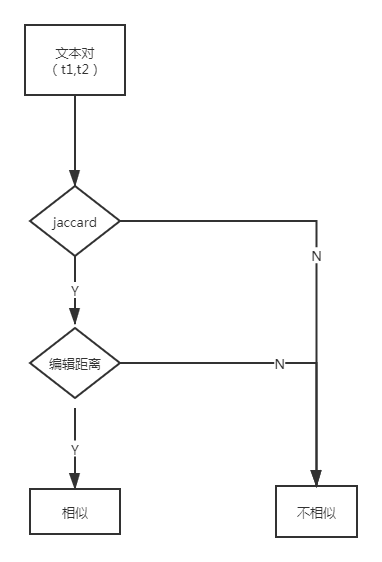
至此,我们就能对系统中所有的日志进行聚类收敛,从而将系统中产生的所有日志都赋予一条系统唯一 id。
简单标注后使用分类器
接下来,我们需要对日志文本进行分类。
这里首先是一个二分类问题,即日志产生时,是否携带异常信息,且会造成系统异常。
比如:OOM 类的异常日志一旦产生,则会造成系统的严重问题,此时应给予重点关注;NullPointerException 之类的问题可能会带来一些未知问题,需要 Warning 级别的告警,而一些常见问题则需要给予相对较低的处理优先级。
最为直观的做法是,根据日志级别进行简单的分级,比如[error]级别的日志即为有异常的日志,[info]级别的日志即为正常的日志。
但是,由于日志本身非标准化的特点,开发人员在打日志的过程中,没有标准可以参照,不同的开发人员打出的日志往往有着不同的特点;另外,不同的系统也有不同健壮性的特征,同样的日志在有的系统中可能会造成较大的影响,有的则不会。
基于此,我们需要对日志进行标注,将不同时间段的日志信息进行 safe/critical 的标注,并训练出相应的分类器,对日志文本进行文本分类。
这里,仍然采用上一步中训练得到的语料库,对每条日志文本进行 TF-IDF 向量化。
然后将向量化后的数据采用分类算法对其进行分类。我们分别采用了朴素贝叶斯、随机森林、fastCNN、xgboost 等对其进行训练, 最终在朴素贝叶斯和随机森林的分类下取得较好的分类结果。
最后,我们对聚类和分类后的信息按时间进行汇总,得到时间序列维度的数据,从而可以基于时间维度对不同的日志文本根据统计特征进行异常检测。再通过结合主机性能、网络运行情况等多种指标特征,进行综合指标异常检测及分析。
在效果方面,以我司 A 类重要级别子系统的数据收敛状况为例来进行讲解。
重要产品 A 类子系统共 116 个,每天产生的总日志数量平均为 900 万条。经过聚类算法收敛后的日志总量约为 1.5 万条,信息降噪比平均为 99.7%,有效的进行了日志的收敛和信息降噪。
从分类的准确率来讲,每个分类的平均准确率在 95%左右。
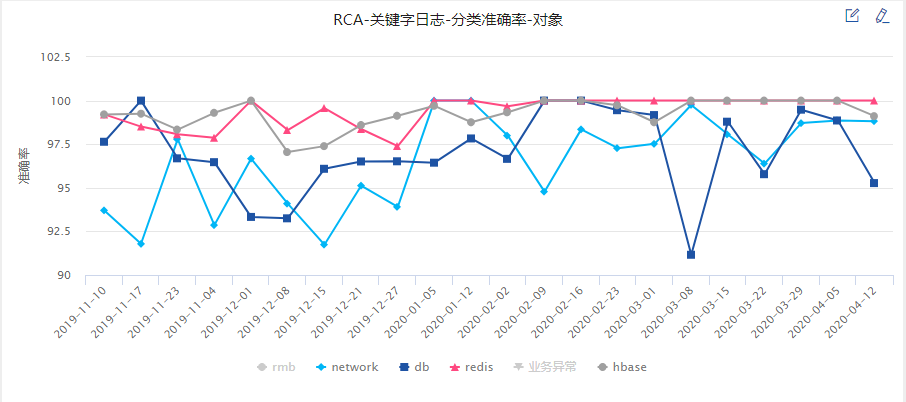
以上就是日志文本异常聚类及相似度检测的相关介绍,如果希望了解我们在智能运维中使用的机器学习算法以及支持根因分析的具体方法,请参阅该系列其他文章。
参考资料
https://www.infoq.cn/article/m78zwql2nc4sdpapcxpg
