webank 系列
| 智能运维系列(一) | AIOps 的崛起与实践:https://www.infoq.cn/article/fqUfkjhecOla1zKUKycN |
| 智能运维系列(二) | 智能化监控领域探索:https://www.infoq.cn/article/Qta6VCyjvHdoiJg5wKze |
| 智能运维系列(三) | 浅析智能异常检测:“慧识图”核心算法:https://www.infoq.cn/article/mryjNLXOlujV7fkQFUaL |
| 智能运维系列(四) | 曝光交易路径:https://www.infoq.cn/article/a72WeEMuM1O63iX1w0ZK |
| 智能运维系列(五) | 浅析基于知识图谱的根因分析系统:https://www.infoq.cn/article/cUYWKqYxrBamV7GwVVjM |
| 智能运维系列(六) | 如何通过智能化手段将运维管理要求落地?:https://www.infoq.cn/article/Wj4PJBg41SlA0fl6glIv |
| 智能运维系列(七) | 化繁为简:业务异常的根因定位方法概述:https://cloud.tencent.com/developer/news/665441 |
| 智能运维系列(八) | 事件指纹库:构建异常案例的“博物馆” https://www.infoq.cn/article/4hxfwtcfonjz7jjrfxzq |
| 智能运维系列(九) | 基于交易树的根因告警定位方法 https://www.infoq.cn/article/t1ytbqmbkp7xxdajkv1p |
| 智能运维系列(十) | 浅析根因告警的系统分析法 https://www.infoq.cn/article/m78zwql2nc4sdpapcxpg |
| 智能运维系列(十一) | 日志文本异常聚类及相似度检测 https://www.infoq.cn/article/kynuvjmfxhtommvdo35t |
| 智能运维系列(十二) | 智能运维的四大挑战和应对之道 https://www.infoq.cn/article/ytozqzowgujajaantrgh |
前言
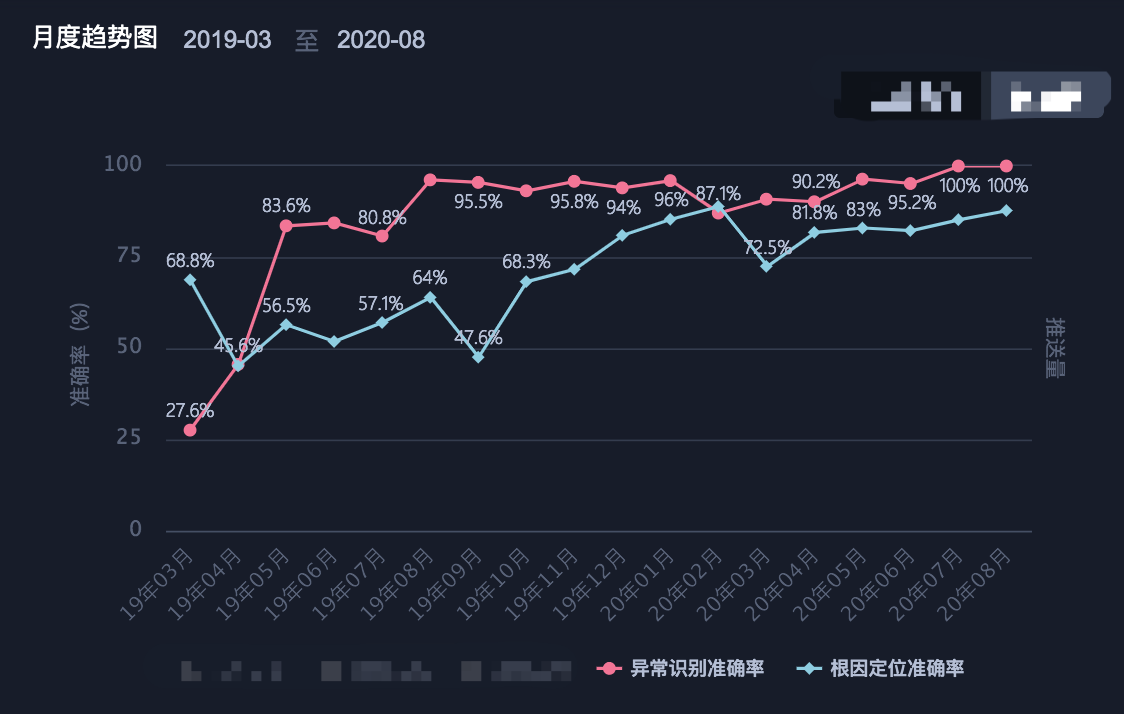
微众银行的 RCA 项目组成立了一年多,一直围绕着异常识别及根因定位开展工作,并以异常识别准确率和根因定位准确率作为最重要的衡量指标。
经过这一年多的努力,异常识别准确率从最初每个月的 30%左右到后来基本稳定在 95%以上,根因定位准确率从 50%左右到维持在 85%左右,目前两大指标仍在持续优化中,具体情况如下图:
图 1 异常识别准确率和根因定位准确率月度趋势
作为经历了整个 RCA 项目从 0 进化到当前状态的一份子,在本文中我主要为大家介绍我们所面临过或正在面临着的四大挑战,同时也会分享一些我们的解决办法及经验,希望对大家有帮助。
挑战 1. 及时性和准确率,如何平衡?
金融行业对应用系统运行的稳定性要求很高,关键交易要做到无损服务,那么如何及时的识别问题并通知责任方就非常重要。
但如果异常识别算法过于敏感,将会产生很多误告从而对运维同学造成骚扰,“宽松了容易漏告,严格了又会造成骚扰”。
经过对一段时间的实际案例的分析判断,我们使用了“算法+经验/规则”结合的方式来维持误告与漏告的平衡。
另外,判断误告漏告的标准要尽量做统一、清晰,这样算法在演进的过程中才能不断进步,防止前后矛盾。
当算法识别到一个指标异常时,系统会及时通知业务运维的同学,随着时间的推移,有可能发现更多指标曲线出现异常,不同的异常指标的曲线反应了不同的影响范围。
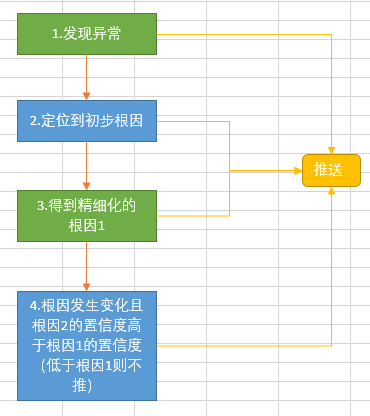
一个检测周期内(一般是 1 分钟)如果识别到了异常,我们先发出异常预警,同时轮询根因定位结果,当异常指标发生变化后,再次启动新的根因分析,如此往复,一旦根因有结果了取最新的结果推送根因,为运维人员提供定位方向。从而在及时性和准确性之间找到一个平衡,具体流程见图 2。
由于目前整个根因分析过程在 2 分钟之内完成,结果也相对稳定,故我们目前只在图 2 中的 1、3 进行推送,避免短时间内多次推送消息造成骚扰。
- 图 2 异常推送策略
挑战 2. 算法和经验/规则,哪个更有效?
RCA 是一个 AI 算法工程化的项目,开始时我们更倾向于使用算法来实现所需功能,但算法的调参过程周期比较长,对于一些根据专家经验较明显的特征,通过加一些规则能更快的达到预期效果。
经过我们的实践,无论是在异常识别方面还是根因定位方面,“算法+经验/规则”都是更加快速有效的解决方案。
在异常识别方面,通过算法已经可以覆盖大部分异常场景的识别,这可以达到 RCA 的早期目标。
随着 RCA 项目的持续推进,标准和要求越来越高。
有一段时期,运维人员常常反馈我们识别的异常是误告,我们通过分析这段时间的异常事件,发现大多运维人员认为是误告的事件都是时延指标突增。
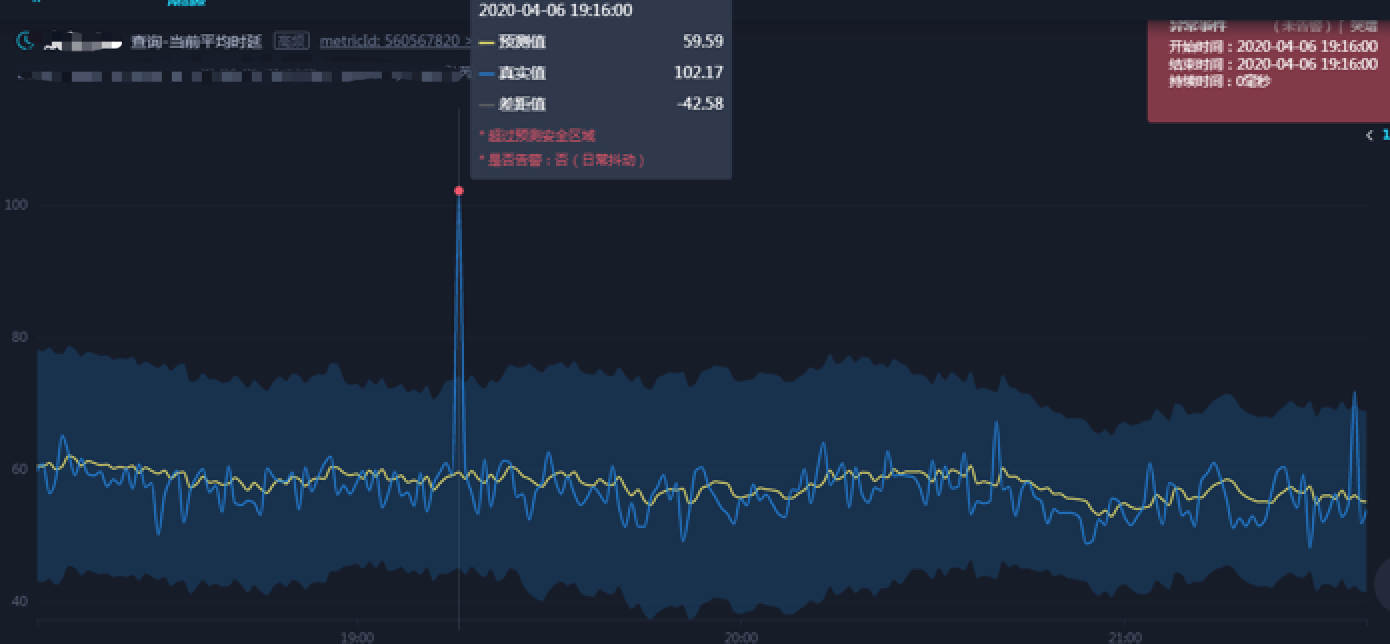
有些时延指标波动的确较大,常常出现毛刺(见图 3),对比历史来说,这些毛刺都是小概率事件,算法判断为异常,但对于运维人员来说,把毛刺当做异常显得过于敏感,如果每个毛刺都投入人力分析也不现实。
为了快速调整这种因为算法太敏感导致的误告,我们想到传统异常识别中常用的思路——设置阈值,相当于人工观察几分钟,如果只是毛刺就暂且忽略不当做异常,如果持续时间超过阈值才当做异常。
如果仅通过调整算法来解决这个问题可能需要更多的时间去调参以适配所有指标曲线。
当然,这种做法也有弊端,例如对专家经验的依赖大,当指标曲线的行为发生变化时很难及时发现从而及时调整参数,所以后续我们也会将“观察分钟数”参数由人工定义优化为算法自动学习自动调整。
图 3 时延指标毛刺
在根因定位方面,我们依然选择使用“算法+经验/规则”的方式,包括将专家经验进行总结,沉淀到算法中。
挑战 3. 实时数据和历史数据,哪个更可信?
在异常识别中,常规做法就是使用历史曲线的趋势来预测实时曲线的趋势。
而在根因定位中,我们最初只重点关注了实时数据,忽略了历史数据。
那么历史数据在根因定位中是否也同样具有参照意义呢?经过实践证明,在根因定位中历史数据也和实时数据一样重要。
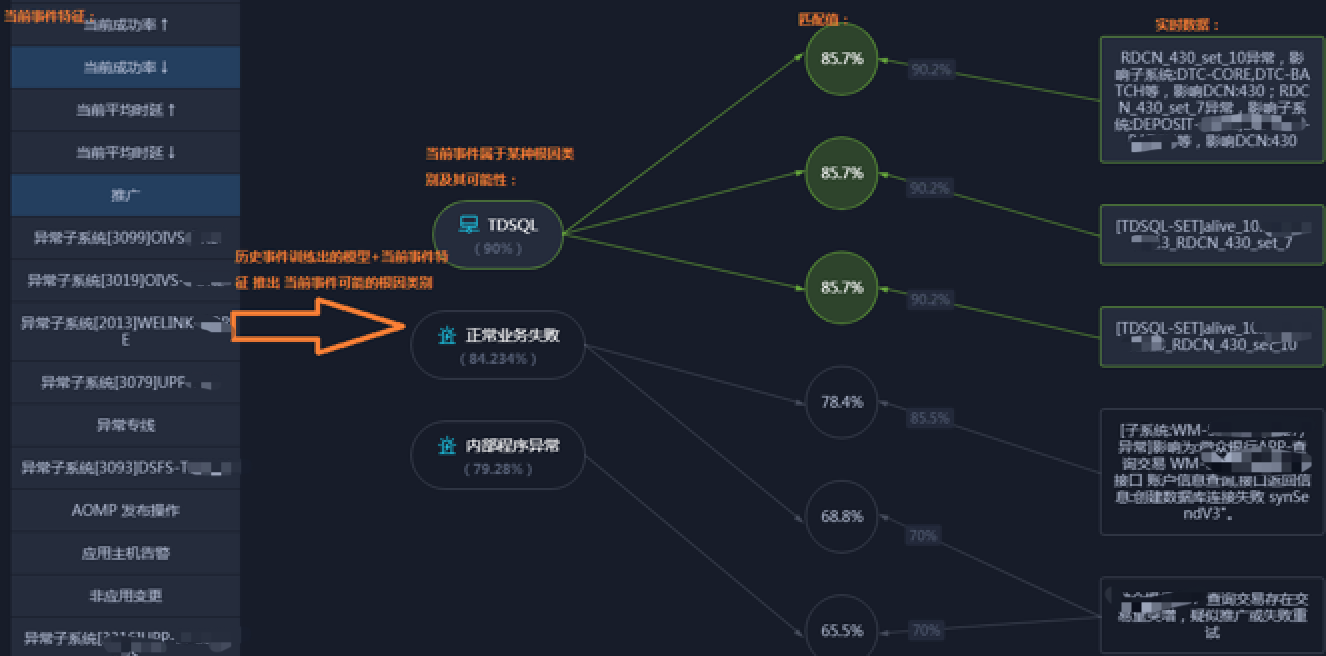
基于“拥有相似特征的异常事件极大可能是同一根因导致的”,我们对所有的异常事件进行了特征提取及根因分类,形成了历史事件库,使用神经网络算法训练模型,当出现新的异常事件时,我们提取新事件的特征,通过根据历史事件库训练出的模型,得出新异常事件最可能属于哪些根因类别,每个根因类别会计算出一个相似度(异常属于这个根因类别的可能性),再与异常发生时挖掘到的实时数据做匹配,那么匹配值最高的就最可能是这个事件的根因,这个过程见图 4。
例如根据模型计算出新事件的根因类别可能是数据库异常,而实时数据中存在数据库变更、数据库主机告警等信息,那么匹配值会非常高,从而推断出这个事件极有可能是数据库变更或数据库主机异常导致。
而当新事件从未出现过,提取的特征不能很好的推断出这个事件属于什么根因类别,即根据历史事件库训练出的模型新异常事件属于各根因类别的可能性都较低时,我们选择相信实时数据的分析结果,不和历史数据做匹配,这样也对这部分事件的根因定位进行了覆盖。
图 4 结合历史数据和实时数据进行根因定位
挑战 4. 当掌握全面的信息时,如何聚焦到有用的信息上?
根因定位掌握的数据源越多越好,挖掘到的数据越全面越好,但我们需要用有效的方式去评估各类数据源以及各类数据的置信度。
对于信息使用者来说,并不需要看到底层的所有数据,他们更希望直接看到对他们最有用的数据,甚至只想看到最终的结论——我该做些什么来处理这个异常?
而做到这一点实现数据可视化就很重要,我们需要从繁杂的数据中找到信息使用者最想要了解和最需要关注的数据,形成主要的推导链,让信息使用者聚焦到这些有用的数据上,在能快速了解推导过程的同时建立起对推导方式的认同和信赖,从而快速采取对应的措施来解决异常。
所以无论是实现方还是信息使用者,都希望可以一眼看到最有用的信息。
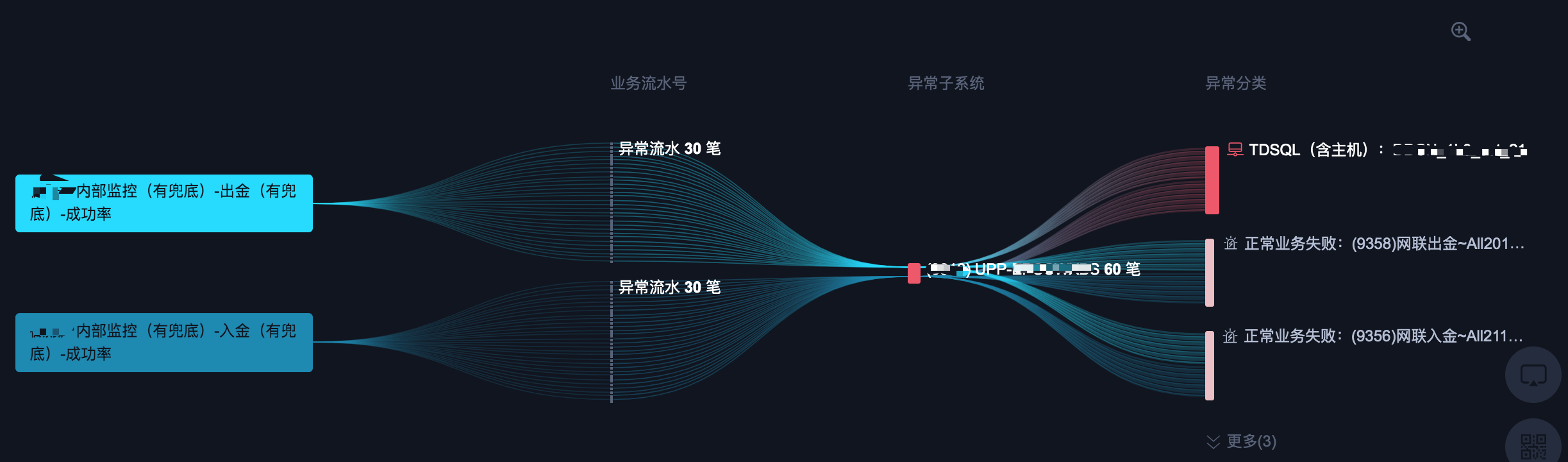
面对这个诉求,我们通过图形化的推到展示推到过程。
图 5 根因定位推到可视化
以上就是在我们在智能根因分析过程中的面临四个挑战以及我们的一些思考,欢迎面临同样挑战或有好的解决方案的朋友和我们交流。
如果希望了解我们在智能运维中使用的机器学习算法以及支持根因分析的具体方法,请参阅该系列其他文章。
参考资料
https://www.infoq.cn/article/m78zwql2nc4sdpapcxpg
