webank 系列
| 智能运维系列(一) | AIOps 的崛起与实践:https://www.infoq.cn/article/fqUfkjhecOla1zKUKycN |
| 智能运维系列(二) | 智能化监控领域探索:https://www.infoq.cn/article/Qta6VCyjvHdoiJg5wKze |
| 智能运维系列(三) | 浅析智能异常检测:“慧识图”核心算法:https://www.infoq.cn/article/mryjNLXOlujV7fkQFUaL |
| 智能运维系列(四) | 曝光交易路径:https://www.infoq.cn/article/a72WeEMuM1O63iX1w0ZK |
| 智能运维系列(五) | 浅析基于知识图谱的根因分析系统:https://www.infoq.cn/article/cUYWKqYxrBamV7GwVVjM |
| 智能运维系列(六) | 如何通过智能化手段将运维管理要求落地?:https://www.infoq.cn/article/Wj4PJBg41SlA0fl6glIv |
| 智能运维系列(七) | 化繁为简:业务异常的根因定位方法概述:https://cloud.tencent.com/developer/news/665441 |
| 智能运维系列(八) | 事件指纹库:构建异常案例的“博物馆” https://www.infoq.cn/article/4hxfwtcfonjz7jjrfxzq |
| 智能运维系列(九) | 基于交易树的根因告警定位方法 https://www.infoq.cn/article/t1ytbqmbkp7xxdajkv1p |
| 智能运维系列(十) | 浅析根因告警的系统分析法 https://www.infoq.cn/article/m78zwql2nc4sdpapcxpg |
| 智能运维系列(十一) | 日志文本异常聚类及相似度检测 https://www.infoq.cn/article/kynuvjmfxhtommvdo35t |
| 智能运维系列(十二) | 智能运维的四大挑战和应对之道 https://www.infoq.cn/article/ytozqzowgujajaantrgh |
| 智能运维系列(十四) | 人与技术相结合的异常管理实践 https://www.infoq.cn/article/m60mowqqi0u2yxcshpfh |
前言
数字银行智能运维系列专题已经进入尾声,已经发表的文章从管理和技术上全面解释了如何构建智能根因分析系统。
这篇文章主要阐述系统背后的 IT 异常事件管理思路,包含异常识别、异常影响评估和通报等,通过自动化、智能化手段来提升异常事件管理效率,帮助缩短平均修复时间(MTTR ,Mean Time to Repair)、增加平均无故障时长(MTTF,Mean Time To Failures),从而达到降低业务损失的目的。
一个异常事件的生命周期包含发现阶段、处理及恢复阶段和总结回顾阶段,每个阶段都有对应的管理要求: 发现阶段需要快速识别异常事件并通报给关联人员;处理及恢复阶段需要实时监控异常影响并进行必要的管理升级,确定异常事件恢复方案并快速恢复服务;总结回顾阶段需要对异常事件进行总结,包括异常的实际影响,后续如何避免重复发生等。
下文将对异常事件全生命周期管理各个阶段进行详细的阐述。
图 1 异常事件生命周期管理
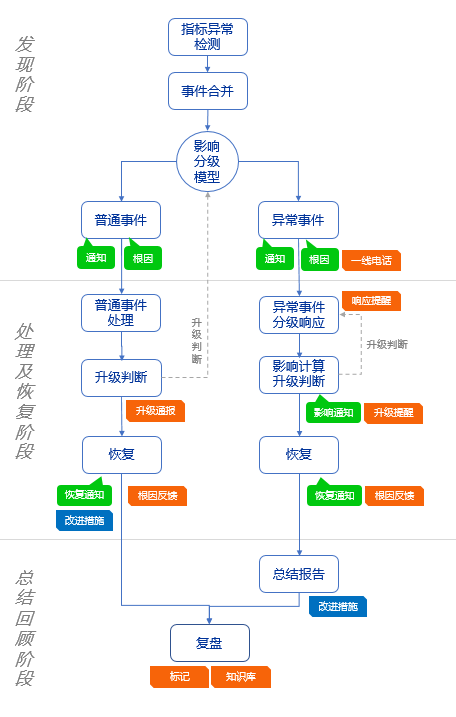
异常发现
异常事件管理的关键是能及时识别到异常并启动异常事件应急响应机制,调度 IT 各项资源尽快恢复服务、降低影响。
微众银行根据实际造成的影响,将异常事件分为多个级别。评级维度包括是否影响关键产品、影响时长、影响量、影响交易占比等。不同的异常事件级别有对应的响应要求和升级要求。
通过 RCA 的异常检测智能算法实现了关键产品业务指标(交易量、成功率、时延)异动的自动发现和预警,即使用机器学习算法实现无阈值的曲线异动识别。算法检测出来的离散的异常指标先经过聚合处理,变成一个个事件。
每个事件再根据影响程度定义不同的级别,以确定后续的处理流程。
异常影响分级模型排除恢复时间的不确定性,将影响业务的重要性、影响面、异常指标严重程度作为评估参数,其中业务重要性通过产品重要性、场景重要性来衡量,影响面通过影响的产品、场景数量来衡量。每个异常都会根据三类参数、通过算法计算出影响分值,匹配出对应的异常事件级别,具体过程如下图所示:
图 2 异常影响分级模型示意图
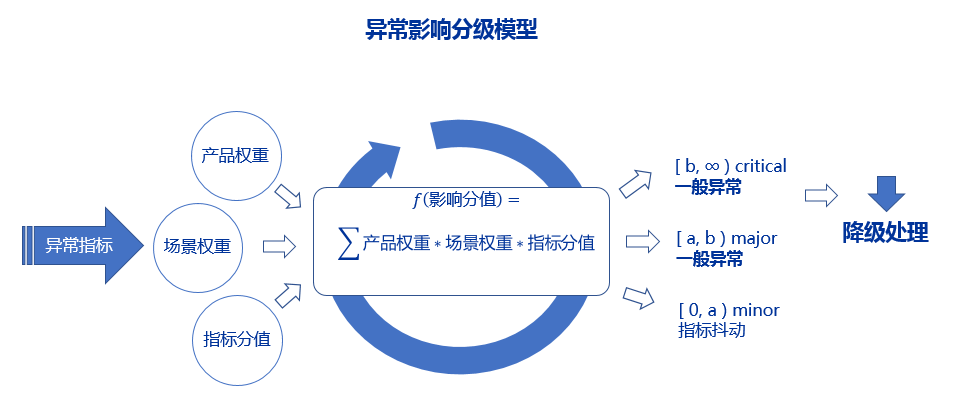
模型解释:
异常事件影响=∑产品系数 * 场景系数 * 指标分值
产品系数:不同产品的业务重要程度; 场景系数:同一个产品下不同场景的重要程度; 指标分值:不同业务指标所反映的严重程度不同,分值不同。
以上模型同时实现对部分已知低风险场景的降级处理,比如单个用户的重复尝试、计划性维护、周期性业务活动等带来的指标波动。
异常影响分级模型投入使用一年多,根据模型计算的异常事件级别准确率达 95%以上,能有效地完成事件级别的初判。
下图是一个异常事件的影响级别展示示例:
图 3 某次异常的影响及级别
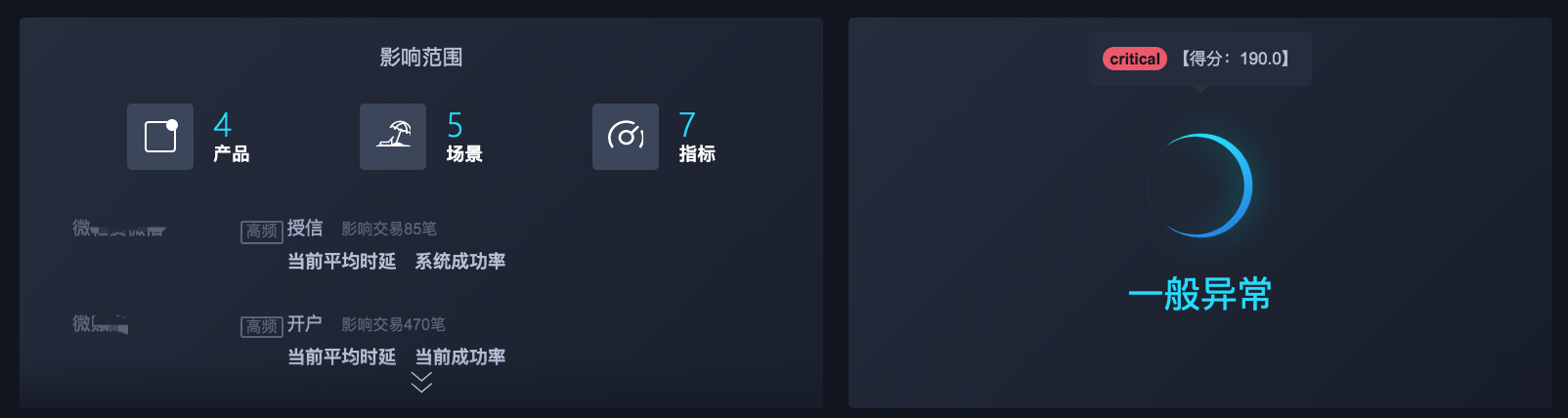
不同分级的事件对应不同的处理流程和通报要求。
普通事件自动通知产品运维团队,按事件管理流程处理。
异常事件除了普通通知手段外,还启动电话通知,并同时进行管理升级,自动通报管理层相关领导,启动异常事件响应机制。
异常处理过程中的持续监测
随着异常事件的动态发展,异常涉及的产品和指标可能会发生变化,事件级别也会随着动态更新,并触发相应的升级机制。
在异常事件持续过程中会周期性计算从异常开始到当前时间对业务的实际影响,并通报相关人员。
工作时段、非工作时段分别由不同角色人员负责升级提醒,双重保障机制。
当 RCA 异常事件涉及的产品和指标部分恢复时,智能分析平台将动态更新指标恢复比例,让异常事件处理团队实时掌握事件处理进展。
在恢复过程中,异常事件处理团队需反馈事件原因,一线运维团队协助跟踪和反馈,作为后续总结及复盘的依据。
异常总结及回顾
异常事件恢复后,会进行两个层面的回顾:
1.关注事件本身,后续如何避免类似事件再次发生:
普通事件总结需要改进的点报问题跟进处理;异常事件须深度回顾处理过程,总结存在问题,在技术上、管理机制上制订改进措施,形成总结报告,并跟踪报告中记录的改进项的完成状态,未来将观察是否有相同原因导致的异常事件发生,从而验证改进措施的效果。
2.关注 RCA 异常检测和根因分析,需优化的方面包含:
时效方面:异常开始、异常发现、异常通报、根因结论推送各环节是否满足时效要求,有没有可优化的空间,如何进一步提高;
异常发现方面:是否漏告,事件合并是否合理,是否误告;
根因分析方面:导致事件发生的真实原因是什么,RCA 根因是否准确,根因证据链是否完整,各类证据(告警、变更、日志、业务操作等)是否具备,数据是否准确,推送是否及时。
通过复盘,可以推动在如下方面做优化:
算法优化,提升异常识别准确率:通过对异常事件识别准确率的持续分析与统计,发现指标之间的关系与指标自身的特点,修正异常识别算法;
运维各方面数据的完善,辅助根因分析:持续推动完善各类监控,每个异常场景能捕捉到作为根因证据的告警;持续完善变更视图,明确每一类变更可能产生的业务影响,快速定位异常是否与变更相关;
专家知识库完善,提升根因分析准确率:针对新的异常特点,总结专家经验形成新的推导规则,完善知识库。
总结和回顾环节对异常事件管理异常重要,意义在于:
减少影响产品和服务的事件量,提高系统稳定性;
提高异常事件检测和根因定位效率,以快速恢复异常。
只有总结和回顾环节真正得到落实,建立有效的反馈机制,才能让 RCA 变得越来越智能,发挥更大的作用。
结束语
RCA 项目实施后,通过技术手段给异常事件管理带来了很多收益:
异常事件管理效率大幅提升:异常事件通报及时率,升级识别准确率是以往管理上的两个痛点,现在都得到了很好的解决,根因分析准确率不断提升,缩短了异常事件恢复时长;
运维更加规范化:RCA 全面使用生产环境的各项数据来支持根因分析,包括监控告警、基础配置、变更操作记录、应用日志、业务交易流水等,倒推相关信息规范化管理,以满足 RCA 输入数据标准化的要求,运维数据更加规范化;
专家经验持续积累:每位运维人员都是某个领域的专家,RCA 的持续反馈机制可以将专家大脑中的隐性知识逐步分享出来,应用到异常检测和根因定位中,并将运维人员从日常排查的重复工作中释放出来,使其有更多的精力去思考架构上、机制上的深层次问题,从而实现进一步的改进和提升。
另外,在异常分析过程中,我们自始至终贯彻了一个核心思想:一方面通过自动化和智能化帮助异常事件更加透明和高效,另一方面,通过科学管理手段,并结合运维专家的专业能力,提供全流程支持。
当异常事件升级到较严重的程度,需要专业的运维管理人员决策和调度协调线下资源,确定异常事件的恢复方案、推动方案落地实施。在整个异常结束后,也需要专业的运维团队进行异常的回顾与分析,提出改进措施和跟踪改进方案的落地,持续指导 RCA 的优化方向。
对于自动化和智能化而言,运维管理人员充当了老师的角色,提供源源不断的专家经验,监控或批改自动化或智能化的输出结论,保障运维平台建设始终服务于运维管理要求。
欢迎各位朋友交流指正。如果希望了解我们在智能运维中使用的机器学习算法以及支持根因分析的具体方法,请参阅该系列其他文章。
参考资料
https://www.infoq.cn/article/m78zwql2nc4sdpapcxpg
