拼写纠正系列
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
中文拼写纠正
最基本的思想,将所有的常见错别字整理为字典。
但是这个字典的数量实际上非常有限,所以还是要借助算法。
本文简单地讲解如何使用n-gram模型结合汉字拼音来作中文错别字纠错,然后介绍最短编辑距离在中文搜索纠错方面的应用;
最后从依赖树入手讲解如何作文本长距离纠错(语法纠错),并从该方法中得到一种启示,利用依赖树的特点结合ESA算法来做同义词的查找。
n-gram模型
在中文错别字查错情景中,我们判断一个句子是否合法可以通过计算它的概率来得到,假设一个句子 S = {w1, w2, …, wn},则问题可以转换成如下形式:
P(s) = P(w1, w2, ..., wn) = P(w1) * P(w2|w1) * P(w3|w2,w1) *....*P(wn|wn-1,wn-2,...,w2,w1)
P(S) 被称为语言模型,即用来计算一个句子合法概率的模型。
但是使用上式会出现很多问题,参数空间过大,信息矩阵严重稀疏,这时就有了n-gram模型,它基于马尔科夫模型假设,一个词的出现概率仅依赖于该词的前1个词或前几个词,则有
2-gram
一个词的出现仅依赖于前1个词,即Bigram(2-gram):
P(s) = P(w1, w2, ..., wn) = P(w1) * P(w2|w1) * P(w3|w2) *....*P(wn|wn-1)
3-gram
一个词的出现仅依赖于前2个词,即Trigram(3-gram):
P(s) = P(w1, w2, ..., wn) = P(w1) * P(w2|w1) * P(w3|w2,w1) *....*P(wn|wn-1,wn-2)
当n-gram的n值越大时,对下一个词的约束力就越强,因为提供的信息越多,但同时模型就越复杂,问题越多,所以一般采用bigram或trigram。
例子
下面举一个简单的例子,说明n-gram的具体使用:
n-gram 模型通过 计算极大似然估计(Maximum Likelihood Estimate)构造语言模型,这是对训练数据的最佳估计,对于Bigram其计算公式如下:
P(wi|wi-1) = count(wi, wi-1)/count(wi-1)
对于一个数据集,假设count(wi)统计如下(总共8493个单词):

而 count(wi, wi-1)统计如下:
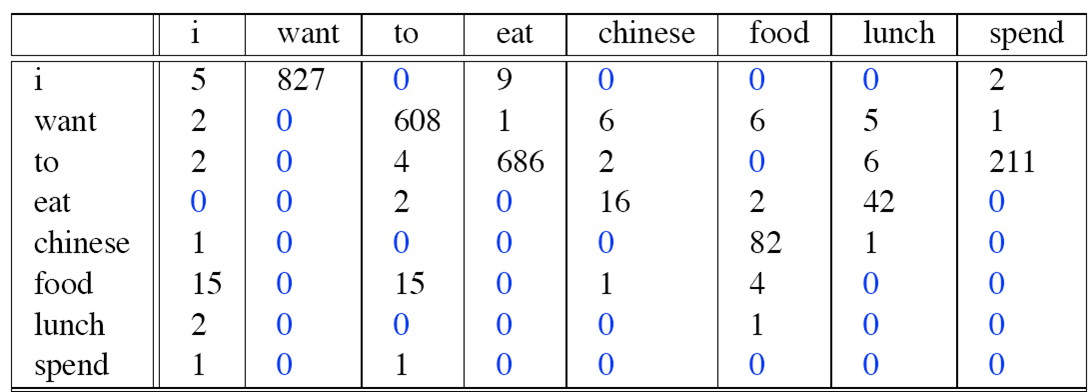
则Bigram概率矩阵计算如下:
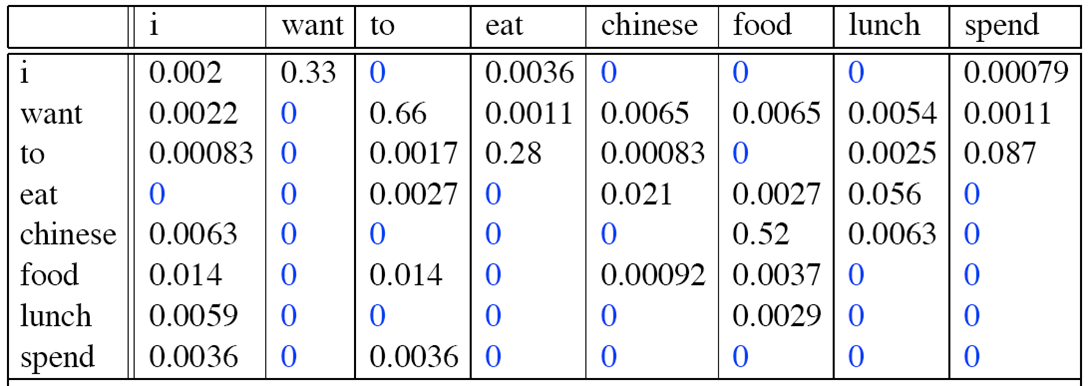
句子“I want to eat Chinese food”成立的概率为:
P(I want to eat Chinese food) = P(I) * P(want|I) * P(to|want) * P(eat|to) * P(Chinese|eat) * P(food|Chinese)
= (2533/8493) * 0.33 * 0.66 * 0.28 * 0.021 * 0.52。
接下来我们只需要训练确定一个阀值,只要概率值≥阀值就认为句子合法。
为了避免数据溢出、提高性能,通常会使用取log后使用加法运算替代乘法运算,即
ps: 取 log 是数据的标准化。
log(p1*p2*p3*p4) = log(p1) + log(p2) + log(p3) + log(p4)
可以发现,上述例子中的矩阵存在0值,在语料库数据集中没有出现的词对我们不能就简单地认为他们的概率为0,这时我们采用拉普拉斯矩阵平滑,把0值改为1值,设置成该词对出现的概率极小,这样就比较合理。
用途
有了上面例子,我们可以拿n-gram模型来做选择题语法填空,当然也可以拿来纠错。
中文文本的错别字存在局部性,即我们只需要选取合理的滑动窗口来检查是否存在错别字,下面举一个例子:
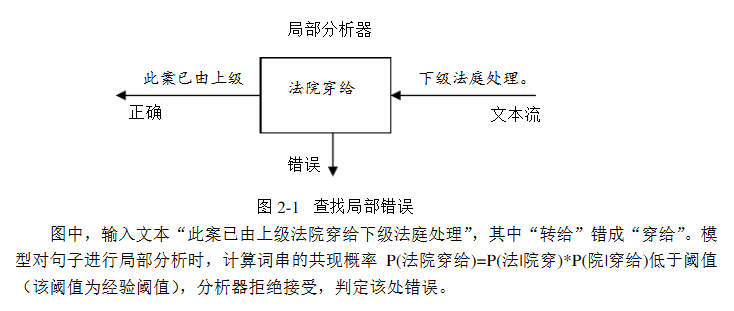
我们可以使用n-gram模型检查到“穿”字打错了,这时我们将“穿”字转换成拼音“chuan”,再从词典中查找“chuan”的候选词,一个一个试填,用n-gram检查,看是否合理。
这就是n-gram模型结合汉字拼音来做中文文本错别字纠错了。
汉字转拼音可以使用 Java 库 pinyin。
最短编辑距离
当然,现实生活中也存在汉字拼音没打错,是词语选错了;
或者n-gram检查合理但词语不存在,例如:搜索琅琊榜,打成了狼牙棒。
这时就用到最短编辑距离了,对于这种热搜词,我们仅需记录n-Top,然后用最短编辑距离计算相似度,提供相似度最高的那个候选项就可以了。
编辑距离
编辑距离,又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。
许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
例如将kitten一字转成sitting:
sitten (k→s)
sittin (e→i)
sitting (→g)
俄罗斯科学家Vladimir Levenshtein在1965年提出这个概念。它是一种DP动态规划算法,在POJ或ACM算法书上有类似的题目。主要思想如下:
首先定义这样一个函数Edit(i, j),它表示第一个字符串的长度为i 的子串到第二个字符串的长度为j 的子串的编辑距离。
显然可以有如下动态规划公式:
if (i == 0 且 j == 0),Edit(i, j) = 0
if (i == 0 且 j > 0),Edit(i, j) = j
if (i > 0 且j == 0),Edit(i, j) = i
if (i ≥ 1 且 j ≥ 1) ,Edit(i, j) = min{ Edit(i-1, j) + 1, Edit(i, j-1) + 1, Edit(i-1, j-1) + F(i, j) },
其中,当第一个字符串的第i 个字符不等于第二个字符串的第j 个字符时,F(i, j) = 1;否则,F(i, j) = 0。
英文实现
这个可以参考 word-checker 英文实现。
import re
from collections import Counter
def words(text): return re.findall(r'\w+', text.lower())
WORDS = Counter(words(open('big.txt').read()))
def P(word, N=sum(WORDS.values())):
"Probability of `word`."
return WORDS[word] / N
def correction(word):
"Most probable spelling correction for word."
return max(candidates(word), key=P)
def candidates(word):
"Generate possible spelling corrections for word."
return (known([word]) or known(edits1(word)) or known(edits2(word)) or [word])
def known(words):
"The subset of `words` that appear in the dictionary of WORDS."
return set(w for w in words if w in WORDS)
def edits1(word):
"All edits that are one edit away from `word`."
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [L + R[1:] for L, R in splits if R]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R)>1]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters]
inserts = [L + c + R for L, R in splits for c in letters]
return set(deletes + transposes + replaces + inserts)
def edits2(word):
"All edits that are two edits away from `word`."
return (e2 for e1 in edits1(word) for e2 in edits1(e1))
工作原理
word –> w correct word –> c
p(c|w)=p(w|c)∗p(c) / p(w)
p(c)为Language Model
| p(w | c)为Error Model |
c ∈ candidates为Candidate Model
argmax 为 Selection Mechanism
其中
p(c)可从预料库里统计而得,简单的 frequence / sum_number
| p(c | w) 需要 data on spelling errors |
实际操作
在没有data on spelling errors的情况下,将”词典里的词“、 ”1 编辑距离“、“2 编辑距离”、“不修正“的权重依次下调。
改进
对于 p(c) 影响因素是未登录词。
比如:
correction(‘addresable’) => ‘addresable’ (0); expected ‘addressable’ (0)
应该修正为addressable的情况却未修正addresable,因为词典里没有addressable这个词。
办法也许是加多数据,也可以是给词加上后缀、前缀、复数等(对于英文)。
对于p(w|c)
correction(‘adres’) => ‘acres’ (37); expected ‘address’ (77)
在没有data on spelling errors的情况下,由于将 ”1 编辑距离“的权重设置得高于“2 编辑距离”,所以错误的修正了。
关键是改善Error Model。
最有效的改善
让模型观察更多的上下文来决定是否修正、怎么修正。
这个可以依赖于 n-gram 等进行辅助,而不会是简单的只靠编辑距离。
中文的类似实现
英文的letters只用26个字母来做替换、插入就行了,中文的就多得多多了。
所以程序就会慢得不能忍。
以下的想法也许有帮助:
(1)同音字/谐音字
(2)形近字
(3)同义词
(4)字词乱序、字词增删
美团的实现方式
- 支持前缀匹配原则
在搜索框中输入“海底”,搜索框下面会以海底为前缀,展示“海底捞”、“海底捞火锅”、“海底世界”等等搜索词;输入“万达”,会提示“万达影城”、“万达广场”、“万达百货”等搜索词。
- 同时支持汉字、拼音输入
由于中文的特点,如果搜索自动提示可以支持拼音的话会给用户带来更大的方便,免得切换输入法。比如,输入“haidi”提示的关键字和输入“海底”提示的一样,输入“wanda”与输入“万达”提示的关键字一样。
- 支持多音字输入提示
比如输入“chongqing”或者“zhongqing”都能提示出“重庆火锅”、“重庆烤鱼”、“重庆小天鹅”。
- 支持拼音缩写输入
对于较长关键字,为了提高输入效率,有必要提供拼音缩写输入。比如输入“hd”应该能提示出“haidi”相似的关键字,输入“wd”也一样能提示出“万达”关键字。
- 基于用户的历史搜索行为,按照关键字热度进行排序
为了提供suggest关键字的准确度,最终查询结果,根据用户查询关键字的频率进行排序,如输入 [重庆,chongqing,cq,zhongqing,zq] —> [“重庆火锅”(f1),“重庆烤鱼”(f2),“重庆小天鹅”(f3),…],查询频率f1 > f2 > f3。
中文语法纠错
之前参加了中文语法错误诊断评测CGED(ACL-IJCNLP2015 workshop)比赛,我负责的是Selection 部分,我们来看官方给出的样例(Redundant、Missing、Selection、Disorder分别对应4种语法错误):

比赛过程中有想到使用依存树来解决Selection(语法搭配错误)问题,语法搭配与其说是语法范畴,倒不如说是语义概念,例如“那个电影”我们判断“个”错了是依据“电影”一词来判断,又如“吴先生是修理脚踏车的拿手”判断“拿手”错了是依据“是”一字,“拿手”是动词,怎么能采用“是+名词”结构呢?
但是当时事情比较多各种手忙脚乱前途未卜,所以没做出来。
后来上网查论文看到一篇《基于n-gram及依存分析的中文自动差错方法》,记得是2年前看到过的,当时对依存树还不理解所以没在意论文的后半部,现在理解了,写东西也有个理论支撑,没想到想法好有缘。
依存树
词与词之间的搭配是看两者之间的语义关联强度,而依存树的边正可以用来体现这种语义关联度,如果一个句子存在Selection语法错误,那么建成依存树也应该存在一条边是不合理的,我们可以用这条边来判断是否出现了语法错误。
在上述论文中作者将其称之为用来作长距离的中文纠错,而n-gram则是短距离中文纠错。
【论文截图】
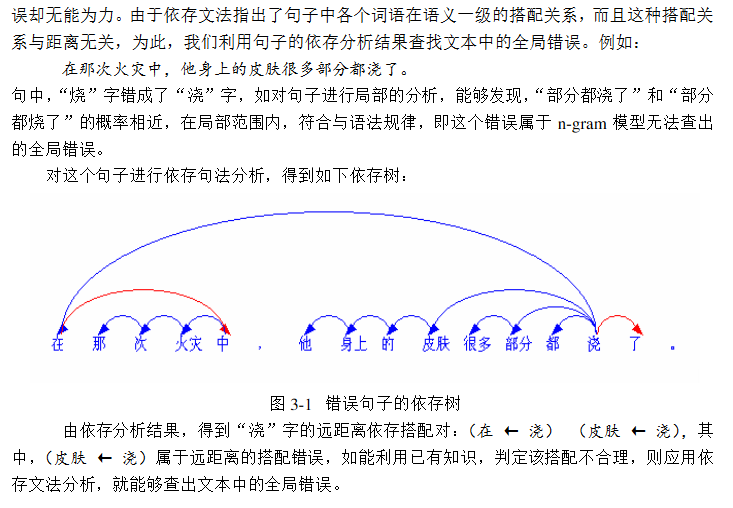
至于怎样利用已有知识,建立领域知识库,我们可以跑一遍正确的语料库数据集,统计那些语法正确的句子的依存树边… …CGED那个比赛所给的训练集有点奇怪,这个也是导致比赛过程不理想没把依存树想法做出来的原因。
我重新从网上找来了几个测试样例(语言学专业的课件PPT),我们来看一下再看如何拿依存树来做同义词聚类。
利用依存树做Selection语法侦错是有了,可是还要纠错呢,怎么实现一种纠错算法呢,当然是同义词替换了,会产生Selection类错误一般都是同义词误用。
我曾经拿HIT-IRLab-同义词词林(扩展版) 对比,效果不是很好,所以就有了后来的同义词聚类想法。

- 同义词
原作者这里说的同义词替换是一种思路。
还有两种方式:同音字,形近字。
依存树同义词查找
之前有接触过同义词聚类的论文,其中印象比较深刻的一篇是《Computing Semantic Relatedness using Wikipedia-based Explicit Semantic Analysis 》,也就是ESA(Explicit Semantic Analysis)算法。
ESA的主要思想就是,将一个Wiki词条看成一个主题概念,然后将词条下的解释文本先用TF-IDF逆文档频率过滤分词,再用倒排索引建立成(word-Topic),这样就可以构造主题向量,我们可以用这些主题向量来做语义相似度计算,完成同义词的查找。
ps: 这种方法工作量巨大,需要特别大的样本,基本词库可以选取一些整理好的的同义词词库。
但是这种工作对于我来说有点难以完成,后来在看Selection平行语料库时,发现一样有意思的东西,就是上图中标成黄色的边,瞬间突发奇想,是不是可以拿这些依存边作为一个Topic,利用倒排索引建立主题向量,这样就可以造出一大堆丰富的原始特征,然后再找个算法作特征选择过滤,再完成同义词查找… …
N-Gram 的数据来源
除了 sougou 的 2-gram 之外,如果我们想整理自己的 n-gram 应该怎么办?
数据的采集
第一步,我们需要用爬虫(或者基于以后的文本小说等等)获取大量的文本。
针对不同的领域,我们可以做不同的 n-gram 也是可行的。
分词
利用 segment 等分词框架进行分词,然后获取对应的 n-gram 进行聚类整理,最后统一持久化。
分词计算 n-gram 的方式
此处以 py-jieba 为例。
#coding=utf-8
'''
Created on 2018-2-6
'''
# 这里的_word_ngrams方法其实就是sklearn中CountVectorizer函数中用于N-Gram的方法,位置在D:\Python27\Lib\site-packages\sklearn\feature_extraction\text.py
def _word_ngrams(tokens, stop_words=None,ngram_range=(1,1)):
"""Turn tokens into a sequence of n-grams after stop words filtering"""
# handle stop words
if stop_words is not None:
tokens = [w for w in tokens if w not in stop_words]
# handle token n-grams
min_n, max_n = ngram_range
if max_n != 1:
original_tokens = tokens
tokens = []
n_original_tokens = len(original_tokens)
for n in xrange(min_n,
min(max_n + 1, n_original_tokens + 1)):
for i in xrange(n_original_tokens - n + 1):
tokens.append(" ".join(original_tokens[i: i + n]))
return tokens
- 测试代码
text = "我去云南旅游,不仅去了玉龙雪山,还去丽江古城,很喜欢丽江古城"
import jieba
cut = jieba.cut(text)
listcut = list(cut)
n_gramWords = _word_ngrams(tokens = listcut,ngram_range=(2,2))
print n_gramWords
for n_gramWord in n_gramWords:
print n_gramWord
# 我 去
# 去 云南旅游
# 云南旅游 ,
# , 不仅
# 不仅 去
# 去 了
# 了 玉龙雪山
# 玉龙雪山 ,
# , 还
# 还 去
# 去 丽江
# 丽江 古城
# 古城 ,
# , 很
# 很 喜欢
# 喜欢 丽江
# 丽江 古城
感受
从某种角度来讲,我们可以使用 n-gram 取实现一个分词工具。
同时,我们又可以利用分词工具,去处理 n-gram 实在是一件很奇妙的事情。
当然,前提是不要循环依赖,因为 jieba 分词主要还是基于 DP+HMM 算法实现的。
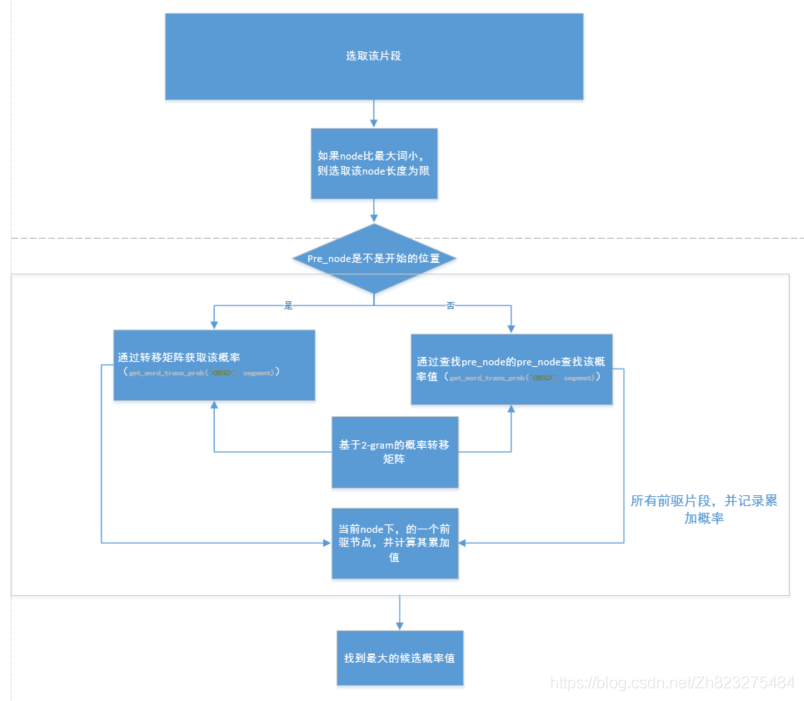
基于n-gram模型的中文分词
最大化概率2-gram分词算法
1、将带分词的字符串从左到右切分为w1,w2,…,wi;
2、计算当前词与所有前驱词的概率
3、计算该词的累计概率值,并筛选最大的累计概率则为最好的前驱点;
4、重复步骤3,直到该字符串结束;
5、从wi开始,按照从右到左的顺序,依次将没歌词的最佳前驱词输出,即字符串的分词结束。
算法框架
核心代码
word_dict = {}# 用于统计词语的频次
transdict = {} # 用于统计该词后面词出现的个数
def train(train_data_path):
transdict['<BEG>'] = {}#<beg>表示开始的标识
word_dict['<BEG>'] = 0
for sent in open(train_data_path,encoding='utf-8'):
word_dict['<BEG>'] +=1
sent = sent.strip().split(' ')
sent_list = []
for word in sent:
if word !='':
sent_list.append(word)
for i,word in enumerate(sent_list):
if word not in word_dict:
word_dict[word] = 1
else:
word_dict[word] +=1
# 统计transdict bi-gram<word1,word2>
word1,word2 = '',''
# 如果是句首,则为<beg,word>
if i == 0:
word1,word2 = '<BEG>',word
# 如果是句尾,则为<word,END>
elif i == len(sent_list)-1:
word1,word2 = word,'<END>'
else:
word1,word2 = word,sent_list[i+1]
# 统计当前次后接词出现的次数
if word not in transdict.keys():
transdict[word1]={}
if word2 not in transdict[word1]:
transdict[word1][word2] =1
else:
transdict[word1][word2] +=1
return word_dict,transdict
# 最大化概率2-gram分词
import math
word_dict = {}# 统计词频的概率
trans_dict = {}# 当前词后接词的概率
trans_dict_count = {}#记录转移词频
max_wordLength = 0# 词的最大长度
all_freq = 0 # 所有词的词频总和
train_data_path = "D:\workspace\project\\NLPcase\\ngram\\data\\train.txt"
from ngram import ngramTrain
word_dict_count,Trans_dict = ngramTrain.train(train_data_path)
all_freq = sum(word_dict_count)
max_wordLength = max([len(word) for word in word_dict_count.keys()])
for key in word_dict_count:
word_dict[key] = math.log(word_dict_count[key]/all_freq)
# 计算转移概率
for pre_word,post_info in Trans_dict.items():
for post_word,count in post_info:
word_pair = pre_word+' '+post_word
trans_dict_count[word_pair] = float(count)
if pre_word in word_dict_count.keys():
trans_dict[word_pair] = math.log(count/word_dict_count[pre_word])
else:
trans_dict[word_pair] = word_dict[post_word]
# 估算未出现词的概率,平滑算法
def get_unk_word_prob(word):
return math.log(1.0/all_freq**len(word))
# 获取候选词的概率
def get_word_prob(word):
if word in word_dict:
prob = word_dict[word]
else:
prob = get_unk_word_prob(word)
return prob
# 获取转移概率
def get_word_trans_prob(pre_word,post_word):
trans_word = pre_word+" "+post_word
if trans_word in trans_dict:
trans_prob = math.log(trans_dict_count[trans_word]/word_dict_count[pre_word])
else:
trans_prob = get_word_prob(post_word)
return trans_prob
# 寻找node的最佳前驱节点,方法为寻找所有可能的前驱片段
def get_best_pre_nodes(sent,node,node_state_list):
# 如果node比最大词小,则取的片段长度的长度为限
max_seg_length = min([node,max_wordLength])
pre_node_list = []# 前驱节点列表
# 获得所有的前驱片段,并记录累加概率
for segment_length in range(1,max_seg_length+1):
segment_start_node = node - segment_length
segment = sent[segment_start_node:node]# 获取前驱片段
pre_node = segment_start_node# 记录对应的前驱节点
if pre_node == 0:
# 如果前驱片段开始节点是序列的开始节点,则概率为<S>转移到当前的概率
segment_prob = get_word_trans_prob("<BEG>",segment)
else:# 如果不是序列的开始节点,则按照二元概率计算
# 获得前驱片段的一个词
pre_pre_node = node_state_list[pre_node]["pre_node"]
pre_pre_word = sent[pre_pre_node:pre_node]
segment_prob = get_word_trans_prob(pre_pre_word,segment)
pre_node_prob_sum = node_state_list[pre_node]["prob_sum"]
# 当前node一个候选的累加概率值
candidate_prob_sum = pre_node_prob_sum+segment_prob
pre_node_list.append((pre_node,candidate_prob_sum))
# 找到最大的候选概率值
(best_pre_node, best_prob_sum) = max(pre_node_list,key=lambda d:d[1])
return best_pre_node,best_prob_sum
def cut(sent):
sent = sent.strip()
# 初始化
node_state_list = []#主要是记录节点的最佳前驱,以及概率值总和
ini_state = {}
ini_state['pre_node'] = -1
ini_state['prob_sum'] = 0 #当前概率总和
node_state_list.append(ini_state)
# 逐个节点的寻找最佳的前驱点
for node in range(1,len(sent)+1):
# 寻找最佳前驱,并记录当前最大的概率累加值
(best_pre_node,best_prob_sum) = get_best_pre_nodes(sent,node,node_state_list)
# 添加到队列
cur_node ={}
cur_node['pre_node'] = best_pre_node
cur_node['prob_sum'] = best_prob_sum
node_state_list.append(cur_node)
# 获得最优路径,从后到前
best_path = []
node = len(sent)
best_path.append(node)
while True:
pre_node = node_state_list[node]['pre_node']
if pre_node ==-1:
break
node = pre_node
best_path.append(node)
# 构建词的切分
word_list = []
for i in range(len(best_path)-1):
left = best_path[i]
right = best_path[i+1]
word = sent[left:right]
word_list.append(word)
return word_list
基于ngram的前向后向最大匹配算法
算法描述
1、利用最大向前和向后的算法对待句子进行切分,分别得到两个字符串s1和s2
2、如果得到两个不同的词序列,则根据bi-gram选择概率最大的(此方法可以消除歧义);
3、计算基于bi-garm的句子生成概率;
代码
# 最要是基于bi-gram的最大前向后向算法,对中文进行分词
import math
from ngram import ngramTrain
from maxMatch import maxBackforward
from maxMatch import maxForward
train_data_path = "D:\workspace\project\\NLPcase\\ngram\\data\\train.txt"
word_counts = 0# 语料库中的总词数
word_types = 0#语料库中的词种类数目
word_dict,trans_dict = ngramTrain.train(train_data_path)
word_types = len(word_dict)
word_counts = sum(word_dict.values())
# 计算基于ngram的句子生成概率
def compute_likehood(seg_list):
p = 0
# 由于概率很小,对连乘取对数转化为加法
for pos,words in enumerate(seg_list):
if pos < len(seg_list)-1:
# 乘以后面的条件概率
word1,word2 = words,seg_list[pos+1]
if word1 not in trans_dict:
# 加平滑,让个该词至少出现1次
p += math.log(1.0/word_counts)
else:
# 加1平滑
fenzi, fenmu = 1.0,word_counts
# 计算转移概率,如p(w1/w2) 为在转移矩阵中trans_dict[word1][word2]在整行的占比
for key in trans_dict[word1]:
if key == word2:
fenzi +=trans_dict[word1][word2]
fenmu += trans_dict[word1][key]
# log(p(w0)*p(w1|w0)*p(w2|w1)*p(w3|w2)) == log(w0)+ log(p(w1|w0))+ log(p(w2|w1)) + log(p(w3|w2))
p +=math.log(fenzi/fenmu)
# 乘以第一个词的概率
if (pos == 0 and words !='<BEG>') or (pos == 1 and seg_list[0] == '<BEG>'):
if words in word_dict:
p += math.log((float(word_dict[words])+1.0)/word_types+word_counts)
else:
# 加1进行平滑
p +=math.log(1.0/(word_types+word_counts))
return p
# 然后进行分词
def cut_main(sent):
seg_list1 = maxForward.maxForwardCut(sent,5,word_dict)
seg_list2 = maxBackforward.maxBackforwadCut(sent,5,word_dict)
seg_list = []
# differ_list1和differ_list2分布及记录两个句子词序不同的部分,用于消除歧义
differ_list1 = []
differ_list2 = []
# pos1和pos2记录两个句子的当前字的位置,cur1和cur2记录两个句子的第几个词
pos1 = pos2 = 0
cur1=cur2 = 0
while 1:
if cur1 == len(seg_list1) and cur2 == len(seg_list2):
break
if pos1 == pos2:# 位置相同
if len(seg_list1[cur1]) == len(seg_list2[cur2]):# 对应的词的长度也相同
pos1 +=len(seg_list1[cur1])# 移到下一位置
pos2 += len(seg_list2[cur2]) # 移到下一位置
if len(differ_list1)>0:
# 说明此时得到两个不同的词序列,根据bi-gram选择概率大的
# 注意不同的时候哟啊考虑加上前面一个词和后面一个词,拼接的时候在去掉
differ_list1.insert(0,seg_list[-1])
differ_list2.insert(0,seg_list[-1])
if cur1 < len(seg_list1)-1:
differ_list1.append(seg_list1[cur1])
differ_list2.append(seg_list2[cur2])
p1 = compute_likehood(differ_list1)
p2 = compute_likehood(differ_list2)
if p1>p2:
differ_list = differ_list1
else:
differ_list = differ_list2
differ_list.remove(differ_list[0])
if cur1<len(seg_list1)-1:
differ_list.remove(seg_list1[cur1])
for words in differ_list:
seg_list.append(words)
differ_list1 = []
differ_list2 = []
seg_list.append(seg_list1[cur1])
cur1 +=1
cur2 +=1
elif len(seg_list1[cur1]) > len(seg_list2[cur2]):
differ_list2.append(seg_list2[cur2])# 记录的其实是前一个词
pos2 += len(seg_list2[cur2])
cur2 +=1
else:
differ_list1.append(seg_list1[cur1])# 记录的其实是前一个词
pos1 +=len(seg_list1[cur1])
cur1 +=1
else:
if pos1 + len(seg_list1[cur1]) == pos2 + len(seg_list2[cur2]):
differ_list1.append(seg_list1[cur1])
differ_list2.append(seg_list2[cur2])
pos1 += len(seg_list1[cur1])
pos2 += len(seg_list2[cur2])
cur1 += 1
cur2 += 1
elif pos1+len(seg_list1[cur1])>pos2+len(seg_list2[cur2]):
differ_list2.append(seg_list2[cur2])
pos2 += len(seg_list2[cur2])
cur2 += 1
else:
differ_list1.append(seg_list1[cur1])
pos1 += len(seg_list1[cur1])
cur1 += 1
return seg_list
总结
最大概率n-gram的方法是借鉴了动态规划方法寻找最大概率的路径,从而找到最佳的分词方法。
主要难点主要在于基于n-gram的前后向匹配算法,在分词过程中,需要用两个指针(记录字的位置和记录词的位置),找到不同的部分,在计算其句子生成的概率,从而消除具有歧义的分词的算法,这个可以避免前后向匹配算法造成的缺点。
