拼写纠正系列
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计、论文和开源实现。
感受
这是 2018 年的论文,基于混淆集的方式。
局限性比较大,但是不失为一种解决方案。
论文+实现
论文地址: https://aclanthology.org/D18-1273.pdf
源码地址:https://github.com/wdimmy/Automatic-Corpus-Generation
摘要
中文拼写检查(CSC)是一项具有挑战性但意义重大的任务,它不仅在许多自然语言处理(NLP)应用中作为预处理步骤,而且在日常生活中帮助阅读和理解文本。
然而,使用数据驱动的方法进行中文拼写检查时,存在一个主要限制,即标注语料库不足,无法充分应用算法和构建模型。本文提出了一种新颖的方法,通过自动生成拼写错误构建CSC语料库,这些错误分别是由视觉或语音相似的字符引起的,分别对应OCR(光学字符识别)和ASR(自动语音识别)方法。
基于构建的语料库,针对三个标准测试集,训练并评估了不同的模型。实验结果证明了该语料库的有效性,从而验证了我们方法的有效性。
1. 引言
拼写检查是检测和纠正文本中拼写错误的关键任务(Yu和Li,2014)。这一任务对于NLP应用(如搜索引擎(Martins和Silva,2004;Gao等,2010)和自动作文评分(Burstein和Chodorow,1999;Lonsdale和Strong-Krause,2003))至关重要,因为拼写错误不仅影响阅读,还可能完全改变文本片段的含义。尤其在中文处理过程中,拼写错误可能会更严重,因为它们可能影响诸如分词(Xue,2003;Song和Xia,2012)和词性标注(Chang等,1993;Jiang等,2008;Sun,2011)等基础任务。在导致拼写错误的所有原因中,一个主要原因是日常文本(如电子邮件和社交媒体帖子)中中文输入法的误用。
表1展示了两个此类中文拼写错误的例子。第一个错误的句子包含了一个误用的字符“己”(ji2),它的形状与其正确字符“已”(yi3)相似。在第二个错误句子中,框选的拼写错误“她”(ta1)与其对应的正确字符“他”(ta1)在语音上是相同的。
- T1
我们应该认真对待这些 **己** (ji2) 经发生的事 **已** (yi3)
在我们班上, **她** (ta1) 是一个很聪明的男孩 **他** (ta1)
表1: 两个包含拼写错误的中文句子。拼写错误以红色标记。
第一个句子包含一个视觉上相似的拼写错误,即已 (yi3) 被误拼为己 (ji2)。第二个句子包含一个语音上相似的拼写错误,即他 (ta1) 被误拼为她 (ta1)。
由于可用数据集的数量有限,许多先进的监督模型在这一领域很少被采用,这阻碍了CSC的发展。目前,一些主流方法仍然专注于使用无监督方法,即基于语言模型的方法(Chen等,2013;Yu等,2014;Tseng等,2015;Lee等,2016)。
因此,CSC技术的发展受到限制,直到目前,CSC的性能仍然不令人满意(Fung等,2017)。为了提高CSC的性能,最大的挑战是缺乏标注拼写错误的大规模语料库,而这样的语料库对于训练和应用监督模型具有很高的价值。数据缺乏的问题主要是由于拼写错误的标注是一项昂贵且具有挑战性的任务。
为了解决数据不可用的问题,并促进CSC的基于数据驱动的方法,本文提出了一种新颖的方法,通过自动构建带有标注拼写错误的中文语料库。
具体而言,由于中文拼写错误主要来源于视觉和语音相似字符的误用(Chang,1995;Liu等,2011;Yu和Li,2014),我们提出了基于OCR和ASR的方法来生成上述两种类型的误用字符。
值得注意的是,与从错误句子中检测拼写错误不同,我们提出的方法旨在自动生成带有标注拼写错误的文本,类似于表1中的错误。借助OCR和ASR方法,CSC语料库可以生成带有视觉和语音拼写错误的标注文本。
在我们的实验中,定性分析表明,OCR或ASR工具包错误识别的中文字符对人类来说并不容易检测,而有趣的是,人们在日常写作中很容易犯这样的拼写错误。在定量比较中,我们将中文拼写检查视为序列标注问题,并实现了一个监督基准模型——双向LSTM(BiLSTM),以评估在三个标准测试数据集上CSC的性能。
实验结果显示,基于我们生成的语料库训练的BiLSTM模型比在标准测试数据集提供的训练数据集上训练的模型表现更好。为了进一步促进CSC任务的发展,我们通过收集每个字符的所有错误变体及其对应的正确参考构建了混淆集。
在错误纠正任务中,混淆集的有效性得到了验证,表明构建的混淆集在许多现有的中文拼写检查方案中具有重要作用(Chang,1995;Wu等,2010;Dong等,2016)。
- 图1

图1:通过基于OCR的方法生成V型错误的示例过程。在OCR检测结果中,除了赝 (yan4),其他三个字符即粟 (li4)、募 (mu4) 和 缉 (ji1),分别被错误识别为栗 (su4)、蓦 (mo4) 和 辑 (ji2)。这三个错误字符与其对应的正确字符在形状上非常相似。
2 自动数据生成
中文拼写错误主要由视觉或语音上相似的字符误用引起(Chang, 1995; Liu et al., 2011; Yu and Li, 2014)。视觉相似字符的错误(以下简称为V型错误)是由于一些视觉上相似的字符对具有显著性。原因在于,中文作为象形文字,包含超过六万多个字符。它们是由有限的部首和组件构成的。至于由语音相似字符误用引起的错误(以下简称为P型错误),我们注意到,汉字的发音通常由拼音定义,拼音由声母、韵母和声调组成(Yang et al., 2012)。在现代汉语中,只有398个音节可以对应成千上万的汉字。因此,很多汉字的发音相似,这进一步导致了P型错误的显著性。在本节的其余部分,我们分别描述如何在2.1和2.2节中生成这两种类型的错误。
2.1 基于OCR的生成方法
受到光学字符识别(OCR)工具容易误识别视觉相似字符的启发(Tong and Evans, 1996),我们故意模糊具有正确字符的图像,并使用OCR工具在其上进行处理,从而生成V型拼写错误。
具体来说,我们使用Google Tesseract(Smith, 2007)作为OCR工具包,生成过程如图1所示。
给定一个句子,首先,我们从中随机选择1至2个字符作为目标字符,进行Tesseract识别,记为Ctargets。
具体而言,除了汉字,其他字符如标点符号和外文字符会被排除,我们还会根据中文维基百科语料库的统计信息,过滤掉低频汉字。其次,我们将Ctargets从文本转化为100 × 100像素的图像,即每个生成的图像大小相同。
第三,我们随机对生成的图像区域进行高斯模糊(Bradski, 2000),目的是使OCR工具产生错误。
最后,我们使用Google Tesseract对模糊图像进行识别。如果识别结果与原字符不匹配,就会生成V型错误,并用此错误字符替换原字符,生成包含V型拼写错误的句子。通过上述步骤,我们为每个句子生成拼写错误及其正确参考。
用于OCR方法的原始文本主要来自人民日报等新闻网站的文章,这些文章经过严格的编辑过程,假设其内容是正确的。
我们通过句末标点符号(如句号“。”、问号“?”和感叹号“!”)对这些文本进行分句(Chang et al., 1993)。
最终,我们得到50,000个句子,每个句子包含8至85个字符,包括标点符号。
然后,我们使用OCR方法处理这些句子,生成一个标注语料库,其中包含约40,000个标注句子和56,857个拼写错误。值得注意的是,在我们的实验中,即使我们对图像进行部分模糊处理,OCR工具仍然能够正确检测图像中的字符,这也解释了为什么生成的标注句子的数量小于原始句子。我们将这个数据集称为D-ocr,并在表3的D-ocr列中展示其统计信息。
不良情况及解决方案
尽管基于OCR的方法运行顺利,但仍有一些值得进一步研究的情况。通过分析该方法生成的拼写错误,我们发现,在形状上,OCR工具有时会错误识别一些与正确字符相差甚远的字符。
例如,在包含字符领(ling3)的模糊图像中,Tesseract错误地识别为铈(shi4),这在形状上与领(ling3)完全不同。因此,这些情况应该被排除,因为人类不太可能犯这样的错误。
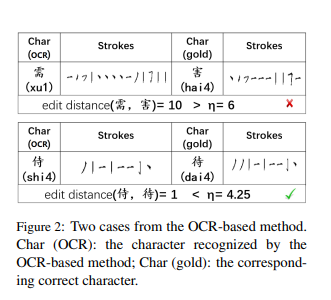
为了解决这个问题,我们提出了一种新方法,通过计算汉字笔画的编辑距离来判断两个字符是否在形状上相似。与由字母构成的英语单词类似,汉字可以分解为不同的笔画。为此,我们从在线字典获取汉字的笔画信息。
根据经验,给定两个汉字c1和c2,我们设定0.25 × (len(c1) + len(c2))为阈值η,其中len(c)表示汉字c的笔画数。如果两个字符的编辑距离超过阈值η,我们认为它们在形状上不相似。为了更清楚地说明这一点,图2展示了一个不良案例和一个良好案例。
- F2
- F3

2.2 基于ASR的生成方法
与OCR工具类似,自动语音识别(ASR)工具也可能将一些字符误识别为发音相似的其他字符(Hartley and Reich, 2005)。
为了构建包含P型错误的标注语料库,我们采用与V型错误和OCR工具类似的思路,采用了图3所示的流程。然而,鉴于现有各种语音识别数据集的可用性,我们采用了一种更简化的方法。我们利用一个公开的普通话语音语料库AIShell(Bu et al., 2017),该语料库包含约14万个句子和对应的语音数据。
我们使用Kaldi(Povey et al., 2011)语音识别工具包将这些语音转录为识别后的句子。
最后,通过将识别后的句子与原句进行对比,我们可以识别识别结果是否正确。如果不正确,这些结果将作为识别错误的结果,并用于构建包含P型拼写错误的语料库。
不良情况及解决方案
对于生成的P型错误,我们同样识别出一些可能引入大量噪声的不良情况。为提高生成语料库的质量,因此需要采取解决方案来删除这些不良情况。表2给出了三种不良情况和一种良好情况。我们将逐一描述解决这些问题的方法。
-
情况1:长度不同的错误识别结果
首先,我们丢弃所有识别结果与对应的参考句子长度不匹配的错误结果。这些错误结果与目标句子的长度明显不同,因此它们不符合我们的预期。 -
情况2:发音完全不同的错误识别字符
第二类错误是识别出的字符与参考句中的字符在发音上完全不同。这些错误不符合我们生成P型错误的需求。为了处理这种情况,我们通过拼音获取汉字的发音,拼音信息来自在线中文词典。然后,我们可以很容易地识别识别错误的字符是否与原句中的字符具有相似或相同的发音。具体而言,按照拼音规则,如果两个字符具有相同的声母和韵母,但声调不同(如:da2 和 da1),则认为它们具有相似发音。 -
情况3:错误字符超过两个
根据Chen et al.(2011)的研究,每个学生的文章平均存在两个错误,这反映了每个句子中平均不会包含超过两个拼写错误。因此,我们移除那些识别错误字符数量超过两个的识别结果,如表2中情况3所示。
通过以上步骤,我们生成了一个包含超过7千个P型拼写错误的语料库。
我们将其称为D-asr,并在表3的D-asr列中展示了其统计信息。
- T3+T4+T5
3 评估
3.1 基准数据
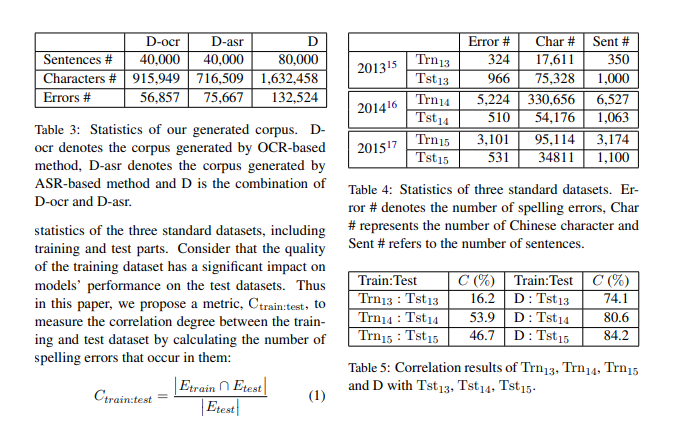
为了评估生成语料库的质量,我们采用了2013至2015年共享任务中的三个基准数据集(Wu et al., 2013;Yu et al., 2014;Tseng et al., 2015)来进行中文拼写检查(CSC)的评估。表4展示了这三个标准数据集的统计信息,包括训练集和测试集部分。
考虑到训练数据集的质量对模型在测试数据集上的表现具有显著影响,因此本文提出了一个度量指标,Ctrain:test,用于衡量训练集和测试集之间的相关度。该指标通过计算训练集和测试集中的拼写错误出现的交集来度量二者的相似度,具体公式如下:
[ C_{train:test} = \frac{|E_{train} \cap E_{test}|}{|E_{test}|} ]
其中,(E_{train}) 和 (E_{test}) 分别表示训练集和测试集中的拼写错误集合。集合中的每个元素是一个包含正确字符和拼写错误字符的对,例如(撼 (han4), 憾 (han4))。
表5展示了在三个不同的测试数据集上,整个生成语料库D的Ctrain:test分别为74.1%、80.6%和84.2%,这些值远高于Trn13、Trn14和Trn15的结果。这一差异可能表明生成的语料库有效,且包含了充足的拼写错误,从而支持了我们生成方法的有效性。
3.2 定性分析
设置
为了评估生成的语料库中是否包含容易由人类犯的错误,我们从中随机选择了300个句子进行人工评估,其中150个来自D-ocr,150个来自D-asr。我们邀请了三名中文母语的大学生阅读并标注这些句子中的错误。然后,我们从句子级别和错误级别两个层次分析这些学生的标注结果。
- 句子级别:只有在句子中的所有错误都被识别时,才认为该句子被正确标注。
- 错误级别:我们计算正确标注的错误数占总错误数的百分比。
结果
表6展示了300个句子及其标注结果。表中的平均召回率表明,三名学生对来自D-asr的错误的识别率高于D-ocr的错误识别率,这在某种程度上表明P-style错误比V-style错误更容易被检测到。此外,我们还观察到,三名志愿者平均未能识别约36.9%的错误,这可能表明我们的生成句子中包含一些挑战性的错误,这些错误很可能在人类写作或输入时发生。这些错误对CSC任务来说具有价值,因为它们可能出现在人们的实际写作或打字中。
案例研究
为了定性分析为何一些拼写错误未被人类检测到,我们对一个包含未被三名学生发现的拼写错误的句子进行了案例研究。该句子是:“政企部分是一种痼疾”(翻译:政治和产业部分是一种慢性病),其中第三个字符“部分”(bu4)是拼写错误,应纠正为“不分”(bu4)。在这个例子中,“部分”和“不分”是两个非常常见的中文词组,容易被认为是正确的。然而,考虑到前面的“政企”(政治和产业)和后面的“是一种痼疾”(是一种慢性病),我们可以看到“部分”不适合当前的上下文,应该纠正为“不分”。
这个案例研究证实了我们的生成语料库中包含一些像人类写作或输入中可能出现的拼写错误,这进一步证明了语料库的质量和我们方法的有效性。
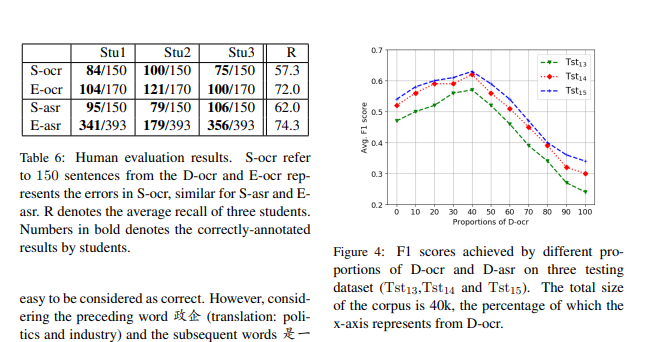
表6:人工评估结果
| Stu1 | Stu2 | Stu3 | R | |
|---|---|---|---|---|
| S-ocr | 84/150 | 100/150 | 75/150 | 57.3 |
| E-ocr | 104/170 | 121/170 | 100/170 | 72.0 |
| S-asr | 95/150 | 79/150 | 106/150 | 62.0 |
| E-asr | 341/393 | 179/393 | 356/393 | 74.3 |
说明:
- S-ocr:表示来自D-ocr的150个句子。
- E-ocr:表示在S-ocr中标注的错误。
- S-asr:表示来自D-asr的150个句子。
- E-asr:表示在S-asr中标注的错误。
- R:表示三名学生的平均召回率。
加粗的数字表示学生标注正确的结果。
- T6-F4
3.3 定量比较
3.3.1 汉语拼写错误检测
在本节中,我们通过汉语拼写错误检测来评估我们生成语料库的质量。我们首先探索不同的P风格和V风格错误比例如何影响语料库的质量。然后,我们将生成的语料库与三个共享任务中提供的训练数据集的检测性能进行比较。
设置
我们将汉语拼写错误检测转化为一个字符序列标注问题,其中正确字符标注为1,错误字符标注为0。然后,我们实现了一个监督学习的序列标注模型,即双向LSTM(BiLSTM)作为我们的基线模型,用于评估不同语料库的质量。BiLSTM的隐藏层大小设置为150,其他超参数在一个包含10%随机选取句子的开发集上进行调优。我们使用RMSprop作为优化器,最小化类别交叉熵损失。
结果
BiLSTM模型在不同D-ocr和D-asr比例下的训练,旨在探索P风格和V风格拼写错误分布如何影响生成语料库的质量。图4显示,当训练数据集大小固定(=40k)时,不同的P风格和V风格错误比例会获得不同的F1分数,这表明拼写错误的比例会影响生成语料库的质量。具体来说,观察到在D-ocr和D-asr的4:6比例下,生成的语料库在三个测试数据集上表现最好。
此外,对于两个特殊比例(0%和100%),我们发现,在相同大小的语料库下,BiLSTM模型在D-asr上的表现优于D-ocr,这表明P风格拼写错误对语料库质量的贡献更大。这一实验结果符合之前的结论(Liu等,2009, 2011),即大多数拼写错误与发音相关。
为了更好地展示生成语料库的质量,我们将其与一些手动标注的训练数据集进行比较(Wu等,2013;Yu等,2014;Tseng等,2015)。根据图4中实验结果的先前分析,我们选择了P风格和V风格拼写错误的4:6比例来构建接下来的训练数据。具体来说,我们构建了五个不同大小的数据集:D-10k、D-20k、D-30k、D-40k和D-50k,这些数据集是从D-ocr和D-asr中按4:6的比例提取的。
接着,我们在这些训练数据集上训练BiLSTM模型,并在Tst13、Tst14和Tst15上评估错误检测性能。表7展示了在三个不同测试数据集上的检测性能。我们得出以下观察结果:
-
训练数据集的大小对模型训练非常重要。对于Tst13,D-10k的F1得分比Trn13更高。一个主要原因可能是Trn13的数据集大小较小(见表3,Trn13大小为350),而测试数据集则远大于此。在这种情况下,模型无法学习到足够的信息,导致无法检测到未见过的拼写错误。此外,我们还可以看到,随着生成语料库大小的持续增大,检测性能稳定提高。因此,对于数据驱动的方法,训练模型时必须使用足够多、包含不同拼写错误的实例。
-
如果训练数据集包含过多“噪音”拼写错误,精度可能会受到影响。从表7可以看出,尽管随着生成语料库的增大,整体性能(F1得分)持续提高,但精度和召回率的变化趋势并不相同。观察到随着训练数据集大小的增加,模型在召回率方面表现得更好。一个可能的原因是,训练数据集中包含更多不同拼写错误的实例,从而减少了测试数据集中未见过的拼写错误数量,帮助模型检测更多拼写错误。然而,精度的提高并不像召回率那样明显。具体来说,在Tst14和Tst15中,D-50k的精度并未超过D-40k。一个可能的解释是,随着训练数据集规模的增大,包含更多拼写错误实例的训练集可能会导致模型误判一些正确字符,从而导致精度下降。
-
与人工标注的有限训练数据集相比,我们生成的大规模语料库可以取得更好的性能。从表7可以看到,使用一定大小的生成语料库训练的模型,其检测性能优于使用手动标注数据集训练的模型。某种程度上,这证明了我们生成语料库的有效性,从而验证了我们方法的有效性。
表7:BiLSTM在Tst13、Tst14、Tst15上的汉语拼写错误检测性能(%)
| 数据集 | P | R | F1 | P | R | F1 | P | R | F1 |
|---|---|---|---|---|---|---|---|---|---|
| Tst13 | Tst13 | Tst13 | Tst14 | Tst14 | Tst14 | Tst15 | Tst15 | Tst15 | |
| Trn | 24.4 | 27.3 | 25.8 | 49.8 | 51.5 | 50.6 | 40.1 | 43.2 | 41.6 |
| D-10k | 33.3 | 39.6 | 36.1 | 31.1 | 35.1 | 32.9 | 31.0 | 37.0 | 33.7 |
| D-20k | 41.1 | 50.2 | 45.2 | 41.1 | 50.2 | 45.2 | 43.0 | 54.9 | 48.2 |
| D-30k | 47.2 | 59.1 | 52.5 | 40.9 | 48.0 | 44.2 | 50.3 | 62.3 | 55.7 |
| D-40k | 53.4 | 65.0 | 58.6 | 52.3 | 64.3 | 57.7 | 56.6 | 66.5 | 61.2 |
| D-50k | 54.0 | 69.3 | 60.7 | 51.9 | 66.2 | 58.2 | 56.6 | 69.4 | 62.3 |
备注: 最佳结果以粗体显示。Trn表示在相应共享任务中提供的训练数据集。例如,Trn表示Tst13中的Trn13。
3.3.2 汉语拼写错误纠正
在检测到汉语拼写错误之后,我们进一步进行拼写错误的纠正,如第3.3.1节所述。我们参考了之前的研究(Chang, 1995; Huang et al., 2007; Wu et al., 2010; Chen et al., 2013; Dong et al., 2016),采用了混淆集和语言模型来处理汉语拼写错误的纠正任务。具体来说,通过收集每个正确字符的所有错误变体,我们为所有涉及的正确字符构建一个混淆集,记作“我们的混淆集”。为了验证其有效性,我们将其与两个公开可用的混淆集(Liu et al., 2009)进行比较,分别是Con1和Con2。具体来说,Con1包含了SC(类似仓颉)、SSST(同音同调)和SSDT(同音不同调),而Con2包含了所有的集合,包括SC、SSST、SSDT、MSST(类似音同调)和MSDT(类似音不同调)。表9展示了这三个混淆集的统计信息。
设置
与Dong等人(2016)相似,我们采用了三元组语言模型来计算给定句子的概率。基于序列标注模型的检测结果,我们选择来自相应混淆集的字符,并且该字符具有最高的概率,作为拼写错误的纠正。对于一个包含n个词的给定句子W = w₁, w₂, …, wₙ,其中wi表示句子中的第i个字符,E是一个包含检测到的错误字符索引的集合,W(wᵢ, c)表示将第i个字符替换为c后生成的新句子。拼写错误纠正过程可以表述为:
∀i ∈ E : arg max c∈C(wᵢ) P(W(wᵢ, c))
其中,P(W)是通过一系列条件概率的乘积近似得到的句子W的概率(Jelinek, 1997),C(wᵢ)指的是wi的混淆集,从中选择具有最大条件概率的字符作为纠正字符。
结果
表9显示了基于三元组语言模型的不同混淆集的运行时间和F1得分。我们可以观察到,构建的混淆集在拼写错误纠正的性能上优于Con1,但略低于Con2。然而,从表9中可以看到,Con2的混淆字符数量远大于我们的混淆集;对于相同的测试,Con2需要更长的时间来完成任务,而我们的混淆集则总是使用最少的时间。这些观察表明,我们构建的混淆集更高效,因为它包含的冗余错误字符较少,这些字符很少作为纠正字符。
错误分析
我们对两种错误情况进行了分析,即假阳性(false positive)和假阴性(false negative),它们分别影响CSC(拼写错误纠正)的精度和召回率。
假阳性(False Positive)
我们发现一个常见问题是,对于一些固定用法,例如成语、短语和诗句,我们的模型经常给出错误的结果。例如,在“风雨送春归”(一首中国诗句,意思是“风雨送别春天”)中,字符“送”被错误地识别为一个无关字符。通过检查我们提出方法生成的注释语料库,我们观察到在大多数情况下,“迎春”是一个更常见的匹配,而“送”在与“春”共同出现时被标注为拼写错误。为提高精度,处理此类情况的一种可能方法是利用一些外部知识,例如构建特殊的汉语用法集。
假阴性(False Negative)
以“想想健康,你就会知道应该要禁烟了”(意思是“当你考虑健康时,你会意识到应该戒烟”)为例,其中“禁”应被纠正为“戒”。然而,由于“戒”和“禁”在视觉上或语音上并不相似,因此我们提出的语料生成方法无法构建这种拼写错误,所以训练的模型无法检测出这种拼写错误。此外,在词汇层面,“禁烟”和“戒烟”是两个相关的常见汉语词组;为了提高召回率,需要更多的上下文信息。
与我们在字符级语料生成上的研究类似,一种潜在的解决方案是构建一个词汇级的注释语料库,以便更好地检测这类拼写错误。
表 8:在Tst13、Tst14、Tst15上的错误纠正结果,分别使用Con1、Con2和我们的混淆集(Ours)
| 指标 | Tst13 | Tst14 | Tst15 |
|---|---|---|---|
| F1 (%) | |||
| Con1 | 47.6 | 52.6 | 55.6 |
| Con2 | 52.1 | 56.1 | 57.1 |
| Ours | 50.3 | 53.0 | 56.3 |
| 时间(秒) | |||
| Con1 | 290.3 | 310.2 | 267.6 |
| Con2 | 679.9 | 792.1 | 622.5 |
| Ours | 101.2 | 132.4 | 119.2 |
表格显示了使用Con1、Con2和我们的混淆集(Ours)进行错误纠正的结果。
F1得分和运行时间均有展示,表明我们的混淆集在效率和性能之间达到了较好的平衡。
表 9:不同混淆集的统计信息
| 名称 | 字符数 | 最小字符数 | 最大字符数 | 平均字符数 |
|---|---|---|---|---|
| Ours | 4,676 | 1 | 53 | 5.6 |
| Con1 | 5,207 | 8 | 196 | 50.6 |
| Con2 | 5,207 | 21 | 323 | 86.0 |
表格显示了不同混淆集的统计信息。
可以看出,Ours的字符数较少,并且每个混淆项的字符数也较小,平均字符数为5.6。
而Con1和Con2的字符数和混淆项的规模相对较大,且包含了更多的字符。
4 相关工作
在拼写错误检测与纠正的研究领域,大多数之前的研究主要集中在设计不同的模型以提高中文拼写检查(CSC)的性能(Chang,1995;Huang等,2007,2008;Chang等,2013)。
与这些研究不同,本工作贡献于训练数据集的生成,这是一个重要的资源,可以用来改善许多现有的CSC模型。
目前,有限的训练数据集为许多数据驱动方法设置了很高的门槛(Wang等,2013;Wang和Liao,2015;Zheng等,2016)。
根据我们的了解,至今为止,尚未有大量的常用标注数据集可供CSC使用。
一些先前的研究(Liu等,2009;Chang等,2013)指出,视觉上和语音上相似的字符是中文文本中拼写错误的主要原因,其中语音相似的拼写错误数量约是视觉相似错误的两倍。因此,我们的研究方法采用了视觉和语音相关技术。
作为从图像中提取文本信息的技术,光学字符识别(OCR)通过识别形状并分配字符来处理图像中的文本。根据Nagy(1988);McBride-Chang等(2003)的研究,识别错误的结果主要是由于某些不同中文字符的视觉相似性。
另一方面,自动语音识别(ASR)是一种基于声学的识别过程,用于处理音频流,在这个过程中,语音相似的字符通常会混淆(Kaki等,1998;Voll等,2008;Braho等,2014)。
5 结论与未来工作
本文提出了一种混合方法,用于自动生成带有标注拼写错误的中文语料库以供拼写检查使用。
具体来说,我们采用了基于OCR和ASR的方法,通过替换视觉上和语音上相似的字符来生成标注的拼写错误。
人类评估确认了我们提出的方法能够生成常见的错误,这些错误通常是人类会犯的,并且这些错误可以作为有效的标注拼写错误用于CSC。
在实验中,我们在生成的语料库上训练了一个神经标注模型,并在基准数据集上测试了结果,确认了语料库的质量,进一步证明了我们提出的语料库生成方法对于CSC的有效性。
通过我们提出的方法生成的大规模标注数据集,能够为改进数据驱动模型的性能提供有用的资源,因为大规模标注数据的可用性是应用任何算法或模型之前的首要步骤。在
本文中,我们没有在CSC模型设计方面投入过多的精力,这将作为未来的潜在工作。
为了促进相关研究并为其他研究者提供帮助,我们将本文的代码和数据公开,地址为:https://github.com/wdimmy/Automatic-Corpus-Generation。
致谢
作者特别感谢Xixin Wu在ASR实验中的建议和帮助。
此外,作者还感谢Li Zhong、Shuming Shi、Garbriel Fung、Kam-Fai Wong以及三位匿名审稿人对本研究的各个方面所提供的帮助和宝贵意见。
参考资料
https://github.com/wdimmy/Automatic-Corpus-Generation/blob/master/README.md
