拼写纠正系列
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计、论文和开源实现。
摘要
本文介绍了我们在NLPTEA2020任务——中文语法错误诊断(CGED)中的系统。CGED旨在诊断四种类型的语法错误:缺失词(M)、冗余词(R)、错误选词(S)和词序错乱(W)。
自动化的CGED系统包含两个部分:错误检测和错误修正。
对于错误检测,我们的系统基于多层双向Transformer编码器模型,并将ResNet集成到编码器中以提高性能。我们还探索了从模型库中逐步集成选择,以提高单一模型的表现。
对于错误修正,我们设计了两个模型,分别推荐S类型和M类型错误的修正。在官方评估中,我们的系统在错误检测的识别级别和位置级别获得了最高的F1分数,在修正级别获得了第二高的F1分数。
1 引言
中文通常被认为是最复杂的语言之一。与英语相比,中文没有单复数变化,也没有动词时态变化。此外,由于中文没有明确的词边界,通常需要在深入分析之前进行分词处理。这些问题使得中文学习对新学习者来说具有很大的挑战性。近年来,越来越多来自不同语言和知识背景的人开始对学习中文作为第二语言产生兴趣。为了帮助这些人识别和纠正中文写作中的语法错误,开发一个自动化的中文语法错误诊断(CGED)工具变得非常必要。
为了促进中文学习中自动语法错误诊断技术的发展,2014年起,自然语言处理教育应用技术(NLP-TEA)将CGED作为共享任务之一,提出了多种方法来解决CGED任务。
在这项工作中,我们介绍了我们在NLPTEA-2020 CGED任务中的系统。
在错误检测方面,我们的系统基于多层双向Transformer编码器模型,并将ResNet集成到编码器中以提升性能。
我们还探索了从模型库中逐步集成选择,以提高单一模型的表现。
在错误修正方面,我们设计了两个模型,分别针对S类型和M类型错误推荐修正。
更具体地,我们使用RoBERTa(Liu et al., 2019)和n-gram语言模型来修正S类型错误,结合预训练的掩码语言模型和统计语言模型生成M类型错误的可能修正结果。
在官方评估中,我们的系统在错误检测的识别级别和位置级别获得了最高的F1分数,在修正级别获得了第二高的F1分数。
本文组织结构如下:第2节简要介绍CGED共享任务,第3节介绍我们的研究方法,第4节展示实验结果,第5节介绍相关工作,最后第6节总结了结论并展望未来工作。
2 中文语法错误诊断
NLPTEA CGED任务的目标是指出中文作为外语学习者写作中的语法错误。
句子中可能包含四种类型的语法错误,包括缺失词(M)、冗余词(R)、选词错误(S)和词序错误(W)。
输入的句子可能包含一种或多种错误。
给定一个句子,系统需要完成以下任务:
(1)判断句子是否正确;
(2)指出句子包含的错误类型;
(3)标明错误的具体位置;
(4)对S类型和M类型错误提供可能的修正。
表1展示了一些典型示例。
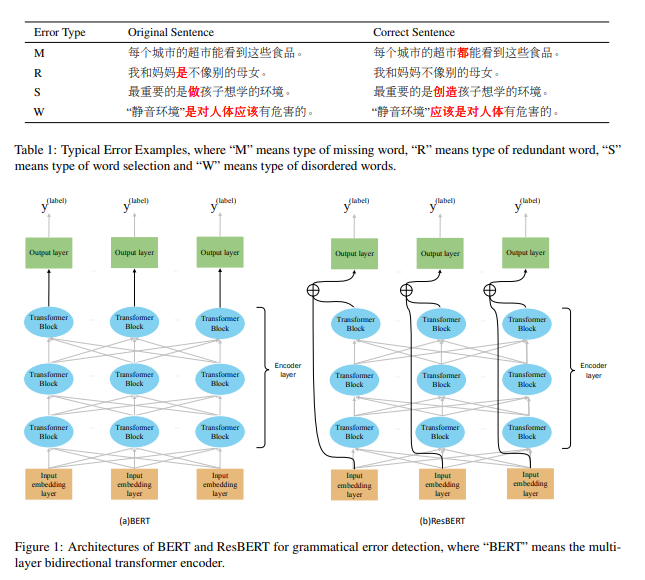
3 方法论
3.1 错误检测
我们将错误检测问题视为序列标注问题。具体而言,给定一个句子 ( x ),我们使用BIO编码(Kim 等,2004)生成相应的标签序列 ( y )。然后,我们结合ResNet和Transformer编码器来解决标注问题。
Transformer编码器
我们使用Vaswani 等(2017)描述的多层双向Transformer编码器(BERT)来编码输入句子。如图1(a)所示,该模型由三部分组成:输入嵌入层 ( I )、编码器层 ( E ) 和输出层 ( O )。给定一个序列 ( S = w_0, …, w_N ) 作为输入,编码器的公式如下:
[ h_0^i = W_e w_i + W_p \tag{1} ] [ h_l^i = \text{transformer block}(h_{l-1}^i) \tag{2} ] [ y_{\text{BERT}}^i = \text{softmax}(W_o h_L^i + b_o) \tag{3} ]
其中,( w_i ) 是当前的标记,( N ) 表示序列的长度。公式(1)用于生成输入嵌入。这里,transformer block 包括自注意力和全连接层,输出 ( h_l^i )。( l ) 表示当前层的层数,( l \geq 1 ),( L ) 是BERT的总层数。公式(3)表示输出层,( W_o ) 是输出权重矩阵,( b_o ) 是输出层的偏置项,( y_{\text{BERT}}^i ) 是语法错误检测的预测结果。
集成ResNet
深度神经网络在每一层学习不同的表示。
例如,Belinkov 等(2017)表明,在机器翻译任务中,网络的低层学习表示单词结构,而高层则更关注单词的意义。
对于强调语法特征的任务(如中文语法错误检测),低层的网络信息被认为非常重要。
在本工作中,我们使用残差学习框架(He 等,2016)将单词嵌入信息与深层信息结合起来。给定序列 ( S = w_0, …, w_N ) 作为输入,ResBERT的公式如下:
[ h_0^i = W_e w_i + W_p \tag{4} ] [ h_l^i = \text{transformer block}(h_{l-1}^i) \tag{5} ] [ R_i = h_L^i - w_i \tag{6} ] [ H_L^i = \text{concat}(h_L^i, R_i) \tag{7} ] [ y_{\text{ResBERT}}^n = \text{softmax}(W_o H_L^i + b_o) \tag{8} ]
公式(6)表示残差学习框架,其中 ( h_L^i ) 的隐藏输出与输入嵌入一起用于逼近残差函数。然后,我们将 ( h_L^i ) 和 ( R_i ) 的连接结果传递给输出层。
逐步集成选择(Stepwise Ensemble Selection)
我们发现,不同的随机种子和dropout值可能导致每次训练结束时不同的性能。
为了提高性能,我们合并不同模型的结果。我们并不是通过加权平均来合并所有单一模型,而是使用来自模型库的逐步集成选择(Caruana 等,2004)来找到一个子集的模型,该子集在加权平均时能获得最优性能。模型库是通过使用不同的随机种子和dropout值生成的。
基本的集成选择过程如下:
- 从空集开始。
- 向集成中添加模型库中最大化集成性能的模型,以提高中文语法错误检测指标在验证集上的表现。
- 重复步骤2,直到达到固定的迭代次数或所有模型都已使用完。
- 返回在验证集上具有最大性能的嵌套集成结果。
在每一步选择最佳模型时,使用的是跨跨度(span-level)的投票机制,具体如下:
- 每个单一模型标注的错误文本跨度都会为该跨度投一票(例如,如果某个位置的词“是”被某个模型标记为R类型,那么它就获得一票)。需要注意的是,只有在某个单一模型标记为错误类型的文本跨度才被认为是候选的错误文本。
- 如果某个候选错误文本跨度收集到的投票数达到最小阈值(例如30% * 模型子集数量),则该文本被标记为真实错误。
所呈现的简单的前向模型选择过程是有效的,但有时会导致过拟合验证集,从而降低集成在测试集上的表现。为了减少过拟合,我们对选择过程做了三项改进,如Caruana 等(2004)所述:
-
有替换的选择:如果没有替换地进行模型选择,性能会随着最佳模型的加入而提高,直到达到峰值,然后迅速下降。通过有替换的选择可以大大减少这个问题。有替换的选择允许同一个模型多次加入集成,这样可以通过加权模型来微调集成:被多次加入集成的模型会获得更大的权重。
-
排序集成初始化:简单的前向模型选择过程从空集开始。前向选择在集成较小的时候容易过拟合。为防止过拟合,我们根据模型的表现对模型库中的模型进行排序,并将最好的 ( N ) 个模型放入集成中。我们设置 ( N = 5 )。
-
袋装集成选择:随着模型库中模型数量的增加,找到会导致过拟合验证集的模型组合的可能性也增加。袋装方法可以最小化这个问题。我们通过从模型库中随机抽样一部分模型来减少模型的数量,并从该样本中选择模型。如果某个特定组合的 ( M ) 个模型发生过拟合,那么它们出现在随机袋中的概率会小于 ( (1 - p)^M ),其中 ( p ) 是袋中模型的比例。我们使用 ( p = 0.5 ),并进行20次袋装集成选择,以确保最好的模型有多次被选中的机会。最终的集成结果是这20个集成的平均值。
3.2 错误修正
该系统还需要为S型和M型错误推荐修正。
在本工作中,我们设计了两个不同的模型,分别为S型和M型错误推荐修正。下面分别描述这两个模型。
S型修正
对于S型错误的修正,我们主要使用RoBERTa(Liu 等,2019)和n-gram语言模型。
首先,我们对语言模型进行领域适配。我们使用之前比赛的CGED训练集对RoBERTa-wwm进行微调,并将CGED数据与新闻语料结合,训练一个5-gram语言模型。
S型修正包括单字符修正和多字符修正。
对于单字符修正,我们考虑RoBERTa生成的前20个候选结果和L2学习者语料库中最常见的3500个字符作为候选项。
我们根据RoBERTa的预测概率、n-gram语言模型的预测概率、视觉相似性和语音相似性(Hong 等,2019)对候选项进行打分。随后,选择得分最高的字符作为修正结果。
对于多字符修正,我们同样选取RoBERTa在每个位置生成的前20个字符。然后,我们将这些字符组合成词,并保留词汇表中出现的词作为候选项。除了单字符修正时使用的四种特征外,我们还考虑了错误词和候选词之间的Levenshtein距离。
数据统计
| 错误类型 | R | M | S | W | |
|---|---|---|---|---|---|
| 训练集 | 52,312 | 11,548 | 13,931 | 23,014 | 3,769 |
| 验证集 | 4,871 | 1,060 | 1,269 | 2,156 | 386 |
M型修正
特别地,我们将M型错误的修正视为完形填空任务,并利用预训练的掩码语言模型和统计语言模型的组合来生成可能的修正结果。
给定怀疑为缺失的位置,我们将M型错误的修正过程分为两个步骤:首先提供可能的修正,然后评估并选择最合理的修正。
使用预训练的掩码语言模型时,我们首先通过基于BERT的序列标注模型预测疑似M型错误位置的缺失字符数。
然后,我们在该位置前插入与预测缺失字符数相同数量的[MASK]符号。接着,使用BERT预测每个[MASK]符号最可能的字符,将其作为修正候选项。
使用统计语言模型时,我们准备了一个L2学习者的中文高频词汇表,并将所有可能的中文词汇从该词汇表补充到疑似M型错误位置,生成一系列修正候选项。
为了评估每个候选项的概率,我们使用这些候选项构造修改后的句子,并计算原句和所有修改句子的困惑度(perplexity),困惑度由在L2学习者语料库上预训练的统计语言模型计算。
如果修改句子的困惑度显著低于原句的困惑度(这个阈值由人工设置),我们就将该候选项视为预测的修正结果。
4 实验
4.1 数据集
根据Fu等(2018)的工作,我们使用包含错误句子和修正句子的训练单元进行单模型训练,数据来源包括2016年(HSK Track)、2017年和2018年的训练数据集。
- CGED 2016 HSK Track训练集包含10,071个训练单元,总共有24,797个语法错误,分为冗余错误(5,538个实例)、缺失错误(6,623个)、词汇选择错误(10,949个)和词序错误(1,687个)。
- CGED 2017训练集包含10,449个训练单元,总共有26,448个语法错误,分为冗余错误(5,852个实例)、缺失错误(7,010个)、词汇选择错误(11,591个)和词序错误(1,995个)。
- CGED 2018训练集包含1,067个语法错误,分为冗余错误(208个实例)、缺失错误(298个)、词汇选择错误(87个)和词序错误(474个)。
训练数据的总体分布如表2所示。
2017年的测试数据集用于验证。该数据集包含4,871个语法错误,分为冗余错误(1,060个实例)、缺失错误(1,269个)、词汇选择错误(2,156个)和词序错误(386个)。
4.2 评价标准
评估方法包括四个层次:
- 检测层次:判断句子是否正确。如果存在错误,则该句子被视为错误,所有类型的错误都视为错误。
- 识别层次:此层次可以视为一个多类别分类问题。修正结果应与金标准的错误类型完全一致。
- 位置层次:系统的输出结果应与金标准的四元组完全一致。
- 修正层次:对于S型和M型错误,需要给出正确的候选修正。每个错误最多推荐3个修正。
在检测、识别和位置层次,我们使用以下指标进行衡量:
- 假阳性率 (False Positive Rate, FPR): [ FPR = \frac{FP}{FP + TN} ]
- 准确率 (Accuracy): [ Accuracy = \frac{TP + TN}{TP + FP + TN + FN} ]
- 精确度 (Precision): [ Precision = \frac{TP}{TP + FP} ]
- 召回率 (Recall): [ Recall = \frac{TP}{TP + FN} ]
- F1值 (F1 Score): [ F1 = \frac{2 \times Precision \times Recall}{Precision + Recall} ]
由于每个团队可以提交三种结果,我们分别在检测层次、识别层次和位置层次上进行三次逐步集成选择,以根据不同层次的表现进行模型选择。
4.3 训练细节
我们尝试了不同的预训练模型参数作为transformer的初始化,例如BERT(Devlin 等,2018)、ELECTRA鉴别器(Clark 等,2020)和BERT-WWM(Cui 等,2019)。我们发现,初始化为ELECTRA鉴别器的模型始终表现得更好。因此,我们选择ELECTRA鉴别器作为transformer的初始化模型。具体而言,我们使用了中文的ELECTRA-Large鉴别器模型,包含1024个隐藏单元,16个头,24层隐藏层,总参数量为324M。
其他训练参数包括:使用128个token的流、每个mini-batch大小为64,学习率为2e-5,训练周期为120。我们使用16个不同的随机种子和5个不同的dropout值,为每个随机种子训练80个单一模型,以进行逐步集成选择。
表 3:使用单一模型和集成方法的验证结果
| 模型 | FPR | 检测层次 Precision | 检测层次 Recall | 检测层次 F1 | 识别层次 Precision | 识别层次 Recall | 识别层次 F1 | 位置层次 Precision | 位置层次 Recall | 位置层次 F1 |
|---|---|---|---|---|---|---|---|---|---|---|
| BERT | 0.6333 | 0.6974 | 0.8626 | 0.7713 | 0.5406 | 0.5721 | 0.5559 | 0.3362 | 0.3178 | 0.3267 |
| BERT-WWM | 0.6966 | 0.6826 | 0.8854 | 0.7709 | 0.5306 | 0.5894 | 0.5585 | 0.3324 | 0.3302 | 0.3313 |
| ELECTRA | 0.8530 | 0.6519 | 0.9439 | 0.7712 | 0.5185 | 0.6489 | 0.5764 | 0.3288 | 0.3720 | 0.3491 |
| ResELECTRA | 0.7709 | 0.6680 | 0.9167 | 0.7728 | 0.5304 | 0.6520 | 0.5849 | 0.3503 | 0.3960 | 0.3722 |
| WA Ensemble | 0.5675 | 0.7216 | 0.8962 | 0.7885 | 0.6175 | 0.5799 | 0.5981 | 0.4871 | 0.3841 | 0.4295 |
| S Ensemble | 0.4333 | 0.7719 | 0.8667 | 0.8166 | 0.6411 | 0.6562 | 0.6486 | 0.4805 | 0.4693 | 0.4748 |
注解:
- S Ensemble 表示逐步集成模型。
- FPR (False Positive Rate) 是假阳性率,表示错误预测为正类的比例。
- Precision (精确度) 是指正确预测为正类的比例。
- Recall (召回率) 是指正确预测为正类的实例占所有正类实例的比例。
- F1 是精确度和召回率的调和平均值,常用于评价分类模型的性能。
从表中可以看出,集成方法(WA Ensemble 和 S Ensemble)在各个层次上相较于单一模型有一定的性能提升,特别是在检测层次和识别层次的精确度上表现突出。
4.4 验证结果
如表 3 所示,我们构建了五个基准系统,包括:
- BERT:表示使用 BERT(Devlin 等,2018)初始化的单一模型;
- BERT-WWM:表示使用 BERT-WWM(Cui 等,2019)初始化的单一模型;
- ELECTRA:表示使用 ELECTRA 判别器(Clark 等,2020)初始化的单一模型;
- ResELECTRA:表示在单一模型中添加了 ResNet 单元的模型;
- WA Ensemble:表示简单的加权平均集成模型。
表 3 显示了我们模型在 2017 测试数据上的整体性能。
ELECTRA 单一模型的表现明显优于 BERT 单一模型和 BERT-WWM 单一模型。我们推测,ELECTRA 判别器在训练时没有使用掩码标记,这使得它在 CGED 任务中表现更好,因为该任务对周围的词语更为敏感。
ResELECTRA 单一模型相较于基准的 ELECTRA 单一模型,在位置层次上提升了 2 分以上,证明了将 ResNet 单元集成的有效性。
逐步选择集成模型(S Ensemble)在位置层次上比最佳的 ResELECTRA 单一模型提升了近 10 分,甚至与 WA Ensemble 模型相比,逐步选择集成模型也提升了 4 分以上。
4.5 测试结果
表 4 显示了错误检测的性能。
我们的系统在识别层次和位置层次上均取得了最佳的 F1 分数。
尽管我们在位置层次上达到了 0.4041 的最高 F1 分数,但与其他团队相比,仍存在较大的差距,说明我们系统在解决中文语法错误诊断方面还有很大的提升空间。
表 5 显示了错误修正的性能。我们在修正的 top1 分数上取得了第二高的成绩。
由于我们只提供零个或一个候选词,因此我们的修正 top1 分数与修正 top3 分数是相同的。
表 4:错误检测的提交运行结果(官方评估测试数据集)
表 4 显示了三个提交的运行结果在错误检测方面的性能。每一列对应检测层次的不同指标,包括 FPR(假阳性率)、Precision(精确度)、Recall(召回率)和 F1 分数。
| 运行 | FPR | 检测层次(Detection level) | 识别层次(Identification level) | 位置层次(Position level) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | Precision | Recall | F1 | ||
| 1 | 0.1010 | 0.9649 | 0.7409 | 0.8382 | 0.7769 | 0.4738 | 0.5886 | 0.4970 | 0.2529 | 0.3352 |
| 2 | 0.2573 | 0.9273 | 0.6213 | 0.6736 | 0.7356 | 0.6213 | 0.6736 | 0.4320 | 0.3514 | 0.3876 |
| 3 | 0.3257 | 0.9101 | 0.8800 | 0.8948 | 0.7320 | 0.6011 | 0.6601 | 0.4715 | 0.3536 | 0.4041 |
| Best Team | 0.0163 | - | - | 0.9122 | - | - | 0.6736 | - | - | 0.4041 |
分析:
- 第一轮 的模型在检测层次上表现最佳,具有最高的 Recall 和 Precision,但是在位置层次和识别层次的表现较差。
- 第二轮 结果相较于第一轮略有下降,尤其是在位置层次和识别层次上的表现较低。
- 第三轮 的模型在位置层次上达到最高的 F1 分数 0.4041,但其 Precision 和 Recall 也有所下降。
最优团队:
- 最优团队的成绩在位置层次上达到了 0.4041,其检测、识别和位置层次的表现都明显优于前三轮的结果。
表 5:错误修正的提交运行结果(官方评估测试数据集)
表 5 显示了三个提交的运行结果在错误修正方面的性能。
每一列对应不同的修正指标,包括 Correction Top1 和 Correction Top3 的 Precision、Recall 和 F1 分数。
| 运行 | Correction Top1 | Correction Top3 | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | |
| 1 | 0.2460 | 0.1149 | 0.1567 | 0.2460 | 0.1149 | 0.1567 |
| 2 | 0.2105 | 0.1540 | 0.1779 | 0.2105 | 0.1540 | 0.1779 |
| 3 | 0.2290 | 0.1575 | 0.1867 | 0.2290 | 0.1575 | 0.1867 |
| Best Team | - | - | 0.1891 | - | - | 0.1885 |
分析:
- 第一轮 的模型在 Correction Top1 和 Correction Top3 的 Precision 和 Recall 上表现较差,F1 分数也相对较低。
- 第二轮 结果在 Recall 上有小幅提升,但 Precision 和 F1 分数依然没有显著提高。
- 第三轮 的模型在 F1 分数上取得了轻微的提升。
最优团队:
- 最优团队在 Correction Top1 和 Correction Top3 的 F1 分数分别达到了 0.1891 和 0.1885,显示出其在错误修正上的最佳表现。
总结:
-
在错误检测任务中,第三轮 提交在位置层次上表现最佳,尽管在其他层次的性能有所下降。
-
在错误修正任务中,第一轮 和 第二轮 的模型表现较为接近,且远低于最优团队的成绩。
5. 相关工作
研究人员使用了多种不同的方法来研究英语语法错误修正任务,并取得了良好的结果(Ng et al., 2014)。
与英语相比,中文语法错误诊断系统的研究起步较晚,数据集和有效方法较为匮乏。
早期工作:
- Chen 等人(2013)仍然使用 n-gram 作为主要方法,并通过加入 Web 资源来提高检测性能。
- Lin 和 Chu(2015)建立了一个基于 n-gram 的评分系统,从而获得了更好的修正选项。
近年来的进展:
- 随着 NLPTEA CGED 任务的引入,中文语法错误诊断逐渐成为共享任务,提出了许多方法来解决这一任务(Yu 等人,2014;Lee 等人,2015,2016)。
-
Zheng 等人(2016)提出了基于字符嵌入和 bigram 嵌入的 BiLSTM-CRF 模型。
-
Shiue 等人(2017)结合了机器学习和传统的 n-gram 方法,使用 Bi-LSTM 检测错误位置,并加入了额外的语言学信息,如 POS、n-gram。
-
Li 等人(2017)使用 Bi-LSTM 生成每个字符的概率,并使用两种策略来判断字符是否正确。
-
Liao 等人(2017)使用 LSTM-CRF 模型来检测输出之间的依赖关系,从而更好地检测错误信息。
-
Yang 等人(2017)在 LSTM-CRF 模型中加入了更多的语言学信息,如 POS、n-gram、PMI 分数和依赖特征。该系统在 CGED2017 任务中达到了最佳的 F1-scores,分别在识别层次和位置层次上表现优异。
- Fu 等人(2018)在 BiLSTM-CRF 模型中加入了更多特征,如 词汇分割、Gaussian ePMI、POS 和 PMI 的结合,并采用了概率集成方法来提高系统性能。该系统在 CGED2018 任务中取得了识别层次和位置层次的最佳 F1-score。
6. 结论与未来工作
本文描述了我们在 NLPTEA-2020 CGED 任务中的系统,该系统结合了 ResNet 和 BERT 用于中文语法错误诊断。
我们还设计了两种不同的集成策略,以最大化模型的能力。
性能亮点:
- 我们的系统在 识别层次 和 位置层次 上取得了最佳的 F1 分数。
- 我们还在 修正 top1 层次 上取得了第二高的 F1 分数,在 检测层次 上取得了第三高的 F1 分数。
未来工作:
- 我们计划通过使用更多的训练数据来构建一个更强大的语法错误诊断系统,并尝试通过使用不同的跨领域语料库来提高系统的能力。
致谢
我们感谢 CGED 2020 任务的组织者们为本任务做出的巨大贡献。
我们也感谢匿名评审员提供的有见地的评论和建议。
本工作得到了 中国国家重点研发计划(项目编号 2018YFB1005100)和 国家自然科学基金(项目编号 61976072, 61632011, 61772153)的资助。
参考资料
https://aclanthology.org/2020.nlptea-1.5.pdf
