拼写纠正系列
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计、论文和开源实现。
论文 & 源码
论文:https://aclanthology.org/2021.emnlp-main.287v2.pdf
源码:https://github.com/benbijituo/SpellBERT/
摘要
中文拼写检查(Chinese Spelling Check,CSC)是检测和修正中文拼写错误的任务。
许多模型利用预定义的混淆集学习正确字符与其视觉或语音相似的错误之间的映射,但这种映射可能存在域外问题。
为此,我们提出了SpellBERT,这是一种基于图的额外特征的预训练模型,且不依赖于混淆集。
为了显式地捕捉两种错误模式,我们采用图神经网络引入部首和拼音信息作为视觉和语音特征。
为了更好地融合这些特征与字符表示,我们设计了类似掩蔽语言模型的预训练任务。
通过这种特征丰富的预训练,SpellBERT的模型大小仅为BERT的一半,却能在OCR数据集上表现出具有竞争力的性能,并在大多数错误未被现有混淆集覆盖的情况下取得了最先进的结果。
1. 引言
拼写检查是检测和修正中文句子中的拼写错误。然而,由于中文作为表意文字的特性,中文拼写检查是一项非平凡的任务。中文有一个庞大的词汇量,包括至少3500个常用字符,这导致了巨大的搜索空间以及错误的分布不均。
尽管难以覆盖大多数错误,但这些错误的模式大致可以归纳为视觉或语音错误(Chang, 1995),如图1所示。
- F1
我喜欢吃蛋糕 高
我喜欢吃蛋挞 达
前者是形状相似的错误,通常由光学字符识别(OCR)或形态学输入法引起。后者是发音相似的错误,通常由自动语音识别(ASR)或语音输入法引起。
以前的工作(Hsieh et al., 2013; Yu and Li, 2014; Wang et al., 2019a; Cheng et al., 2020)倾向于使用预定义的混淆集来查找并过滤修正候选。混淆集通过错误统计(Liu et al., 2010)构建,其中包含视觉相似的字符对和语音相似的字符对,依据错误模式进行映射。然而,这些模型只学习了来自混淆集的浅层映射,并且它们的性能高度依赖于混淆集的质量。但很难找到一个更新且符合领域要求的混淆集。
本文提出了两种预训练任务,显式地建模上述两种错误模式。为了建模视觉错误,我们引入了部首特征。汉字可以被分解成各种组成部分,称为部首。对于语音错误,我们采用拼音作为特征,它们是发音的描述。我们通过关系图卷积网络(Schlichtkrull et al., 2018)将这些视觉和语音特征与字符表示融合。与BERT中的掩蔽语言模型(Devlin et al., 2019)类似,我们随机替换一些字符,然后用错误的输入预测原始的视觉和语音特征。我们的模型SpellBERT可以基于视觉或语音模式来内在地学习修正错误,而不是简单的映射。在OCR数据集上,SpellBERT能够在大多数错误未被混淆集覆盖的情况下取得最先进的结果,这表明SpellBERT可以很好地进行泛化,而不依赖于混淆集。
在资源受限的部署场景中,构建轻量级模型是必要的。SpellBERT的模型大小仅为BERT的一半,对于这些场景更加高效。
总结来说,SpellBERT在训练和推理阶段不依赖于混淆集,且模型仅为BERT的一半大小,但能够展示出具有竞争力的性能,并且泛化能力良好。
2. 相关工作
当前的方法将中文拼写检查(CSC)视为序列生成问题或序列标注问题。
Wang 等人(2019b)提出了复制机制来生成修正后的序列。Bao 等人(2020)通过基于块的生成模型统一了单字符和多字符的修正。
预训练模型(PTMs)在序列标注任务中取得了成功(Qiu 等人,2020)。
掩蔽语言模型(MLM)被引入作为预训练任务,用于预测基于上下文的掩蔽或替换词。
MLM的模式直观地适合转化为预测拼写错误并进行修正。凭借PTM的强大能力,已取得显著进展(Hong 等人,2019)。基于MLM,混淆集被应用于缩小预测正确字符的搜索空间。Cheng 等人(2020)通过混淆集构建了一个图来帮助最终的预测。Nguyen 等人(2020)提出了一个可适应的混淆集,但其训练过程并非端到端的。
理想情况下,CSC语料库可以通过基于混淆集替换词汇的方式无限构建。
Wang 等人(2018)通过基于OCR和ASR的方法生成了27万个数据。Zhang 等人(2020)通过替换方法生成了500万个增强数据,而Li 等人(2021)通过相同方法生成了900万个增强数据。Zhang 等人(2021)通过随机替换字符为噪声拼音来破坏输入句子,这种新的预训练任务适用于CSC。
最近,一些方法也在CSC中利用了语音和视觉特征。
Liu 等人(2021)使用GRU(Bahdanau 等人,2014)对拼音序列和汉字笔画序列进行编码,作为额外特征。Xu 等人(2021)有类似的设计,但他们编码了字符的图像以获取视觉特征。
Huang 等人(2021)通过音频和视觉模态的知识丰富了字符表示。
我们的做法与这些工作有所不同。
对于语音特征,我们将拼音视为一个整体,而不是序列;对于视觉特征,我们使用了部首,它比笔画更高层次;同时,我们通过图神经网络将这些额外的特征进行融合。
3. 方法
我们将中文拼写检查(CSC)视为一个序列标注问题。
一个包含n个字符的输入序列表示为 ( X = {x_1, x_2, \dots, x_n} ),我们的目标是将其转换为目标序列 ( Y = {y_1, y_2, \dots, y_n} )。在此过程中,错误的字符将被检测并修正。显然,输入和输出共享相同的词汇表,大多数输出字符可以直接从输入中复制。
我们的模型框架如图2所示,包含三个部分:基于BERT的编码器、特征融合模块和预训练组件。以下将详细阐述我们的设计。
3.1 基于MLM的骨干网络
BERT(Devlin 等人,2019)成功的原因之一是其掩蔽语言模型(MLM)预训练任务。BERT随机掩蔽或替换某些词元,然后预测原始词元。将掩蔽和替换的词元视为拼写错误,BERT被适配为拼写检查器。每个输入字符 ( x_i ) 都会通过BERT嵌入层(BERTEmbedding)被映射到其嵌入表示 ( e_i )。然后,( e_i ) 会传递到BERT编码层(BERTEncoder),得到表示 ( h_i ),如下所示:
[ e_i = \text{BERTEmbedding}(x_i), \quad (1) ] [ h_i = \text{BERTEncoder}(e_i), \quad (2) ]
其中 ( e_i, h_i \in \mathbb{R}^{1 \times d} ),且 ( d ) 为隐藏维度。
接下来,( h_i ) 会与所有字符的嵌入进行相似度计算,以获取一个基于词汇表的预测分布 ( \hat{y}_i ),如以下公式所示:
[ \hat{y}_i = \text{Softmax}(h_i E^T), \quad (3) ]
其中 ( E \in \mathbb{R}^{V \times d} ),( \hat{y}_i \in \mathbb{R}^{1 \times V} ),并且 ( V ) 是词汇表的大小。这里,( E ) 表示BERT嵌入层,( E ) 的第i行对应于公式(1)中的 ( e_i )。最后,我们选择字符 ( x_k ) 作为修正结果,其中 ( e_k ) 与 ( h_i ) 具有最高的相似度。
3.2 融合视觉和语音特征
上述骨干网络对于此任务缺乏特别的建模。中文拼写错误大致可以分为两种模式:视觉错误和语音错误。视觉错误与正确字符的形状相似,而语音错误则与正确字符的发音相似。
部分工作利用了外部混淆集,该混淆集预定义了视觉相似对和语音相似对之间的映射(Yu 和 Li,2014;Wang 等人,2019a;Cheng 等人,2020)。这些模型依赖混淆集来过滤候选字符,但混淆集可能过时或不适应特定领域。
为了更好地捕捉这两种错误模式,我们提出了一个特征融合模块,通过图神经网络(GNN)来结合视觉和语音特征。
视觉特征通过部首来建模,部首是汉字的基本组成部分。
语音特征则通过拼音来建模,拼音描述了字符的发音。
我们将这两种特征与字符表示融合,以增强模型对拼写错误的修正能力。
这一融合方法能够有效提升中文拼写检查的性能,尤其在混淆集无法覆盖的错误上表现得尤为出色。
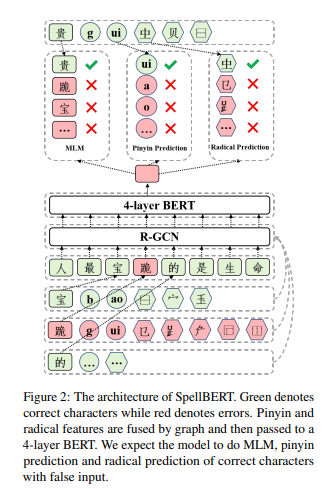
为了建模这两种错误模式,我们通过结合部首和拼音信息,将字符表示 ei 注入视觉和语音特征。汉字可以分解成部件,即部首,而视觉错误通常与正确字符共享部分部首。拼音是汉字的发音描述序列,语音错误通常与正确拼音重叠。基于这些额外的特征,我们的模型可以自动学习视觉相似和语音相似的映射。我们采用关系图卷积网络(Schlichtkrull 等人,2018),简称 R-GCN,将多种特征注入到字符表示 ei 中,公式 1 如下。我们将字符视为节点,输入序列 X 可以自然地组织成一条线性图。部首和拼音也被视为图中的节点。
如果一个部首或拼音属于某个字符,我们在它们之间构建边连接。
我们根据节点对的不同来定义这些连接类型。
此外,我们还在相邻字符之间构建边,因为局部上下文信息对于更好地结合拼音和部首特征是有益的。
因此,我们定义了以下几种类型的边:
-
字符与部首之间的边
-
字符与拼音之间的边
-
字符与固定长度上下文内相邻字符之间的边
-
字符与自身之间的边
我们通过字符嵌入 ei 来初始化字符节点的特征(公式 1)。为了表示和更新部首节点和拼音节点的特征,我们还构建了一个额外的嵌入表,该表通过平均相关字符嵌入来初始化。如图 2 所示,这些特征在关系图上传播,公式如下:
ˆei = σ ( ∑r∈R ∑j∈Nr_i 1/ci,r Wrej + W0ei ) (4)
其中 ei 表示字符 xi 的嵌入,ej 表示连接节点 j 的特征;r 表示边的类型;Nr_i 是边类型 r 连接的节点集合;Wr 是边类型 r 的变换层,ci,r 是一个特定问题的归一化常数,这里设置为 |Nr_i|。最终的 ˆei 可以看作是通过部首和拼音信息增强的字符表示。
最后,我们将增强后的表示与原始字符嵌入结合,公式 3 更新为:
hi = BERTEncoder(ei + ˆei), (5)
其中 hi 表示每个字符的最终表示。
3.3 用于 CSC 的增强预训练任务
已有研究表明,通过预训练类似任务,外部信息可以更好地融入到 BERT 模型中(Peters 等,2019;Zhang 等,2019;Sun 等,2020;Ma 等,2020)。考虑到部首和拼音特征是外部添加的,我们设计了两个额外的预训练任务,即部首预测和拼音预测。
在 MLM(Masked Language Model)中,Devlin 等(2019)随机屏蔽了一定比例的输入标记,然后预测这些标记。在部首和拼音预测中,我们随机屏蔽了字符与其部首和拼音之间的连接,然后预测被屏蔽的连接。
通过重建这些连接,模型可以学习到更好的表示,这些表示不仅包含上下文信息,还融合了视觉和语音信息。
与 MLM 相同,我们随机选择 15% 的字符进行处理。如果选中一个字符,我们的潜在做法如下:
-
10% 的情况下保持字符不变,然后预测该字符本身、其部首和拼音。这是为了匹配下游微调中的情况,其中每个字符都可以直接看到其所有的部首和拼音。
-
60% 的情况下将字符替换为 [MASK],并且以 80% 的概率屏蔽其所有连接。然后预测被屏蔽的字符及其连接。
-
30% 的情况下将字符替换为从混淆集合中采样的一个混淆词,并且以 80% 的概率屏蔽其所有连接。然后预测原始字符及其连接。这是为了迫使我们的模型根据错误的部首和拼音纠正字符。请注意,在此阶段我们仅使用混淆集合来构造拼写错误。
在我们的图中,边没有表示,图仅在 BERT 嵌入层和 BERT 编码器层之间使用。
因此,我们将边预测任务转换为标记分类任务。对于每个字符 xi,我们将其一个部首和拼音作为真实值,并从其他不属于该字符的部首和拼音中进行负采样。
我们使用这些部首和拼音的特征嵌入作为分类层,以计算它们与 BERT 编码器层中 hi 的相似度,公式 2 如下。相关的嵌入将被拉近,而不相关的嵌入则会被拉远。
3.4 降低参数量
考虑到部署时对计算效率的需求,需要一个轻量级的模型。
我们仅使用 4 层 BERT 来初始化、预训练和微调我们的模型,这将总参数量从 1.1 亿减少到 5500 万。
我们还测量了轻量级模型的推理速度,实验结果表明,它在时间效率上优于 12 层的 BERT 模型。
4 实验
4.1 预训练设置
我们使用 BERT(Devlin 等,2019)基础模型作为初始化,仅使用前 4 层。我们的模型是通过 PyTorch(Paszke 等,2019)和 DGL(Wang 等,2019c)实现的。我们随机选择了 Xu(2019)提供的 100 万个句子作为预训练语料,并将句子填充到最大长度为 128。我们将学习率设置为 5e-5,批量大小为 1024,并在 4 块 RTX 3090 上预训练 10,000 步,大约花费 2 天时间。
4.2 数据集和微调设置
我们在三个广泛使用的数据集上进行 CSC 实验,分别是 SIGHAN14(Yu 等,2014)、SIGHAN15(Tseng 等,2015)和 OCR(Hong 等,2019),并将其标记为 csc14、csc15 和 ocr。csc14 和 csc15 的原始语料来自中文学习者的作文,采用繁体中文,Wang 等(2019a)、Zhang 等(2020)和 Nguyen 等(2020)将其转换为简体中文,并使用 Wang 等(2018)提供的增强数据。由于我们的预训练语料是简体中文,我们使用了后者的设置。我们直接使用了 Cheng 等(2020)提供的语料。在这种设置下,csc14、csc15 的训练集以及 Wang 等(2018)提供的增强数据被合并为一个新的训练集。我们分别在 csc14 和 csc15 的测试集上对模型进行了微调。
ocr 是一个简体中文数据集,句子较短,且来自娱乐领域。我们只使用 ocr 中的数据进行训练和测试,总共有 4575 个句子。
对于不同的数据集,我们发现以下超参数范围效果较好:批量大小设置为 {32, 64},学习率设置为 {1e-5, 2e-5, 3e-5},训练的 epoch 数量从 5 到 20。
在 csc14 和 csc15 上,我们通过官方工具(Tseng 等,2015)在句子级别评估我们的模型;在 ocr 上,评估指标是编辑级别,通过另一个官方工具(Wu 等,2013)计算。
4.3 结果与分析
主要结果
如表 1 所示,我们将 SpellBERT 与最近的工作和一个 4 层 BERT 基线进行了比较。
它们都是基于 BERT 的,这意味着它们的参数数量至少是我们模型的两倍。
然而,通过融合拼音和部首特征以及特征丰富的预训练,SpellBERT 在 OCR 数据集上仍然表现最好。
与 Nguyen 等(2020)相比,我们的工作在 csc14 和 csc15 上取得了更好的结果。
尽管如此,SpellBERT 与 SpellGCN(Cheng 等,2020)之间仍然存在差距,这表明我们设计的额外模块并未完全弥补模型参数减少带来的差异。
表 1:检测级别和修正级别的结果
| Model | Detection Level | Correction Level | ocr | csc14 | csc15 | ocr | csc14 | csc15 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| Nguyen et al. (2020) (BERT 12 layers) | - | - | - | 82.5 | 61.6 | 70.5 | 84.5 | 71.8 | 77.6 | - | - | - | 82.1 | 60.2 | 69.4 | 84.2 | 70.2 | 76.5 |
| Bao et al. (2020) (BERT 12 layers) | 77.6 | 63.3 | 69.7 | - | - | - | - | - | - | 46.5 | 37.9 | 41.7 | - | - | - | - | - | - |
| Cheng et al. (2020) (BERT 12 layers) | - | - | - | 83.1 | 69.5 | 75.7 | 85.9 | 80.6 | 83.1 | - | - | - | 82.8 | 67.8 | 74.5 | 85.4 | 77.6 | 81.3 |
| BERT (4 layers) | 67.8 | 35.2 | 46.4 | 82.6 | 59.0 | 68.8 | 85.2 | 68.9 | 76.2 | 43.2 | 22.4 | 29.5 | 82.4 | 58.0 | 68.1 | 84.8 | 66.9 | 74.8 |
| SpellBERT (4 layers) | 83.5 | 60.4 | 70.1 | 83.1 | 62.0 | 71.0 | 87.5 | 73.6 | 80.0 | 66.0 | 47.7 | 55.4 | 82.9 | 61.2 | 70.4 | 87.1 | 71.5 | 78.5 |
| w/o graph | 81.2 | 61.4 | 69.9 | 81.8 | 62.0 | 70.5 | 87.8 | 73.1 | 79.8 | 61.1 | 46.2 | 52.6 | 81.5 | 60.5 | 69.4 | 87.5 | 71.1 | 78.4 |
| w/o pre-training | 67.6 | 36.1 | 47.1 | 81.3 | 60.5 | 69.3 | 86.4 | 70.7 | 77.8 | 51.7 | 27.6 | 36.0 | 81.0 | 59.3 | 68.5 | 86.0 | 68.0 | 75.9 |
说明:
对于基线模型,我们使用了它们报告的结果。Hong 等(2019)和 Bao 等(2020)在 csc14 和 csc15 上使用了繁体中文语料,因此它们的结果与我们的结果不可直接比较。
表 2:数据集统计信息
| Dataset | Noises | Errors covered by confusion sets |
|---|---|---|
| ocr test | 0/1000 (0%) | 302/1303 (23.2%) |
| csc14 test | 16/1062 (1.5%) | 663/792 (83.7%) |
| csc15 test | 10/1100 (0.9%) | 605/715 (84.6%) |
说明:
- Noises 指的是在将数据转换为简体中文时产生的噪音数据。
- Errors covered by confusion sets 表示在测试数据中,使用混淆集(Wu et al., 2013)所覆盖的错误数量。
模块的有效性
我们分别去除图结构和预训练阶段,以测试它们的有效性。
结果显示,预训练通常能显著提升所有数据集的性能,这表明预训练对 CSC 是一种有效的方法。图机制的贡献相对不那么显著,但它使得我们能够将编码器的参数转移到其他架构中。
混淆集合的影响
需要注意的是,我们在 OCR 数据集上的改进要比在 csc14 和 csc15 上的改进更为明显。首先,在将数据转换为简体中文时,难免会引入噪声,csc14 和 csc15 的噪声比例分别为 1.5% 和 0.9%。另一个原因是,之前的工作(如 Nguyen 等,2020 和 Bao 等,2020)依赖混淆集合来筛选候选项。在 csc14 和 csc15 中,83.7% 和 84.6% 的测试错误被混淆集合覆盖,这是一种理想且不常见的情况。而在 OCR 数据集中,由于混淆集合覆盖的错误更少,性能自然较差。
在 OCR 数据集上,混淆集合只能覆盖 23.2% 的错误,且句子的平均长度较短。可以将混淆集合视为 OCR 中的外域数据。SpellBERT 在该数据集上的表现有了显著提升,表明 SpellBERT 可以在不同语料库上良好地泛化,而不依赖混淆集合。消融实验进一步证明了我们提出的模块有助于处理未知错误。
效率分析
与 12 层 BERT 相比,SpellBERT 的参数数量只有其一半,因此在空间效率上比基于 BERT 的其他工作更具优势。
为了验证时间效率,我们根据每个句子的绝对时间消耗进行了速度测量,参照了 Hong 等(2019)中提到的方法。
表 3 的结果表明,SpellBERT 的速度至少提高了 1.5 倍。
表 3:速度比较(每句处理时间,毫秒)
| Dataset | 平均长度 | 每句时间 (ms) | 加速比 |
|---|---|---|---|
| ocr test | 10.2 | 48 | 1.58x |
| csc14 test | 50.0 | 98 | 1.56x |
| csc15 test | 30.6 | 77 | 1.54x |
说明:
- Preprocessing time(预处理时间)已被排除。
- 实验设置:批量大小为 1,使用 4 核心 Intel(R) Xeon(R) Silver 4114T CPU,参照 Hong et al. (2019) 的实验环境进行。
5 结论
在本研究中,我们提出了一种轻量级的预训练模型——SpellBERT,用于中文拼写检查。
我们将拼音和部首作为语音和视觉特征,并设计了两个预训练任务,旨在使预训练模型能够显式地捕捉错误模式。
实验结果表明,SpellBERT的表现与大型预训练模型相当。
此外,SpellBERT在微调和推理阶段可以直接使用,无需混淆集,这使得使用更加方便,并且能够更好地处理现有混淆集中未能覆盖的错误。
致谢
本研究得到了中国国家重点研发计划(项目编号:2020AAA0108702)和国家自然科学基金(项目编号:62022027)的支持。
小结
希望本文对你有所帮助,如果喜欢,欢迎点赞收藏转发一波。
我是老马,期待与你的下次相遇。
参考资料
https://blog.csdn.net/qq_36426650/article/details/122796348
