基本介绍
a) 标注问题(Tagging)
i. 任务(Task): 在句子中为每个词标上合适的词性(Label each word in a sentence with its appropriate part of speech)
ii. 输入(Input): Our enemies are innovative and resourceful , and so are we. They never stop thinking about new ways to harm our country and our people, and neither do we.
iii. 输出(Output): Our/PRP$ enemies/NNS are/VBP innovative/JJ and/CC resourceful/JJ ,/, and/CC so/RB are/VB we/PRP ?/?. They/PRP never/RB stop/VB thinking/VBG about/IN new/JJ ways/NNS to/TO harm/VB our/PROP$ country/NN and/CC our/PRP$ people/NN, and/CC neither/DT do/VB we/PRP.
b) Motivation
i. 词性标注对于许多应用领域是非常重要的(Part-of-speech(POS) tagging is important for many applications)
1. 语法分析(Parsing)
2. 语言模型(Language modeling)
3. 问答系统和信息抽取(Q&A and Information extraction)
4. 文本语音转换(Text-to-speech)
ii. 标注技术可用于各种任务(Tagging techniques can be used for a variety of tasks)
1. 语义标注(Semantic tagging)
2. 对话标注(Dialogue tagging)
c) 如何确定标记集(How to determine the tag set)?
i. “The definition [of the parts of speech] are very far from having attained the degree of exactitude found in Euclidean geometry” Jespersen, The Philosophy of Grammar
ii. 粗糙的词典类别划分基本达成一致至少对某些语言来说(Agreement on coarse lexical categories (at least, for some languages))
1. 封闭类(Closed class): 介词,限定词,代词,小品词,助动词(prepositions, determiners, pronouns, particles, auxiliary verbs)
2. 开放类(Open class): 名词,动词,形容词和副词(nouns, verbs, adjectives and adverbs)
iii. 各种粒度的多种标记集(Multiple tag sets of various granularity)
1. Penn tag set (45 tags), Brown tag set (87 tags), CLAWS2 tag set (132 tags)
- 示例:Penn Tree Tags
标记(Tag) 说明(Description) 举例(Example) CC conjunction and, but DT determiner a, the JJ adjective red NN noun, sing. rose RB adverb quickly VBD verb, past tense grew
d) 标注难吗(Is Tagging Hard)?
i. 举例:“Time flies like an arrow”
ii. 许多单词可能会出现在几种不同的类别中(Many words may appear in several categories)
iii. 然而,大多数单词似乎主要在一个类别中出现(However, most words appear predominantly in one category)
1. “Dumb”标注器在给单词标注最常用的标记时获得了90%的准确率(“Dumb” tagger which assigns the most common tag to each word achieves 90% accuracy (Charniak et al., 1993))
2. 对于90%的准确率我们满足吗(Are we happy with 90%)?
iv. 标注的信息资源(Information Sources in Tagging):
1. 词汇(Lexical): 观察单词本身(look at word itself)
单词(Word) 名词(Noun) 动词(Verb) 介词(Preposition) flies 21 23 0 like 10 30 21
2. 组合(Syntagmatic): 观察邻近单词(look at nearby words)
——哪个组合更像(What is more likely): “DT JJ NN” or “DT JJ VBP“?
学习标注(Learning to Tag)
-
基于转换的学习(Transformation-based Learning)
-
隐马尔科夫标注器(Hidden Markov Model Taggers)
-
对数线性模型(Log-linear models)
二、 基于转换的学习(Transformation-based Learning ——TBL)
a) 概述:
i. TBL 介于符号法和基于语料库方法之间(TBL is “in between” symbolic and corpus-based methods);
ii. TBL利用了更广泛的词汇知识和句法规则——很少的参数估计(TBL exploit a wider range of lexical and syntactic regularities (very few parameters to estimate))
iii. TBL关键部分(Key TBL components):
-
一个容许的用于“纠错”的转换规范(a specification of which “error-correcting” transformations are admissible)
-
学习算法(the learning algorithm)
b) 转换(Transformations)
i. 重写规则(Rewrite rule): tag1 → tag2, 如果C满足某个条件(if C holds)
– 模板是手工选择的(Templates are hand-selected)
ii. 触发条件(Triggering environment (C))::
-
标记触发(tag-triggered)
-
单词触发(word-triggered)
-
形态触发(morphology-triggered)
c) 转换模板(Transformation Templates)
i. 图略;
ii. 附:TBL算法的提出者Eric Brill(1995-Transformation-Based Error-Driven Learning and Natural Language Processing: A Case Study in Part of Speech Tagging)中的模板:
-
The preceding (following) word is tagged z.
-
The word two before (after) is tagged z.
-
One of the two preceding (following) words is tagged z.
-
One of the three preceding (following) words is tagged z.
-
The preceding word is tagged z and the following word is tagged w.
-
The preceding (following) word is tagged z and the word two before (after) is tagged w.
当条件满足时,将标记1变为标记2(Change tag1 to tag 2 when),其中变量a,b,z和w在词性集里取值(where a, b, z and w are variables over the set of parts of speech)。
iii. 举例: 源标记 目标标记 触发条件 NN VB previous tag is TO VBP VB one of the previous tags is MD JJR JJR next tag is JJ VBP VB one of the prev. two words is “n’t”
d) TBL的学习(Learning component of TBL):
i. 贪婪搜索转换的最优序列(Greedy search for the optimal sequence of transformations):
-
选择最好的转换(Select the best transformations);
-
决定它们应用的顺序(Determine their order of applications);
e) 算法(Algorithm)
注释(Notations):
-
Ck — 第k次迭代时的语料库标注(corpus tagging at iteration k)
-
E(Ck) — k次标注语料库的错误数(the number of mistakes in tagged corpus)
C0 := corpus with each word tagged with its most frequent tag
for k:= 0 step 1 do
v:=the transformation ui that minimizes r(ui(Ck))
if (E(Ck)− E(v(Ck)) < then break fi
Ck+1 := v(Ck)
τk+1 := τ
end
输出序列(Output sequence): τ1,...,τn
f) 初始化(Initialization)
i. 备选方案(Alternative approaches)
-
随机(random)
-
频率最多的标记(most frequent tag)
-
…
ii. 实际上TBL对于初始分配并不敏感(In practice, TBL is not sensitive to the original assignment)
g) 规则应用(Rule Application):
i. 从左到右的应用顺序(Left-to-right order of application)
ii. Immediate vs delayed effect:
Consider “A → B if the preceding tag is A”
– Immediate: AAAA →?
– Delayed: AAAA → ?
h) 规则选择(Rule Selection):
i. 我们选择模板及其相应的实例(We select both the template, and its instantiation);
ii. 每个规则对已给出的标注进行修改(Each rule τ modifies given annotations)
- 某些情况下提高(improves in some places ):Cimproved(τ)
- 某些情况下降低(worsens in some places):Cworsened (τ)
- 对剩余数据不触动(does not touch the remaining data)
iii. 规则的贡献是(The contribution of the rule is): Cimproved(τ)− Cworsened (τ)
iv. 第i次迭代的规则选择(Rule selection at iteration i):
τ_selected (i)= argmax_τ_contrib(τ)
i) TBL标注器(The Tagger):
i. 输入(Input):
-
未标注的数据(untagged data);
-
经由学习器学习得到规则(S)(rules (S) learned by the learner);
ii. 标注(Tagging):
-
使用与学习器相同的初始值(use the same initialization as the learner did)
-
应用所有学习得到的规则,保持合适的应用顺序(apply all the learned rules ,keep the proper order of application)
-
最后的即时数据为输出(the last intermediate data is the output)
j) 讨论(Discussion)
i. TBL的时间复杂度是多少(What is the time complexity of TBL)? ii. 有无可能建立一个无监督的TBL标注器(Is it possible to develop an unsupervised TBL tagger)?
k) 与其他模型的关系(Relation to Other Models):
i. 概率模型(Probabilistic models):
- “k-best”标注(“k-best” tagging);
- 对先验知识编码(encoding of prior knowledge);
ii. 决策树(Decision Trees)
- TBL 很有效(TBL is more powerful (Brill, 1995));
- TBL对于过度学习“免疫”(TBL is immune to overfitting)。
关于TBL,《自然语言处理综论》第8章有更通俗的解释和更详细的算法说明。
马尔科夫模型(Markov Model)
a) 直观(Intuition):
对于序列中的每个单词挑选最可能的标记(Pick the most likely tag for each word of a sequence)
i. 我们将对P(T,S)建模,其中T是一个标记序列,S是一个单词序列(We will model P(T,S), where T is a sequence of tags, and S is a sequence of words)
ii.
P({T}delim{|}{S}{})={P(T,S)}/{sum{T}{}{P(T,S)】
Tagger(S)= argmax_{T in T^n}logP({T}delim{|}{S}{})
= argmax_{T in T^n}logP({T,S}{})
b) 参数估计(Parameter Estimation)
i. 应用链式法则(Apply chain rule):
P(T,S)={prod{j=1}{n}{P({T_j}delim{|}{S_1,...S_{j-1},T_1,...,T_{j-1】{})】*
P({S_j}delim{|}{S_1,...S_{j-1}T_1,...,T_{j】{})
ii. 独立性假设(马尔科夫假设)
(Assume independence (Markov assumption)):
={prod{j=1}{n}{P({T_j}delim{|}{T_{j-2},T_{j-1】{})】*P({S_j}delim{|}{T_j}{})
c) 举例(Example)
i. They/PRP never/RB stop/VB thinking/VBG about/IN new/JJ
ways/NNS to/TO harm/VB our/PROP$ country/NN and/CC our/PRP$
people/NN, and/CC neither/DT do/VB we/PRP.
ii. P(T, S)=P(PRP|S, S)∗P(They|PRP)∗P(RB|S, PRP)∗P(never|RB)∗…
d) 估计转移概率(Estimating Transition Probabilities)
P({T_j}delim{|}{T_{j-2},T_{j-1】{})=
{lambda_1}*【Count(T_{j-2},T_{j-1},T_j)}/{Count(T_{j-2},T_{j-1})】
+{lambda_2}*【Count(T_{j-1},T_j)}/{Count(T_{j-1})】
+{lambda_3}*【Count(T_j)}/{Count(sum{i}{}{T_i})】
e) 估计发射概率(Estimating Emission Probabilities)
P({S_j}delim{|}{T_j}{})={Count(S_j,T_j)}/{Count(T_j)}
i. 问题(Problem): 未登录词或罕见词(unknown or rare words)
- 专有名词(Proper names)
“King Abdullah of Jordan, the King of Morocco, I mean, there’s a series of places — Qatar, Oman – I mean, places that are developing— Bahrain — they’re all developing the habits of free societies.”
- 新词(New words)
“They misunderestimated me.”
f) 处理低频词(Dealing with Low Frequency Words)
i. 将词表分为两个集合(Split vocabulary into two sets)
1. 常用词(Frequent words)— 在训练集中出现超过5次的词(words occurring more than 5 times in training)
2. 低频词(Low frequency words)— 训练集中的其他词(all other words)
ii. 依据前缀、后缀等将低频词映射到一个小的、有限的集合中(Map low frequency words into a small, finite set, depending on prefixes, suffixes etc. (see Bikel et al., 1998))
g) 有效标注(Efficient Tagging)
i. 对于一个单词序列,如何寻找最可能的标记序列(How to find the most likely a sequence of tags for a sequence of words)?
-
盲目搜索的方法是可怕的(The brute force search is dreadful)— 对于N个标记和W个单词计算代价是N^W.for N tags and W words, the cost is NW
-
主意(Idea): 使用备忘录(Viterbi算法)(use memoization (the Viterbi Algorithm))
——结束于相同标记的序列可以压缩在一起,因为下一个标记仅依赖于此序列的当前标记(Sequences that end in the same tag can be collapsed together since the next tag depends only on the current tag of the sequence)
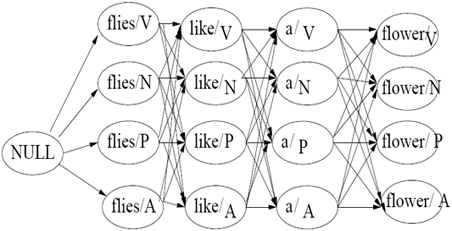
h) Viterbi 算法(The Viterbi Algorithm)
i. 初始情况(Base case):
pi delim{[}{0, START}{]} = log 1 = 0
pi delim{[}{0, t_{-1】{]} = log 0 = infty
对所有其他的t_{-1}(for all other t_{-1})
ii. 递归情况(Recursive case):
- 对于i = 1…S.length及对于所有的t_{-1} in T:
pi delim{[}{i, t_{-1】{]} = {max}under{t in T union START}{ pi delim{[}{i-1, t}{]} + log P(t_{-1}delim{|}{t}{}) + log P(S_i delim{|}{t_{-1】{})}
- 回朔指针允许我们找出最大概率序列(Backpointers allow us to recover the max probability sequence):
BP delim{[}{i, t_{-1】{]} = {argmax}under{t in T union START}{ pi delim{[}{i-1, t}{]} + log P(t_{-1}delim{|}{t}{}) + log P(S_i delim{|}{t_{-1】{})}
i) 性能(Performance)
i. HMM标注器对于训练非常简单(HMM taggers are very simple to train)
ii. 表现相对很好(Perform relatively well) (over 90% performance on named entities)
iii. 最大的困难是对 p(单词|标记) 建模(Main difficulty is modeling of p(word|tag))
四、 结论(Conclusions)
a) 标注是一个相对比较简单的任务,至少在一个监督框架下对于英语来说(Tagging is relatively easy task (at least, in a supervised framework, and for English))
b) 影响标注器性能的因素包括(Factors that impact tagger performance include):
i. 训练集数量(The amount of training data available)
ii. 标记集(The tag set)
iii. 训练集和测试集的词汇差异(The difference in vocabulary between the training and the testing)
iv. 未登录词(Unknown words)
c) TBL和HMM框架可用于其他自然语言处理任务(TBL and HMM framework can be used for other tasks)
