介绍
这篇写的很好 https://levy5307.github.io/blog/PacificA/
PacificA是微软实现的一款强一致性的分布式共识协议,具有简单易实现、可用性高的优点
本篇文章的内容都是从微软发布的《PacificA: Replicationi in Log-Based Distributed Storage System》总结而来,如有疑惑请移步。
前提条件
对于PacificA,需要系统满足下述条件:
-
server可能发生故障,但是只有fail-stop故障,不能是fail-slow
-
message可以被丢弃或者乱序,但是不能被修改
-
网络分区可能发生
-
不同服务器上的时钟不一定同步,甚至不一定是松散同步的,但是时间漂移有上限
primary/backup结构
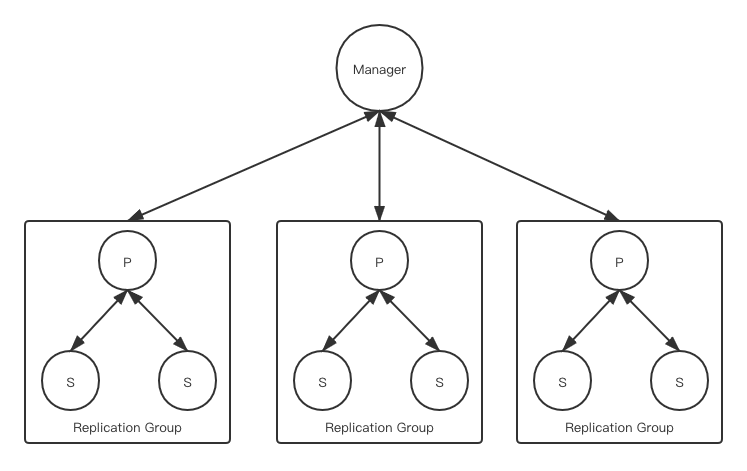
如上图所示,PacificA采取了primary-backup结构。
同时我们将客户端请求分为两种:query和update。其中query不会更新数据、而update则会更新。
当一个replica group中的所有server都按照相同的顺序处理请求时,强一致性便可以得到保证。对于update请求,primary为其分配一个单调并连续增长的sn编号,并指示所有的secondary按照编号顺序执行update请求。我们为每个replica维护了一个prepare list和commit point,该prepare list是按照sn排序的。在prepare list中commit point之前的部分叫做committed list。committed list中的数据保证不会丢失(除非系统发生不可忍受的故障,即发生了所有replica的永久性故障)。
在primary-backup模型中,所有的请求都会发送给primary。
对于query请求,primary只需要本地处理就可以了,其获取当前最新的数据返回给客户端。但是对于update请求则需要所有的secondary都参与进来。
其具体时序图如下:
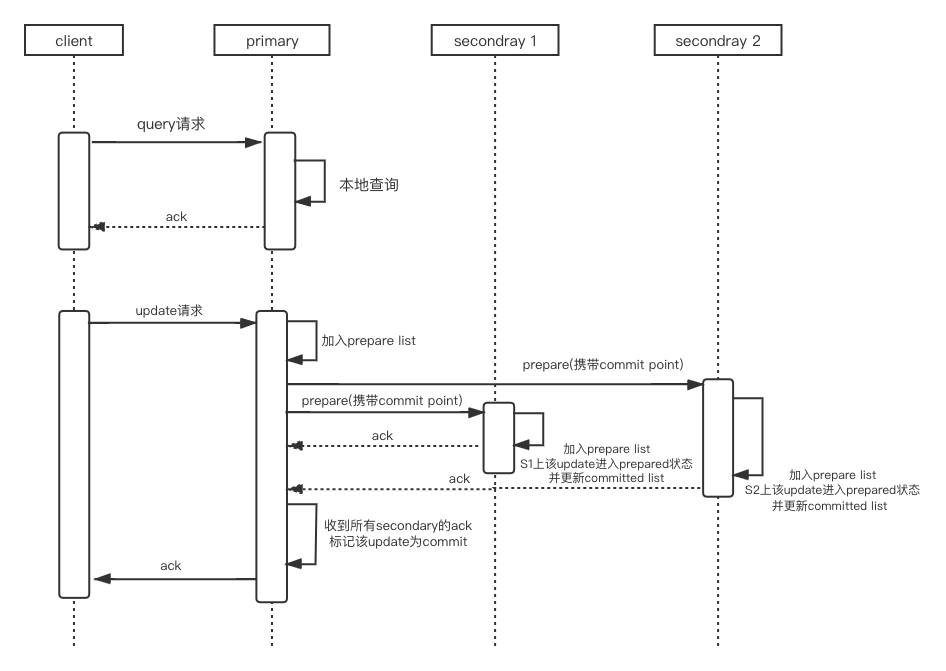
由于:
只有当所有的secondary将该请求加入到prepare list中的之后,primary才会将其加入到committed list中,并且, 只有primary将该请求加入到committed list之后,secondary才会将其加入到committed list
所以,我们可以得到如下结论,我们称之为Commit Invariant。
Commit Invariant:假设p是primary,并且q是当前配置中的任意一个replica,committed(q) ⊆ committed(p) ⊆ prepared(q)成立.
在我们的replication模型里将数据管理和配置管理分割开来,接下来我们将看一下配置管理。
配置管理
在我们的系统中,有一个叫做global configuration manager的组件存在,他用来管理所有replica group的配置,他保存当前的配置及其版本号。
一个server可以根据failure detection探测到某个replica下线而删除某一个replica,相反也可以添加一个replica。这时该server需要将修改后的配置文件和当前配置的版本号发送给configuration manager。当版本号和configuration manager保存的版本号匹配时,新的配置将被采纳并将配置版本号+1
当发生网络分区时,配置冲突将会发生:primary尝试删除secondary;而secondary则尝试将自己提升为primary。此时configuration manager将如何处理这种情况呢?其实很简单,configuration manager只需要接收最早来的请求,而不管是primary发送来的、还是secondary发送来的。此时其接收到最早来的请求之后,会更新其本地保存的版本号,所以第二个之后来的请求都将会被拒绝。
任何遵从Primary Invariant的错误探测机制都可以用来删除一个replica:
Primary Invariant: 在任何时候,只有configuration manager的当前配置中将p作为primary时,服务器p才会认为自己是primary。因此在任意时候,一个replica group中仅有一个服务器认为自己是primary。
租期和错误探测
即使有configuration manager来维护当前配置,但是Primary Invariant也不一定能够保证。
例如:
-
由于网络抖动,s1将自己提升为primary,manager接受了
-
此时old primary并不知情,仍然在处理请求
-
假如old primary处理读,new primary在处理写,此时从old primary读取的数据有可能是旧值
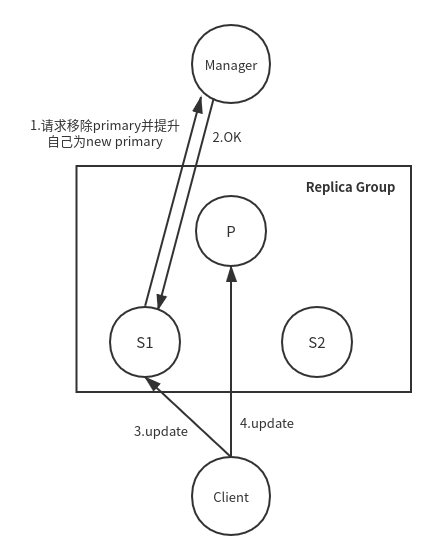
这显然违反了强一致性。导致这个问题的根本原因是不同server上的配置文件的local view不一定相同,也就是说,有可能某些server上保存的是旧版本的配置文件、而没来得及更新。
为了解决这个问题采用了以租期为基础的错误探测机制。
在一个租期内,primary定期的向secondary发送beacons,并等待其acknowledge。从最新一次接收到ack的beacon的发送时间开始,如果经过一个固定的时间(lease period)内没有收到acknowledge,那么primary则认为自己的租期已经结束了,此时primary将停止处理任何请求并且联系configuration manager去移除相应的secondary。由于primary及时将自己租期结束,从而避免了old primary和新primary同时存在。
另外,对于secondary如果在一定时间(grace period)内没有收到来自primary的beacon,那么其同样会通知configuration manager,令其移除primary并令自己成为新的primary。
如果lease period <= grace period,那么primary的响应一定是要早于secondary的,也就是说,如果primary没有挂掉的话,primary将自己置为不可用一定早于secondary提升自己为primary,从而避免了多primary存在,保证了Primary Invariant
|--- lease period ----| lease IsExpired, commit suicide
|---- lease period ----|
replica: ---------------------------------------------------------------->
\ / \ / _\
beacon ack beacon ack x (beacon deliver failed)
_\/ _\/
meta : ---------------------------------------------------------------->
|----- grace period -----|
|---- grace period -----| grace IsExpired, declare worker dead
NOTE: 为了减少failure detector占用过多的资源,可以将beacon和acknowledge附加在replication信息上,当数据通路空闲时再单独发送beacon。
Reconfiguration, Reconciliation and Recovery
本协议最复杂的部分就是如何处理reconfiguration。我们将reconfiguration分为三种:移除sedondary、移除primary和增加secondary。下面我们来分别说明。
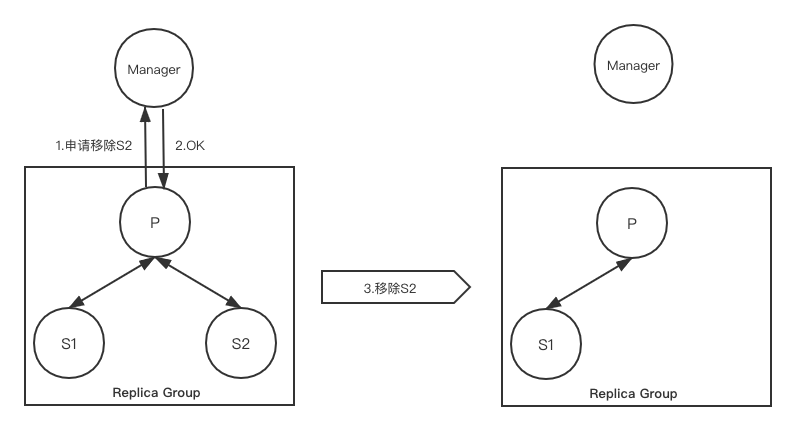
移除secondaries
参照上述租期的概念,当primary怀疑一些secondary上发生了错误时,便会触发移除这些secondary。
此时primary会向manager发送一个新版本的配置,该配置中将其怀疑的这些secondary移除。
当manager接受了配置后,primary才能继续工作(因为当发现secondary不可用时,primary先是认为自己的租期到期了,并停止处理任何请求)
移除primary
该过程的触发是某个secondary怀疑primary不可用,然后便会向manager发送一个新版本配置,该配置中将old primary移除并将自己提升为primary。当manager同意后,该secondary就将自己视为了new primary。
但是此时该new primary还不能开始处理请求,还需要经过reconciliation才可以。
在reconciliation过程中,new primary将其所有prepare list中未commit的prepare发送至secondaries,令这些prepare最后commit。并令一些secondary删除其本地有、而new prmary没有的prepare。
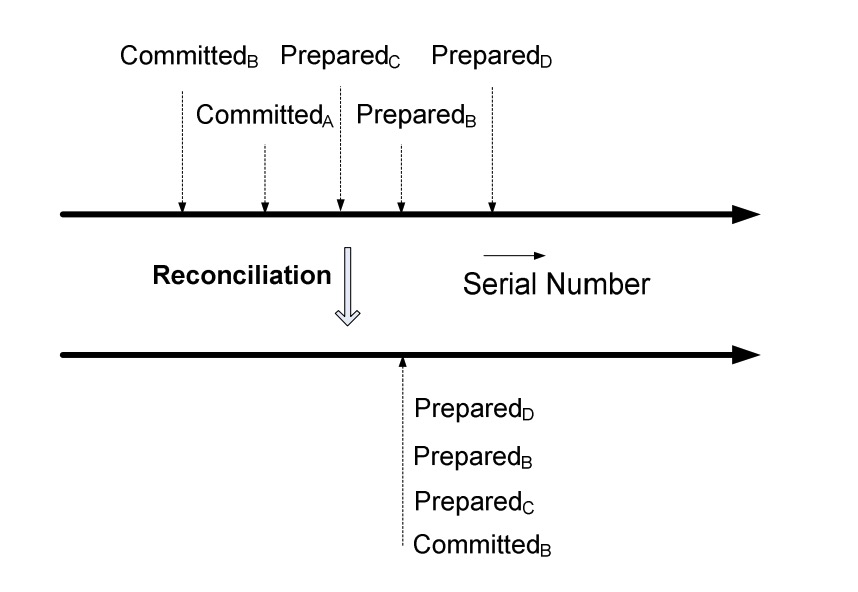
如上图所示,A是old primary,随后B替换掉A成为new primary。上面一条线表示进行reconciliation之前的prepare list和committed list状态。下面一条线表示执行完reconciliation之后的状态。
由于任何一个secondary的prepared list都包含了所有committed request,因此reconciliation确保可以遵循Reconfiguration Invariant,即:
Reconfiguration Invariant: 如果primary p在时间点t执行了reconciliation,那么t之前的时间,该replica group中任何replica上的committed list都是t这个时间点的commited list的前缀。
这也就说明了,任何previous primary的committed list都是new primary的committed list的前缀。
添加新secondaries
在将一个新的secondary加入到replica group时,必须要保证Commit Invariant,这就要求新的replicas在加入replica group之前必须拥有了适当的prepared list,我们将该过程称为recovery。
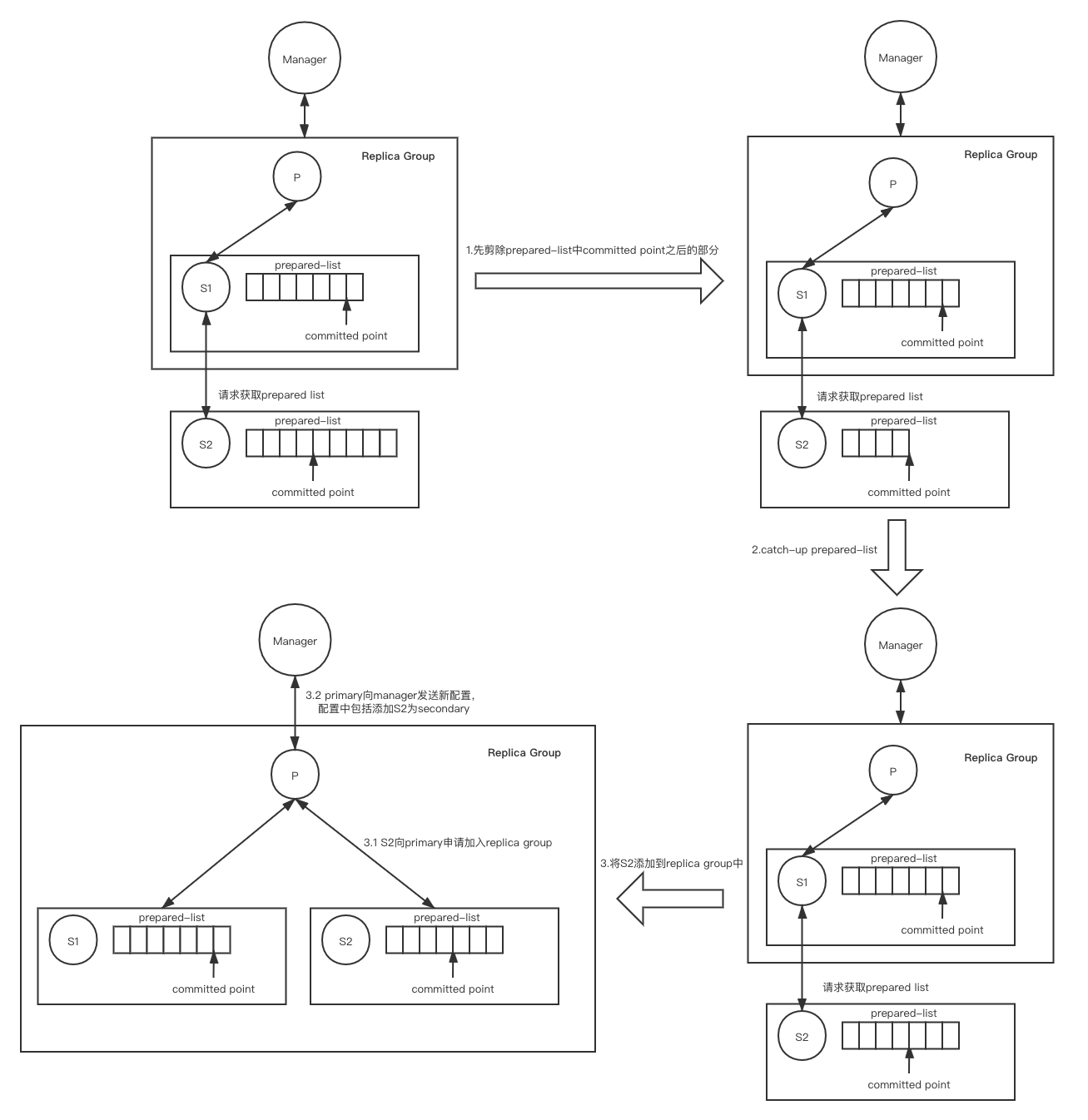
一种简单的实现recovery的方法是,在new replica复制完prepared list之前,primary delay执行所有的请求,但是这在实践中是不可接受的。另一种替换方式是,该new replica在刚加入时作为candidate secondary。该candidate secondary在任何一个replica中复制prepare list,当其catch up后再令primary将其添加为secondary,然后由primary向configuration manager发送新版本配置,在该配置中将该candidate secondary添加为正式的secondary。
当然,由于candidate需要cache up prepared list, 所以recovery是很耗费资源的。但是一个从来没有在该replica group存在过的replica加入时,full state transfer是在所难免的。但是对于一个replica曾经在该replica group存在过的情况(例如由于网络分区、或者该replica曾经发生过某种错误),则完全可以避免full state transfer,其只需要复制其本地所没有的部分prepared list就可以了。
但是这里有一点需要注意,根据Reconfiguration Invariant,任何一个old replica的committed list一定是当前committed list和prepared list的前缀,但是old replica上的prepared list却不一定是当前prepared list的前缀(这种情况是由于该replica脱离replica group之后,发生了primary切换,详情可见reconciliation图)。因此,任何old replica只能保存其prepared list到committed point,在其之后的部分完全剪除,然后再执行cache-up recovery来获取剩余的prepared-list。
具体执行流程如下图(在这里为了简化说明,假设添加secondary过程中客户端没有update请求):
Discussions
可用性及性能
在PacificA中,对于一个有n个节点的replica group,可以允许n-1个节点挂掉而仍然可以对外提供服务。
同时,可以令Configuration manager有多个,并运用Paxos等算法来管理以实现其高可用。当然,configuration manager的不可用并不影响正常情况下的读写操作。
由于Configuration manager并不参与到正常情况下的读写操作,并且只有在replica group中的节点需要reconfiguration的时候参与进来,所以其不会成为性能瓶颈。
replica group挂掉后的数据持久性
上面讲到,对于一个有n个节点的replica group,可以允许n-1个节点挂掉而正常对外提供服务。但是当replica group中的所有节点都挂掉后就不能正常工作了。如果所有的节点永久性挂掉了,那么数据就丢失了。但是如果有一台节点恢复、并且Configuration Manager也恢复,那么数据将不会丢失。
为了实现replica group整体挂掉情况下的数据持久性,所有的replica都将prepared list和committed point保存到持久化存储设备上。
当一个replica从failure中恢复过来,它首先联系configuration manager,查看其是否是当前配置中的replica,如果是的话,获取其角色:如果是primary,那么它将尝试向所有的secondaries重新获取租期,如果它是secondary,它将回复当前primary的beacon信息。
与Paxos对比
在Paxos中,一个请求在大多数的replica节点上达到prepared状态后便可以commit,对于query请求也是如此。但是在PacificA中,对于update请求,需要所有的replica节点都达到prepared状态才能commit。但是对于读请求,只需要读primary就可以了,无需走replication流程,这样带来下面几个不同:
性能
Paxos对于少数replica的性能问题不敏感,因为他只需要大部分节点commit就可以了,其他的几个可以catch up in background。同样,少数replica的失败对性能有非常小的影响。
但是,在PacificA协议中,任何一个节点的变慢都会导致整体变慢。也就是说,PacificA对于抖动更加敏感。任何一个节点的失败,replica group都在reconfiguration完成后停止对外提供服务。如此一来,租期timeout值的设置就需要非常谨慎:如果设置过大,那么在reconfiguration中将有过长的时间不能提供服务;如果设置过小,将会产生false suspicion,这将导致从replica group中移除一些non-faulty但是当时只是有些慢的replica
可用性
当大多数的replica挂掉后Paxos便不可用了,但是在PacificA中,只要有一个节点存在便可以对外提供服务,所以PacificA可用性是好过Paxos的。
简单易实现
显然PacificA比起Paxos来简单的多,更容易实现
Weakening Strong Consistency
有时候强一致性不是必要的,并且减弱一致性会带来一些性能上的提升。
强一致性有如下两个要求:
所有的副本必须以相同的顺序执行更新操作 查询操作返回最新的状态 减弱第一条将会导致不同replica之间的state diversion。这个处理起来非常麻烦。所以我们主要从第二点入手。这里主要有两种方式来实现:
第一种就是去掉租期。去掉租期的话,将会导致Primary Invariant无法保证,也就是说,可能会在某个时间,replica group中有两个primary。当查询请求发往old primary时,将有可能访问旧的数据。但是无需担心state diversion的问题,因为new primary肯定是先前配置中replica group中的一员,这样当old primary接收到update请求,若要提交必须所有secondary prepared。当发往new primary之后,他知道自己是new primary,将不会接受该prepare,导致update失败
第二种便是secondary也参与处理读请求。发往secondary的请求有可能读到过期的数据。
是什么?
PacificA严格来说不是一个算法,而是一个分布式一致性框架。
它采用配置集群和存储集群的方式,实现数控分离,这点和SDN有点像。
其中配置集群负责管理,具体说来是采用了ETCD方案,而ETCD又是采用raft算法来实现一致性的。
具体说来,选主的过程可以概括为:从者失联,自立为王;主者失联,下野流放。
还有一点有意思的是,这里也应用了一种叫做租约机制的玩意,形象的说就是一厢情愿。
所谓一厢,指的是授权者颁布lease时,不会管接收方的状态。
就像男孩子追女孩子一样,虽然有点傻,但一般男生在一段时间内会信守承诺,克服重重困难。
但和所有靠谱承诺一样,都是会是有期限的。所以lease期限到后,双方都不认了,这时授权者又可以重新颁发lease,接收方也不相信这个lease的有效性。
比如说,一台服务器发出lease,我在30秒内部改变数据,那么其他client就可以放心的在这30s内访问数据,不用担心数据不一致问题。
30s后,其他client再收到lease就视而不见了。
PacificA算法分析
PacificA算法是微软亚洲研究院提出的一种用于日志复制系统的分布式一致算法,与其他的一致性算法相比,PacificA算法主要用于数据的一致性管理,并另辟蹊径采用其他一致性组件来进行配置一致性管理。
1. 特点
配置管理与数据管理分离:引入额外一致性组件来维护Configuration
强一致性:任意时刻读取到的数据都是最新数据
少数派Replica可用时仍可读写:每个副本都有全量数据因此只要有一个副本存在即可保证读写
去中心化的故障检测:通过节点间的契约机制来进行故障检测
2. 名词
Replica Group:互为副本的一组数据的集合,其中有一个primary,其余都是secondary
Configuration: Repica Group的元数据,如副本有哪些,谁是primary等
Configuration Manager: 配置一致性管理工具
Serial Number(SN): 代表Update的执行顺序,每次update增加1
Prepared List: Update操作的序列
Committed List: 已经提交的update序列,是Prepared List的前缀
3. 读写流程
3.1 查询(query)
该算法中,查询只能在primary上进行,primary获取自身的数据,直接返回即可
3.2 更新(update)
更新也是在primary上发起,流程如下
primary为updateRequest分配一个SN
primary发送prepare请求到各secondary,请求中包含updateRequest和SN
各secondary接收到请求,并将updateRequest和SN加入到PreparedList中,返回ACK给primary
当primary收到所有secondary的ack后,则执行该update,并将commit point移动到该commit。
返回执行成功
可以看到当一个update执行成功后,primary上对应的数据已经commit,secondary上数据也被加入到了更新队列中。在这种情况下
读操作读取的是primary上的commitList,可以拿到更新的数据。
secondary中虽然数据没有被commit,但是也被加入到了prepared List中,当主节点挂掉时仍能保证数据不丢失。
secondary上的数据不能自己commit,而必须由于primary来触发。这是为了应对由于异常情况导致update没有执行成功,secondary自主commit导致未更新成功数据被commit,且数据领先与primary。
3.3 Committed Invariant
从读写流程可以推导出committed不变式”Committed Invariant”
Secondary Committed List为Primary committed List的前缀, 即primary commit领先于secondary。
Primary Committed List为Secondary PreparedList的前缀,即Sencodary拥有primary commit的所有数据(虽然没有committed)。其实当没有在进行update操作时,Secondary的PreparedList和Primary的CommittedList是应该是一样长的。
这里想到一个异常情况,当update执行过程中,primary挂掉了,导致更新失败,secondary已经被prepare了update,这时一个secondary被选为新的primary,将其所有的update commit,那之前失败的update操作数据不就出现在了数据中,导致与预期不符?
这里与同事讨论了一下,认为pacificA算法中一个primary或secondary是一个数据实体,不应该是一个执行实体,所以当primary挂掉后,update任务不会执行失败,而是等待选出新的primary,并在其上commit这个update,保证不会出现数据不一致的情况。
4. 故障检测和恢复
pacificA通过契约(lease)的方式来进行primary和secondary间的互相检测。primary会定期(lease period)向各节点请求契约,如果某个节点没有回复,则说明该节点已经故障,primary会向Configuration Manager请求移除该secondary。 如果过了(grace period), 一个secondary没有收到primary的请求,则认为primary故障,该secondary会向Configuration请求移除Primary,并将自己设置为primary。这里要注意
当多个secondary均发现primary故障,则按照first win原则,先请求的成为primary
当出现网络分区时,primary会要求剔除secondary, secondary要求剔除primary,但由于lease period< grace period,可以保证primary先于secondary发现故障,并将secondary剔除
4.1 secondary故障
当一个scondary故障时,primary在向该secondary发送lease请求时会超时,primary向Configuration Manage发送Reconfiguration请求将该secondary从Configuration中移除
4.2 primary故障
当primary故障时, secondary在超过grace period没有收到primary的请求,就会向Configuration Manager发送Reconfiguraiont请求
要求将primary从configuration中移除并将自己选为primary。多个secondary竞争成为primary时,遵循first win原则。
当一个secondary被选为primary后 ,它会向所有的secondary发送prepare请求,要求所有的sencodary均以其pareparedList为准进行对齐,当收到所有secondary的ack后,primary将自己的commit point移动到最后,这个时候primary才能对外提供服务。
4.3 网络分区的场景
网络分区场景下,primary认为secondary故障,secondary认为primary故障,但由于lease period小于grace period,所以primary会先与secondary发现故障,并向Congfiguration Manager发送请求移除secondary
4.4 新节点加入
新节点加入时,首先会先成为secondary candidate, 然后追平primary的preparedList,然后申请成为secondary。还有一种情况是之前故障的节点恢复加入,这个时候会复用之前的preparedlist并追平secondary的preparedlist, 然后申请成为secondary。
4.5 Primary Invariant
在pacificA算法中,要保证primary不变式Primary Invariant,即
同一个时刻只有一个副本认为自己是primary
configuration Manager也认为其是primary。
从前面的故障恢复可以看到pacificA算法通过lease(契约)机制保证了这个不变式
4.6 Reconfiguration Invariant
重新配置不变式:当一个新的primary在T时刻完成reconfiguration,那么T时刻之前任意节点(包括原primary)的committedList都是新的primary当前committedList的前缀。
该不变式保证了reconfiguration过程中没有数据丢失,由于update机制保证了任意的sencondary都有所有的数据,而reconfiguration重新选primary要求新的primary commit其所有的prepareList,因此这个不变式可以得到保证。
5. 算法总结
PacificA是一个读写都满足强一致的算法,它通过三个不变式保证了读写的primary的唯一性,读写的强一致性,故障恢复的可靠性。
它把数据的一致性和配置的一致性分开,使用额外的一致性组件(Configuration Manager)维护配置的一致性,结合lease机制保证了Primary Invariant,使得在同一时刻有且仅有一个primary。
update操作时,要求所有的secondary均prepare当前update,primary commit当前update,保证了Committed Invariant, 使得读操作可以获取到最新数据,primary故障时,secondary也有全量的数据。
故障恢复机制保证了当secondary被选为primary时,其commit包含之前primary或secondary的commit,保证了Reconfiguration Invariant,使得在故障恢复后数据不会有丢失。
参考资料
https://www.yukx.com/arithmetic/article/details/2051.html
https://zhuanlan.zhihu.com/p/30270149
https://levy5307.github.io/blog/PacificA/
