初识Lucene
Lucene的简单易用性是它广受欢迎和成功的关键因素之一。Lucene是一个设计得非常优秀的软件, 因为它向用户提供了简单易用的索引和搜索API, 并屏蔽了复杂的实现过程。因此, 当开始使用Lucene时, 不必很深入地了解它的信息索引及检索的内部工作原理。而且由于Lucene API的简单直接, 你只需要学会如何使用它提供的类就可以了。在本章中, 我们通过一些现成的代码实例来为你展示如何使用Lucene进行基本的索引和搜索操作。接着简要地介绍在索引和搜索过程中所需要了解的全部核心知识点。鉴于目前也存在一些有着类似于Lucene的功能的信息检索产品(有Java语言实现的, 也有非Java的:有免费的也有商业的) , 本章的最后对它们进行了简单的比较和分析。
1.1 信息组织和访问的发展历程
为了认识我们这个复杂的世界,人类发明了各种各样的分类和组织信息的方案。在图书馆中使用的杜威十进制分类法(Dewey decimal system) 就是一种经典的层次分类方法。随着因特网的普及和数字信息量爆炸式的增长,可以让我们足不出户就可以接触到海量的信息。现在一些公司, 例如Yahoo!, 已经将在线数据的组织和分类作为其公司的业务。然而,随着数据量的日益剧增,我们迫切需要一种全新的、更动态化的方法来查找所需的信息。尽管我们可以对数据进行分门别类,但是,从成千上万的类别或子类别中查找信息已经不再是一种行之有效的方法了。
如今我们的信息来源已经不仅仅限于因特网领域中了——因为台式电脑的存储量也在飞速增长。如何在浩瀚如海的数据中迅速地定位到所需的信息,这时这个难题就凸现出来了。通过改变目录、展开或收起文件夹已不是一种访问存储文档的有效方法。此外,人们不仅仅要使用计算机最原始的计算功能,而且还使用它来存储和播放多媒体文件。这些应用都要求计算机能够快速查找到某一特定的数据片断;同时,我们还必须能够方便地查找到大量的, 例如图片、视频、音频等不同格式的富媒体文件(rich media) 。我们一边要面对如此大量的信息,一边又吝惜着宝贵的时间资源。只有找到一种更加灵活、自由和即时查询(adhoc query) 的方式才能解决这个矛盾, 而这种方式必须能够使查询尽可能地简单,并能迅速穿越严格的分类界限,准确找到我们所需要的信息。
1.2 理解Lucene
目前很多开发人员正通过不同途径去解决信息超载的问题。一部分人通过设计独创的用户接口, 一部分人通过智能代理, 而另一部分人通过开发像Lucene这样成熟的工具去解决这个问题。
在进入本章的实例代码之前, 我们先从总体上介绍一下Lucene是什么,Lucene能够做些什么, 以及Lucene的发展历程。
1.2.1 Lucene是什么
Lucene是一个高性能的、可扩展的信息检索工具库。你可以把它融入到应用程序中以增加索引和搜索功能。Lucene是一个纯Java实现的成熟、自由、开源的软件项目; 它是备受程序员欢迎的开源组织Apache Jakarta的成员项目, 基于Apache软件许可协议的授权。因此, 近几年来, Lucene已经成为最受推崇和青睐的Java开源信息检索工具库。注:在本书中将使用信息检索库术语来描述Lucene这一类型的搜索工具。人们通常认为信息检索库就是搜索引擎,其实两者是有所区别的,我们不应该混淆这两者的概念。
当你使用Lucene时很快就会发现, 它提供了一套简单却十分强大的核心API, 而使用它们时并不需要用户对全文索引和搜索的机制有很深的理解。
若要把Lucene集成到应用程序中, 你只需掌握Lucene中少数的几个类就可以了。
因为Lucene只是一个Java库,对于不同的索引和搜索内容它是通用的,相对于大量其他的搜索程序来说,这是一个很大的优势。
刚开始接触Lucene的人经常会误认为它是类似于文件搜索程序、Web爬虫或是Web 站点搜索引擎的一个现成的应用程序。
但事实上, Lucene 并不如此: Lucene 只是一个软件库或者说是工具包,它并不具备搜索应用程序的完整特征。
它只关注于文本的索引和搜索,并能够出色地完成这些工作。Lucene 用简单易用的API 隐藏了复杂的索引和搜索操作的实现过程,因此可以使应用程序专注于自身的业务领域。
所以你可以将 Lucene视为应用程序之下的一个接口层,如图1.5所示。
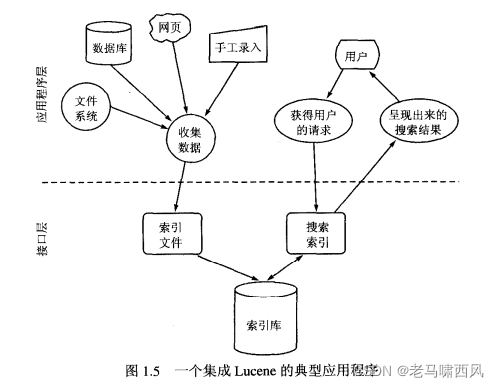
很多具备完整搜索特征的应用程序就是建立在Lucene之上的。如果你正在为抓取数据、处理文档以及搜索功能寻找一个框架或组件的话, 那么你应该考虑在Lucene Wiki的网页(http:/wki.apache.org/jakarta-lucenc/PoweredBy)中去寻找下面可供选择的方案:Search Blox, Nutch, LARM以及j Search, 当巾可能就会有你所需要的。我们将在第10章对其中的Nutch和Search Blox进行介绍。
1.2.2 Lucene能做些什么
通过使用Lucene, 你可以为应用程序添加索引和搜索功能(这些功能将在1.3节中介绍) 。
Lucene能够对任意可转换为文本格式的数据进行索引和搜索。
如图1.5所示。Lucene并不关心数据的来源、格式, 甚至文件使用什么自然语言都没有关系, 只要可以把它转换成文本格式。也就是说你可以用Lucene来索引、搜索存放在文件中的诸如以下的数据:远程Web服务器上的网页, 本地文件系统中的文档、简单的文本文件、WORD文档、HTML或者PDF格式的文件, 或者其他一切能够从中提取文本信息的数据格式。
同样地, 你还可以利用Lucene来索引存储在数据库中的数据, 从而使应用能够为用户提供其他很多数据库所不具备的全文索引搜索的功能。而一旦应用程序集成了Lucene,用户就可以进行如+George+Rice-eat-pudding, Apple-pie+Tiger, animal:monkey ANDfood:banana等有着复杂查询条件的搜索。
利用Lucene,你可以为诸如电子邮件消息、归档的邮件列表、即时聊天消息、Wiki(一种提供共同创作环境的网站, 每人都可以任意修改网站上的页面数据)页面……很多类型的数据建立索引,并进行搜索工作。
1.3 索引和搜索
1.3.1 什么是索引,为什么如此重要?
假如想要从大量文件中搜索出包含某个单词或短语的文件。
你会怎样开始去编写一个程序来完成这个功能呢?
一个比较初级的方法就是顺序扫描每个文件,查找其中有没有包含需要搜索的单词或短语。不过这个方法有很多缺陷,最显著的就是它不适用于规模非常大的文件或者文件数量非常多的应用环境。而这正是索引所适用的领域。为了快速搜索大量的文本文件,首先必须为文件建立索引,就像是为一本书建立目录,然后把文本转换成你能够快速搜索到的格式,而不是使用那种慢速顺序扫描的处理方法。
这个转换过程就叫索引操作(indexing) , 它的输出就称为索引文件(index) 。
你可以把索引想像成一种数据结构,这种结构允许对存储在其中的单词进行快速随机存取。这种设计思想类似于书后的索引,这种索引可以让你快速定位需要关注的某个主题的页码。在Lucene中, 索引是一个经过精心设计的数据结构, 通常作为一组索引文件存储在文件系统中。我们在附录B中详细介绍了索引文件结构, 在此只需把Lucene索引简单地想像成一种用来快速查找单词的工具。
1.3.2 什么是搜索
搜索是一个在索引中查找关键字的过程,这个过程的目的是为了找到这些关键字在哪些地方出现过。
搜索的质量通常由查确率(precise) 和查全率(recall) 来衡量。
查全率可以衡量这个搜索系统查找到相关文档的能力,而查确率则用来衡量搜索系统过滤非相关文档的能力。当然,也需要考虑很多其他的因素。我们已经提到过快速查找大量文本文件的速度和能力问题。例如:对单一项的查询、多个项的查询、短语查询、通配符、结果评分、排序等功能的支持以及友好的查询输入语法,对于一个搜索系统而言都是很重要的。Lucene强大的软件库提供了大量的搜索特性, 由于数量众多, 我们必须要用第3、5和6三章的篇幅来为你讲解Lucene的搜索功能。
1.4 Lucene实践:一个应用实例
我们来看一下Lucene的实际应用。
为了说明这个问题, 我们需要先回忆一下在1.3.1节描述过的关于索引和搜索文件的内容。
此外,这里假定你要索引并搜索存储在一个目录树中而非单个目录中的文件。
创建索引
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Paths;
/**
* @author binbin.hou
* @date 2018/11/15 11:24
*/
public class Indexer {
public static int createIndex(String dataDir, String indexDir) throws Exception {
IndexWriter indexerWriter = initIndexWriter(indexDir);
int numIndexed = doIndex(indexerWriter, dataDir);
return numIndexed;
}
/**
* 构造方法 实例化IndexWriter
*
* @param indexDir 索引文件夹
* @throws IOException 异常
*/
public static IndexWriter initIndexWriter(String indexDir) throws IOException {
//得到索引所在目录的路径
Directory directory = FSDirectory.open(Paths.get(indexDir));
// 标准分词器
Analyzer analyzer = new StandardAnalyzer();
//保存用于创建IndexWriter的所有配置。
IndexWriterConfig iwConfig = new IndexWriterConfig(analyzer);
//实例化IndexWriter
return new IndexWriter(directory, iwConfig);
}
/**
* 执行索引处理
* @param indexWriter 实现
* @param dataDir 文件夹
* @return 结果
* @throws Exception 异常
*/
public static int doIndex(IndexWriter indexWriter, String dataDir) throws Exception {
File[] files = new File(dataDir).listFiles();
for (File file : files) {
//索引指定文件
indexFile(indexWriter, file);
}
//返回索引了多少个文件
int number = indexWriter.numDocs();
// 提交并且关闭
indexWriter.commit();
indexWriter.close();
return number;
}
/**
* 索引指定文件
*
* @param f
*/
private static void indexFile(IndexWriter indexWriter, File f) throws Exception {
//输出索引文件的路径
System.out.println("索引文件:" + f.getCanonicalPath());
//获取文档,文档里再设置每个字段
Document doc = getDocument(f);
//开始写入,就是把文档写进了索引文件里去了;
indexWriter.addDocument(doc);
}
/**
* 获取文档,文档里再设置每个字段
*
* @param f 文件
* @return document 文档
*/
private static Document getDocument(File f) throws Exception {
Document doc = new Document();
//把设置好的索引加到Document里,以便在确定被索引文档
doc.add(new TextField("contents", new FileReader(f)));
//Field.Store.YES:把文件名存索引文件里,为NO就说明不需要加到索引文件里去
doc.add(new TextField("fileName", f.getName(), Field.Store.YES));
//把完整路径存在索引文件里
doc.add(new TextField("fullPath", f.getCanonicalPath(), Field.Store.YES));
return doc;
}
public static void main(String[] args) throws Exception {
//索引指定的文档路径
String indexDir = "D:\\gitee\\lucene-in-action\\index";
//被索引数据的路径
String dataDir = "D:\\gitee\\lucene-in-action\\data";
int numIndexed = createIndex(dataDir, indexDir);
System.out.println(numIndexed);
}
}
根据针对 dataDir 中的文件,创建对应的索引信息到 indexDir 文件夹下。
查询索引
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.nio.file.Paths;
/**
* @author binbin.hou
* @date 2018/11/15 11:35
*/
public class Searcher {
public static void search(String indexDir, String q) throws Exception {
// 得到读取索引文件的路径
Directory dir = FSDirectory.open(Paths.get(indexDir));
// 通过dir得到的路径下的所有的文件
IndexReader reader = DirectoryReader.open(dir);
// 建立索引查询器
IndexSearcher is = new IndexSearcher(reader);
// 实例化分析器
Analyzer analyzer = new StandardAnalyzer();
// 建立查询解析器
/**
* 第一个参数是要查询的字段; 第二个参数是分析器Analyzer
*/
QueryParser parser = new QueryParser("contents", analyzer);
// 根据传进来的p查找
Query query = parser.parse(q);
// 计算索引开始时间
long start = System.currentTimeMillis();
// 开始查询
/**
* 第一个参数是通过传过来的参数来查找得到的query; 第二个参数是要出查询的行数
*/
TopDocs hits = is.search(query, 10);
// 计算索引结束时间
long end = System.currentTimeMillis();
System.out.println("匹配 " + q + " ,总共花费" + (end - start) + "毫秒" + "查询到" + hits.totalHits + "个记录");
// 遍历hits.scoreDocs,得到scoreDoc
/**
* ScoreDoc:得分文档,即得到文档 scoreDocs:代表的是topDocs这个文档数组
*
* @throws Exception
*/
for (ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = is.doc(scoreDoc.doc);
System.out.println(doc.get("fullPath"));
}
// 关闭reader
reader.close();
}
public static void main(String[] args) throws Exception {
//索引指定的文档路径
String indexDir = "D:\\gitee\\lucene-in-action\\index";
//我们要搜索的内容
String q = "lucene";
search(indexDir, q);
}
}
输出的结果如下:
匹配 lucene ,总共花费16毫秒查询到2个记录
D:\gitee\lucene-in-action\data\en.txt
D:\gitee\lucene-in-action\data\zh.txt
参考资料
《Lucene in Action II》
