1.5 理解索引过程的核心类
正如你在 Indexer 类中所看到的,执行最简单的索引过程需要用到下列几个类:
-
IndexWriter
-
Directory
-
Analyzer
-
Document
-
Field
接下来是这些类的一个简要的讲解,通过这些讲解可以使你对这些类有一个初步的印象。
并且我们将会在整本书中频繁地使用这些类。
1.5.1 IndexWriter
IndexWriter 是索引过程的核心组件。这个类用于创建一个新的索引并且把文档加到已有的索引中去。
可以把 IndexWriter 当作这样的一个对象:它可以为你提供对索引的写入操作,但不能用于读取或搜索索引。
尽管它的名字是IndexWriter, 但它并不是惟一能够修改索引的类;2.2节将会向你介绍怎样使用 Lucene API 修改一个索引。
1.5.2 Directory
Directory 类描述了 Lucene 索引存放的位置。它是一个抽象类,具体的子类(Lucene中包含了它的两个子类)提供特定的存储索引的方法。
在前面的 Indexer 例中,我们用一个真实的文件系统目录的路径,来生成一个 Directory 实例,并把这个实例传递给IndexWriter 的构造函数。
然后, IndexWriter 使用了Directory 的一个具体的实现——FSDirectory, 在这个文件系统的一个目录中创建索引文件。
在应用程序中,大部分情况下是将 Lucene 索引存储在磁盘里。
为了做到这一点,就像我们在 Indexer 程序中做的那样,利用FSDirectory(一个Directory 子类就能够为 Lucene创建和维护文件系统中的一组真实文件。
Directory 的另外一个实现类是 RAMDirectory。虽然 RAMDirectory 和 FSDirectory具有同样的接口,但是 RAMDirectory 把数据保存在内存中。所以,这个对于小体积的索引而言非常有用,因为这些索引能够被完整地装载到内存中并且随着应用程序中止而被销毁。由于所有的数据都存储在高速存储器,而不是在相对较的硬盘中,因此RAMDirectory 适用于需要快速存取索引的应用环境,不管是用于索引操作还是搜索操作。
例如, Lucene 的开发者在所有的单元测试中都广泛使了 RAMDirectory:当一个测试运行时,他们就会创建或搜索一个存放在高速存取存储器中的索引;而当一个测试完结时,这个索引就会被自动销毁,不在硬盘中留任何痕迹。
当然,如果 Lucene 是运行在将文件缓存到内存的操作系统的情况下, RAMDirectory 和 FSDirectoty 在性能上的差异就不那么明显了。
在本书中,将看到这两个类的一些具体的应用。
1.5.3 Analyzer
在文本被索引之前,需要经过分析器(Analyzer)的处理。
应用程序在 IndexWriter 的构造函数中指定程序所需要使用的分析器,它负责从将被索引的文本文件中提取语汇单元(tokens), 并除剩下的无用信息。
如果将要被索引的文档不是纯文本文档,那么就需要先将其转换为文本文档,这点将会在2.1节巾有进一步的讲述。
此外,在第7章中会为你介绍怎样从多媒体格式文件中分离出文本。
Analyzer 是一个抽象类, Lucene 中提供了它的几个具体实现类。其中一些分析器用于移除停止词 (stop words)(指一些很常用、但不能用来帮助区分文档的词,比如a、an、 the、in、on 等等);还有一些分析器用于把语汇单元转换为小写形式,这样做可以使搜索忽略大小写的区别;除此以外,还有很多类型。
Analyzer 是 Lucene 很重要的一部分,并且它的用途远远不只是对输入进行过滤。
对于一个要在应用程序中集成 Lucene 的开发者来说,选择什么样的分析器是应用程序设计中非常关键的一步。关于这一部分内容,我们将在第4章详细介绍。
1.5.4 Document
一个文档代表一些域(Field) 的集合。
你可以把Document对象当成一个虚拟的文档——比如一个web页面、一个E-mail消息或者一个文本文件等——然后你可以从中取回大量的数据。
一个文档的域代表文档或者和文档相关的一些元数据。
文档数据的数据源(比如数据库记录、WORD文档、书的一个章节等) 对于Lucene来说都是无关紧要的。
像作者、标题、主题、修改日期等元数据都作为文档不同的域被单独存储并索引。注:本书中所涉及的Document是指Lucene中的一个类, 是承载数据的实体。它是一个抽象的概念, 后面章节中用Document代表一个被索引的基本单元, 比如一个txt文件、一个网页、论坛的一个讨论记录、一件艺术品等。有时我们会将Document说成文档, 但你应该知道这里所说的文档与通常所说的WORD、PDF等文档之间是有所区别的。
Lucene只能处理文本。因为Lucene的内核本身只处理java.lang.String和java.io.Reader两种对象。虽然各种类型的文档都能够被索引和搜索, 但非文本文件的处理方式并不像处理那些能够转换为纯文本的String或者Reader对象那样简单。读者可以在第7章学到如何处理非文本文档。
在Indexer中, 我们专注的是文本文件的索引操作。所以, 我们为每一个检索到的文本文件创建一个Document实例, 并往该实例中添加组成的它的域(Field将在下一节介绍) , 最后把这个Document对象添加到索引中去, 这样就完成了索引文档的操作。
ps: 类似于数据库中的一行数据。
1.5.5 Field
ps: 类似于数据库中的每一列。
索引中的每一个Document对象都包含一个或多个不同命名的域(Field) ,这些域包含于Field类中。
每一个域都对应于一段数据,这些数据在搜索过程中可能会被查询或者在索引中被检索。
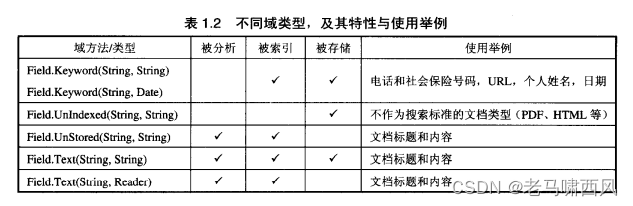
Lucene 提供了以下四种不同类型的域:
Keyword 域——不需要被分析, 但是会被逐字地被索引并存储。
该类型适用于原始值,也就是需要被全部保留的域,如URL、文件系统路径、日期、个人姓名、社会保险号码、电话号码等。
例如, 在Indexer(列表1.1) 中, 我们将文件系统路径作为一个Keyword域使用。
UnIndexed 域——既不需要被分析也不进行索引, 但是该值同样被存储在索引文件中。
该类型适合于需要和搜索结果一起被显示出来,但用户不会将它的值直接用于搜索的情形(如URL或者数据库的主键等) 。
由于这种域的原始值被存储在索引中,若索引体积太大以至于成为一个突出的问题时,该类型不适合存储具有较大文本的域。
UnStored域——与UnIndexed类型域相反, 该域类型需要被分析并索引, 但是不会存储在索引文件中。
该类型适用于索引那些不需要以其原始形式进行检索的大数据量文本,比如网页的正文,或者其他类型的文本文档等。
Text域——需要被分析且索引。
这意味着该类型的域能够被搜索,但是要注意域的大小。
如果被索引的数据是一个字符串,它将会被储存起来;但是如果数据(就像我们的例子Indexer那样) 来自Reader对象, 那么它就不会被储存在索引文件中。
该类型常常会导致混乱,所以使用Text类型域时要特别小心。
每个域都由域名(name) 和域值(value) 对所组成。选用哪一种类型的域取决于用户自己想如何使用该域及其值。
严格地说, Lucene中只含有一种类型的域:各个Field对象是通过它们各自的特征进行区分的。
有的Field对象经过分析,而有的则没有;有的Field对象被编入索引,而有的被逐字存储等等。
表1.2提供了一个不同域特性的总结,并通过给出通用的例子,向你说明域是怎样建立的。
要注意所有的域都能用域名称(name) 及其值(value) 的两个字符串(String) 来创建。
以下直接使用域名和域值进行叙述。
此外, Date和String对象都能作为参数传给Keyword域,而Text域除了可以接受String对象外,还能接受Reader对象作为其参数。
在以上的各个函数中, 域值在编入索引之前都被转换成了Reader对象; 这些附加的方法为开发者提供了更友好的API。
注; 注意 Field.Text(String, String) 和 Field.Text String, Reader) 之间的区别。
若使用字符串(String) 变量,Lucene就会存储该域的值,然而如果使用Reader变量则不存储。
如果要索引一个字符串, 但是不存储它,那么就使用 Field.UnStored(String, String)。
最后, UnStored 和 Text 域能被用于创建项向量 (term vector, 一个高级主题,将在5.7节中介绍)。
读者可以通过 Field.UnStored(String, String, true)、Field.Text(String, String,true)或者 Field.Text(String, Reader,true)来为指定的UnStored 和 Text 域创建项向量。当使用 Lucene 来进行索引操作时,会经常用到以上这些的类。
为了实现基本的搜索功能,你需要熟悉同样小巧精练的 Lucene搜索类集合。
1.6 理解搜索过程的核心类
Lucene提供的基本搜索接口像索引接口一样简单易懂。仅需要少数一些类来执行基本搜索操作:
-
Index Searcher
-
Term
-
Query
-
TermQuery
-
Hits
下文提供了这些类的简要介绍。在进入到更多高级主题之前,本书将会在后面的章节中对这些类进行详细阐述。
1.6.1 index Searcher
Index Searcher类用于搜索Index Writer类所创建的索引:这个类是连接索引的重要手段,并提供了一些search方法。
可以将Index Searcher类看作一个以只读方式打开索引的类。
它提供了许多search方法, 其中的一些方法在它的抽象父类Searcher中实现;
最简单的search方法是将单个Query对象作为函数的一个参数, 并返回一个Hits对象。
TopDocs hits = is.search(query, 10);
我们将在第3章对Index Searcher进行详细介绍, 并在第5章和第6章给出更深层次的内容。
1.6.2 Term
项(Term) 是用于搜索的一个基本单元。如同域对象一样, 它包括了一对字符串元素:与域中的域名(name) 和域值(value)相对应。
注意,对 Term 刘象的处理实际上已经被包含在编制索引的过程中。
但是,它们由 Lucene 在 API 内部创建,所以在编制索引时一般不需要考虑它们。
在搜索过程中,可以构造 Term 对象与TermQuery 对象一起使用:
Hits hits = is.search(q);
以上代码命令 Lucene 查找在名为“contents”的域中包含单词“lucene”的所有文档。
因为 TermQuery 是从抽象父类 Query 继承而来,所以可以在声明的左边使用 Query 类型。
1.6.3 Query
Lucene 含有许多具体的查询(Query)子类。到现在为止,我们已经谈到的只是 Lucene基本的 Query 子类: TermQuery。
其他的 Query 子类有 BooleanQuery、PhraseQuery、PrefixOvery. PhrasepretixOnery. RangeOnery. FilteredOnery和Spananery等。
所有这些查询类型都将包含在第3章内容中。Query 是它们共同的抽象父类,它包含了一些非常实用的方法,其中最有趣的一个当属 setBoost(float), 该方法将在3.5.9节详细描述。
1.6.4 Termauery
TermQucry 是 Luccnc 提供的最基本的查询类型,也是简单查询类型之一。
它用来匹配在指定域中包含了特定项的文档,就像读者在上文中看到的一样。
1.6.5 Hits
Hits 类是一个存放有序搜索结果指针的简单容器,在这里搜索结果是指匹配一个己知查询的一系列文档。
出于性能上的考虑, Hits 实例不会一次性地从索引中装载所有匹配某个查询的文档,每次只会装载它们中的一小部分。
第3章将会更详细地描述这个类。
ps: 这里的 lucene in action II 没有提及版本,发现和 v7.2.1 差异较大。
参考资料
《Lucene in Action II》
