2.7 控制索引过程
在对中小型文档集合进行索引的情况下,默认配置的Lucene能够很好地工作。
但是,如果应用程序要处理很大的索引, 你可能想在Lucene的索引过程中添加一些控制,以保证应用程序获得最佳的索引性能。
例如,你可能正在索引几百万个文档,并想加速这一过程,使花费的时间从几个小时缩短到几分钟。而你的计算机有空闲的内存(RAM) ,所以你有必要知道如何使Lucene能更好地利用空闲的内存空间。
Lucene中有几个参数允许你在索引期间控制Lucene的性能和资源的使用。
2.7.1 调整索引性能
在一个典型的索引应用中,程序性能的瓶颈存在于将索引文件写入磁盘的过程中。
如果你曾经分析过索引应用程序,应该会发现运行该程序大部分的时间都耗费在操作索引文件的程序段上。
因此,我们有必要使Lucene索引新对象和修改索引文件时变得更智能。
如下图所示,当新的 Document 对象添加到 lucene 时,最开始是被写入到内存中,而不是直接写入磁盘。
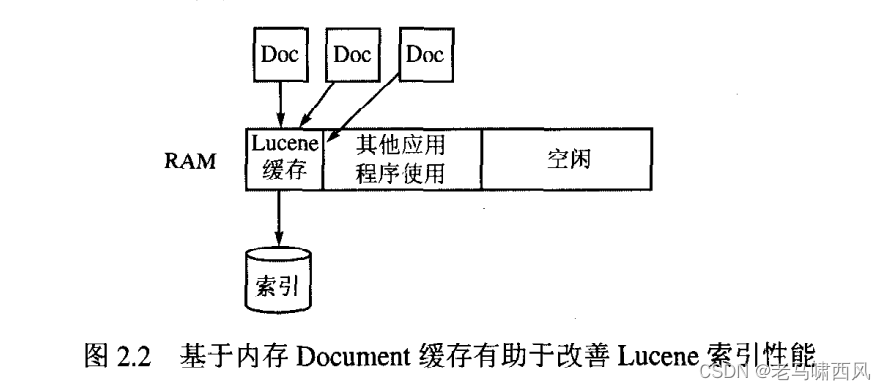
这么做的目的,是为了提升性能。
当然,lucene 暴露了一些配置,让我们可以对这个过程进行调整。

Index Writer的 mergeFactor 参数在将Document对象写入磁盘之前,让你能控制在内存中存储Document对象的数量以及合并多个索引段的频率(索引段在附录B中介绍) 。
在将它们作为单个段(segments) 写入磁盘之前, Lucene在内存中默认存储10个Document对象。 mergeFactor 的值为10也意味着磁盘上的段数达到10的乘方时, Lucene会将这些段合并为一个段。
例如, 如果你将 mergeFactor 设置为10, 每当有10个Document对象添加到索引中时, Lucene就会在磁盘上创建一个新的段。
当添加第10个大小为10个文档对象的段时,所有的这10个段会合并为大小为100的一个段。
又当添加了10个这样大小为100的段之后, 它们将被合并为包含1000个Document对象的一个段, 依次类推。
因此, 任意时刻索引中的段数都不会出现大于9的情况,并且每个合并后的段的大小均为10的乘方。
这一规则有一个小小的例外,与Index Writer另外一个实例参数maxMergeDocs参数有关:当合并多个段时,Lucene要确保各个段中所包含的Document对象的个数不超过maxMergeDocs的大小。
例如,假定maxMergeDocs的值设置为1000。当添加第10000个Document对象时, Lucene不会将多个段合并成大小为10000的一段, 而是会创建大小为1000的第10个段, 并且在添加每1000个Document对象之后, 仍将新段的大小保持为1000。
现在你已经明白了参数 mergeFactor 和maxMergeDocs是怎样工作的,也能推断出使用较大的 mergeFactor 参数会让Lucene使用更多的RAM; 而另一方面, 这样也使磁盘写入数据的频率降低,因此加速了索引过程。
较小的 mergeFactor 参数使内存的使用减少,并使索引更新的频率升高。这样做令数据的实时性更强,但是也降低了索引过程的速度。
类似地, 较大的maxMergeDocs参数更适用于批量索引的情况, 较小的maxMergeDocs参数更适用于交互性较强的索引。
需要小心的是, 因为较大的 mergeFactor 参数意味着较低频率的合并,会导致索引中的索引文件数增多。
虽然这并不影响索引的性能,但是它会降低搜索速度, 因为Lucene需要打开、读取和处理更多的索引文件。
minMergeDocs是Index Writer另一个影响索引性能的变量。在Document对象被合并为一段之前, minMergeDocs的值控制着缓存的Document对象个数。
minMergeDocs参数让你能够使用更多的内存空间来换取更快的索引。
与 mergeFactor 不同的是,该参数并不影响磁盘上的索引段大小。
范例:Index Tuning Demo
为了对不同的 mergeFactor 、maxMergeDocs和minMergeDocs参数值对索引速度的影响有更好的理解, 请参看程序2.4中的Index Tuning Demo类。
该类有四个命令行参数:添加到索引中的Document对象总数、 mergeFactor 的值、maxMergeDocs的值,以及minMergeDocs的值。
所有的四个参数必须被指定好, 必须为整型, 必须按照以上顺序输入。
为了使代码更简洁,这里并没有对非法使用进行检查。
ps: V7.2.1 发现这些配置都没有,应该是被 MergePolicy 隐藏起来了。不过其核思想还是不会变化的。
配置的影响
从以上运行情况可以看到,当操作系统为运行 JVM (Java 虚拟机)提供更多内存时,增大 mergeFactor 和minMergeDocs 的值可以提高索引过程的速度。
请注意,若将minMergeDacs设为10000会导致程序抛出 OutOfMemoryError 的异常:如果为mergeFactor 赋一个太大的值,也可能会导致这种异常。
注:增大 mergeFactor和 minMergeDocs 的值只会在一定程度上提高索引的速度。值越大,占用的内存也越多,如果设定的值过大有可能会导致索引进程耗尽所有内存。记住 IndexTuningDemo(就像这个词本意已经表示出来的那样)仅仅是mergeFactor, maxMergeDocs 和 minMergeDocs 的一个使用范例。在这个类中,只是向索引添加由单个词构成的城的 Documents 对象,因而我们才可以为mergeFactor 设置一个非常大的值。
在实际应用中, 使用 Lucenc 的应用程序处理的索引往往是这样的:索引的文档含有多个域,并且每个域包含大量的文本。这些应用程序不能像这个例子一样,将 mergeFactor和 minMergeDocs 的值设得过大,除非机器拥有很大的内存空间——因为在索引时,内存容量的大小正是限制 mergeFactor 和 minMergeDocs 值大小的主要因素。如果你要运行 IndexIuningDemo,一定要谨记操作系统和文件系统的高速缓存对程序运行性能的影响。确保缓存已经可以使用并且每个配置都已经运行了几遍,特别是在其他空闲的机器上运行这样的应用程序时更应如此。
ps:
降低频次,可以提升速度,但是降低了实时性。
内存中存放的东西越多,速度相较于磁盘会更快,但是磁盘本身是有限的。
2.7.2 内存中的索引
RAMDirectory 在前面的章节中, 我们提到Lucene把新加的文档先保存在内存中后才把它们存到磁盘上, 并通过这种方法来进行内部缓冲。
如果你正在使用FS Directory(Directory类的一个基于文件的具体实现),以上的缓存操作将是自动、透明地完成的。
但是,你可能会希望对索引过程、内存使用情况和从内存缓冲区到磁盘传送文件的频率某方面进行更多的控制。此时可以把 RAMDirectory 作为一个内存缓冲器使用。 RAMDirectory 和FS Directory的对比 RAMDirectory 在内存中所进行的操作比FS Directory在磁盘上所完成的工作要快得多。
程序2.5中的代码创建了两个索引:一个基于FS Directory, 另一个则基于 RAMDirectory 除此之外, 其他部分都是相同的——每个索引都包含了1000个具有相同内容文档的对象。
测试代码
这里把 Directory 调整为基于 RAM 的,其他保持不变:
public void ramConfigTest() throws IOException {
Directory directory = new RAMDirectory();
Analyzer standardAnalyzer = new StandardAnalyzer();
IndexWriterConfig iwConfig = new IndexWriterConfig(standardAnalyzer);
IndexWriter indexWriter = new IndexWriter(directory, iwConfig);
// 写入
List<String> nameList = Arrays.asList("张三", "李四");
for(String name : nameList) {
Field contentField = new TextField("sender",name, Field.Store.YES);
Field idField = new StringField("id",name, Field.Store.YES);
Document document = new Document();
document.add(contentField);
document.add(idField);
indexWriter.addDocument(document);
}
indexWriter.commit();
indexWriter.close();
// 读取
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(reader);
Term term = new Term("id","张三");
Query termQuery = new TermQuery(term);
TopDocs topDocs = indexSearcher.search(termQuery,10);
// 展示
for(ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document doc = indexSearcher.doc(scoreDoc.doc);
System.out.println(doc);
}
}
并行索引多个索引文件
把RAM Directory作为一个缓冲器的思想还可以有更深入的应用, 如图2.3所示。你可以创建一个多线程的索引程序, 这个程序并行地使用多个基于RAM Directory的索引,每个线程中都有一个这样的索引,并利用 IndexWriter 的 addIndexs(Directory[]) 方法把这些索引合并成一个单一的索引文件存储到磁盘上。
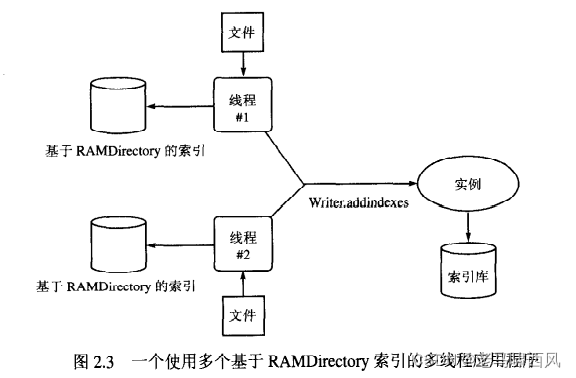
2.8 优化索引
优化索引其实就是将多个索引文件合并成单个文件的过程,它是为了减少索引文件的数量,并且能在搜索时减少读取索引文件的时间而进行的操作。我们曾在2.7小节中讲过, 当我们要把新的Document对象添加到索引中时, Lucene先把这些对象缓存到内存中,然后将其合并成一个段,最后再把这个段写入磁盘,同时也可以根据预先的要求把它和磁盘上原有的段合并。虽然可以通过使用merge Factor、max Merge Docs和min Merge Docs参数控制Lucene对段的合并过程,不过当索引操作完成后, Lucene的索引里可能还是会有若干个不同的段。
虽然应用程序可以很好地对一个包含多个段(segment) 的索引进行搜索, 但是Lucene的API可以让用户进一步优化这个索引,从而减少Lucene所消耗的资源, 并能进一步改善应用程序的搜索性能。对索引进行优化会把所有段合并成单个段。
你可以通过调用IndexWriter的optimize() 方法(或许你已经注意到了前面程序中已经调用过这个方法, 所以我们在此不再将其单独列出)优化个索引。
索引的优化过程涉及很多磁盘的输入输出操作,所以要恰当地进行索引的优化操作。
ps: 这些在 V7.2.1 版本应该是没有暴露的。
必须强调的是,对索引优化只会提高搜索操作的速度,它对索引过程的速度没有影响。
向一个未优化的索引中加入新的 Document 对象和向一个已优化的索引中加入Document 对象的速度是一样的。
优化过的索引能提高搜索的速度是由于 Lucene 只需要打开并运行较少的文件,而未优化过的索引则相反。
已优化的索引比未优化的索引包含的索引文件要少得多。
优化所需的磁盘空间
值得指出的是, Lucene 对一个索引的优化操作是通过把已存在的段合并成一个全新的段来完成的,这些已存在段的内容最终会在新的段中表示出来。
因而在进行优化时,使用的磁盘空间会有明显的增加。
在新段创建完成时, Luccnc 删除并移除这些旧段。
因此,在旧的段还没有被删除之前,索引占用的磁盘空问会变成原来的两倍,因为此时新段和旧段都会存储在索引中。
在优化完成后,所占用的磁盘空间会降回到优化前的状态。请记住,索引优化的对象可以是多文件索引或复合索引。
为什么需要优化?
尽管未经优化的索引在大多数应用程序中都能够很好地进行工作,但在那些处理大批量索引的应用程序中,使用优化过的索引会给应用程序带来更多的好处。
特别是在搜索操作需要长时间打开多个索引文件的情况下,更能体现出索引被优化后的优势,因为使用优化过的索引可以减少需要打开的文件描述符的个数。
假设你正在开发一个服务器端的应用程序,随着时间的推移,当用户需要向他们各自的索引中添加新的文档时,使用未经过优化的索引会导致这一更新过程变得十分缓慢。这是因为随着新的文档不断地被加入到各个索引中,这些索引中的段的数量也会随之增加。
这就意味着如果要对这些未经优化的索引进行搜索, Lucene必须持续长时间对多个打开的索引文件进行管理,从而有可能最终达到操作系统所设定的打开文件数量的上限。为了解决这个问题,我们可以开发一个能定期对索引进行优化的系统。该系统的工作机制可以类似于一个独立的应用程序,它是通过周期性地遍历用户的索引和运行以下代码来实现的:
当然,如果这段代码是在独立的应用程序中运行的,就必须注意索引文件并发性的修改所带来的问题。在某一时刻,一个索引只能被操作系统的一个进程所修改。换句话说, 在同一时间里, 只允许一个进程使用Index Writer对象打开某个索引。正如将在本章后续部分中看到的那样, Lucene利用基于文件的锁机制来防止这种由索引的并发修改所引发的问题。
优化的时机
虽然在索引过程中的任意时刻、任意进程都能对索引文件进行优化,而且这样做也不会损坏索引文件或使其不能被搜索,但是在索引过程中对索引进行优化的做法并不值得提倡。优化操作的最佳时机是在索引过程结束之后,且当你确认在此后的一段时间内不会对索引文件进行更改的时候。在索引过程中进行优化只会使优化操作耗费更多的时间。
注:与大多数人所想的相反,事实上对索引进行优化并不能提高索引速度。
它只能通过尽可能地减少必须打开、处理和进行搜索的索引文件,从而提高搜索的速度。
我们只要在索引过程结束,并确认索引文件在将来一段时间内不需要被更改时进行优化即可。
2.9 并发性、线程安全性以及锁机制
这部分内容将介绍三个紧密联系的主题:索引文件的并发访问、Index Reader和Index Writer的线程安全性,以及Lucene用于避免索引被破坏而使用的锁机制。
通常,Lucene的初学者们对这几个主题都存在一定的误解。
而准确地理解这些内容是十分重要的,因为,当索引应用程序同时服务于大量不同的用户时,或为了满足一些突发性的请求、而需要通过对某些操作进行并行处理时,这些内容会帮助你消除在构建应用程序过程中所遇到的疑问。
Lucene 提供了一些修改索引的方法,例如索引新文档、更新文档和删除文档:在执行这些操作时,为了避免对索引文件造成损坏,需要遵循一些特定的规则。这类问题通常会在 web应用程序中突显出来。因为 web应用程序是同时为多个请求而服务的。
Lucene的并发性规则虽然比较简单,但我们必须严格遵守:
1) 任意数量的只读操作都可以同时执行。例如,多个线程或进程可以并行地对同一个索引进行搜索。
2) 在索引正在被修改时,我们也可以同时执行任意数量的只读操作、例如,当某个索引文件正在被优化,或正在对索引执行文档的添加、更新或删除操作时,用户仍然可以对这个索引进行搜索。
3) 在某一时刻,只允许执行一个修改索引的操作。也就是说,在同一时间,一个索引文件只能被一个Index Writer 或 IndexReader 对象打开。
基于以上的并发性规则,我们可以构造一些关于并发性的更全面的例子,如表2.2中所示。
表中说明了是否允许我们对一个索引文件进行各种并发性的操作。

线程安全性
一个索引文件只能被一个Index Writer 或 IndexReader 对象打开。
但是 IndexWriter/IndexReader 本身都是线程安全的。
应用程序不需要进行额外的同步处理。尽管Index Reader和Index Writer这两个类都是线程安全的, 使用Lucene的应用程序还是必须确保这两个类的对象对索引的修改操作不能重叠。也就是说, 在使用Index Writer对象将新文档被添加至索引中之前, 必须关闭所有已经完成在同一个索引上, 进行删除操作的Index Reader实例。同样地, 在Index Reader对象对索引中的文档进行删除和更新之前, 必须关闭此前已经打开该索引的Index Writer实例。
表2.3是一个关于并发操作的矩阵,它向我们展示了一些具体操作是否能并发地执行。
该表假定应用程序只使用了一个Index Writer或Index Reader实例。
请注意,在此我们并没有将对索引的更新视为一个单独的操作列出,因为它实际上可以被看成是在删除操作后再进行一个添加操作。

这个矩阵可以归纳为:
1) IndexReader 对象在从索引中删除一个文档时, Index Writer 对象不能向其中添加文档。
2)Index Writer 对象在对索引进行优化时, IndexReader 对象不能从其中删除文档。
3)Index Writer 对象在对索引进行合并时, IndexReader 对象也不能从其中删除文档。
从上面的矩阵及其归纳中,我们可以得到这样一个使用模式:当Index Writer对象在对索引进行修改操作时, IndexReader 对象不能对索引进行修改。这个操作模式是对称的:当 IndexReader 对象正在对索引进行修改操作时,IndexWriter 对象同样也不能对索引进行修改。
这里读者可以感到, Lucene 的并发性规则和社会中的那些良好的习惯以及合理的法规具有相通之处。我们不一定非得严格地遵守这些规则,但是如果违反这些规则将会造成相应的后果。在现实生活中,违反法律法规也许得银铛入狱。
在使用 Lucene 时,违背这些规则,则会损坏你的索引文件。Lucene 使用者可能会对并发性有错误的理解甚至误用,但 Lucene 的创造者们对此早已有所预料,因此他们通过锁机制尽可能地避免应用程序对索引造成意外的损坏。
本书将在2.9.3节中对 Lucene 索引的锁机制进行进一步的介绍。
2.9.3 索引锁机制
在Lucene 中,锁机制是与并发性相关的一个主题。
在同一时刻只允许执行单一进程的所有代码段中, Lucene 都创建了基于文件的锁,以此来避免误用 Lucene 的API造成对索引的损坏。
各个索引都有其自身的锁文件集:在默认的情况下,所有的锁文件都会被创建在计算机的临时目录中,这个目录由 Java 的 java.io.tmpdir 中的系统属性所指定。如果在索引文档时,观察一下那个临时目录,就可以看到 Lucene 的 write.lock 文件;在段 (segment)进行合并时,还可以看到 commit.lock 文件。
你可以通过设定org.apache.lucene.lockDir 中的系统属性,使锁文件存放的目录改至指定的位置。
这个系统属性可以通过使用 Java API 在程序中进行设定,还可以通过命令行进行设定,如:-Dorg.apache.lucene.lockDir=/path/to/lock/dir。
若有多台计算机需要访问存储在共享磁盘中的同一个索引,则应该在程序中显式地设定锁目录,这样位于不同计算机上的应用程序才能访问到彼此的锁文件。
根据已知的锁文件以及网络文件系统(NFS)出现的问题,锁目录应该选择放在一个不依赖于网络的文件系统卷上。
以下就是上面提到的两个锁文件:
$ ls-1 /tmp/lucene*.lock
lucene-de61b2c77401967646cf8916982a09a0-write.lock
lucene-de61b2c77401967646cf8916982a09a0-commit.lock
write.lock文件用于阻止进程试图并发地修改一个索引。
更精确地说,Index Writer对象在实例化时获得write.lock文件, 直到Index Writer对象关闭之后才释放。
当Index Reader对象在删除、恢复删除文档或设定域规范时,也需要获得这个文件。
因此,write.lock会在对索引进行写操作时长时间地锁定索引。
当对段进行读或合并操作时, 就需要用到commit.lock文件。
在Index Reader对象读取段文件之前会获取commit.lock文件,在这个锁文件中对所有的索引段进行了命名, 只有当Index Reader对象已经打开并读取完所有的段后, Lucene才会释放这个锁文件。Index Writer对象在创建新的段之前,也需要获得commit.lock文件,并一直对其进行维护,直至该对象执行诸如段合并等操作,并将无用的索引文件移除完毕之后才释放。
因此,commit.lock的创建可能比write.lock更为频繁, 但commit.lock决不能过长时间地锁定索引,因为在这个锁文件生存期内,索引文件都只能被打开或删除,并且只有一小部分的段文件被写入磁盘里。
表2.4对Lucene中各种使用Lucene API来锁定索引的情况进行了概括。
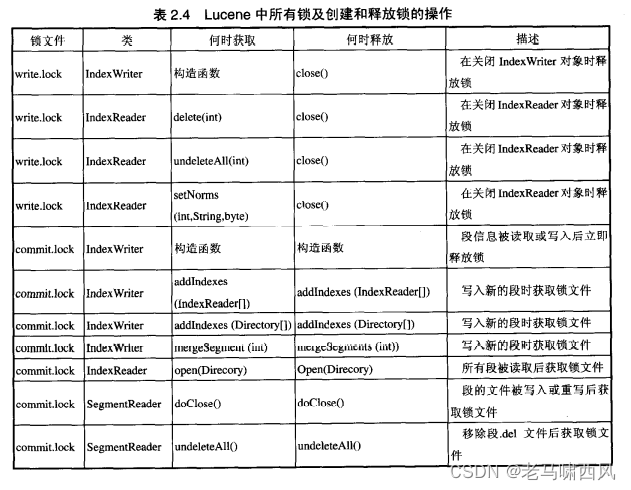
请注意另外两个与锁相关的方法: 1)Index Reader的isLocked(Directory)
这个方法可以判断参数中指定的索引是否已经被上锁。
在想要对索引进行某种修改操作之前,应用程序需要检查索引是否被锁保护时,通过使用这个方法可以很方便地得到结果。
2)Index Reader的unlock(Directory) ———该方法的作用正如其命名那样。
尽管通过这个方法可以使你在任意时刻对任意的Lucene索引进行解锁, 然而它的使用具有一定的危险性。因为Lucene创建锁自有其理由,此外, 在修改一个索引时对其解锁可能导致这个索引被损坏,从而使得这个索引失效。
虽然知道Lucene使用了哪些锁文件,何时、为什么要使用它们, 以及在文件系统的何处存放这些锁文件,但是你不能直接在文件系统对它们进行操作。
你应该通过Lucene的API对它们进行操作。
否则, 如果将来Lucene开始启用一种不同的锁机制,或者Lucene改变了锁文件的命名或存储位置时,应用程序可能会受到影响面不能顺利执行。
参考资料
《Lucene in Action II》
