场景
如果我们不能通过搜索找到某个文档,那么这个文档就不能为我们所用。即使我们已经对文档进行了索引,如果不能够快速可靠地找到这些文档,我们仍然会徒劳无功。
例如,考虑如下情景:
假设我们需要找出最近12个月出版的有关 Java 的书籍列表,这些书的内容里一定要包含“open source”或“Jakarta”这样的关键字,此外还要求它们是特价书籍。
另外请别忘了,还要加上一点,关键字“Apache”也应该计算在内,因为我们在说“Apache”时往往也就意味着“Jakarta”。
并且一定要保证速度,响应时间应该在毫秒的数量级上”。
如果有一个数以百万计容量的文档库,该如何为该文档库实现类似上述的需求的搜索功能?
使用 Lucene API 来提供搜索功能非常简单且易于实现,不过它内部的机制却是非常复杂的,通过这些机制我们可以满足用户在搜索方面的需求,比如搜索结果会把相关度最大的文档排列最优先的位置,而且还能够以极快的速度检索出结果。本章的内容涵盖了使用Lucene API 进行搜索的通用方法。大部分基于 Lucene 实现的搜索应用程序都能够提供良好的搜索特性,而这种特性基本上都是使用本章所提供的技术来实现的。
在第5章我们将深入研究更高级的搜索功能;而在第6章,为了获得更强大的搜索功能,我们详述了如何对Lucene 中的某一些进行扩展。
首先,让我们示范一个简单的例子,仅仅编写几行代码就能实现搜索功能。
然后,我们将对 Lucene 的一个最为独特的属性——评分规则进行深入的研究。
在对这个例子有个全局的理解后,我们还将进一步深入探究 Lucene 如何对搜索结果进行排序,最后,我们将介绍 Lucene 是如何处理各种不同类型的查询的。
3.1 实现一个简单的搜索程序
假设要想为应用程序添加搜索功能,并且事先已经对数据进行索引,现在要做的就是为用户提供全文搜索的功能。很难想象如果不使用 Lucene, 要实现这个功能是多么的困难。利用 Lucene, 我们只需要编写短短的几行代码就可以获得所需的搜索结果。通过Lucene 我们还可以简单而高效地对搜索结果进行访问,这就能够用更多的精力去研究一些更重要的问题,比如程序业务逻辑和搜索结果的用户界面等。
在本章中,我们只讨论 Lucene API中一些主要的类,因为在将 Lucene 搜索功能融入到应用程序中时需要使用到这些类(如表3.1所示)。

当我们查询 Lucene 的一个索引时,Lucene 会返回一个有序的 Hits 对象集合(collection)。
Lucene 使用默认的评分方式对该集合内的对象按照其得分高低进行排序。对于一个给定的查询, Lucene 为每个文档计算一个评分(即一个表示相关性的数值)。
Hits 本身不是实际的匹配文档集,只是指向这些匹配文档的引用(reference)。
在许多显示搜索结果的应用程序中,用户访问的只是最开始的一部分匹配文档,因此没有必要对搜索结果中的所有文档都进行检索;而只需检索那些有必要呈现给用户的文档就可以了。
对于大型索引来说,系统甚至可能没有足够的物理内存来存储所匹配到的全部文档。
在接下来的部分中,我们把IndexSearcher、Query、Hits 对象和一些基本的对象的搜索结合起来,介绍Lucene 的搜索特性。
3.1.1 对特定项(specific term) 的搜索
IndexSearcher 是用于对索引中的文档进行搜索的核心类。
它有几个重载的 search() 方法。
可以使用最常用的 search 方法对指定的项进行搜索。
一个项(Term)对象由该项所处域的名称,以及该项的值组成——在下面的例子里,我们所搜索的项就位于 subject 域里。
注:重点:原始文本可能已经被分析器 (analyzer)划分为若干个项,在分析过程中Lucene 可能会消除掉一些项(比如停止词)、或把各个项转换成小写的形式,还可能把还原为其基本形式(即还原为词干)或者插入一些附加的项(即同义词处理 synonym processing)等。
重要的一点是,传递给 IndexSearcher 的项应该和对源文档进行分析后所得出的项保持一致。
第 4 章将详细讨论这个分析过程。
- 查询例子
// 读取
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(reader);
Term term = new Term("id","张三");
Query termQuery = new TermQuery(term);
TopDocs topDocs = indexSearcher.search(termQuery,10);
V7.2.1 版本没有 Hits,而是 TopDocs。所以没有直接取书中的例子。
QueryParser
解析用户输入的查询表达式: QueryParser
大部分用于搜索的应用程序都需要具备以下两个特征:能对复杂查询条件进行解析并能访问搜索到的文档。
Lucene 的 search 方法需要一个 Query 对象作为其参数。
对查询表达式的解析,实际上是将诸如“mock OR junit”这样的用户输入的查询表达式转换成一个对应的Query 实例的过程;
在下面的例子中,我们可以使用一个带有两个逻辑“或”子句的 BooleanQuery 对象来作为程序所需的 Query 对象,在这个 BooleanQuery 对象里
Lucene 具有一个引人注目的特性,那就是我们可以通过 QueryParser 类对查询表达式进行解析。
- 例子
创建索引:
@Test
public void createIndexTest() throws IOException {
final String indexDir = "index/chap03";
//1. 构建 writer
Directory directory = FSDirectory.open(Paths.get(indexDir));
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig iwConfig = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, iwConfig);
//2. 写入 document
List<String> contentList = Arrays.asList("java with lucene", "go with lucene", "go with java");
int id = 0;
for(String text : contentList) {
id++;
Document document = new Document();
document.add(new StringField("id", id+"", Field.Store.YES));
document.add(new TextField("content", text, Field.Store.YES));
indexWriter.addDocument(document);
}
//3. 关闭属性
indexWriter.commit();
indexWriter.close();
}
输出结果:
@Test
public void queryParserTest() throws IOException, ParseException {
final String indexDir = "index/chap03";
//1. 构建 writer
// 得到读取索引文件的路径
Directory dir = FSDirectory.open(Paths.get(indexDir));
// 通过dir得到的路径下的所有的文件
IndexReader reader = DirectoryReader.open(dir);
// 建立索引查询器
IndexSearcher indexSearcher = new IndexSearcher(reader);
// 实例化分析器
Analyzer analyzer = new StandardAnalyzer();
/**
* 第一个参数是要查询的字段; 第二个参数是分析器Analyzer
*/
// 指定查询 content 内容,满足有 java 和 lucene 关键词。
QueryParser parser = new QueryParser("content", analyzer);
Query query = parser.parse("java and lucene");
TopDocs hits = indexSearcher.search(query, 1);
// 结果展现
for (ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = indexSearcher.doc(scoreDoc.doc);
System.out.println(doc.get("content"));
}
}
日志结果:
java with lucene
特别是对于 QueryParser, 我们还需要更进一步的解释。
下面我们就对如何使用 QueryParser 进行简要的介绍,稍后我们还会在本章中对此问题再加以详细讨论。
表达式范式
ps: expresson 这个功能非常强大,本质上需要解析字符串,构建语法树。
| 表达式 | 范式 | 备注 |
|---|---|---|
| java | 默认包含 java 的文档 | |
| java junit | 默认包含 java 或者 unit 的文档 | 等价于 java OR junit |
| +java +junit | 默认同时包含 java 和 unit 的文档 | 等价于 java AND junit |
| title:ant | title 域包含 ant 项的文档 | |
| title:ant -subject:maven | title 域包含 ant 项的文档,且 subject 余不包含 maven 的文档 | - 等价于 AND NOT |
| (ant OR maven) AND npm | 默认域包含 and 或者 maven,且包含 npm 的文档 | |
| title:”junit in action” | title 域包含 “junit in action” 的文档 | |
| title:”junit in action”~5 | title 域包含 “junit in action” 且距离小于 5 的文档 | |
| java* | 包含 java 开头的文档 | |
| java~ | 和 java 相似的文档,比如 lava | |
| price:[100 TO 200] | price 域值在 [100,200] 范围内的数据 |
3.2 使用 IndexSearcher
IndexSearcher 构建
让我们更深入地了解一下 Lucene 的 IndexSearcher 类。
像 Lucene 其他主要的API一样,IndexSercher 简单易用。
搜索操作是通过一个 IndexSearcher 的实例完成的。
读者可以通过以下参数来构造个 IndexSearcher 实例。
-
通过 Directory 对象
-
通过文件系统的路径
我们推荐使用第一种方法(使用 Directory 对象的构造函数),因为应用程序最好将索引存放的路径与搜索操作隔离开来,从而使搜索的程序段不必关注索引所保存的位置,也就是说,无论这些索引是保存在文件系统、RAM还是其他什么地方,我们都不需要对执行搜索的代码段进行修改。
而实际上, directory 是一个从文件系统索引中加载的FSDirectory 对象。
ps: 方法 1 可以让 RAM 和 FS 保持一致性。
final String indexDir = "index/chap03";
//1. 构建 writer
// 得到读取索引文件的路径
Directory dir = FSDirectory.open(Paths.get(indexDir));
// 通过dir得到的路径下的所有的文件
IndexReader reader = DirectoryReader.open(dir);
// 建立索引查询器
IndexSearcher indexSearcher = new IndexSearcher(reader);
执行查询
构造好 IndexSearcher 对象后,我们紧接着调用它的一个 search 方法进行搜索。
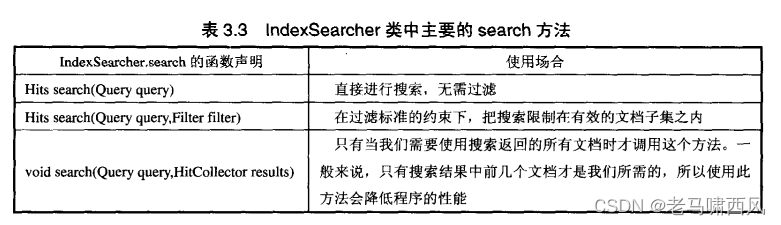
表3.3展示了IndexSearcher 的三个主要的 search 函数的定义。
本章只讨论 search(Query)方法,这可能是你目前惟一需要关注的方法。
我们将在第5章中讨论其他的 search 方法,在那些search 方法中将包含一些用于对结果进行排序的参数。
比如:
// 实例化分析器
Analyzer analyzer = new StandardAnalyzer();
// 指定查询 content 内容,满足有 java 和 lucene 关键词。
QueryParser parser = new QueryParser("content", analyzer);
Query query = parser.parse("java and lucene");
TopDocs hits = indexSearcher.search(query, 1);
ps: 这里的 search 替换为 searchAfter 就可以构建对应的分页实现,还有对应的 Sort 排序规则,后续进行讨论。
结果处理
TopDocs 是符合条件的数据引用,我们可以通过下面的方式获取结果:
// 结果展现
for (ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = indexSearcher.doc(scoreDoc.doc);
System.out.println(doc.get("content"));
}
3.2.3 将索引读入内存
使用RAMDirectory 类对临时索引进行查询是非常合适的,但是更多的应用程序需要持久保存其索引,因此不能将索引一直驻留在内存中。这就最终需要用到我们在前两章介绍过的 FSDirectory 类。
尽管如此,在某些特定的情况下,应用程序会以只读方式使用索引。
例如,假设你所使用的计算机的主存储器容量超过了文件系统中 Lucene 索引文件的大小,虽然可以通过存储在索引目录中的索引进行搜索,但也可以通过从慢速的硬盘上将索引读入快速的 RAM中,然后搜索内存储器中的索引,这种方式能更好地利用现有的硬件资源。
在这种情况下,RAMDirectory 的构造函数通常用于将基于文件系统的索引读入到主存储器中,从而使得应用程序能充分利用 RAM 访问速度较快的优点。
以下是 RAMDirectory 对象的构造过程:
RAMDirectory ramDir = new RAMDirectory(dir)
RAMDirectory 有多个重载的构造函数,这些构造函数分别能够将一个 java.io.File、路径字符串对象或者其他的 Directory 对象加载到 RAM 中。
在 IndexSeracher 中对RAMDirectory 的使用是十分方便的,它和使用 FSDirectory 作为参数并没有任何区别。
3.3 理解 Lucene 的评分机制
为了使读者能够对影响 Lucene 评分的各个因素有一个全面的认识,我们在这章就来讨论一下这个复杂的主题。
首先,我们来看一下图3.1中的相似度评分公式。
Lucene 会为由某一指定查询匹配到的每个文档d使用这个公式计算其相应的得分。
- 图 3.1 Lucene 利用这个公式计算出匹配于某一查询的文档的评分

注:如果你对这个方程式或者这种数学计算思想的理解存在一定困难,可以跳过这个小节。
Lucene 的评分机制是相当拔尖非常优秀的,但完全理解 Lucene 的评分机制如何工作并不需要使用 Lucene 的各项功能。
通过这个评分公式得到的只是原始的得分,但由 Hits 对象返回的关于某一文档的评分却不一定是其原始的得分。
因为,评分最高的文档的得分如果超过了1.0,那么接下来的所有评分都会以这个评分为标准进行计算,因此所有 Hits 对象的得分都只能小于或等于1.0。
表 3.5 列出了在评分公式中的各个因子。

在公式中加入加权因子 (boost factor),可使你有效地对某个查询或某一域给评分带来的影响施加控制。
Lucene 在索引时,显式地通过 boost(t.field in d)来设置某个域的加权因子。该加权因子的默认值为1.0。
在索引期间,也可以为 Document 对象设置加权因子。它隐式地把该文档中所有域的初始加权因子都设置为指定值。特定域的加权因子是初始加权因子的倍数,经过一定处理后才最终得出该域加权因子的值。在索引过程中,有可能多次将同一域添加到同一个文档中,在这种情况下,该域的加权因子就等于该域在这个文档的所有加权因子之和。在2.3小节中我们就曾经讨论过在索引时对某个域进行加权处理的问题。
在这个公式中除了一些明确的因子外,其他一部分作为查询标准(queryNorm)的因子可以在每次查询的基础上计算出来。
Query 对象本身对匹配文档的评分也会产生一定的影响。加权处理某一 Query 对象仅在应用程序执行多重子句的查询时比较有效;如果只搜索单个项,加权处理该项相当于同时对所有匹配该项的文档都进行了相同比例的加权。在多重子句的布尔查询中,一些文档可能只匹配其中的一个子句,使用不同的加权因子可以用来区分不同的查询条件。Query 对象加权因子的值也默认为1.0。
在这个评分公式中,对绝大多数因子的控制都是通过 Similarity 实例来实现的。如果不另外指定,在默认的情况下 Lucene 会用 DefaultSimilarity 来实现 Similarity 类。
此外,DefaultSimilarity 类还负责处理评分中更多的计算过程,例如,项频率(term frequency)因子就是实际频率的平方根。因为这是一本讲述如何“实践”的书籍所提到的,故深入研究这些核心运算过程已经超出了本书的范围。
实际上,这些因子是极少需要改变的。如果你需要改变这些因子,请参考 Similarity 类的相关文档,但同时必须对这些因子的作用有很好的理解,并清楚改变它们后有可能带来的结果。
此外还要注意,索引过程中改变加权因子或使用了 Similarity 类的方法后,为了同时协调所有的相关因子,应用程序需要对索引进行重建。
Explain
评分公式的复杂程度是显而易见的,令人望而却步。
我们正在讨论的是评分公式中一些因子,它们使基于同一查询的某些文档的评分高于其他的文档。如果确实想知道这些因子是如何计算出来的, Lucene 提供了一个称为 Explanation 的类来满足这个需要。IndexSearcher 中有一个 explain 方法,调用该方法需要提供一个 Query 对象和一个文档ID作为参数,且该方法会返回一个 Explanation 对象。
Explanation 对象的内部包含了所有关于评分计算中各个因子的细节信息。如果需要的话,虽然可以对每个因子的细节进行访问,但是通常全部输出这些解释还是有必要的。
toString()方法可以将 Explanation 对象很好地以文本格式输出来。
例子
以下是一个简单的输出Explanation 对象的程序例子:
public void queryParserExplainTest() throws IOException, ParseException {
final String indexDir = "index/chap03";
//1. 构建 writer
// 得到读取索引文件的路径
Directory dir = FSDirectory.open(Paths.get(indexDir));
// 通过dir得到的路径下的所有的文件
IndexReader reader = DirectoryReader.open(dir);
// 建立索引查询器
IndexSearcher indexSearcher = new IndexSearcher(reader);
// 实例化分析器
Analyzer analyzer = new StandardAnalyzer();
/**
* 第一个参数是要查询的字段; 第二个参数是分析器Analyzer
*/
// 指定查询 content 内容,满足有 java 和 lucene 关键词。
QueryParser parser = new QueryParser("content", analyzer);
Query query = parser.parse("java and lucene");
TopDocs hits = indexSearcher.search(query, 1);
// 结果展现
for (ScoreDoc scoreDoc : hits.scoreDocs) {
Explanation explanation = indexSearcher.explain(query, scoreDoc.doc);
// 输出
System.out.println(explanation.toString());
}
}
对应的输出结果:
0.8836655 = sum of:
0.44183275 = weight(content:java in 0) [BM25Similarity], result of:
0.44183275 = score(doc=0,freq=1.0 = termFreq=1.0
), product of:
0.44183275 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:
4.0 = docFreq
6.0 = docCount
1.0 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:
1.0 = termFreq=1.0
1.2 = parameter k1
0.75 = parameter b
2.0 = avgFieldLength
2.0 = fieldLength
0.44183275 = weight(content:lucene in 0) [BM25Similarity], result of:
0.44183275 = score(doc=0,freq=1.0 = termFreq=1.0
), product of:
0.44183275 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:
4.0 = docFreq
6.0 = docCount
1.0 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:
1.0 = termFreq=1.0
1.2 = parameter k1
0.75 = parameter b
2.0 = avgFieldLength
2.0 = fieldLength
参考资料
《Lucene in Action II》
