是什么
实现方式
开源
滑块验证码的形式
滑块验证码的形式也很多,大多都类似下面这样的。
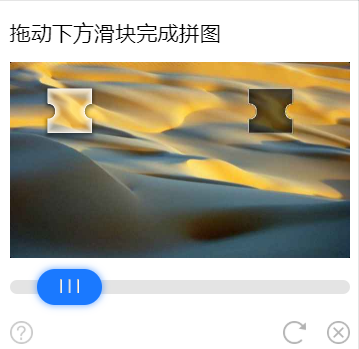
一般类似这样的验证码已经有很成熟的解决方案了。
比如 js 破解,图像识别破解等等。
但是我在项目中遇到的验证码有一点不同是下面这种验证码(拼夕夕的验证码)可以看到背景更复杂,而且它使用两个缺口,两个缺口的形状不一样,因此对于此类验证码识别更加困难。

采用的方法
对该类新型验证码分析,最开始准备使用深度学习的方法,大力出奇迹,但是有一个现实问题没多少数据。
公司目前收集的也只有六七十张,于是只好放弃深度学习,采用传统方法opencv来做。
使用opencv做的思路就是,获取滑块图和背景图,进行模板匹配,匹配度最高作为结果输出
1.滑块图、背景图切分
想要拿到干净的滑块图和背景图需要进行js破解,这个破解比较耗时一张验证码大概需要30s,30s后验证码都失效了,所以我只能手动切图。
下面是切图代码:
def crop(img_name):
img = cv2.imread(img_name)
# bg = img[130:,0:362] # 裁剪坐标为[y0:y1, x0:x1]
part = img[0:362,0:139]
bg = img[0:362,139:]
# cv2.imwrite("part_crop.png", part)
# cv2.imwrite("bg_crop.png", bg)
return bg,part
切好的滑块图和背景图

图片切好过后就可以进行模板匹配了
模板匹配
对切好的图片先进行轮廓提取,然后再使用模板匹配,其中轮廓提取使用了Canny算子:
def detect_captcha_gap(bg,tp):
'''
bg: 背景图片
tp: 缺口图片
return:空缺距背景图左边的距离
'''
# 读取背景图片和缺口图片
# bg_img = cv2.imread(bg) # 背景图片
# tp_img = cv2.imread(tp) # 缺口图片
bg_img = bg
tp_img = tp
# 识别图片边缘
bg_edge = cv2.Canny(bg_img, 100, 200)
tp_edge = cv2.Canny(tp_img, 100, 200)
# 转换图片格式
bg_pic = cv2.cvtColor(bg_edge, cv2.COLOR_GRAY2RGB)
tp_pic = cv2.cvtColor(tp_edge, cv2.COLOR_GRAY2RGB)
# cv2.imwrite("bg_style.png",bg_pic) # 保存背景轮廓提取
# cv2.imwrite("slide_style.png",tp_pic) # 保存滑块背景提取
# 缺口匹配
res = cv2.matchTemplate(bg_pic, tp_pic, cv2.TM_CCOEFF_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # 寻找最优匹配
th, tw = tp_pic.shape[:2]
tl = max_loc # 左上角点的坐标
# 返回缺口的左上角X坐标
br = (tl[0]+tw,tl[1]+th) # 右下角点的坐标
cv2.rectangle(bg_img, tl, br, (0, 0, 255), 2) # 绘制矩形
cv2.imwrite("result_new.png", bg_img) # 保存在本地
# 返回缺口的左上角X坐标
return tl[0]
下面是Canny算子提取的轮廓图,可以发现效果还是不错,能够看到两幅图中的相似轮廓。
目前已经能够正确匹配出滑块对应缺口的位置了。
滑块破解
bilibili 破解
# -*- coding:utf-8 -*-
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver import ActionChains
from bs4 import BeautifulSoup
from urllib.request import urlretrieve
from PIL import Image
import time, re, random, os
class CrackGeetest():
def __init__(self):
self.url = 'https://passport.bilibili.com/login'
self.browser = webdriver.Chrome()
self.wait = WebDriverWait(self.browser, 10)
def mk_img_dir(self):
"""
创建图片目录文件
:return:
"""
if not os.path.exists('Image'):
os.mkdir('Image')
def get_geetest_image(self):
"""
获取验证码图片
:return: 图片location信息
"""
bg = []
fullgb = []
while bg == [] and fullgb == []:
soup = BeautifulSoup(self.browser.page_source, 'lxml')
bg = soup.find_all('div', class_='gt_cut_bg_slice')
fullgb = soup.find_all('div', class_='gt_cut_fullbg_slice')
bg_url = re.findall('url\(\"(.*?)\"\);', bg[0].get('style'))[0].replace('webp', 'jpg')
fullgb_url = re.findall('url\(\"(.*?)\"\);', fullgb[0].get('style'))[0].replace('webp', 'jpg')
bg_location_list = []
fullgb_location_list = []
for each_bg in bg:
location = {}
location['x'] = int(re.findall('background-position: (.*)px (.*)px;', each_bg.get('style'))[0][0])
location['y'] = int(re.findall('background-position: (.*)px (.*)px;', each_bg.get('style'))[0][1])
bg_location_list.append(location)
for each_fullgb in fullgb:
location = {}
location['x'] = int(re.findall('background-position: (.*)px (.*)px;', each_fullgb.get('style'))[0][0])
location['y'] = int(re.findall('background-position: (.*)px (.*)px;', each_fullgb.get('style'))[0][1])
fullgb_location_list.append(location)
self.mk_img_dir()
urlretrieve(url=bg_url, filename='Image/bg.jpg')
print('缺口图片下载完成!')
urlretrieve(url=fullgb_url, filename='Image/fullgb.jpg')
print('背景图片下载完成!')
return bg_location_list, fullgb_location_list
def get_merge_image(self, filename, location_list):
"""
根据图片位置合并还原
:param filename: 图片
:param location: 位置
:return:合并后的图片对象
"""
im = Image.open(filename)
new_im = Image.new('RGB',(260,116))
im_list_upper = []
im_list_lower = []
for location in location_list:
if location['y'] == -58:
im_list_upper.append(im.crop((abs(location['x']),58,abs(location['x'])+10,116)))
if location['y'] == 0:
im_list_lower.append(im.crop((abs(location['x']),0,abs(location['x'])+10,58)))
x_offset = 0
for img in im_list_upper:
new_im.paste(img, (x_offset, 0))
x_offset+=img.size[0]
x_offset = 0
for img in im_list_lower:
new_im.paste(img, (x_offset, 58))
x_offset+=img.size[0]
new_im.save('Image/'+re.split('[./]', filename)[1]+'1.jpg')
return new_im
def is_px_equal(self, img1, img2, x, y):
"""
判断两个像素是否相同
:param img1: 图片1
:param img2:图片2
:param x:位置1
:param y:位置2
:return:像素是否相同
"""
pix1 = img1.load()[x,y]
pix2 = img2.load()[x,y]
threshold = 60
if abs(pix1[0]-pix2[0]) < threshold and abs(pix1[1]-pix2[1]) < threshold and abs(pix1[2]-pix2[2]) < threshold:
return True
else:
return False
def get_gap(self, img1, img2):
"""
获取缺口偏移量
:param img1: 不带缺口图片
:param img2: 带缺口图片
:return:
"""
left = 60
for i in range(left, img1.size[0]):
for j in range(img1.size[1]):
if not self.is_px_equal(img1, img2, i, j):
left = i
return left
return left
def get_track(self, distance):
"""
根据偏移量和手动操作模拟计算移动轨迹
:param distance: 偏移量
:return: 移动轨迹
"""
# 移动轨迹
tracks = []
# 当前位移
current = 0
# 减速阈值
mid = distance * 4 / 5
# 时间间隔
t = 0.2
# 初始速度
v = 0
while current < distance:
if current < mid:
a = random.uniform(2, 5)
else:
a = -(random.uniform(12.5, 13.5))
v0 = v
v = v0 + a * t
x = v0 * t + 1 / 2 * a * t * t
current += x
if 0.6 < current - distance < 1:
x = x - 0.53
tracks.append(round(x, 2))
elif 1 < current - distance < 1.5:
x = x - 1.4
tracks.append(round(x, 2))
elif 1.5 < current - distance < 3:
x = x - 1.8
tracks.append(round(x, 2))
else:
tracks.append(round(x, 2))
return tracks
def get_slider(self):
"""
获取滑块
:return:滑块对象
"""
try:
slider = self.wait.until(EC.element_to_be_clickable((By.XPATH, '//div[@class="gt_slider"]/div[contains(@class,"gt_slider_knob")]')))
return slider
except TimeoutError:
print('加载超时...')
def move_to_gap(self, slider, tracks):
"""
将滑块移动至偏移量处
:param slider: 滑块
:param tracks: 移动轨迹
:return:
"""
action = ActionChains(self.browser)
action.click_and_hold(slider).perform()
for x in tracks:
action.move_by_offset(xoffset=x,yoffset=-1).perform()
action = ActionChains(self.browser)
time.sleep(0.6)
action.release().perform()
def success_check(self):
"""
验证是否成功
:return:
"""
try:
if re.findall('gt_success', self.browser.page_source, re.S):
print('验证成功!')
return True
else:
print('验证失败!')
return False
except TimeoutError:
print('加载超时...')
finally:
self.browser.close()
if __name__ == '__main__':
try:
while True:
check = CrackGeetest()
check.browser.get(check.url)
bg_location_list, fullgb_location_list = check.get_geetest_image()
img1 = check.get_merge_image('Image/fullgb.jpg', fullgb_location_list)
img2 = check.get_merge_image('Image/bg.jpg', bg_location_list)
# distance应根据实际情况做微调
distance = check.get_gap(img1, img2) * 1.138
slider = check.get_slider()
tracks = check.get_track(distance)
check.move_to_gap(slider, tracks)
time.sleep(0.5)
CHECK = check.success_check()
if CHECK == True:
break
except Exception:
print('程序出错啦!')
qq 的滑块破解
from selenium import webdriver
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains # 鼠标拖动
driver = webdriver.Chrome(executable_path="../chromedriver.exe")
url = "https://mail.qq.com/"
driver.get(url)
time.sleep(3)
driver.switch_to.frame("login_frame")
driver.find_element_by_id("u").send_keys("1428515626")
time.sleep(0.5)
driver.find_element_by_id("p").send_keys("cdsfds2121")
time.sleep(1)
WebDriverWait(driver, 10).until(ec.element_to_be_clickable((By.ID, "login_button"))) # 判断按钮是否可以点击
driver.find_element_by_id("login_button").click()
time.sleep(2)
driver.switch_to.frame("tcaptcha_iframe") # 滑块又是一个新的frame框架 需要重新更改
time.sleep(0.4)
while True:
slider = WebDriverWait(driver, 5).until(ec.element_to_be_clickable((By.ID, "tcaptcha_drag_thumb")))
distance = 190
actions = webdriver.ActionChains(driver)
# 点击开始拖拽
actions.click_and_hold(slider) # 先一直点击不动
actions.pause(0.3) # 暂停0.2秒
actions.move_by_offset(distance + 20, 0)
actions.pause(0.15)
actions.move_by_offset(-35, 0)
actions.pause(0.6)
actions.release() # 松开按钮
actions.perform()
time.sleep(2)
try:
shuaxin = WebDriverWait(driver, 1).until(ec.presence_of_element_located((By.ID, "e_reload")))
driver.find_element_by_id("e_reload").click()
time.sleep(1)
except:
driver.quit()
break
小结
希望本文对你有所帮助,如果喜欢,欢迎点赞收藏转发一波。
我是老马,期待与你的下次重逢。
