业务需求
其他部门提供一个全量的文件。
每天都会按照日期新生成一个实体标注标签文件,如 entity_tag_20220801.txt。其中 20220801 是每一天的生成日期。
V1 基本思路
直接遍历全量的文件。
发现性能比较差,要跑很久才能完成。
V2 多线程
使用多线程
性能基本可以接受,但是数据库压力还是比较大的。
V3 文件差异
结合业务,其实一般情况下,实体的标准信息,并不会轻易的变化。
那么,只处理差异的部分显然性能会更好。
差异文件如何获取?
可以让文件的提供者对比文件差异。
如果对方不允许的话,那么可以自行对比。
linux
最简单的思路,可以通过 linux 的命令对比差异。
java 可以通过 command 命令调用 linux 的命令。
sort
diff
uniq
可以把两个文件中差异的部分输出到指定的文件。
一个同事就是通过 linux 命令进行文件差异对比。
java 代码调用对应的 linux command 命令。
缺点有两个:
(1)如果是 windows 系统,不太好直接测试。
(2)如果生产环境是 k8s 等虚拟节点,系统的 IO 比较高,可能会被直接 kill 掉。
那么,能不能通过 java 程序实现上面的功能呢?
答案是肯定的。
v4 程序实现文件差异对比
个人还是希望通过程序的方式,来实现文件的差异对比。
便于一些管理和拓展。
常规方式
如果文件不大,可以把所有的数据加载到内存中,然后通过程序进行集合的差集运算。
此处不做深入。
大文件
如果文件非常大的话,那应该怎么处理呢?
同时怎么保证性能呢?
实现思路
要想对比文件内容的差异,同时兼顾性能。
建议从拆分为 2 个步骤解决这个问题。
(1)排序
(2)差异
接下来我们一起来看一下这 2 个问题即可。
排序
大文件排序
通常来说,外排序处理的数据不能一次装入内存,只能放在读写较慢的外存储器(通常是硬盘)上。
在排序阶段,先读入能放在内存中的数据量,将其排序输出到一个临时文件,依此进行,将待排序数据组织为多个有序的临时文件。之后在归并阶段将这些临时文件组合为一个大的有序文件,也即排序结果。
算法
-
将大文件拆分为多个子文件,一遍可以完全加载到内存
-
对每一个子文件进行内存排序,为后续排序做好准备
-
对文件 2 个合并为 1 个,保证合并后依然是有序的
-
重复步骤 3,直到最后一个文件。就是结果
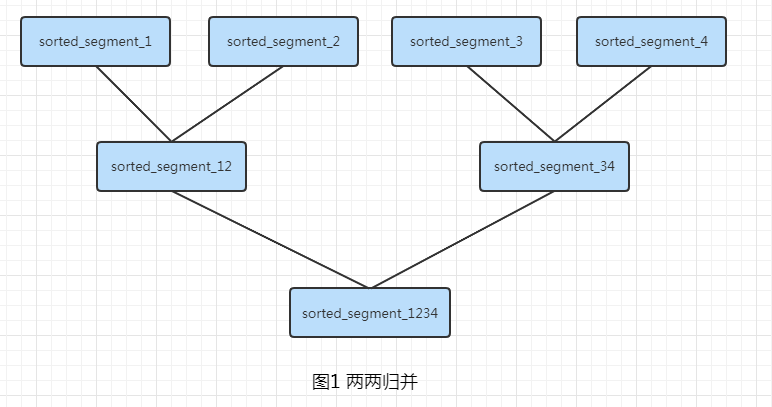
本文演示的是二路归并,以此可以拓展为 K 路归并。
一些需要考虑点
下面几个小问题在实现之前可以思考一下。
(1)文件拆分,需要保证可以完全加载到内存。同时保证拆分的大小用户可以指定,便于适应不同的业务场景。
(2)理论上说,任意 2 个文件合并,都可以达到步骤 3 的效果。但是如果 2 个文件行数差异过大,性能反而会下降。比如,一直把文档往单一的文件上合并。
(3)处于性能考虑,2 个文件合并为 1 个,一般是可以并行的。可以引入多线程提升性能。
实现例子
下面说一下 java 实现的核心代码。
@Override
public void sort(String sourceFile,
String targetFile) {
// 1. 创建
this.createTempDir(sourceFile);
//2. 文件拆分
splitSourceFile(sourceFile);
//3. 合并文件
mergeFiles(0, sourceFile, targetFile);
//4. 删除文件夹
deleteDirs(sourceFile);
}
我们重点看一下文件的拆分和合并。
文件拆分
按照一定的 limitLines(默认为 10W 行)对原始文件进行拆分。
每一个子文件都进行排序,统一放在临时文件夹中。
/**
* 对原始文件进行拆分
* @param sourceFilePath 源文件
*/
private void splitSourceFile(String sourceFilePath) {
try {
final String tempDirName = getSourceTempDir(sourceFilePath);
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(sourceFilePath)));
int i = 0;
int count = 0;
String num = "";
List<String> list = new ArrayList<>();
while ( (num = br.readLine()) != null){
list.add(num);
count++;
if (count == limitLines){
String filePath = tempDirName + "tmp_0_" + i++;
Collections.sort(list);
FileUtil.write(filePath, list);
list.clear();
count = 0;
}
}
// 如果不为空的话
if(CollectionUtil.isNotEmpty(list)) {
String filePath = tempDirName + "tmp_0_" + i++;
Collections.sort(list);
FileUtil.write(filePath, list);
list.clear();
}
br.close();
} catch (Exception e) {
throw new SortException(e);
}
}
文件合并
文件的合并采用递归实现。
(1)一开始从 tmp_0_xxx 的文件开始
(2)2 个一组进行合并,放入到下一层 tmp_1_xxx。尽量缩小合并文件的大小差异。
(3)如果文件是奇数个,剩余的最后一个直接重命名进行下一层。
(4)递归调用,如果只剩最后一个文件,循环终止。
/**
* 合并文件
* @param level 层级
* @param sourceFile 原始文件
* @param targetFile 目标文件
*/
private void mergeFiles(int level,
String sourceFile,
String targetFile) {
try {
final String tempDirPath = getSourceTempDir(sourceFile);
// 临时文件夹
File tempDir = new File(tempDirPath);
File[] files = tempDir.listFiles();
if (files.length <= 1) {
// 复制到结果文件
copyFile(files[0], targetFile);
files[0].delete();
return;
}
int index = 0;
int nextLevel = level+1;
// 2 2合并,并将文件之后放在下一个 level
int i = 0;
for (i = 0; i < files.length - 1; i += 2) {
String fileName = tempDirPath + "tmp_" + nextLevel + "_" + index++;
mergeTwoFiles(fileName, files[i], files[i + 1]);
files[i].delete();
files[i + 1].delete();
}
// 还剩一个单独的,修改名称直接放在下一个 level
if (i == files.length - 1) {
copyFile(files[i], tempDirPath + "tmp_" + nextLevel + "_" + index++);
files[i].delete();
}
// 递归处理
mergeFiles(level+1, sourceFile, targetFile);
} catch (IOException e) {
throw new SortException(e);
}
}
大文件的差异对比
实现
我们在上一步已经把一个大文件进行排序,保证其有序性。
接下来对比差异就会方便一些。
算法思路
假设有 A/B 两个文件,要对比 A 和 B 的差异。
只需要逐行对比两个文件,把差异的部分写入结果文件中即可。
java 实现
java 实现的核心如下:
@Override
public void differ(String sourceFilePath, String targetFilePath, String resultFilePath) {
try {
BufferedReader sourceReader = InnerFileUtils.getBufferedReader(sourceFilePath);
BufferedReader targetReader = InnerFileUtils.getBufferedReader(targetFilePath);
BufferedWriter resultWriter = InnerFileUtils.getBufferedWriter(resultFilePath);
String sourceLine = sourceReader.readLine();
String targetLine = targetReader.readLine();
// 这里暂时不考虑重复行的问题(可以文件先去重复)
// 只能比较出左边在右边没有的,右边和左边的差异需要反过来对比一次。
while (sourceLine != null && targetLine != null) {
// 左边较小是可以直接放入差异文件中的,因为文件有序。
if (sourceLine.compareTo(targetLine) < 0) {
resultWriter.write(sourceLine);
resultWriter.newLine();
sourceLine = sourceReader.readLine();
} else if(sourceLine.compareTo(targetLine) > 0) {
// 左边的文件较大
//1. 左边大,如果直接添加。右边文件后续可能存在相同的内容。
//2. 左边大,直接丢弃右边。会不会右边没有相同的内容,而导致实际存在这个差异?放在最后在处理即可。
targetLine = targetReader.readLine();
} else if (sourceLine.equals(targetLine)) {
// 二者相等(相等的同时丢弃处理)
sourceLine = sourceReader.readLine();
targetLine = targetReader.readLine();
}
}
// 剩余的左边部分处理
while (sourceLine != null){
resultWriter.write(sourceLine);
resultWriter.newLine();
sourceLine = sourceReader.readLine();
}
sourceReader.close();
targetReader.close();
resultWriter.close();
} catch (IOException e) {
throw new CompareException(e);
}
}
整合使用
实现了上面 2 个工具之后,我们想程序解决一开始的业务问题就会比较简单。
对于一个 entity_tag_20220802.txt 的全量标签文件,我们获取到昨天的全量文件 entity_tag_20220801.txt。
(1)对 2 个文件进行排序,得到:
entity_tag_20220802_sort.txt
entity_tag_20220801_sort.txt
(2)对比 02 和 01 的差异,得到:
entity_tag_20220802_differ.txt
(3)增量处理
针对差异文件,进行增量的处理。
当然,第一次的时候,需要进行全量文件的解析处理。
小结
每一个业务需求,都会有多种方式去实现。
有时候因为时间和考虑不周全,会导致方案有一些问题。
多思考,并且逐步优化,找到适合业务的场景才是最重要的。
我是老马,期待与你的下次重逢。
