概要
自动识别文件的两个版本之间的差异是采矿代码存储库的几个应用程序中的常见和基本任务。
GIT是一种版本控制系统,具有差异实用程序,用户可以选择从默认算法Myers到高级直方图算法的差异算法。
从我们的系统映射中,我们在最近的研究中确定了DIFF的三个流行应用。
关于14个Java项目中代码流失指标的影响,我们根据不同的差异算法获得了1.7%至8.2%的不同值。
关于错误引入的变更识别,我们发现已确定的错误框架提交中有6.0%和13.3%的介绍在10个Java项目中的错误引入更改的结果不同。
对于补丁应用程序,我们发现直方图比迈尔斯更适合通过手动分析提供代码的更改。
因此,我们强烈建议在挖掘GIT存储库时使用直方图算法(Histogram algorithm)来考虑源代码的差异。
介绍
DIFF实用程序计算并显示两个文件之间的差异,通常用于研究同一文件的两个版本之间的更改。
由于在经验软件工程研究中了解和衡量软件伪像的变化至关重要,因此DIFF通常用于各种主题,
例如在缺陷预测中,代码流失(Nagappan和Ball 2005; Shin等人,2011年)和过程指标(Hata等人。2012; Madyyski和Jureczko 2015; Kamei and Shihab 2016),代码作者身份(Rahman and Devanbu 2011; Meng etal。2013),克隆家谱(Kim etal。2005; Duala-Ekoko and Robillard 2007)和经验性变化的研究(Barr等人,2014年; Ray等人,2015年)。
随着GITHUB的增长,最近的研究还使用GIT命令分析了软件从GIT存储库中的变化。
Git是一种版本控制系统,为用户提供了差异实用程序,以选择diff的算法。
GIT提供四种差异算法,即迈尔斯,最小,耐心和直方图。(Myers, Minimal, Patience, and Histogram. )
没有识别算法,迈尔斯(Myers)被用作默认算法。
在文本差异中,所有差异算法在生成差异输出时在计算上都是正确的。但是,由于不同的差异算法,有时DIFF输出有时不同。
不同的DIFF算法可能会识别不同的变化块,即,删除或连续添加的程序语句列表,至少由一条不变的上下文分开(Ray等人,2015年)。
我们希望开发人员完成的一系列变化的操作可以由变更帅哥代表。但是,可能会有不适当的识别。尽管2011年GIT 1.7.7footnote1中引入的直方图可能会为GIT差异提供更好的性能,但在软件工程师社区中并不流行。因此,我们专注于Myers和直方图算法,以经验研究对软件工程研究的影响。这项研究的动机试图阐明采用不同的差异算法对经验研究的影响,并研究哪种差异算法可以提供更好的差异结果,这些结果可以预期恢复不断变化的操作。此外,我们的研究提供了迈尔斯和直方图生成差异的全面程序,并显示了其产出之间的差异。
据我们所知,GIT DIFF命令中不同差异算法的经验比较从未进行过。
在本文中,我们进行了两个顺序分析:系统的映射和经验比较(systematic mapping and empirical comparisons.)。
对于系统的映射,我们从2013年至2017年发表的三个高级期刊和八个顶级国际会议记录中收集论文。
然后,我们在以下四个方面中绘制了52份识别论文:DIFF算法的频率,分析的软件文物,目的是挖掘GIT的目的 存储库和数据起源。
系统映射的结果表明,先前的研究未考虑高级差异算法。
就GIT命令的重点而言,在挖掘代码更改的52篇论文中,有51个。
我们还发现,使用GIT命令的目的是获取补丁(46.2%),其次是指标收集(25%),以及引入更改识别(SZZ算法)(23.1%)。
关于数据集,大多数论文研究了OSS项目(98%),即使其余工作分析了工业数据。
在我们的经验分析中,我们根据在映射研究中发现的最流行的GIT差异用法进行了三个比较:收集指标,识别错误介绍和获取补丁。
我们研究了两种差异算法之间的分歧:迈尔斯和直方图,并在生成差异列表时对其质量进行手动测量。
基于以前的相关研究,我们研究了14个OSS项目中文件中的代码更改,这些项目采用了指标收集的连续集成和10个用于错误简介标识的Apache项目,以量化两种差异算法产生的差异输出的差异。
我们通过手动比较了377个变化的两种差异,分析了从迈尔斯(Myers)得出的斑块的质量,这是上述两个比较中确定的21,590个变化的统计代表性样本。
我们的发现表明,在GIT DIFF命令中使用各种差异算法产生的不等性差异列表。
这会影响每个 CI-Java 项目中添加和删除不同代码行的文件数量不同。
这些添加和删除的行以不同的数量和位置来区分,差异分别在0.8%到6.2%和1.4%到7.6%之间。
不同的 diff 输出也影响了错误引入识别中识别文件的不同数量。
具有不同删除代码行的文件的百分比范围从 2.4% 到 6.6%。
关于补丁分析的结果,我们发现,在代码更改中,直方图在 62.6% 的文件中更好,而 Myers 在 16.9% 的文件中更好。
但是,两种 diff 算法在生成非代码更改列表方面均具有良好的质量。
总之,这项工作的贡献是:
-
对使用差异的研究的系统调查;
-
对从 Myers 和 Histogram 产生的差异输出中收集的指标进行分析;
-
分析 Myers 和直方图输出以识别潜在的引入错误的更改;
-
Myers 和 Histogram 之间的手动比较以调查其输出质量
本文的其余部分结构如下。
第 2 节介绍了文献中各类 diff 算法的应用。
第 3 节简要介绍了 git 命令中使用的差异算法。
我们解释了两种 diff 算法在生成更改列表时的区别。
第 4 节描述了我们如何进行系统的制图研究并展示调查结果。
第 5 节介绍了三个比较和研究问题的概述。
第 6、7 和 8 节报告了我们的程序并讨论了它们在执行三个比较研究中的结果;
即分别收集指标、识别错误引入和获取补丁。
在第 9 节中,我们讨论了不同 diff 算法的含义并提供了示例,并讨论了它们对有效性的威胁,最后我们在第 10 节中得出结论。
源代码差异
现有的差分技术使用名称和结构的相似性来匹配特定粒度的代码元素,例如基于文本和基于抽象语法树 (AST)。
如今,基于树的差分技术被广泛使用(例如,Unix 中的 diff),因为预计它们比基于文本的差分技术具有更好的可理解性。
这种 AST 差异工具被用于几项研究。例如,Change Distilling (CD) 通过查找比较的两个抽象语法树的节点之间的匹配和最小编辑脚本来提取代码更改,该脚本可以在计算匹配的情况下将一棵树转换为另一棵树(Fluri 等人。 2007)。
在这项研究中,基于文本的差异用于提取过程开始时的变化作为输入,然后使用提出的 AST 算法进行进一步处理。与文本差异相比,Change Distiller 能够分配更改的类型,例如方法的声明或主体部分,而不仅仅是行号。
Diff/TS (Hashimoto and Mori 2008) 和 MTDIFF (Dotzler and Philippsen 2016) 使用移动代码来计算变化。
Diff/TS 用于分析程序版本之间的细粒度结构变化,但只能处理 Python、Java、C 和 C++ 项目,而 MTDIFF 提高了以前基于树的方法检测移动代码的准确性。 Falleri 等人。
(2014)引入了一种算法来计算抽象语法树粒度的编辑脚本,包括移动动作。
在这项研究中,作者进行了一项性能研究,以测量他们提出的算法与其他工具(如 GumTree 和 RTED 算法)之间的运行时间和内存消耗。
在比较所涉及算法之间的运行时间时,使用经典文本差异来呈现参考值。 Higo 等人也使用了基于树的差分方法。
(2017) 将复制和粘贴视为一种编辑动作,形成基于树的编辑脚本,以及 Huang 等人。
(2018) 提出 CLDIFF 用于生成简洁的链接代码差异,其粒度介于现有代码差异和代码更改摘要方法之间。
尽管基于树的差异技术有许多优点,但基于文本的差异由于其简单性和轻量级运行时而被广泛用于软件工程研究中的多个应用程序。
因此,在本文中,我们只专注于研究改变 diff 算法的影响,而不是比较更广泛类别的差分技术。
Git中的差异算法
Diff 是一个自动比较程序,用于查找存储中同一文件的旧版本和新版本之间的差异(包括插入、删除、文档重命名、文档移动等)。
diff 实用程序在一个文件中逐行提取与另一个文件相比的代码更改,并在列表中报告它们。
diff 程序的操作已经通过使用 Hunt 和 MacIlroy (1976) 提出的最长公共子序列 (LCS) 问题得到了根本解决。
自 1970 年首次在 Unix 操作系统上运行以来,diff 命令已广泛用于许多研究。
git diff 命令在代码更改提取的应用程序中有许多选项,脚注 3 包括提取与索引和提交、文件系统上的路径、对象的原始内容相关的更改,甚至量化每个对象的更改数量相对于 来源。
研究人员和从业者可以根据提取数据的需要使用这些可用选项的变化,更不用说差异算法了。
diff 算法的本质是对比两个序列,并通过使用有序删除和插入的一系列操作来了解从第一个序列到第二个序列的转换。
如果删除和插入在同一范围内发生,则可以将子序列标记为更改。
可以使用此选项 --diff-algorithm=<algorithm> 选择 diff 算法。
在 Git 中,有四种 diff 算法,即 Myers、Minimal、Patience 和 Histogram,用于获取位于两个不同 commit 中的两个相同文件的差异。
Minimal 和 Histogram 算法分别是 Myers 和 Patience 的改进版本。
每种算法都有自己的程序来查找原始文档中出现的项目,但在第二个中没有,反之亦然; 因此,可能会产生不同的产出。
由于 Minimal 和 Histogram 算法的基本思想与它们的前身相似,本文只对比了 Myers 和 Histogram 这两种 diff 算法。
Myers
Myers 算法由 Myers (1986) 开发。
在 git diff 命令中,默认使用此算法。
该算法的操作使用最少编辑的脚本递归地跟踪两个主要的相同序列。
由于 Myers 只注意到两者实际上相等的序列,因此对于整个剩余序列重复执行其他先验子序列和后验子序列之间的比较。
图 1 表示从 Openmicroscopy 项目中提取的同一文件 (GuiCommonElements.java) 从第一个版本到第二个版本的几个代码更改。
脚注 4 如图所示,第一个版本中的第 673 和 689 行之间的代码转换为第 673 行和第 693 行之间的较新版本。
图 2 显示了 Myers 算法如何从图 1 中的代码更改生成差异输出。
首先,Myers 从同一文件的两个版本的第一行开始顺序扫描代码行,以找到相互匹配的线对。
一旦算法找到文件的两个版本之间完全相同的行,这些行将被视为未修改的行(例如,图 2a 中两个版本中的第 673-675 行对)。
然后,该算法执行相同的扫描以重复提取其余代码行的其他匹配行对,如图 2b 和 c 所示。
在图 2c 中,我们可以看到 Myers 算法找到的所有未修改的行:两个版本中的第 673-675 行对,第 1 版中的第 679 行和第 2 版中的第 677 行,681 和 680,683 和 685,684 和686、686 和 687,以及 687 和 688)。版本 1 中未配对的行随后被视为删除行,而版本 2 中未配对的行被视为添加行。
因此,Myers 算法从同一文件的第一和第二版本中按顺序生成配对和不配对的行,如图 4a 所示。
- FIG.1

A set of changes from an older file into a newer file
- FIG.2

How Myers identifies the diff
Minimal 算法是 Myers 的扩展版本。
该算法在查找变化方面的操作是通过比较两个类似于 Myers 的对象而产生的,但进行了额外的尝试以使补丁大小尽可能小。
脚注 5 结果,使用此算法创建的差异列表是 通常与迈尔斯相同。
如果我们将 Minimal 算法应用于图 1 中的代码,则差异输出也显示在图 4a 中。
Myers 算法的一个主要限制是它经常捕获空行或括号并匹配行以匹配而不是捕获“唯一”行(即在两个版本中只出现一次或最少出现的行),例如函数声明代码或赋值行。
因此,Myers 有时会产生不明确的差异列表,这些列表没有描述实际的代码更改。更改的代码和替换它们的代码之间的位置通常写在不适当的行中,或者单独位于不代表修改的行中。
此外,有时会出现更改代码的标识冲突;例如,图 4a 中第 4 行和第 15 行中的代码。事实上,这些代码行源自未修改的同一行。
使用 Myers 算法,即使没有显示更改,该唯一行也会被检测为更改的代码。这使得可能导致错误识别代码更改。
Myers 算法的一个主要限制是它经常捕获空行或括号并匹配行以匹配而不是捕获“唯一”行(即在两个版本中只出现一次或最少出现的行),例如函数声明代码或赋值行。
因此,Myers 有时会产生不明确的差异列表,这些列表没有描述实际的代码更改。更改的代码和替换它们的代码之间的位置通常写在不适当的行中,或者单独位于不代表修改的行中。
此外,有时会出现更改代码的标识冲突;例如,图 4a 中第 4 行和第 15 行中的代码。
事实上,这些代码行源自未修改的同一行。使用 Myers 算法,即使没有显示更改,该唯一行也会被检测为更改的代码。这使得可能导致错误识别代码更改。
直方图
直方图算法是 Patience 的增强版,由著名的 BitTorrent 开发者 Bram Cohen 打造。
脚注 6 它支持低出现率的常用元素,用于提高效率。
直方图最初是在 jgitFootnote 7 中构建的,并在 git 1.7.7 中引入。
Patience 通过关注出现次数最少但必不可少的行来标记文本中的重要行。
这个 diff 自动化过程也是一个基于 LCS 的问题,但它使用了不同的技术。
耐心只注意到从在特定范围内唯一出现的行以及在两个文件中也写得非常相似的行中获得的标记行的最长公共子序列。
这意味着具有单个括号或新行的行通常被忽略; 否则,Patience 会保留独特的线条,例如函数定义。
直方图策略的工作方式与耐心相似,通过为文件的第一个版本中的每一行开发外观直方图。随后显示第二个版本中的每个元素以有序的方式与第一个序列匹配,以查找元素的存在并计算出现次数。如果元素存在并且它们的存在比第一个序列中的少,则它们有望成为潜在的 LCS。一旦第二个序列的筛选完成,LCS 的最低出现被标记为分隔符。分割产生的两个部分(即部分 1 表示 LCS 之前的区域,而部分 2 表示 LCS 之后的区域),然后使用与算法开始相同的过程重复执行。这意味着如果两个文件中都存在唯一的共同元素,则直方图的表现与耐心相似;否则,它会选择出现次数最少的元素。与其他两种 diff 算法(即 Myers 和 Patience)相比,直方图的声明速度要快得多。脚注 8
为了容易理解直方图生成图 1 的差异输出,我们描述了图 3 中的过程。首先,直方图扫描文件第一个版本中的所有元素以计算每一行的出现次数。提取第二个版本中的每一行以与第一个版本中的元素顺序匹配,以找到完全相同的行并计算出现次数。如果算法发现两个版本中的行匹配并且它们的存在是唯一的(即仅出现一次或在两者中出现最少),则将它们视为潜在的 LCS,然后将其标记为分隔符。如图 3a 所示,两个版本中的第 674 行都被标记为第一个分隔符。本次切片后会产生两个子段,即分隔符前后的区域。在这些小节中,算法会找到更多独特的配对;当算法考虑一个子部分时,扫描整个文档时不唯一的行可能是唯一的。然后将相同的过程应用于两个子部分。直方图比较了两个版本中上部的第 673 行,以及下部的版本 1 中的第 675-689 行和第 2 版中的第 675-693 行。由于 673 行在两个版本中仅在上部出现最少,因此,该行有望成为第二个分隔符。在下部,扫描过程从头开始重新执行。如图 3b 所示,该过程产生一个新的分隔符(即版本 1 中的第 676 行和版本 2 中的第 682 行)和两个新的子部分(即版本 1 中的第 675 行和版本 2 中的第 675-681 行)上部分,第 1 版中的第 677-689 行和第 2 版中的第 683-693 行作为下部分)。随后对分区产生的两个新子部分重复执行相同的过程。图 3c 显示了比较两个版本中的所有元素后的最后一步。所有被标记为分隔符的潜在 LCS 都应该是未修改的行,而其他行被认为是版本 1 中的删除行和版本 2 中的添加行。因此,生成差异输出,如中所述图 4b。
- FIG3
How Histogram identifies the diff

差异对比:
- FIG4
Diff outputs produced by Myers and Histogram

与 Myers 相比,直方图算法提供的差异结果更容易让软件档案矿工理解,因为直方图更清楚地区分了更改的代码行。该算法通过尝试匹配同一文件的两个版本之间的唯一行来拆分更改的代码行。
因此,它将减少冲突的发生(即,将一行未更改的代码标识为更改的代码,以便在差异列表中,此代码作为删除和插入的代码重复写入)。
例如,如果我们使用 git diff 命令中的直方图提取图 1 中同一文件的两个版本之间的差异,我们将获得如图 4b 所示的输出。图 4b 的第 10 行中的唯一代码行没有被检测为更改代码,因为它作为与该行匹配的基准,其中该行在 Myers 的情况下被识别为更改代码。这会影响其他更改代码的序列。在第 4 行和第 9 行之间应该放置一个额外的 if 条件块。这块代码清楚地理解为在赋值代码语句之前插入的新代码(第 10 行中的代码,用作一些唯一要匹配的行之一)。同样明显的是,第 12 行和第 16 行之间的代码被第 17 行中的一行代码替换,而文件中省略了第 20 行中的右花括号,以及三行新代码(第 23、24 和 25 行) ) 被添加到图 4b 中代码的末尾。
系统映射:以前的研究如何使用 Git Diff?
为了了解以前的研究使用 diff 的方式,我们对使用 git diff 命令进行研究的论文进行了系统映射。
正如彼得森等人所述。 (2008 年),系统映射研究可以通过对同一研究领域内与研究兴趣相关的出版物数量进行分类和量化来提供和可视化研究领域的统计洞察力。该方法的主要活动是从广泛的出版物中搜索相关文献,包括期刊文章、书籍、文档档案和脚本。
我们进行了系统的映射,因为我们打算:
(i)通过结构化的方式量化来概述研究领域(Kuhrmann et al. 2017),
(ii)确认当前发表的研究中的知识(Petersen et al. 2015)。
系统映射是可靠的,因为研究结果在整个时间段内可重复且一致(Wohlin 等人,2013 年),并且它们有利于更好地报告初步研究的一些实证结果(Budgen 等人,2008 年)。
为了了解最近的研究如何使用 git diff,我们为这个系统映射准备了以下研究问题。
-
使用哪种差异算法?
-
分析什么样的软件工件,代码或其他文档?
-
使用差异的目的是什么?
-
数据源来自哪里,OSS还是行业?
程序
图 5 说明了我们的系统映射过程的概述,该过程分为初始阶段和高级阶段。
第一阶段包括三个步骤,包括数字图书馆选择、论文收集、搜索字符串定义和初始搜索执行。
第二阶段从通过缩小搜索词和阅读全文开始重复的手动排除,然后是论文分类和统计分析。
- FIG5
Design of the survey procedure
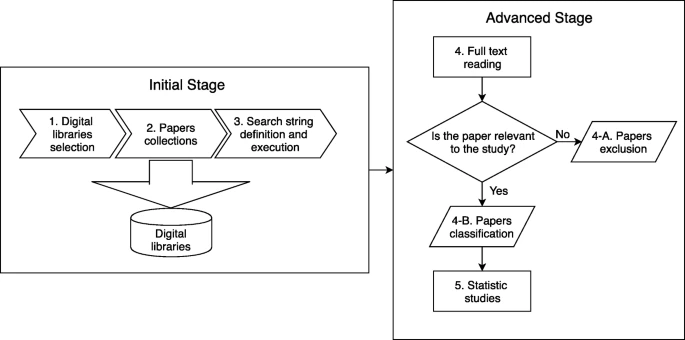
步骤1 数字图书馆选择。
选择合适的文献对于保证高质量的论文和掌握软件工程领域的最新问题至关重要(Kavitha 2009)。
我们专门针对在软件工程领域的高级期刊和会议论文集中发表的论文。
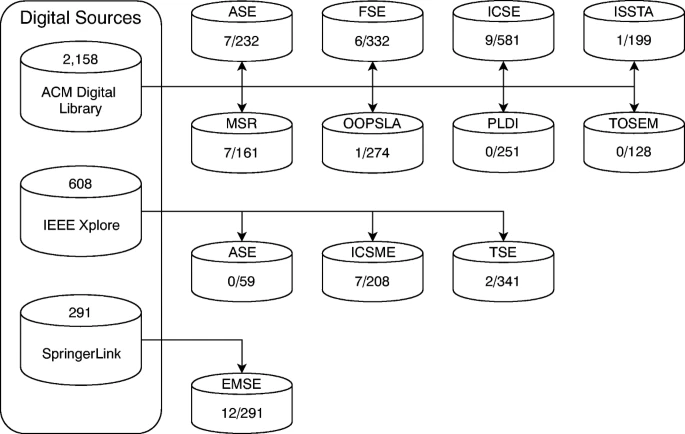
为了最大限度地提高找到高度相关的优质文章的可能性,我们使用了三个特定的数字资源:ACM 数字图书馆、脚注 9 IEEE Xplore、脚注 10 和 SpringerLink。
脚注 11 表 1 显示了我们调查中使用的出版物来源列表,包括它们 影响因子 (IF) 脚注 12 和 2018 年 CORE Rankings 中发布的排名。
脚注 13 我们收集了 2013 年至 2017 年间这三个数字来源的已发表论文。
第2步 论文集。
为了减少研究背景下的偏见,我们只收集了技术论文。
不符合我们标准的论文(即少于 10 页的论文、社论、小组、海报会议和意见)被排除在外。
如图 6 所示,通过应用我们的标准,我们在 5 年的时间跨度内从三个数字资源中总共获取了 3,057 篇论文。
- FIG6
Number of collected papers from each source
第 3 步 搜索字符串定义和执行。
在这一步中,我们制定了搜索关键字,将目标论文过滤成使用 git diff 命令的更具体的作品。
我们定义了三个与命令相关的特定搜索词,即 git、log 和 diff。
收集了包含三个单词之一且没有词缀或后缀的完全匹配的论文(例如 github、博客、对数、日志记录、不同、困难等)。
由于我们只关注在 git 存储库中使用 diff 命令的研究,因此排除了未完全提及至少三个关键字之一的论文,尽管它们使用了其他术语,例如差异,这可能表明其他 diff 工具的实现。
命令 git log 也是目标,因为该命令可以产生带有特定选项的差异。
通过使用这三个搜索词,从数据库中提取的所有论文都被手动扫描为全文。因此,仅包含包含这三个搜索字符串的已发表作品。
作为第 3 步的结果,我们能够识别出 137 篇论文。
第4步 全文阅读。
为了确保收集的先前研究与我们的目标相关,我们随后对论文进行了全文阅读。
这一过程由第一作者和第二作者进行,以避免晦涩难懂,并根据其内容更详尽地区分主要研究。
我们将包容性和排斥性标准应用于表 2 中描述的全文。符合包容性标准的论文被保留以供进一步处理,而其他符合排斥性标准的论文被排除在研究之外。
在这一步之后,我们有 52 篇论文。
映射结果
图 7 显示了过去 5 年每个期刊和会议的论文数量分布。
从热图中可以看出,除PLDI和TOSEM外,所有期刊和会议论文集在5年内至少发表了一篇论文中与git diff命令应用相关的作品。
应用 git diff 命令的论文大多发表在 EMSE 上,尤其是 2017 年,占 6 篇。
- FIG7
Number of papers per journals and conferences between 2013 and 2017
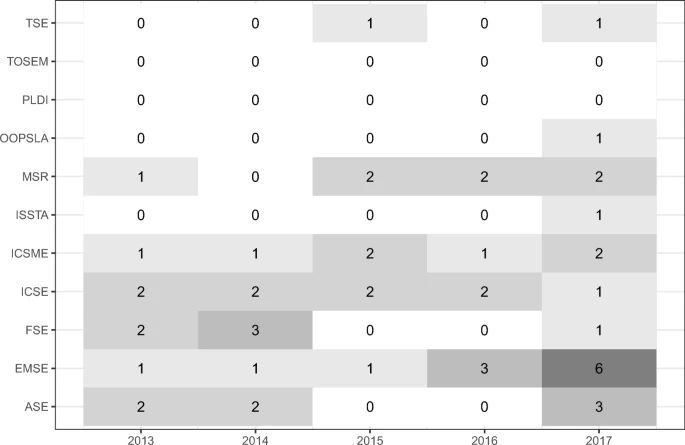
使用哪种差异算法?
在 52 项主要研究中,我们确定了命令中不同差异算法在提取更改中的应用。
特别值得注意的是,尽管大多数指令在使用 git 命令来提取所需数据时应用了不同的选项,但之前选择的作品都没有考虑不同的差异算法。
这表明所有收集的研究都使用 Myers 作为默认算法。
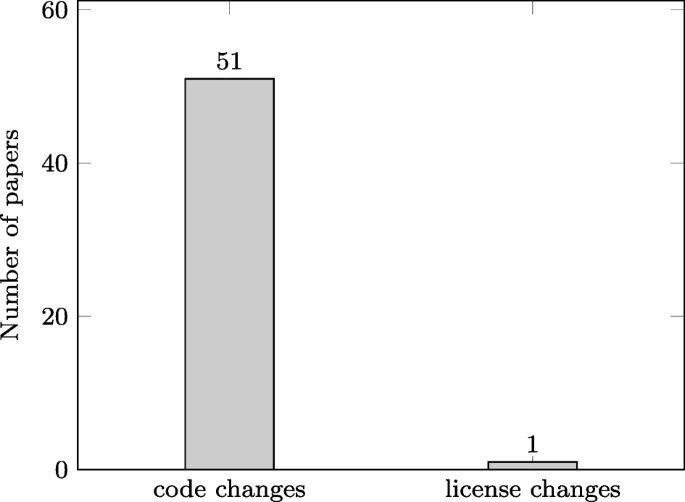
分析了什么样的软件工件?
为了理解在之前的研究中使用 git 命令提取的组件,我们主要关注两个焦点作为我们对文档进行分类的参数;
即代码更改和许可证更改,如图 8 所示。
从图中可以看出,代码更改是研究人员在过去五年中使用 git 命令提取软件存储库的主要重点。
因此,在我们的比较中,我们分析了从数据源中提取的代码更改。
- FIG8
Number of papers based on parameter searched using git command
使用差异的目的是什么?
通过手动阅读论文,我们总结了提取软件开发记录的目的,并将它们分为五类,如图 9 所示。
- FIG9
Number of papers classified with the purpose of using the git command
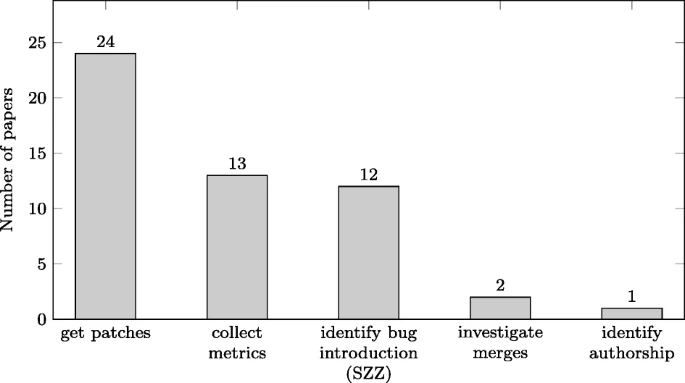
从图中我们看到,最常见的目的是获取补丁,多达 24 项研究,其次是收集指标和识别 bug 介绍,分别涵盖 13 项和 12 项研究。
一些研究涉及合并调查和作者身份识别。
这一发现促使我们进一步调查不同差异算法在提取用于度量收集的添加和删除行、引入错误的更改识别和获取补丁方面的影响。
数据源从何而来?
我们的目的是全面了解不同 diff 算法产生的不同结果; 因此,我们需要在 git diff 命令中运行一组算法实现测试。
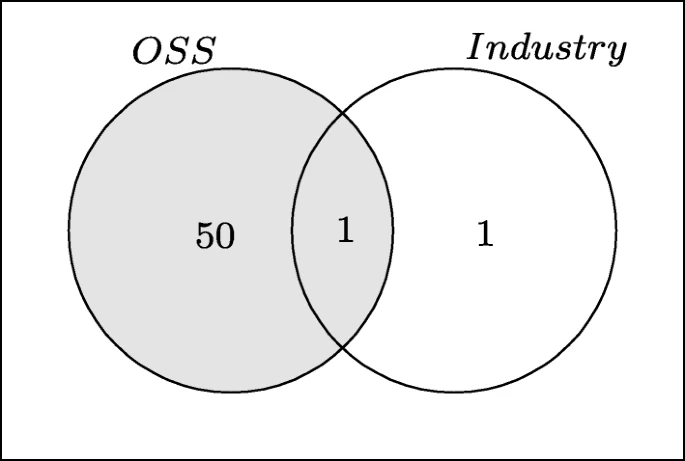
从我们的数据集分类结果来看,开源软件(OSS)被认为是工业类型的主要数据源,如图 10 所示。
因此,我们从 OSS 项目中挖掘数据以支持我们的比较。
- FIG10
Distribution of the type of data sources used in prior studies
概括
git diff 命令使用情况的调查结果证实,之前在 2013 年至 2017 年间进行的研究没有使用各种 diff 算法来提取同一文件的第一和第二版本之间的差异。
在挖掘差异列表时,他们使用带有一些附加选项的默认差异算法应用标准命令,但没有考虑各种差异算法。
我们还发现,之前研究中最需要的信息是开源项目中的代码更改。
代码更改主要用于彻底调查计算行更改的数量并以度量的形式记录它们,使用特定方法(即 SZZ 算法)定位错误的根源,并分析补丁。
这些类型的分析结果显然依赖于 git diff 命令中应用的 diff 算法产生的 diff 记录。
因此,提取代码更改行的不同差异算法可能会区分研究的最终结果和描述的结论。
比较和研究问题概述
我们系统映射的结果揭示了使用 git diff 命令的三个最常见目的。
这鼓励我们在三个应用程序中对 Myers 和直方图算法进行比较分析:指标、SZZ 算法和补丁。
我们的目的是调查这三个应用程序中使用的两种 diff 算法之间的差异程度以及它们影响研究结果的可能性。
为了实现这些目标,我们解决了以下研究问题:
问题 1:diff相关指标的值会因为不同的diff算法而变得不同吗?
对于度量(第 6 节),由两种 diff 算法识别的文件中相等和不相等的更改行是基于两个因素计算的:代码行的数量和位置。
然后我们比较了添加和删除代码行相同和不同的文件的数量,以了解两种算法在提供差异记录方面的差异的重要性。
问题 2:由于不同的差异算法,引入错误的更改识别的结果是否不同?
使用 SZZ 算法定位引入错误的更改的结果依赖于差异结果。
在第 7 节中,我们在 git diff 命令中应用了 Myers 和直方图算法,以了解 diff 列表是否影响引入错误的更改识别的结果。
问题 3:哪种 diff 算法在生成好的 diff 方面更好?
最后,我们手动比较了已识别补丁的质量。
在第 8 节中,我们调查了 377 个变化,这是在上述两次比较中确定的 21,590 个变化的统计代表性样本。
在我们的三个比较中,为了提取更改,我们应用了 git 命令:git diff -w --ignore-blank-lines --diff-algorithm=<algorithm> <parentcommit ID> <commit ID> -- <filename>。
我们使用相同的选项 -w 和 –ignore-blank-lines 来忽略空格和行都是空白的更改。
根据 diff 命令生成代码更改的目的,各种选项的使用很常见。
但是,由于我们的重点是将 Myers 和 Histogram 作为可在相同情况下使用的 diff 算法进行比较,因此我们不考虑调查其他选项的影响。
比较:指标 (RQ1)
RQ1:diff相关指标的值会因为不同的diff算法而变得不同吗?
分析设计
如图 11 所示,我们使用两种 diff 算法研究以下两个基本的 diff 相关指标:Myers 和 Histogram。
- FIG11
Overview of the metrics collection procedure
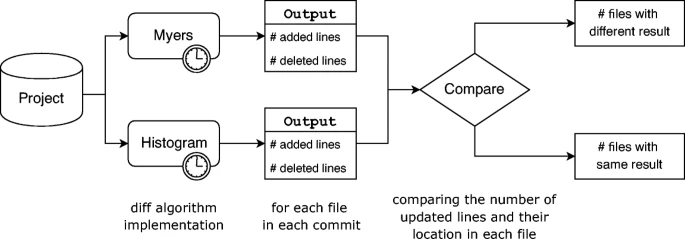
NLA: The number of added lines in a file.
NLD: The number of deleted lines in a file.
对于我们的实证分析,我们收集了之前研究中使用的 14 个项目的 Git 存储库(Rausch 等人,2017 年),这些项目在我们的系统映射中被确定为使用 git 收集指标的研究。
目标 14 个项目是采用持续集成 (CI) 并用 Java 编写的 OSS。
项目描述及master分支提交次数见表3
我们调查了主分支中所有提交中的所有修改文件。为了从文件中提取 NLA 和 NLD,我们实现了 git 命令:
git diff -w --ignore-blank-lines --diff-algorithm=<algorithm> <parent commit ID> <commit ID> -- <filename> .
如果两种算法的 NLA 和 NLD 的值相同,我们认为结果相同;否则,结果被认为是不同的。
然而,一些依赖这些度量的软件工程任务没有考虑添加和删除行的位置,尽管度量值相同,但更改行的不同位置可能是偶然发生的。
我们推测,改变线的不同数量和位置会对实证研究产生不同的影响。因此,我们分别调查了已识别更改位置的分歧。
如果每行更改的代码的位置相同,我们认为结果相同;否则,结果被认为是不同的。讨论文件级别和提交级别的结果,以了解不同的结果如何以不同的粒度出现。
我们看到不同指标值的百分比在 0.8% 到 6.2% 之间。
考虑到变化位置的不同结果,范围从 1.4% 到 7.6%,我们发现即使识别的位置不同,也有相当多部分的度量值是相同的。
为了进一步探讨 Myers 和 Histogram 之间的分歧,我们计算了受不同代码更改次数和文件差异输出中位置影响的提交次数。
在每个项目中,我们计算了具有相同和不同数量的文件的总和,以及在整个项目中的每次提交中插入和删除的行的位置。一个提交可能包含多个修改的文件。
如果一个提交记录了至少一个文件在数量或位置上具有不相等的代码更改行,我们将此提交归类为“不同”。
另一方面,如果提交中的所有文件都有相同的更改行,我们将提交归类为“相同”类。在这个过程中,我们只通知代码行数和位置不相等的文件。
我们的结果表明,受更改行影响的几个更改文件具有相似的提交。
我们将这几个包含不同更改代码行的文件中的相同提交分组到单个提交中。
然后,我们总结了由于在 git diff 命令中使用 Myers 和直方图算法而导致的具有不同数量和位置的更改代码行的提交百分比,如表 5 中所述。
一般来说,我们的比较表明,在命令中使用两种 diff 算法进行的数据提取为所有提交中的大多数文件生成了相同的 diff 列表。
然而,即使提交中每个文件的输出都以相同的结果为主,Myers 和直方图的差异输出记录了几个具有不同添加和删除行的文件。
这些分歧影响了不同数量的提交,这些提交的文件包含更改的代码行。
受代码行数影响的提交数量差异水平足够高,范围从 1.7% 到 8.2%,而行的不等位置影响提交数量的差异水平从 2.8% 到 13.9 %。
概括
度量比较的结果提供了明确的证据,表明使用多种形式的差异算法可能会区分差异列表。
由于度量对变化位置的差异不敏感,因此即使识别的变化位置不同,也可以获得相同的值。
但是,我们看到在文件级别从 0.8% 到 6.2% 以及在提交级别从 1.7% 到 8.2% 获得了不同的度量值。
这些差异可能会对使用差异相关指标的研究产生影响。
比较:SZZ 算法 (RQ2)
RQ 2 : 由于不同的 diff 算法,引入 bug 的更改识别结果是否不同?
SZZ 算法
Śliwerski 等人提出的 SZZ 算法。
(2005) 是一种识别引入错误的更改的方法。
SZZ 使用错误跟踪系统(例如 Bugzilla)作为链接存档版本的软件(例如 CVS)的参考。
图 12 描述了 SZZ 算法的基本思想。
- FIG12
SZZ: Locating bug-introducing changes
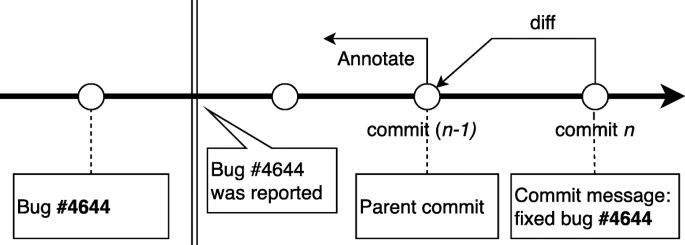
SZZ 算法首先通过在日志消息中搜索错误报告标识号(错误 ID)来识别错误修复提交,这些标识号是开发人员在修复错误时编写的。
此错误修复提交的提交 ID 随后用于跟踪先前的提交(父提交)。
通过应用差异来提取代码更改以查找父提交中文件的旧版本与错误修复提交中同一文件的新版本之间的差异。
识别出的删除行被认为是与错误相关的行的候选。
为了识别引入错误的提交,使用 cvs annotate 命令来调查何时添加了行。
在 bug 相关行的候选中,在 bug 报告时间之前创建的行被认为是经过验证的 bug 相关行。
引入那些经过验证的与错误相关的行的提交被标识为引入错误的提交。
分析设计
图 13 描述了我们分析的验证过程。
对于我们的实证分析,我们研究了之前研究中使用的 10 个开源 Apache 项目(da Costa et al. 2017),这在我们的系统映射中被确定为一项利用 Git 使用 SZZ 算法识别错误引入的研究。
项目描述和master分支的commit数量如表6所示。我们分析了使用不同的diff算法对原始SZZ算法的影响。
我们研究了基于 diff 的 SZZ 算法结果中 Myers 和 Histogram 的不一致。
- FIG13
Overview of the validation process of bug-introducing commit
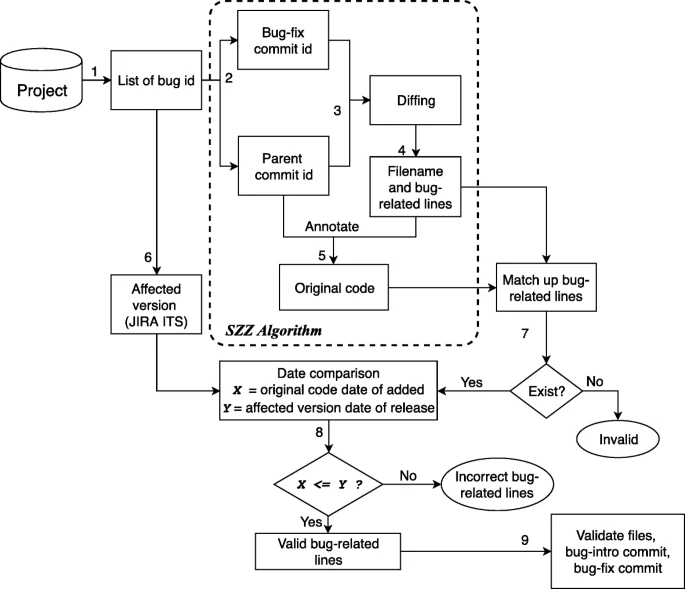
首先,使用特定关键字(即“bug”、“fix”、“defect”和“patch”(Śliwerski et al. 2005))搜索提交消息中的错误报告 ID,然后将识别的提交标记为候选 错误修复提交。
在每个候选的错误修复提交中,我们专注于修改后的文件。
两种 diff 算法用于使用以下命令识别已删除的行:
git diff -w --ignore-blank-lines --diff-algorithm= <algorithm> <parent commit ID> <bug-fix Candidatecommit ID> -- <filename >。
通过获取父提交 ID 中的文件,我们随后应用 git blame 命令(类似于 cvs annotate)来定位被删除行的来源。
那些被删除的行被认为是与错误相关的行的候选。
类似于 da Costa 等人的程序。 (2017),下一步是查找受影响的软件版本的错误。我们从 JIRA 问题跟踪系统中提取错误报告及其受影响的版本。脚注 14 如果单个错误 ID 影响多个版本,则选择最早的版本,因为 SZZ 算法针对错误的初始外观。从受影响版本的集合中,我们将引入 bug 相关行的候选行的日期与版本的发布日期进行比较。如果受影响版本的发布日期晚于 bug 相关行候选的引入日期,我们将其归类为有效的 bug 相关行;否则,我们将它们归类为无效。
使用这些有效的错误相关行集,我们可以验证引入错误的提交、错误相关的文件和修复错误的提交。验证过程以与上述过程相反的方向执行。有效的引入错误的提交是最初添加有效的错误相关行的提交。包含错误相关行的文件被认为是有效的错误相关文件。从 bug 修复提交的候选者中,如果至少有一个有效的关联 bug 引入提交,我们认为候选 bug 修复提交是有效的,否则无效。
结果
表 7 显示了 Myers 和直方图算法的输出,包括有效的错误相关行、文件、引入错误的提交和错误修复提交的数量。
两种算法在所有 10 个项目中产生了不同数量的有效错误相关行,这导致了不同数量的文件、引入错误的提交和错误修复提交。
与第 6 节中的指标分析类似,由于更改位置的不敏感性,某些项目的更改数量差异相对较小或相同。
由于调查 bug 引入的位置也很重要,我们对具有相同和不同位置的 bug 相关行的文件进行比较。
表 8 显示了该结果。
可以看出,每个项目中修改代码位置不同的文件总数都很高,从2.4%到6.6%不等。
这意味着某些文件可能包含可疑的错误相关行,只是因为算法不同。
将这些数据进行进一步分析,然后我们总结了有效的错误修复提交的数量。
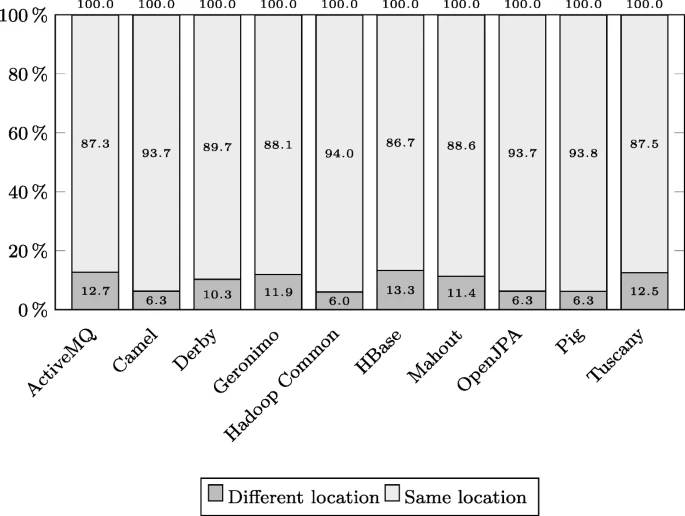
如图 14 所示,所有研究的项目都有不同数量的有效错误修复提交,这是由 Myers 和直方图产生的有效错误相关行的不同位置引起的。
不同结果的百分比在 6.0% 到 13.3% 之间,平均为 9.7%。
该分析发现有证据表明,近 10% 的错误修复提交并不能保证成功定位引入错误的更改,因为如果我们在 git diff 命令中应用不同的 diff 算法,一些被怀疑为候选引入错误的更改的已删除行是不同的 . 这是因为文件中与错误相关的有效行有可能被特定的 diff 算法识别,但在使用其他 diff 算法时它仍然未被检测到。
- FIG14
The percentage of valid bug-fixing commits that have the same and different positions of valid bug-related lines
概括
SZZ 算法的结果证实,不同的 diff 算法可能会产生不同的结果,在已识别的错误修复提交总数中分别占 6.0% 和 13.3%。
Myers 和直方图有时会在多个文件中生成不同数量和位置的已删除行(与错误相关的行)。
这些差异肯定会影响包含错误相关行的分歧文件的数量、引入错误的提交的数量以及实际上具有包含错误的文件的错误修复提交。
因此,比较结果表明,先前使用 SZZ 算法定位错误的几项研究有可能产生不准确的分析。
比较:补丁(RQ3)
RQ 3:哪种 diff 算法在生成好的 diff 方面更好?
分析设计
从前面的两个比较中,我们发现不同的 diff 算法可以有不同的度量收集和错误引入识别(SZZ 算法)的结果。
在计算上,两种 diff 算法在文本差异中都是正确的。
但是,由于不同的 diff 算法,diff 输出有时会有所不同。
差异结果可能会显示不同的更改区域,其中包含一个连续的删除和添加行列表,称为更改块 (Ray et al, 2015)。
我们期望开发人员完成的一组更改操作可以用更改块来表示。
但是,更改大块的识别可能是不合适的。
在我们的调查中,无法自动识别此问题。
因此,我们手动分析 diff 的质量。
为了判断 diff 算法的质量,如果算法满足我们的两个标准,我们定义为“更好”:
(i)它适当地检测不应该被识别为更改的行的未修改行,以及
(ii)它更多地显示更改的行系统地(Kim et al. 2013)。添加和删除代码行的顺序预计将更接近开发人员对代码所做的操作。如果代码元素一起更改,它们将明确显示为组系统更改或报告它们的共同结构特征。
对于此分析,我们使用了第 6 节和第 7 节中使用的相同数据集,如表 9 所示。
在 CI-Java 项目中,我们认为所有提交 ID 中的所有修改文件都是目标,而在 Apache 项目中,在所有错误修复提交候选中更改的文件都是目标。
我们应用了与其他两个比较相同的命令:
git diff -w --ignore-blank-lines --diff-algorithm=<algorithm> <parent commit ID> <commit ID> -- <filename> 生成差异输出来自迈尔斯和直方图。
在第一组的每个项目中,我们分析了执行两个 diff 策略时插入和删除行的位置不同的文件。而在第二组中,仅分析了删除行的位置不同的文件。
我们将比较分为两类:(i)代码内差异和(ii)非代码差异。
第一类差异意味着两种算法生成的不同差异列表是源代码文件中的代码行或代码块。
否则,第二个差异意味着这两种算法之间的分歧不是一行代码,例如注释的更改,或非代码文件的更改,例如文本文件的修改。
两种差异算法之间的定性分析由前两位作者分多个步骤手动执行。最初,第一作者列出了来自两个项目组的所有文件。
从这个列表中,使用调查系统中提供的工具计算文件的样本大小脚注 15 以统计表示每个项目中文件的样本,以便关于 diff 算法质量的结论可以推广到所有项目中的所有文件置信水平为 95%,置信区间为 5。如表 9 所示,所有项目组汇总的文件总数为 21,590。从这个人群中,我们选择了 377 个文件的随机样本。
在第二步中,我们在样本中所有文件的 Myers 和直方图算法生成的两个差异输出之间进行了手动比较。本文的前两位作者参与了对差异输出的独立注释,这使得结果有望更加可靠。为了指定两种 diff 算法之间的比较结果,我们生成了三个类别,如表 10 中所述。如果直方图算法产生的差异输出更恰当地显示未修改的线并提供更好的组系统变化以显示比较结果,我们将直方图分配给比较结果。与迈尔斯相比,线路发生了变化。如果 Myers 产生的结果提供了更合适的未更改上下文,并且与直方图的 diff 相比更系统地显示了组变化,我们将它们标记为 Myers。如果一种算法产生的差异输出并不比另一种更好,那么我们将它们标记为相同。随后计算了来自 377 个文件的两位作者之间的比较结果,以找到 kappa 一致性。脚注 16 我们获得了 70.82%,归类为“实质性一致性”(Viera 和 Garrett 2005)。这意味着,我们手动研究的统计结果是可以接受的。
结果
表 11 显示了两种差异算法在呈现代码更改方面的工作情况。
可以看出,Histogram 在 in-Code diff 类别中的数量超过了其他结果,这强调了该算法在具体区分代码的变化方面要好得多。
图 15 显示了与 Myers 相比,直方图算法如何提供更好的代码更改输出。
我们从 ActiveMQ 项目的提交 f56ea45e5 中的文件 AmqpMessage.javaFootnote 17 中提取了差异。
确实,没有一个算法在描述变化方面是不正确的。
然而,直方图算法提供了一个合理的差异输出,更好地描述了人类改变的意图,因为 if 语句被移动到一个新的方法并添加了一个新的方法调用。
虽然从 Myers 的结果来看,尚不清楚开发人员如何更改代码。
未修改的行被标识为从原始位置(第 18 行和第 19 行)中删除并添加到新位置(第 6 行和第 7 行)。
- FIG15
Example of diff outputs generated by Myers and Histogram in extracting the code changes

这项手动调查还强调,Myers 和 Histogram 算法几乎具有从非代码更改中提取差异的能力。
如表 11 所示,它们的百分比在非代码差异中几乎相等(13.4% 的文件使用直方图更好,14.9% 的文件使用 Myers 更可取)。
两种 diff 算法应用的高百分比甚至为相同的文件产生相同的质量(参见图 16 中的示例),达到 71.6%,这甚至得到了加强。
这种量化表明我们可以使用这些算法中的任何一种来从非代码更改中产生差异。
如图 16 所示,两种 diff 算法都能很好地揭示 Openmicroscopy 项目的提交 e5924527fa 中文件 ChannelMetadataLoader.javaFootnote 18 中的评论更改,因为这两个列表都是可读和可理解的。
两个列表之间的唯一区别是初始添加行的位置和第一个插入行之后的匹配行。然而,这些分歧并没有改变我们对所发生修改的解释。
- FIG16
Example of diff lists generated by Myers and Histogram in extracting the non-code changes

概括
由于 Myers 和 Histogram 在识别更改的代码行时的程序不同,它们可能会产生不同的 diff 结果。
我们手动比较发现,它们的区别在于修改的次数、修改的行的顺序,甚至检测到的添加和删除的代码。
它们肯定会影响 diff 输出的可读性,换句话说,两种 diff 算法产生的 diff 结果的质量是不同的。
重要的是,我们的结果证明,与 Myers 相比,直方图在提取源代码差异方面经常产生更好的差异结果。
讨论
启示和建议
在本文中,我们描述了不同差异对研究结果的影响。
在图 15 所示的示例中,我们可以看到两种算法都从第 169 行识别出更改的代码行。
然而,两个差异输出中显示的已识别更改行存在一些差异。
第一个区别是更改的行数。 从图 15 可以看出,检测到的变化线的数量是不相等的。
Myers 发现了 11 条变化的线,而直方图发现了 13 条线。
在一项旨在从代码更改中收集指标的研究中,考虑不同的差异算法很重要,因为它会影响更改的数量。
在软件质量分析中,用于衡量更改的过程度量的一个关键因素是修改的行数(NLA 和 NLD)。
例如,Gousios 等人进行的一项工作。 (2008) 提出了一种方法来衡量软件开发人员的贡献,使用差异记录来计算文件中更改的行数。然后使用此数量的更改行来计算所有受影响文件的提交大小。根据我们的指标比较,我们发现 1.7% 到 8.2% 的提交由于不同的算法应用程序具有不同的 NLA 和 NLD。虽然我们的手动调查表明,使用直方图提取 60% 以上的差异输出效果更好。因此,如果本研究尝试应用直方图,它可能会影响大约 1% 到 4% 的不同提交大小。因此,这也会影响对软件开发人员贡献的衡量。
Rausch 等人进行了另一项与度量分析相关的研究。 (2017)。
作者调查了可能影响软件质量的更改的复杂性。研究结果支持更高的 NLA 和 NLD 中值导致构建失败的增加。该研究还发现,修改文件数量的高平均值与失败的构建相关。根据我们的指标分析结果,我们发现 0.8% 到 6.2% 的文件具有不同的 NLA 和 NLD。因此,如果在本研究中应用直方图,这将影响大约 0.5% 到 3.5% 的与失败构建相关的修改文件。
第二个区别是改变线的位置。 图 15 显示两种 diff 算法以不同方式检测删除的行。 Myers 标识了一行“赋值”和一行“方法”调用,而直方图指定了一个“if 条件”块。
与 SZZ 应用程序相关,两种 diff 算法都会产生不同的删除行,这些删除行被认为是引入 bug 的候选行。
因此,识别的错误相关行可能由于不同的差异算法应用而无效,这可能导致错误引入更改识别失败。
da Costa 等人进行的一项研究。 (2017) 调查了五个 SZZ 程序的输出,以发现引入错误的变化。
对 10 个 Apache 项目的研究分析了引入错误的更改的有效性。作者使用的 bug 相关行的验证过程与我们的研究相似。它将最早受影响软件版本的发布日期与引入错误相关行候选的日期进行比较。
然而,在我们的研究中,我们增强了验证其他三个参数的过程,即最初添加有效错误相关行的错误引入提交、包含有效错误相关行的文件以及相关的错误修复提交有效的引入错误的提交。
我们的 SZZ 分析表明,不同的 diff 算法应用会对 SZZ 算法的结果产生影响。我们发现 2.4% 到 6.6% 的有效文件具有不同位置的有效错误相关行。由于根据我们的手动分析,直方图在 60% 以上的差异输出中更好,因此,如果 da Costa 等人的研究。 (2017) 在 diff 命令中应用直方图,大约 1.5% 到 4% 的文件在他们的研究结果中可能有不同的有效错误相关行。
Rodriguez-Perez 等人也研究了 SZZ 算法。 (2018 年)。作者对已发表的文章进行了文献综述,重点关注 SZZ 算法的功能及其被模仿的能力。这项研究与我们的相似之处在于调查由于 SZZ 算法的修改而产生的变化影响。然而,该研究侧重于学术论文中随时间变化的 SZZ 的可用性,而我们的研究分析了 SZZ 中不同 diff 算法应用对研究结果的影响。不考虑 Rodriguez-Perez 等人收集的 187 项先前研究中使用的 SZZ 版本。 (2018 年),我们了解到 SZZ 是 10 年内广泛使用且广为人知的算法。这种错误识别算法通常用于调查提交大小(26% 的论文)、代码行(15% 的论文)、更改数量(12% 的论文)、受影响文件的数量(8%论文)等。正如我们在 SZZ 分析中所描述的,diff 算法也对 SZZ 有影响。因此,如果在这 187 项先前的研究中应用直方图,它可能会影响研究结果。
我们对指标和 SZZ 应用的调查提供了证据,表明在 git 命令中应用不同的 diff 算法会对研究结果产生影响。
还承认直方图算法在生成更改的代码行方面比 Myers 算法要好得多。
因此,我们建议使用 git diff 命令中的 Histogram 从源代码中提取更改。
对有效性的威胁
对结构有效性的威胁出现在映射研究和 SZZ 应用程序中。在我们的映射研究中,我们只选择了特别提到 git 命令的论文。
结果,使用过 git 命令但未在全文中提及的论文被忽略,这可能会导致选择偏差。由于不同的 diff 算法产生不同的结果,我们认为如果作者有意选择它们,论文应该提到 diff 的算法名称。
在 SZZ 应用程序中,我们使用少量关键字来检测描述修复错误的提交消息。这限制了我们提取所有潜在的候选错误修复提交的能力。
即便如此,只要在日志消息中包含关键字,也可以收集不应被识别为修复错误的提交。但是,由于我们的重点是调查 Myers 和 Histogram 生成的差异列表的差异程度,因此错误提交对研究结果的影响很小。对构造有效性的另一个威胁是 diff 算法更好的定义。我们根据我们的两个标准考虑算法的良好质量,而许多可以考虑。
不同的软件工程任务可能对差异分析有不同的要求。但是,由于我们的重点是期望从差异输出中恢复不断变化的操作,因此这个问题的影响并不显着。
关于我们实验中使用的存储库,出现了对外部有效性的威胁。
尽管我们分析了从 Git 存储库中挖掘的 24 个 OSS Java 项目,但我们不能将我们的研究结果推广到其他开源项目或行业。
为了减少对可靠性的威胁,我们公开了我们的数据集。
我们提供了我们收集的文件列表,这些文件由 Myers 和 Histogram 算法识别,这些算法用于三个实证分析(参见 GitHubFootnote 19)。
结论
为了了解使用不同 diff 算法、Myers 和 Histogram 的影响,我们首先通过对 2013 年至 2017 年间发表的论文进行系统映射来阐明 diff 的应用。
然后,我们对三个主要应用的影响进行了实证分析:(i) 代码流失指标 ,(ii)SZZ算法,和(iii)补丁提取。
我们的定量分析表明,不同的 diff 算法可以报告不同数量的变化线,识别不同的变化位置。
我们的定性调查表明,直方图更适合描述代码更改。
由于 diff 是各种软件工程任务的基本工具,因此考虑算法的局限性和优势很重要。
目前我们建议在分析代码更改时使用直方图算法。
小结
多思考。
参考资料
https://link.springer.com/article/10.1007/s10664-019-09772-z
