介绍
流(Streams)是持续流动且永无止境的记录集合。
与表不同,它们通常不存储在磁盘上,而是通过网络流动,并在内存中短暂地保存。
流与表相辅相成,因为它们代表了企业当前和未来发生的事情,而表则代表了过去。将流存档到表中是非常常见的。
与表类似,您经常希望使用基于关系代数的高级语言查询流,根据模式进行验证,并针对可用资源和算法进行优化。
Calcite 的 SQL 是标准 SQL 的扩展,而不是另一种“类似 SQL”的语言。
这种区别很重要,原因有几个:
- 对于任何了解常规 SQL 的人来说,流式 SQL 非常容易学习。
- 语义清晰,因为我们的目标是在流上产生与相同数据在表中时相同的结果。
- 您可以编写结合流和表(或流的历史,基本上是一个内存中的表)的查询。
- 许多现有工具可以生成标准 SQL。
- 如果不使用 STREAM 关键字,则回到常规的标准 SQL。
一个示例模式
我们的流式 SQL 示例使用以下模式:
- Orders(rowtime、productId、orderId、units)- 一个流和一个表
- Products(rowtime、productId、name)- 一个表
- Shipments(rowtime、orderId)- 一个流
一个简单的查询
让我们从最简单的流式查询开始:
SELECT STREAM *
FROM Orders;
rowtime | productId | orderId | units
----------+-----------+---------+-------
10:17:00 | 30 | 5 | 4
10:17:05 | 10 | 6 | 1
10:18:05 | 20 | 7 | 2
10:18:07 | 30 | 8 | 20
11:02:00 | 10 | 9 | 6
11:04:00 | 10 | 10 | 1
11:09:30 | 40 | 11 | 12
11:24:11 | 10 | 12 | 4
这个查询从 Orders 流中读取所有列和行。像任何流式查询一样,它永远不会终止。它在 Orders 到达时输出一条记录。
要终止查询,请键入 Control-C。
STREAM 关键字是流式 SQL 中的主要扩展。它告诉系统您对即将到来的订单感兴趣,而不是现有的订单。
SELECT *
FROM Orders;
rowtime | productId | orderId | units
----------+-----------+---------+-------
08:30:00 | 10 | 1 | 3
08:45:10 | 20 | 2 | 1
09:12:21 | 10 | 3 | 10
09:27:44 | 30 | 4 | 2
4 records returned.
这个查询也是有效的,但会打印出所有现有的订单,然后终止。我们将其称为关系查询,与流式查询相对。它具有传统的 SQL 语义。
Orders 很特殊,因为它既是一个流,又是一个表。如果您尝试在表上运行流式查询,或在流上运行关系查询,Calcite 将会报错:
SELECT * FROM Shipments;
ERROR: Cannot convert stream 'SHIPMENTS' to a table
SELECT STREAM * FROM Products;
ERROR: Cannot convert table 'PRODUCTS' to a stream
过滤行
就像在常规的 SQL 中一样,您可以使用 WHERE 子句来过滤行:
SELECT STREAM *
FROM Orders
WHERE units > 3;
rowtime | productId | orderId | units
----------+-----------+---------+-------
10:17:00 | 30 | 5 | 4
10:18:07 | 30 | 8 | 20
11:02:00 | 10 | 9 | 6
11:09:30 | 40 | 11 | 12
11:24:11 | 10 | 12 | 4
投射表达式 Projecting expressions
在 SELECT 子句中使用表达式来选择要返回的列或计算表达式:
SELECT STREAM rowtime,
'An order for ' || units || ' '
|| CASE units WHEN 1 THEN 'unit' ELSE 'units' END
|| ' of product #' || productId AS description
FROM Orders;
rowtime | description
----------+---------------------------------------
10:17:00 | An order for 4 units of product #30
10:17:05 | An order for 1 unit of product #10
10:18:05 | An order for 2 units of product #20
10:18:07 | An order for 20 units of product #30
11:02:00 | An order by 6 units of product #10
11:04:00 | An order by 1 unit of product #10
11:09:30 | An order for 12 units of product #40
11:24:11 | An order by 4 units of product #10
我们建议您始终在 SELECT 子句中包含 rowtime 列。
在每个流和流式查询中具有排序的时间戳使得以后可以进行高级计算,例如 GROUP BY 和 JOIN。
滚动窗口 Tumbling windows
在流上计算聚合函数有几种方法。
它们的区别在于:
- 每个输入行产生多少行输出?
- 每个输入值出现在一个总计中,还是多个总计中?
- 什么定义了“窗口”,即贡献给给定输出行的行集合?
- 结果是流还是关系?
有各种窗口类型:
- 滚动窗口(GROUP BY)
- 跳跃窗口(多重 GROUP BY)
- 滑动窗口(窗口函数)
- 级联窗口(窗口函数)
以下图表显示了在哪种类型的查询中使用它们:
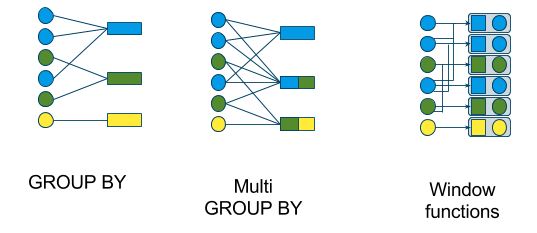
首先,我们将看一个滚动窗口,它由一个流式的 GROUP BY 定义。
以下是一个示例:
SELECT STREAM CEIL(rowtime TO HOUR) AS rowtime,
productId,
COUNT(*) AS c,
SUM(units) AS units
FROM Orders
GROUP BY CEIL(rowtime TO HOUR), productId;
rowtime | productId | c | units
----------+-----------+---------+-------
11:00:00 | 30 | 2 | 24
11:00:00 | 10 | 1 | 1
11:00:00 | 20 | 1 | 7
12:00:00 | 10 | 3 | 11
12:00:00 | 40 | 1 | 12
结果是一个流。在11点时,Calcite会为自10点以来有订单的每个productId发出一个子总计,时间戳为11点。
在12点时,它将发出在11:00到12:00之间发生的订单。
每个输入行只对一个输出行做出贡献。
Calcite 是如何知道在11:00:00时10:00:00的子总计已经完成,以便它可以发出它们呢?它知道 rowtime 是递增的,并且知道 CEIL(rowtime TO HOUR) 也是递增的。因此,一旦它看到11:00:00之后的一行,它就永远不会看到会贡献到10:00:00总计的行。
一个递增或递减的列或表达式被称为单调的。
如果列或表达式的值稍微有些混乱,并且流具有机制(例如标点符号或水印)来声明某个特定值将永远不会再次出现,那么该列或表达式被称为准单调的。
如果在 GROUP BY 子句中没有单调或准单调的表达式,Calcite 将无法取得进展,也不会允许查询:
SELECT STREAM productId,
COUNT(*) AS c,
SUM(units) AS units
FROM Orders
GROUP BY productId;
ERROR: Streaming aggregation requires at least one monotonic expression in GROUP BY clause
单调和准单调列需要在模式中声明。当记录进入流时,单调性受到强制执行,并被从该流中读取的查询所假设。
我们建议为每个流提供一个名为 rowtime 的时间戳列,但您也可以声明其他列为单调,例如 orderId。
我们将在下面讨论标点符号、水印和其他推进方式。
改进的滚动窗口
前面的滚动窗口示例之所以易于编写,是因为窗口是一个小时。
对于不是整个时间单位的间隔,比如2小时或2小时17分钟,您不能使用 CEIL,表达式会变得更加复杂。
Calcite支持滚动窗口的另一种语法:
SELECT STREAM TUMBLE_END(rowtime, INTERVAL '1' HOUR) AS rowtime,
productId,
COUNT(*) AS c,
SUM(units) AS units
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), productId;
rowtime | productId | c | units
----------+-----------+---------+-------
11:00:00 | 30 | 2 | 24
11:00:00 | 10 | 1 | 1
11:00:00 | 20 | 1 | 7
12:00:00 | 10 | 3 | 11
12:00:00 | 40 | 1 | 12
如您所见,它返回与先前查询相同的结果。 TUMBLE 函数返回一个分组键,对于所有最终在给定摘要行中的行都是相同的;
TUMBLE_END 函数采用相同的参数并返回该窗口结束的时间;还有一个 TUMBLE_START 函数。
TUMBLE 有一个可选参数用于对齐窗口。
在以下示例中,我们使用30分钟的间隔和0:12作为对齐时间,因此查询在每个小时的12分和42分发出摘要:
SELECT STREAM
TUMBLE_END(rowtime, INTERVAL '30' MINUTE, TIME '0:12') AS rowtime,
productId,
COUNT(*) AS c,
SUM(units) AS units
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '30' MINUTE, TIME '0:12'),
productId;
rowtime | productId | c | units
----------+-----------+---------+-------
10:42:00 | 30 | 2 | 24
10:42:00 | 10 | 1 | 1
10:42:00 | 20 | 1 | 7
11:12:00 | 10 | 2 | 7
11:12:00 | 40 | 1 | 12
11:42:00 | 10 | 1 | 4
跳跃窗口 Hopping windowsPermalink
跳跃窗口是对滚动窗口的一种推广,允许数据在窗口中保留超过发出间隔的时间。
例如,以下查询会发出一个时间戳为11:00的行,其中包含从08:00到11:00(或者如果我们很严谨的话,是10:59.9)的数据,以及一个时间戳为12:00的行,其中包含从09:00到12:00的数据。
SELECT STREAM
HOP_END(rowtime, INTERVAL '1' HOUR, INTERVAL '3' HOUR) AS rowtime,
COUNT(*) AS c,
SUM(units) AS units
FROM Orders
GROUP BY HOP(rowtime, INTERVAL '1' HOUR, INTERVAL '3' HOUR);
在这个查询中,因为保留期是发出期的3倍,每个输入行对应于恰好3个输出行。想象一下,HOP 函数为传入的行生成一组组键,并将其值放入每个组键的累加器中。例如,HOP(10:18:00, INTERVAL ‘1’ HOUR, INTERVAL ‘3’) 生成了3个周期:
- [08:00, 09:00)
- [09:00, 10:00)
- [10:00, 11:00)
这引发了允许用户定义分区函数的可能性,对于不满意内置函数 HOP 和 TUMBLE 的用户来说。
我们可以构建复杂的表达式,例如指数衰减的移动平均:
SELECT STREAM HOP_END(rowtime),
productId,
SUM(unitPrice * EXP((rowtime - HOP_START(rowtime)) SECOND / INTERVAL '1' HOUR))
/ SUM(EXP((rowtime - HOP_START(rowtime)) SECOND / INTERVAL '1' HOUR))
FROM Orders
GROUP BY HOP(rowtime, INTERVAL '1' SECOND, INTERVAL '1' HOUR),
productId
该查询会发出:
- 一个时间戳为11:00:00的行,其中包含在 [10:00:00, 11:00:00) 内的行;
- 一个时间戳为11:00:01的行,其中包含在 [10:00:01, 11:00:01) 内的行。
该表达式比较近期的订单与旧订单的权重更大。将窗口从1小时扩展到2小时或1年对结果的准确性几乎没有影响(但会使用更多内存和计算资源)。
请注意,我们在聚合函数(SUM)中使用了 HOP_START,因为它是在子总计中的所有行中都是常数值。对于典型的聚合函数(SUM、COUNT等),这是不允许的。
如果您熟悉 GROUPING SETS,您可能会注意到分区函数可以看作是 GROUPING SETS 的一般化,因为它们允许输入行贡献到多个子总计中。GROUPING SETS 的辅助函数,如 GROUPING() 和 GROUP_ID,可以在聚合函数内部使用,因此不足为奇的是,HOP_START 和 HOP_END 也可以以同样的方式使用。
GROUPING SETS
对于流式查询,GROUPING SETS 是有效的,前提是每个分组集都包含一个单调或准单调的表达式。
CUBE 和 ROLLUP 对于流式查询无效,因为它们会产生至少一个将所有内容聚合在一起的分组集(类似于 GROUP BY ())。
过滤聚合后的结果
与标准 SQL 一样,您可以使用 HAVING 子句来过滤流式 GROUP BY 发出的行:
SELECT STREAM TUMBLE_END(rowtime, INTERVAL '1' HOUR) AS rowtime,
productId
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), productId
HAVING COUNT(*) > 2 OR SUM(units) > 10;
子查询、视图和 SQL 的闭包特性
前面的 HAVING 查询可以使用子查询中的 WHERE 子句来表示:
SELECT STREAM rowtime, productId
FROM (
SELECT TUMBLE_END(rowtime, INTERVAL '1' HOUR) AS rowtime,
productId,
COUNT(*) AS c,
SUM(units) AS su
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), productId)
WHERE c > 2 OR su > 10;
HAVING 是在 SQL 初期引入的,当时需要一种在聚合之后执行过滤的方法。(回想一下,WHERE 在进入 GROUP BY 子句之前过滤行。)
从那时起,SQL 已经成为一个数学上封闭的语言,这意味着您可以对表执行的任何操作也可以对查询执行。
SQL 的闭包特性非常强大。它不仅使 HAVING 过时(或者至少将其减少为语法糖),还使视图成为可能:
CREATE VIEW HourlyOrderTotals (rowtime, productId, c, su) AS
SELECT TUMBLE_END(rowtime, INTERVAL '1' HOUR),
productId,
COUNT(*),
SUM(units)
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), productId;
SELECT STREAM rowtime, productId
FROM HourlyOrderTotals
WHERE c > 2 OR su > 10;
FROM 子句中的子查询有时被称为“内联视图”,但实际上,它们比视图更基本。视图只是将 SQL 划分为可管理的块的便捷方式,通过给这些块命名并将它们存储在元数据存储库中。
许多人发现,嵌套查询和视图在流上比在关系上更有用。流式查询是连续运行的操作器管道,而且通常这些管道会变得相当长。嵌套查询和视图有助于表达和管理这些管道。
顺便说一句,WITH 子句可以达到与子查询或视图相同的效果:
WITH HourlyOrderTotals (rowtime, productId, c, su) AS (
SELECT TUMBLE_END(rowtime, INTERVAL '1' HOUR),
productId,
COUNT(*),
SUM(units)
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), productId)
SELECT STREAM rowtime, productId
FROM HourlyOrderTotals
WHERE c > 2 OR su > 10;
从流转换到关系 Converting between streams and relationsPermalink
回顾 HourlyOrderTotals 视图的定义。
该视图是流还是关系?
它不包含 STREAM 关键字,因此它是一个关系。
但是,它是一个可以转换为流的关系。
您可以在关系和流式查询中使用它:
# 一个关系;将查询历史的 Orders 表。
# 返回一小时内销售的产品 #10 的最大数量。
SELECT max(su)
FROM HourlyOrderTotals
WHERE productId = 10;
# 一个流;将查询 Orders 流。
# 返回至少销售了一个产品 #10 的每个小时。
SELECT STREAM rowtime
FROM HourlyOrderTotals
WHERE productId = 10;
这种方法不仅限于视图和子查询。根据 CQL 中的方法,流式 SQL 中的每个查询都被定义为一个关系查询,并在顶层 SELECT 中使用 STREAM 关键字将其转换为流。
如果在子查询或视图定义中存在 STREAM 关键字,则它不起作用。
在查询准备阶段,Calcite 会确定查询中引用的关系是否可以转换为流或历史关系。
有时,流会提供其部分历史数据(例如 Apache Kafka 主题中的最近 24 小时数据),但并非全部。
在运行时,Calcite 会确定是否有足够的历史记录来运行查询,如果没有,则会报错。
“饼图”问题:流上的关系查询
有一种特殊情况需要将流转换为关系,这就是我所说的“饼图问题”。
想象一下,您需要编写一个包含图表的网页,如下所示,该图表总结了过去一小时内每种产品的订单数量。
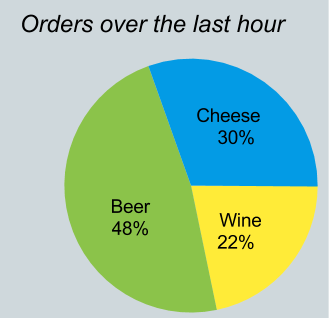
但是 Orders 流只包含少量记录,而不是一个小时的汇总。我们需要在流的历史记录上运行一个关系查询:
SELECT productId, count(*)
FROM Orders
WHERE rowtime BETWEEN current_timestamp - INTERVAL '1' HOUR
AND current_timestamp;
如果 Orders 流的历史记录正在被存储到 Orders 表中,我们可以回答查询,尽管成本很高。
更好的方法是,如果我们可以告诉系统将一个小时的汇总材料化为一个表,在流动时持续维护它,并自动重写查询以使用该表。
排序(Sorting)
ORDER BY 的用法与 GROUP BY 类似。语法看起来像是常规的 SQL,但 Calcite 必须确保能够及时地提供结果。
因此,它要求在 ORDER BY 关键字的首要位置使用单调表达式。
SELECT STREAM CEIL(rowtime TO hour) AS rowtime, productId, orderId, units
FROM Orders
ORDER BY CEIL(rowtime TO hour) ASC, units DESC;
大多数查询将按照它们插入的顺序返回结果,因为引擎使用的是流式算法,但您不应该依赖这一点。
例如,考虑以下情况:
SELECT STREAM *
FROM Orders
WHERE productId = 10
UNION ALL
SELECT STREAM *
FROM Orders
WHERE productId = 30;
产品ID为30的行明显是无序的,这可能是因为 Orders 流根据产品ID进行了分区,并且分区流在不同的时间发送了它们的数据。
如果您需要特定的排序,可以添加显式的 ORDER BY:
SELECT STREAM *
FROM Orders
WHERE productId = 10
UNION ALL
SELECT STREAM *
FROM Orders
WHERE productId = 30
ORDER BY rowtime;
您只需要在最外层查询中添加 ORDER BY。
如果需要在 UNION ALL 之后执行 GROUP BY 等操作,Calcite 会隐式添加 ORDER BY,以便使 GROUP BY 算法成为可能。
表构造器(Table constructor)
VALUES 子句创建一个具有给定行集的内联表。
不允许流式处理。行集永远不会更改,因此流永远不会返回任何行。
SELECT STREAM * FROM (VALUES (1, 'abc'));
错误:无法流式传输 VALUES
滑动窗口(Sliding windows)
标准 SQL 提供了所谓的“分析函数”,可以在 SELECT 子句中使用。
与 GROUP BY 不同,这些函数不会合并记录。对于每个进入的记录,都会产生一个输出记录。但是聚合函数是基于许多行的窗口进行计算的。
让我们看一个示例。
SELECT STREAM rowtime,
productId,
units,
SUM(units) OVER (ORDER BY rowtime RANGE INTERVAL '1' HOUR PRECEDING) unitsLastHour
FROM Orders;
这个功能提供了很大的能力,而几乎没有什么努力。您可以在 SELECT 子句中使用多个函数,基于多个窗口规范。
下面的示例返回过去10分钟内订单平均订单大小大于过去一周的平均订单大小的订单。
SELECT STREAM *
FROM (
SELECT STREAM rowtime,
productId,
units,
AVG(units) OVER product (RANGE INTERVAL '10' MINUTE PRECEDING) AS m10,
AVG(units) OVER product (RANGE INTERVAL '7' DAY PRECEDING) AS d7
FROM Orders
WINDOW product AS (
ORDER BY rowtime
PARTITION BY productId))
WHERE m10 > d7;
为了简洁起见,这里使用了一种语法,部分地使用 WINDOW 子句定义窗口,然后在每个 OVER 子句中细化窗口。
如果您愿意,您也可以在 WINDOW 子句中定义所有窗口,或者在内联中定义所有窗口。
但真正的力量超越了语法。在幕后,这个查询正在维护两个表,并使用 FIFO 队列向子总计添加和删除值。
但是,您可以在查询中访问这些表,而不需要引入连接。
窗口聚合语法的一些其他特点:
-
您可以基于行计数定义窗口。
-
窗口可以引用尚未到达的行。(流将等待它们到达)。
-
您可以计算依赖于顺序的函数,例如 RANK 和中位数。
Cascading windows
如果我们想要一个查询,对于每条记录都返回一个结果,就像一个滑动窗口一样,但是在固定的时间段内重置总数,就像一个滚动窗口一样,这样的模式被称为级联窗口。
以下是一个示例:
SELECT STREAM rowtime,
productId,
units,
SUM(units) OVER (PARTITION BY FLOOR(rowtime TO HOUR)) AS unitsSinceTopOfHour
FROM Orders;
它看起来类似于一个滑动窗口查询,但是单调表达式出现在窗口的 PARTITION BY 子句中。
当 rowtime 从 10:59:59 移动到 11:00:00 时,FLOOR(rowtime TO HOUR) 从 10:00:00 变为 11:00:00,因此开始一个新的分区。
新小时的第一行到达时将开始一个新的总数;第二行将有一个由两行组成的总数,依此类推。
Calcite 知道旧分区将永远不会再次使用,因此从内部存储中删除该分区的所有子总数。
可以在同一查询中结合使用使用级联和滑动窗口的分析函数。
流与表的连接
在流相关的情况下,有两种连接类型:流到表连接和流到流连接。
如果表的内容不会改变,则流到表连接很简单。此查询将订单流与每个产品的列表价格进行关联:
SELECT STREAM o.rowtime, o.productId, o.orderId, o.units,
p.name, p.unitPrice
FROM Orders AS o
JOIN Products AS p
ON o.productId = p.productId;
如果表发生更改会发生什么?例如,假设产品 10 的单价在 11:00 增加到 0.35。在 11:00 之前下的订单应该使用旧价格,而在 11:00 之后下的订单应该反映新价格。
实现此目的的一种方法是使用一个包含每个版本的开始和结束生效日期的表,下面是 ProductVersions 的示例:
SELECT STREAM *
FROM Orders AS o
JOIN ProductVersions AS p
ON o.productId = p.productId
AND o.rowtime BETWEEN p.startDate AND p.endDate;
另一种实现方法是使用具有时间支持的数据库(即能够查找数据库在过去任意时刻的内容),并且系统需要知道 Orders 流的 rowtime 列对应于 Products 表的事务时间戳。
对于许多应用程序来说,支持时间或版本的表的成本和工作量是不值得的。
当重播时,查询给出不同的结果是可以接受的:在此示例中,重播时,所有产品 10 的订单都被分配了较晚的单价 0.35。
Joining streams to streams
如果连接条件迫使两个流保持彼此有限的距离,那么连接两个流是有意义的。
在下面的查询中,发货日期在订单日期的一小时内:
SELECT STREAM o.rowtime, o.productId, o.orderId, s.rowtime AS shipTime
FROM Orders AS o
JOIN Shipments AS s
ON o.orderId = s.orderId
AND s.rowtime BETWEEN o.rowtime AND o.rowtime + INTERVAL '1' HOUR;
请注意,许多订单不会出现在结果中,因为它们没有在一小时内发货。
当系统接收到时间戳为 11:24:11 的订单 10 时,它已经从哈希表中删除了包括时间戳为 10:18:07 的订单 8 在内的订单。
正如您所看到的,“锁定步骤”将两个流的单调或准单调列绑定在一起,对于系统来说,这是必要的以推进。如果系统无法推断出锁定步骤,则它将拒绝执行查询。
DML
不仅查询对流具有意义;对流运行 DML 语句(INSERT、UPDATE、DELETE,以及它们更少见的兄弟 UPSERT 和 REPLACE)也是有意义的。
DML 是有用的,因为它允许您基于流或基于流的表来实现流,并且因此在值经常使用时节省工作量。
考虑流应用程序通常由一系列查询管道组成,每个查询将输入流转换为输出流。管道的组件可以是视图:
CREATE VIEW LargeOrders AS
SELECT STREAM * FROM Orders WHERE units > 1000;
或者是持续的 INSERT 语句:
INSERT INTO LargeOrders
SELECT STREAM * FROM Orders WHERE units > 1000;
这两者看起来类似,在这两种情况下,管道中的下一步可以从 LargeOrders 中读取,而不必担心它是如何填充的。
它们在效率上有所不同:INSERT 语句无论消费者的数量如何都会执行相同的工作;视图的工作量与消费者的数量成正比,并且特别是在没有消费者时不执行任何工作。
对于流,其他形式的 DML 也是有意义的。例如,以下持续的 UPSERT 语句维护了一个表,该表将订单的最后一个小时的摘要材料化:
UPSERT INTO OrdersSummary
SELECT STREAM productId,
COUNT(*) OVER lastHour AS c
FROM Orders
WINDOW lastHour AS (
PARTITION BY productId
ORDER BY rowtime
RANGE INTERVAL '1' HOUR PRECEDING)
标点符号
标点符号允许流查询在单调键中没有足够的值推送结果时取得进展。
(我更喜欢使用术语“行时间界限”,而水印是一个相关的概念,但出于这些目的,标点符号已经足够。)
如果流启用了标点符号,则可能无法排序,但仍然可排序。因此,就语义而言,以排序的流进行工作已经足够。
顺便说一句,如果流是t-排序的(即每个记录都保证在其时间戳后t秒内到达)或者是k-排序的(即每个记录保证不会超过k个位置的乱序),那么乱序的流也是可排序的。因此,对这些流的查询可以类似地规划为对具有标点符号的流的查询。
而且,我们经常希望对非基于时间但仍然单调的属性进行聚合。“一个团队在赢得状态和输掉状态之间转换的次数”就是一个这样的单调属性。系统需要自己确定可以安全地对这样的属性进行聚合;标点符号不会添加任何额外的信息。
我想到了一些规划器的元数据(成本度量):
- 此流在给定属性(或属性)上是否排序?
- 是否可能对流在给定属性上进行排序?(对于有限关系,答案始终是“是”;对于流,它取决于是否存在标点符号,或者属性和排序键之间的链接。)
- 我们需要引入多少延迟才能执行该排序?
- 执行该排序的成本(CPU、内存等)是多少?
我们已经有了(1),在 BuiltInMetadata.Collation 中。对于(2),对于有限关系,答案始终是“是”。但是对于流,我们需要实现(2)、(3)和(4)。
流的状态
本文中并非所有概念都已在Calcite中实现。而且,有些可能已经在Calcite中实现,但在特定适配器(如SamzaSQL)中尚未实现。
已实现的功能:
- 流式SELECT、WHERE、GROUP BY、HAVING、UNION ALL、ORDER BY
- FLOOR 和 CEIL 函数
- 单调性
- 不允许流式VALUES
未实现的功能:
以下功能在本文中被描述得好像Calcite支持它们,但实际上它并没有(尚未)支持。全面支持意味着参考实现支持该功能(包括负面案例),并且TCK对其进行测试。
- 流到流的JOIN
- 流到表的JOIN
- 在视图上使用流
- 具有ORDER BY的流式UNION ALL(合并)
- 流上的关系查询
- 流式窗口聚合(滑动窗口和级联窗口)
- 检查子查询和视图中的STREAM是否被忽略
- 检查流式ORDER BY是否不能包含OFFSET或LIMIT
- 有限的历史;在运行时,检查是否有足够的历史来运行查询。
- 准单调性
- HOP 和 TUMBLE(以及辅助的 HOP_START、HOP_END、TUMBLE_START、TUMBLE_END)函数
本文中需要完成的任务:
- 重新审视是否可以流式VALUES
- 使用OVER子句定义流上的窗口
- 考虑是否允许在流式查询中使用CUBE和ROLLUP,理解到某些级别的聚合永远不会完成(因为它们没有单调表达式),因此永远不会被发出。
- 修复UPSERT示例,删除在最近一小时内未发生的产品记录。
- DML输出到多个流;也许是标准REPLACE语句的扩展。
函数
以下函数不属于标准SQL,但在流SQL中定义。
标量函数:
- FLOOR(dateTime TO intervalType) 将日期、时间或时间戳值向下舍入到给定的间隔类型
- CEIL(dateTime TO intervalType) 将日期、时间或时间戳值向上舍入到给定的间隔类型
分区函数:
- HOP(t, emit, retain) 返回一组分组键,用于将行作为跳跃窗口的一部分
- HOP(t, emit, retain, align) 返回一组分组键,用于将行作为具有给定对齐方式的跳跃窗口的一部分
- TUMBLE(t, emit) 返回一组分组键,用于将行作为滚动窗口的一部分
- TUMBLE(t, emit, align) 返回一组分组键,用于将行作为具有给定对齐方式的滚动窗口的一部分
- TUMBLE(t, e) 等同于 TUMBLE(t, e, TIME ‘00:00:00’)。
- TUMBLE(t, e, a) 等同于 HOP(t, e, e, a)。
- HOP(t, e, r) 等同于 HOP(t, e, r, TIME ‘00:00:00’)。
参考资料
https://calcite.apache.org/docs/spatial.html
- 介绍
- 一个示例模式
- 一个简单的查询
- 过滤行
- 投射表达式 Projecting expressions
- 滚动窗口 Tumbling windows
- 改进的滚动窗口
- 跳跃窗口 Hopping windowsPermalink
- GROUPING SETS
- 过滤聚合后的结果
- 子查询、视图和 SQL 的闭包特性
- 从流转换到关系 Converting between streams and relationsPermalink
- “饼图”问题:流上的关系查询
- 排序(Sorting)
- 表构造器(Table constructor)
- 滑动窗口(Sliding windows)
- Cascading windows
- 流与表的连接
- Joining streams to streams
- DML
- 标点符号
- 流的状态
- 函数
- 参考资料
