现象
机器在定时跑批执行大量 SQL 时,发现系统触发大量的 FULL-GC。
配置信息
应用中配置了的 druid 大概如下:
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close">
<!-- 基本属性 url、user、password -->
<property name="url" value="${jdbc_url}" />
<property name="username" value="${jdbc_user}" />
<property name="password" value="${jdbc_password}" />
<!-- 配置初始化大小、最小、最大 -->
<property name="initialSize" value="5" />
<property name="minIdle" value="5" />
<property name="maxActive" value="10" />
<!-- 配置从连接池获取连接等待超时的时间 -->
<property name="maxWait" value="10000" />
<!-- 配置间隔多久启动一次DestroyThread,对连接池内的连接才进行一次检测,单位是毫秒。
检测时:1.如果连接空闲并且超过minIdle以外的连接,如果空闲时间超过minEvictableIdleTimeMillis设置的值则直接物理关闭。2.在minIdle以内的不处理。
-->
<property name="timeBetweenEvictionRunsMillis" value="600000" />
<!-- 配置一个连接在池中最大空闲时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="300000" />
<!-- 设置从连接池获取连接时是否检查连接有效性,true时,每次都检查;false时,不检查 -->
<property name="testOnBorrow" value="false" />
<!-- 设置往连接池归还连接时是否检查连接有效性,true时,每次都检查;false时,不检查 -->
<property name="testOnReturn" value="false" />
<!-- 设置从连接池获取连接时是否检查连接有效性,true时,如果连接空闲时间超过minEvictableIdleTimeMillis进行检查,否则不检查;false时,不检查 -->
<property name="testWhileIdle" value="true" />
<!-- 检验连接是否有效的查询语句。如果数据库Driver支持ping()方法,则优先使用ping()方法进行检查,否则使用validationQuery查询进行检查。(Oracle jdbc Driver目前不支持ping方法) -->
<property name="validationQuery" value="select 1 from dual" />
<!-- 单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法 -->
<!-- <property name="validationQueryTimeout" value="1" /> -->
<!-- 打开后,增强timeBetweenEvictionRunsMillis的周期性连接检查,minIdle内的空闲连接,每次检查强制验证连接有效性. 参考:https://github.com/alibaba/druid/wiki/KeepAlive_cn -->
<property name="keepAlive" value="true" />
<!-- 连接泄露检查,打开removeAbandoned功能 , 连接从连接池借出后,长时间不归还,将触发强制回连接。回收周期随timeBetweenEvictionRunsMillis进行,如果连接为从连接池借出状态,并且未执行任何sql,并且从借出时间起已超过removeAbandonedTimeout时间,则强制归还连接到连接池中。 -->
<property name="removeAbandoned" value="true" />
<!-- 超时时间,秒 -->
<property name="removeAbandonedTimeout" value="80"/>
<!-- 关闭abanded连接时输出错误日志,这样出现连接泄露时可以通过错误日志定位忘记关闭连接的位置 -->
<property name="logAbandoned" value="true" />
<!-- 根据自身业务及事务大小来设置 -->
<property name="connectionProperties"
value="oracle.net.CONNECT_TIMEOUT=2000;oracle.jdbc.ReadTimeout=10000"></property>
<!-- 打开PSCache,并且指定每个连接上PSCache的大小,Oracle等支持游标的数据库,打开此开关,会以数量级提升性能,具体查阅PSCache相关资料 -->
<property name="poolPreparedStatements" value="true" />
<property name="maxPoolPreparedStatementPerConnectionSize"
value="20" />
<!-- 配置监控统计拦截的filters -->
<!-- <property name="filters" value="stat,slf4j" /> -->
<property name="proxyFilters">
<list>
<ref bean="log-filter" />
<ref bean="stat-filter" />
</list>
</property>
<!-- 配置监控统计日志的输出间隔,单位毫秒,每次输出所有统计数据会重置,酌情开启 -->
<property name="timeBetweenLogStatsMillis" value="120000" />
</bean>
可能1:druid stat 导致
这里从网上选择写的比较好的文章,整体排查思路是类似的。
首先我们不能只靠猜测,要拿出证据。
内存 dump 就是最好的证据。
内存 dump
得益于在JVM参数中加了-XX:+HeapDumpOnOutOfMemoryError 参数,在发生OOM的时候系统会自动生成当时的Dump文件,这样我们可以完整的分析“案发现场”。
这里我们使用 Eclipse Memory Analyzer 工具来帮忙解析Dump文件。
开始怀疑是 druid 的 connection 没有释放导致的内存泄露,就 DUMP 了一下文件。
发现大概如下:

从Overview中的饼图可以很明显的看到有个蓝色区域占了最大头,这个类占了245.6MB的内存。
再看左侧的说明写着DruidDataSource,好的,罪魁祸首就是他了。

再通过Domainator_Tree界面可以看到是com.alibaba.druid.pool.DruidDataSource类下的com.alibaba.druid.stat.JdbcDataSourceStat$1对象里面有个LinkedHashMap,这个Map持有了600多个Entry,其中大约有100个Entry大小为2000000多字节(约2MB)。
而Entry的key是String对象,看了一下String的内容大约都是 select IFNULL(sum remain_principal),0) from t_loan where customer_id in (?, ?, ?, ? ...,果然就是刚才错误日志所提示的代码的功能。
补充说明
问题分析
由于计算这些用户金额的查询条件有3万多个所以这个SQL语句特别长,然后这些SQL都被JdbcDataSourceStat中的一个HashMap对象所持有导致无法GC,从而导致OOM的发生。
嗯,简直是教科书般的OOM事件。
然也有人在github的Druid的Issues上提出了这个问题。
源码分析
接下来去看了一下JdbcDataSourceStat的源码,发现有个变量为 LinkedHashMap<String, JdbcSqlStat> sqlStatMap 的Map。
并且还有个静态变量和静态代码块:
private static JdbcDataSourceStat global;
static {
String dbType = null;
{
String property = System.getProperty("druid.globalDbType");
if (property != null && property.length() > 0) {
dbType = property;
}
}
global = new JdbcDataSourceStat("Global", "Global", dbType);
}
这就意味着除非手动在代码中释放global对象或者remove掉sqlStatMap里的对象,否则sqlStatMap就会一直被持有不能被GC释放。
已经定位到问题所在了,不过简单的从代码上看无法判定这个sqlStatMap具体是有什么作用,以及如何使其释放掉,于是到网上搜索了一下,发现在其Github的Issues里就有人提出过这个问题了。每个sql语句都会长期持有引用,加快FullGC频率。
sqlStatMap这个对象是用于Druid的监控统计功能的,所以要持有这些SQL用于展示在页面上。
由于平时不使用这个功能,且询问其他同事也不清楚为何开启这个功能,所以决定先把这个功能关闭。
根据文档写这个功能默认是关闭的,不过被我们在配置文件中开启了,现在去掉这个配置就可以了
统计 sql 是否相同?
分析结论:批量操作,由于参数个数不同,导致sqlStatMap存储的数据量大。
解决方式
xml 禁用配置
根据文档写这个功能默认是关闭的,不过被我们在配置文件中开启了,现在去掉这个配置就可以了
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close">
...
<!-- 监控 -->
<!-- <property name="filters" value="state"/> -->
</bean>
修改完上线后一段时间后没有发生OOM了,这时再通过jmap -dump:format=b,file=文件名 [pid]命令生成Dump文件,会发现内存占用恢复正常,并且也不会看到com.alibaba.druid.pool.DruidDataSource类下有com.alibaba.druid.stat.JdbcDataSourceStat$1的占用。
证明这个OOM问题已经被成功解决了。
解决方案
Druid的监控统计功能是通过filter-chain扩展实现,如果你要打开监控统计功能,配置StatFilter,
具体看这里:https://github.com/alibaba/druid/wiki/配置_StatFilter
方案一:直接关闭Druid的stat
显式的在配置文件使用spring.datasource.druid.filter.stat=false。
方案二:开启sql合并
结构重复的sql语句的sql比较多,可以开启sql合并。
例如:批量操作导致sqlStatMap过大可以采用这种方案。
SQL监控的 LinkedHashMap<String, JdbcSqlStat> sqlStatMap 是以SQL语句作为键的。
针对上面批量处理导致大量的sql存储到sqlStatMap的问题,可以开启sql合并。
解决方案:
或者通过增加JVM的参数配置: -Ddruid.stat.mergeSql=true
或者
spring:
druid:
connectionProperties: druid.stat.mergeSql=true
或者:
@Configuration
public class DruidConfig {
@Bean
public StatFilter statFilter() {
StatFilter statFilter = new StatFilter();
statFilter.setMergeSql(true);
return statFilter;
}
}
方案三:控制sqlStatMap大小
有业务需求不能合并sql或者合并了sql也没有太大效果(结构重复的sql语句不多),也可以不设置sql合并而是设置druid.stat.sql.MaxSize(默认1000个)。
老马的个人理解,主要是下面的一段:
个人看的 druid 版本为 v1.2.15
private final LinkedHashMap<String, JdbcSqlStat> sqlStatMap;
sqlStatMap = new LinkedHashMap<String, JdbcSqlStat>(16, 0.75f, false) {
protected boolean removeEldestEntry(Map.Entry<String, JdbcSqlStat> eldest) {
boolean remove = (size() > maxSqlSize);
if (remove) {
JdbcSqlStat sqlStat = eldest.getValue();
if (sqlStat.getRunningCount() > 0 || sqlStat.getExecuteCount() > 0) {
skipSqlCount.incrementAndGet();
}
}
return remove;
}
};
druid.stat.sql.maxSize: 记录SQL最大长度。是Druid连接池中的一个配置项,用于限制记录到统计信息中的SQL语句的最大长度。当SQL语句的长度超过这个配置的值时,Druid的统计模块将不会完全记录这条SQL,而是可能截断或不记录以避免占用过多内存资源。这个设置有助于在保持数据库访问统计信息的同时,管理内存使用,尤其是在处理大量长SQL或复杂查询的应用场景中。通过合理配置,可以平衡统计需求与系统资源的有效利用。
LinkedHashMap有一个 removeEldestEntry(Map.Entry eldest)方法,通过覆盖这个方法,加入一定的条件,满足条件返回true。当put进新的值方法返回true时,便移除该map中最老的键和值。
sqlStatMap重写了removeEldestEntry方法,来控制最大数量。
解决方案:
或者通过增加JVM的参数配置: -Ddruid.stat.sql.MaxSize=100
或者:
spring:
druid:
connectionProperties: druid.stat.sql.MaxSize=100
SpringBoot2.x会自动开启Druid的stat
有同学发现,自己的SpringBoot项目的配置文件中并没有开启stat配置,但是还是出现上面现象。
需要注意的是:SpringBoot2.x可以自动装配Druid。且会自动开启stat监控。
public class DruidFilterConfiguration {
@Bean
@ConfigurationProperties(FILTER_STAT_PREFIX)
@ConditionalOnProperty(prefix ="spring.datasource.druid.filter.stat", name = "enabled", matchIfMissing = true)
@ConditionalOnMissingBean
public StatFilter statFilter() {
return new StatFilter();
}
}
matchIfMissing = true意思是没有配置spring.datasource.druid.filter.stat=true,那么会加载该Bean。
解决方案:是在配置类中使用spring.datasource.druid.filter.stat=false,或者在自己的Configuration配置StatFilter这个bean。
当然也会自动开启监控台:
@ConditionalOnWebApplication
@ConditionalOnProperty(name = "spring.datasource.druid.stat-view-servlet.enabled", havingValue = "true", matchIfMissing = true)
public class DruidStatViewServletConfiguration {
@Bean
public ServletRegistrationBean statViewServletRegistrationBean(DruidStatProperties properties) {
DruidStatProperties.StatViewServlet config = properties.getStatViewServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean();
registrationBean.setServlet(new StatViewServlet());
registrationBean.addUrlMappings(config.getUrlPattern() != null ? config.getUrlPattern() : "/druid/*");
if (config.getAllow() != null) {
registrationBean.addInitParameter("allow", config.getAllow());
}
if (config.getDeny() != null) {
registrationBean.addInitParameter("deny", config.getDeny());
}
if (config.getLoginUsername() != null) {
registrationBean.addInitParameter("loginUsername", config.getLoginUsername());
}
if (config.getLoginPassword() != null) {
registrationBean.addInitParameter("loginPassword", config.getLoginPassword());
}
if (config.getResetEnable() != null) {
registrationBean.addInitParameter("resetEnable", config.getResetEnable());
}
return registrationBean;
}
}
可访问http://ip:端口/druid/sql.html查看控制台,默认密码没有配置。
个人疑问:1000 个为什么会导致 FULL-GC?
druid.stat.sql.MaxSize 默认值是多少?看一些默认说法是 1000?这个应该不会导致频繁 GC 才对呀?
个人的项目比较特别,属于是一个连接池的统一管理,会有很多 connect 被创建。
所以一个对象是 1000,那么 100 个呢?
所以比较好的方式,可以通过直接将对应的 stat 设置为 false。
下面我们来看一下另一个中可能性。
v2-可能性2 prepareStatement
配置
<!-- 打开PSCache,并且指定每个连接上PSCache的大小,Oracle等支持游标的数据库,打开此开关,会以数量级提升性能,具体查阅PSCache相关资料 -->
<property name="poolPreparedStatements" value="true" />
怀疑点
和上面的统计类似,这里的预处理虽然提升了性能,但是每一次都不同,会怎么样呢?
我们来网上另一种可能性的例子。
问题定位分析
一般来说,Java领域出现非bug类的问题百分之九十都是由于内存/GC出现了问题导致的。
但是具体是哪方面比如网络、上下游系统、内存泄漏等,需要具体问题具体分析,要分析问题第一步就是要获取系统的运行状态。
下面是上传文件时候的GC情况。
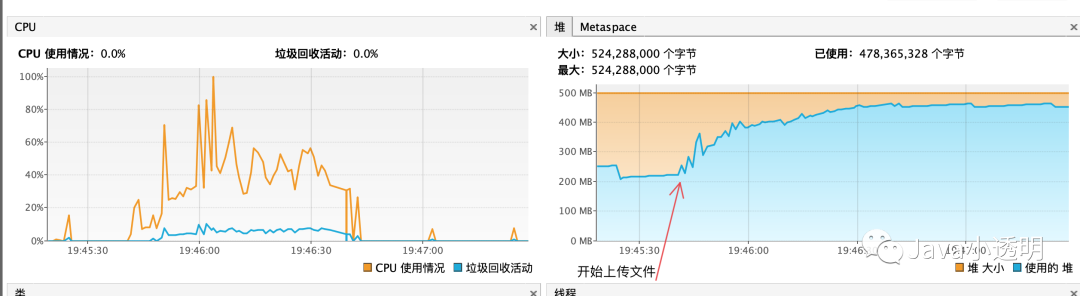
可以看出来是内存一直被占用,无法被释放(手动执行GC也不行),但是问题在于上传的请求已经结束,理论上此次上传占用的内存全部可以被回收掉,不应该出现内存占用的问题。
一般来说如果内存占用并且没有被释放掉,我的经验是有以下二种可能:
-
内存发生了泄漏,使用完对象后有全局变量引用,导致无法被GC
-
程序某个地方发生阻塞等待,导致方法栈帧里面引用的对象无法被释放,常见的有数据库阻塞
接下来就是要明确占用的内存里面到底是哪些东西?
dump下来JVM的堆内存,在jvisualvm中进行分析。
利用OQL对比较大的String进行筛选结果如下:

发现大量的String对象是SQL语句,这些就是文件解析后进行执行的SQL语句,那么问题来了,为啥这些SQL并没有被回收?
一般第一直觉出现SQL往往会联想到Mybatis框架上去,因为他是与SQL关系非常紧密的地方,但是经过对Mybatis框架代码的review过后发现,并不是Mybatis缓存的问题。当然日志中也可能出现SQL,不过也很快被我排除了。
如果说请求完成了,一般请求中产生的对象也会被释放,那么有什么是不会释放的呢?
最终想到一个:数据库连接Connection,Connection与执行SQL强相关,并且Connection一般都是从池中获取,使用完后会放回池中,与当前的现象非常的符合。
而后对sql语句的GC Root分析也证明了这一点:
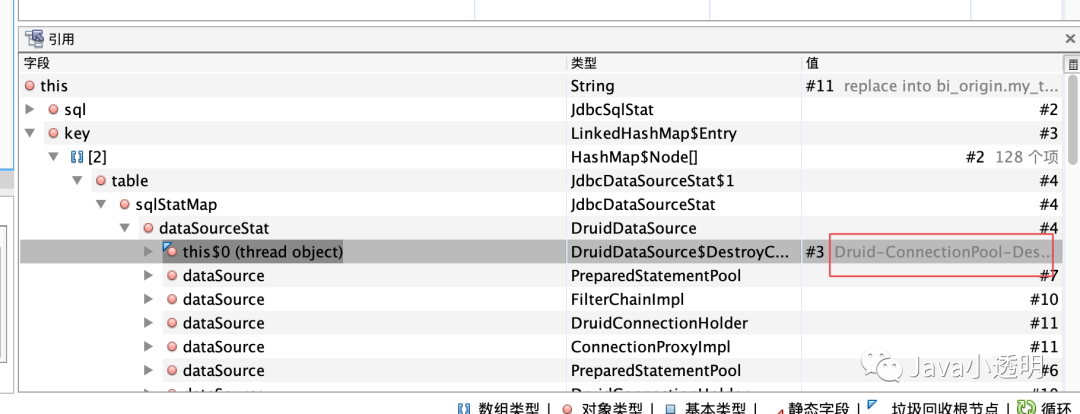
PS: 可以发现这里还是直接用 MAT 比较直观
解决方式
那么可能猜测,SQL被缓存在Connection中,并随着Connection一起被放回Connection Pool中去了,通过百度Druid的参数配置将数据源的SQL缓存关闭。
DruidDataSource dataSource = new DruidDataSource();
dataSource.setPoolPreparedStatements(false);
之后在进行一次文件上传,这时的GC就非常的丝滑,也并没有出现内存释放不掉的情况。
总结
改进方式
其实这个问题可以有其他的解决办法,但是直接修改配置是最简单并且最快恢复业务的,应该是最优先采用的。
但是从技术的角度来说不是这样,通过Druid数据源的代码review,发现Druid利用LinkedHashMap做了一个LRU Cache缓存SQL语句,Cache的容量是20个语句。
这种方式其实有个问题在于如果一个SQL语句非常大,20个SQL也可能导致内存被占用非常多。
所以其实将LRU Cache中的强引用替换成SoftReference,就可以完美解决大SQL倾斜的问题。
归纳线上问题的一般思路
线上问题的一般步骤分为 1)指标监控观察 2)分析并猜想原因 3)验证猜想。
这其中我觉得最核心的能力应该是:证据链的查找以及分析决策树的建立。
举个线上CPU占用率高的问题,下图就是应该在脑中建立起来的分析决策树,从现象到猜想到验证,而打印Stack以及查看GC日志就是证据链查找的一部分。
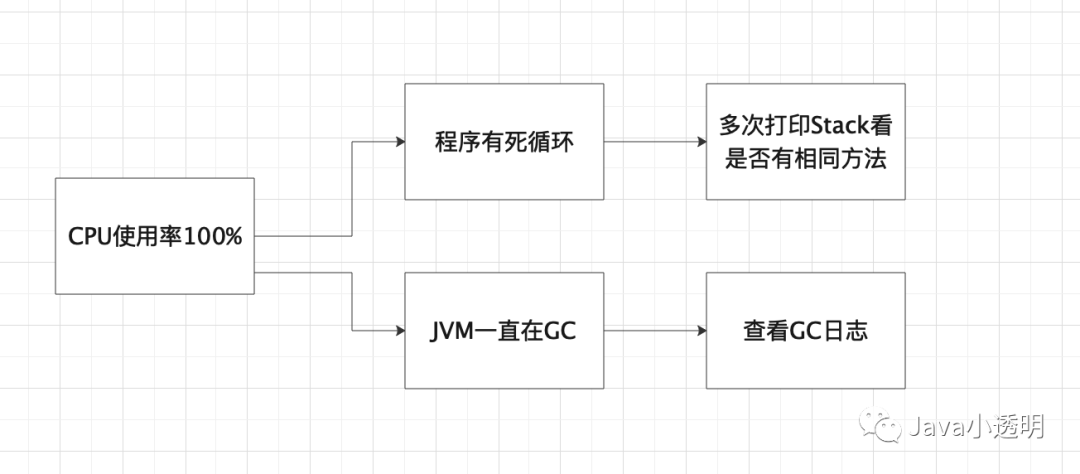
线上定位问题就是这样,改问题不难,难的是知道哪里会出问题,并且对知识广度也是有要求的,问题可能在网络、数据库、linux系统参数配置、内存等等,所以有空多看看跨领域的书也是有帮助的,哈哈。
第三篇-druid导致oracle内存溢出,druid – Oracle数据库下PreparedStatementCache内存问题解决方案…
说明
个人觉得这一篇分析写的不错,所以记录一下,作为上面的补充。
Oracle支持游标,一个PreparedStatement对应服务器一个游标,如果PreparedStatement被缓存起来重复执行,PreparedStatement没有被关闭,服务器端的游标就不会被关闭,性能提高非常显著。
在类似 SELECT * FROM T WHERE ID = ? 这样的场景,性能可能是一个数量级的提升。
由于PreparedStatementCache性能提升明显,DruidDataSource、DBCP、JBossDataSource、WeblogicDataSource都实现了PreparedStatementCache。
PreparedStatementCache带来的问题
阿里巴巴在使用jboss连接池做PreparedStatementCache时,遇到了full gc频繁的问题。
通过mat来分析jmap dump的结果,发现T4CPreparedStatement占内存很多,出问题的几个项目,有的300M,有的500M,最夸张的900M。
这些应用 都是用jboss连接池访问Oracle数据库,T4CPreparedStatement是Oracle JDBC Driver的PreparedStatement一种实现。
oracle driver不是开源,通过逆向工程以及mat分析,发现其中占内存的是字段char[] defineChars,defineChars大小的计算公式是这样的:
defineChars大小 = rowSize * rowPrefetchCount
rowPrefetchCount在Oracle中,缺省值为10。
其中rowSize是执行查询设计的每一列的大小的和。
计算公式是:
rowSize = col_1_size + col_2_size + ... + col_n_size
很悲剧,有些列数据类型是varchar2(4000),于是rowSize巨大,很多个表关联的SQL,rowSize可能高达数十K,再乘以 rowPrefetchCount,defineChars大小接近1M。
可以想想,maxPoolSize设置为 30,PreparedStatementCacheSize设置为50的场景下,是可能导致PreparedStatementCache占据上G的内存。
实际测试得到的结果如下:
varchar2(4000) col_size 4000 chars
clob -> col_size col_size 4000 bytes
实际占据内存的公式:
占据内存大小峰值 = defineChars大小 * PreparedStatementCacheSize * MaxPoolSize
我们实际分析,一个应用运行的SQL大约数百条,PreparedStatementCacheSize为 50,PreparedStatementCache的算法为LRU,很多的SQL执行之后,在Cache中HitCount为0就被淘汰了,淘汰的过程,其位置从第1移到第50,这个漫长的过程导致了defineChars不能够被young gc回收。
Druid的解决方案
使用OracleDriver提供的PreparedStatementCache支持方法,清理PreparedStatement所持有的buffer。
Oracle在10.x和11.x的Driver中,都提供了如下管理PreparedStatementCache的接口,如下:
package oracle.jdbc.internal;
import java.sql.SQLException;
public interface OraclePreparedStatement extends oracle.jdbc.OraclePreparedStatement, OracleStatement {
public void enterImplicitCache() throws SQLException;
public void exitImplicitCacheToActive() throws SQLException;
public void exitImplicitCacheToClose() throws SQLException;
}
DruidDataSource在管理Oracle PreparedStatement Cache时,调用了上述方法。
当调用了enterImplicitCache之后,T4CPreparedStatement中的 defineChars和defineBytes都会被清空。
测试表明,通过上述处理,能够有效降低内存。
根据PreparedStatement执行的结果,计算RowPrefetch大小 DrudDataSource对在PreparedStatement.executeQuery和execute方法返回的ResultSet做监控统计执行SQL返回的行数,然后根据统计的结果来设置rowPrefetchSize。
例如SQL
SELECT * FROM ORDER WHERE ID = ?
这样的SQL每次返回的纪录数量都是0或者1,根据这个统计的最大值来设置rowPrefetchSize。如果最大值为1,则需要设置rowPrefetchSize为2。
计算公式如下:
int maxRowFetchCount = max(resultSet.size) + 1;
if (maxRowFetchCount > defaultRowPrefetch) {
maxRowFetchCount = defaultRowPreftech;
}
prearedStatement.rowPrefetch = maxRowFetchCount;
根据生产环境的监控统计,大多数的SQL返回的行数都是比较小的,通常是1。
通过这种算法,能够减少PreparedStatementCache的内存占用。
添加PreparedStatementCache计数器 包括:
PreparedStatementCacheCurrentSize
PreparedStatementCacheDeleteCount 缓存删除次数
PreparedStatementCacheHitCount 缓存命中次数
PreparedStatementCacheMissCount 缓存不命中次数
PreparedStatementCacheAccessCount 缓存访问次数
通过这五个计数器,我们清晰了解PreparedStatementCache的工作情况,然后根据实际情况调整。
参考资料
惨遭DruidDataSource和Mybatis暗算,导致OOM
https://www.jianshu.com/p/fb37ab115121
https://blog.csdn.net/weixin_39688750/article/details/116320980
