Memgraph 中的复制原理
在生产环境中,确保数据和操作的连续可用性非常关键,而这可以通过多种方式实现。
在 Memgraph 中,采用了 复制(Replication) 机制作为解决方案。
分布式系统理论中的 CAP 定理(又称 Brewer 定理)指出,任何分布式系统在以下三个属性中最多只能同时保证两个:
- 一致性(Consistency, C) — 在给定时间点,所有节点对数据有相同的视图。
- 可用性(Availability, A) — 所有客户端即使在部分节点故障情况下也能访问到数据。
- 分区容忍性(Partition tolerance, P) — 即使出现部分网络断开,系统仍能按预期工作。
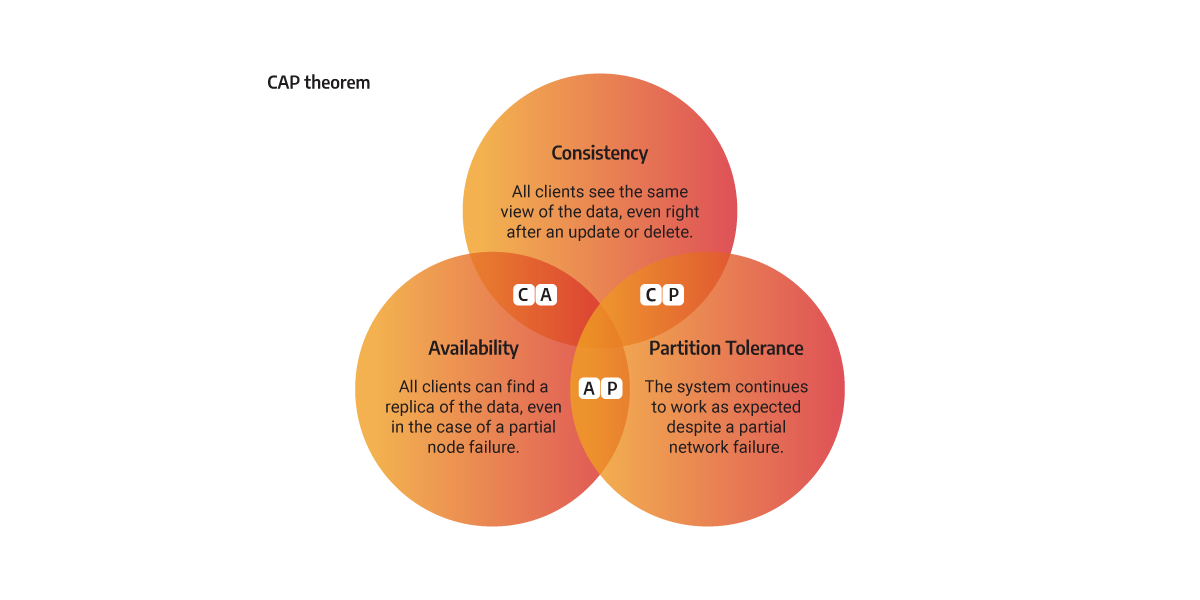
Memgraph 大多数使用场景侧重于对实时图数据运行分析型负载,由于某些共识算法(如 Raft)在试图同时满足 CAP 三属性时引入复杂性和性能开销,因此 Memgraph 选择了更简单的复制策略。
复制的本质是在一个存储节点和一个或多个其他存储节点之间进行数据复制,但这种简化意味着只能满足 CAP 中的两个属性。
Memgraph 中的实现机制
要启用复制,集群中必须至少有两个 Memgraph 实例,每个实例具有如下其中一种角色:
- MAIN 实例 — 接受读写请求
- REPLICA 实例 — 接受只读请求,并从 MAIN 持续拉取更新
💡 MAIN 实例 同时支持读和写操作,而 REPLICA 实例 只响应读操作。
启动集群时,所有实例默认为 MAIN。
配置复制集群时,必须手动指定一个实例为 MAIN,并将其他实例降级为 REPLICA。每个 REPLICA 实例通过监听某个端口运行一个 RPC 复制服务器来接收来自 MAIN 的数据。
MAIN 向 REPLICA 复制数据时,可采用三种不同模式:SYNC、ASYNC 或 STRICT_SYNC。复制模式决定了 MAIN 在提交数据库更改时的条件,从而影响系统在一致性和可用性间的权衡。

复制模式
复制模式定义了 MAIN 如何在提交更改时与 REPLICA 协作,从而偏向一致性或可用性。Memgraph 当前支持三种模式:SYNC、STRICT_SYNC 和 ASYNC。
当 REPLICA 注册并加入集群后,它会开始复制流程以追赶 MAIN 的当前状态。初始复制(首次注册 REPLICA)默认使用 ASYNC 模式。等 REPLICA 与 MAIN 达成初步同步后,复制模式将切换为注册时指定的模式。
SYNC 复制模式
在 SYNC 模式下,MAIN 提交事务后会向所有 REPLICA 发送更改,并等待它们响应或者超时。与 STRICT_SYNC 不同,即使某个 SYNC 模式的 REPLICA 不可用,MAIN 仍会继续提交事务。
这种模式不会在 REPLICA 故障时阻止写操作,同时其他 REPLICA 仍能收到更新数据。SYNC 模式保证 一致性和分区容忍性(CP),但存在非常小的数据丢失风险。若需要更强一致性,可考虑 STRICT_SYNC 模式。
STRICT_SYNC 复制模式
在 STRICT_SYNC 模式下,MAIN 不仅等待所有 REPLICA 的响应,而且如果其中某个 STRICT_SYNC REPLICA 挂掉,则 MAIN 将无法提交本地事务。为此,集群在所有实例间运行 两阶段提交协议(2PC) 以实现这种强同步。
此模式牺牲吞吐量以确保数据一致性,因此特别适用于对高可用性和故障切换无数据丢失要求极高的场景。STRICT_SYNC 同样保证 一致性与分区容忍性(CP)。
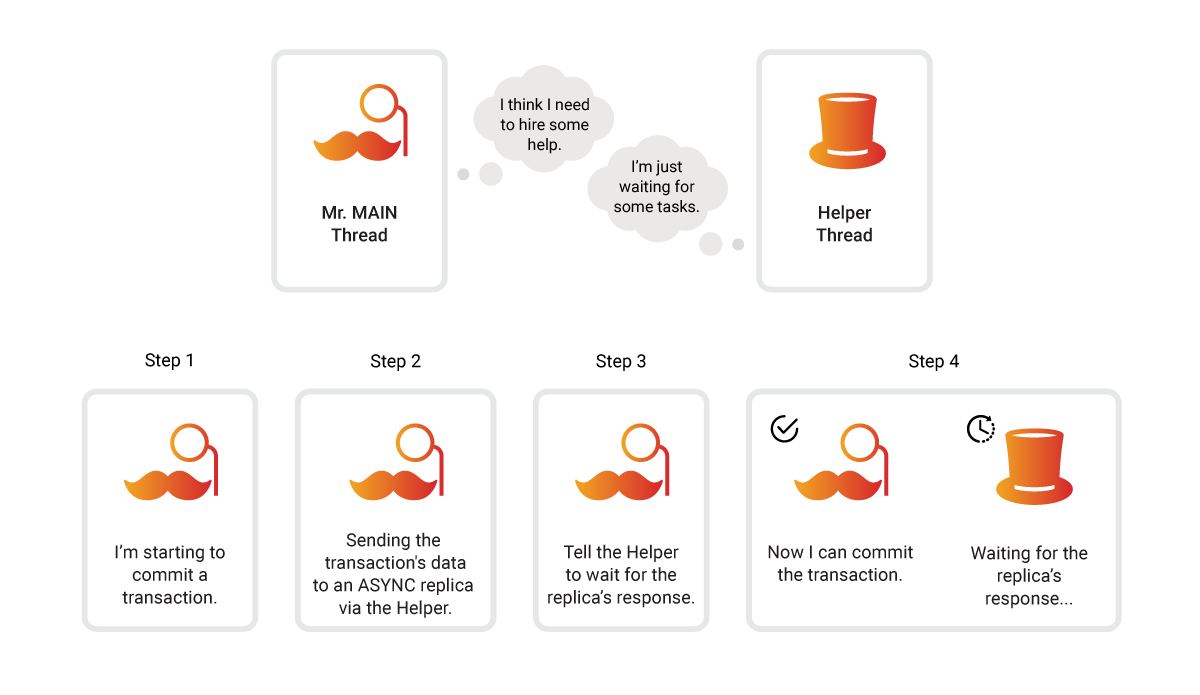
ASYNC 复制模式
在 ASYNC 模式下,MAIN 提交事务时不会等待 REPLICA 的确认,而是在后台线程发送复制任务。每个 REPLICA 都有一个永久线程与 MAIN 保持连接以接收任务,并在成功复制后发送确认。
此模式保证 可用性与分区容忍性(AP),但只能实现最终一致性。
REPLICA 状态机
复制过程中 REPLICA 可处于如下五种状态之一:
- READY — REPLICA 已同步所有数据
- REPLICATING — 正在接收事务并复制;成功后将回到 READY,否则转为 INVALID
- INVALID/BEHIND — REPLICA 落后于 MAIN,需要同步
- RECOVERY — MAIN 检测到落后状态后进入该状态,正在传输耐久性文件以追赶 MAIN
- DIVERGED — 在手动故障切换时可能出现的状态,需要管理员进行冲突解决和恢复,才能转为 READY
REPLICA 本身不会主动判断其状态。MAIN 通过 RPC 心跳监控 REPLICA 并决定其当前状态,同时负责触发同步机制。
实例同步机制
要理解实例之间如何保持数据同步,需要先理解 Memgraph 中被复制的基本耐久性实体:
- 快照(Snapshots) — 全库状态的某一时间点镜像
- 预写日志(WAL, Write-Ahead Logs) — 追加式日志文件,保存已提交的增量更改
- 增量对象(Delta objects) — 事务中产生的最小原子更新单元(例如节点、边或属性的增删改)
Memgraph 会尽可能优先传输 WAL,因为它比完整快照体积小。在理想情况下,当 REPLICA 保持同步时,MAIN 只向其发送增量对象,并且 REPLICA 会从 READY → REPLICATING → READY。
若 REPLICA 落后(INVALID),MAIN 会发送缺失的数据,以 WAL 或快照方式进行恢复。发送完成后 REPLICA 状态转为 READY。
多租户复制(Enterprise)
在启用了多租户的 Enterprise 环境中,每个数据库(即租户)都有唯一的 UUID。复制过程中,耐久性文件会附带对应的数据库 UUID,使得 REPLICA 能正确应用每个租户的数据。若先在独立实例创建数据库再接入集群会导致 UUID 冲突,必须从一开始就启用复制。

高级复制话题
以下是关于内部实现的更深入技术细节:
耐久性文件的锁定机制
为了避免正在用于同步的耐久性文件被删除,Memgraph 有一个文件保留机制。当某线程锁定文件时,该文件不会被删除;删除请求将排入队列等待清理。
同时读写 WAL 文件
复制线程在发送 WAL 文件时会临时禁止刷新内部缓冲区,以避免发送不完整的数据片段。之后再恢复刷新并将缓冲区内容写入新的 WAL 文件。
时间戳一致性问题修复
为保证复制过程中 REPLICA 状态判断正确,每个全局操作必须分配唯一时间戳;REPLICA 不会为只读操作增加时间戳以避免干扰快照隔离。
Epoch ID 与时间戳补充机制
每次实例成为 MAIN 时都会分配唯一的 epoch_id,用于检测复制兼容性,防止旧 MAIN 恢复后错误地与现 MAIN 建立重新复制关系。
系统数据复制
除图数据外(节点、关系、索引等),系统级数据(如身份验证结构)在 Enterprise 版中也可复制,使 REPLICA 成为完整一致的读取副本。(memgraph.com)
如需继续翻译后续子章节,例如 设置 Docker 复制集群 或 复制命令参考,请告知要翻译的部分名称。
参考资料
https://memgraph.com/docs/clustering/replication/how-replication-works
