数据处理
本文详细介绍了 Milvus 中数据插入、索引建立和数据查询的实现。
数据插入
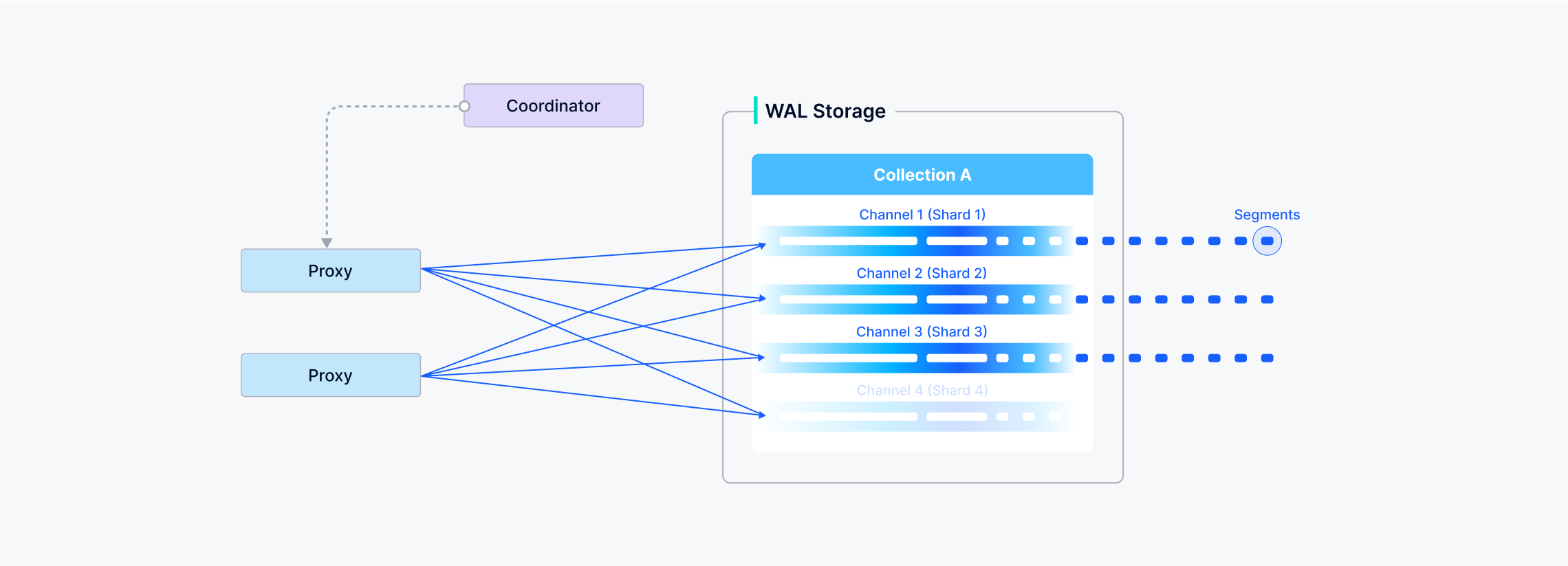
在 Milvus 中,你可以选择一个 Collections 使用多少个分片–每个分片映射到一个虚拟通道(vchannel)。
如下图所示,Milvus 会将每个vchannel分配给一个物理通道(pchannel),每个pchannel绑定到一个特定的流节点。
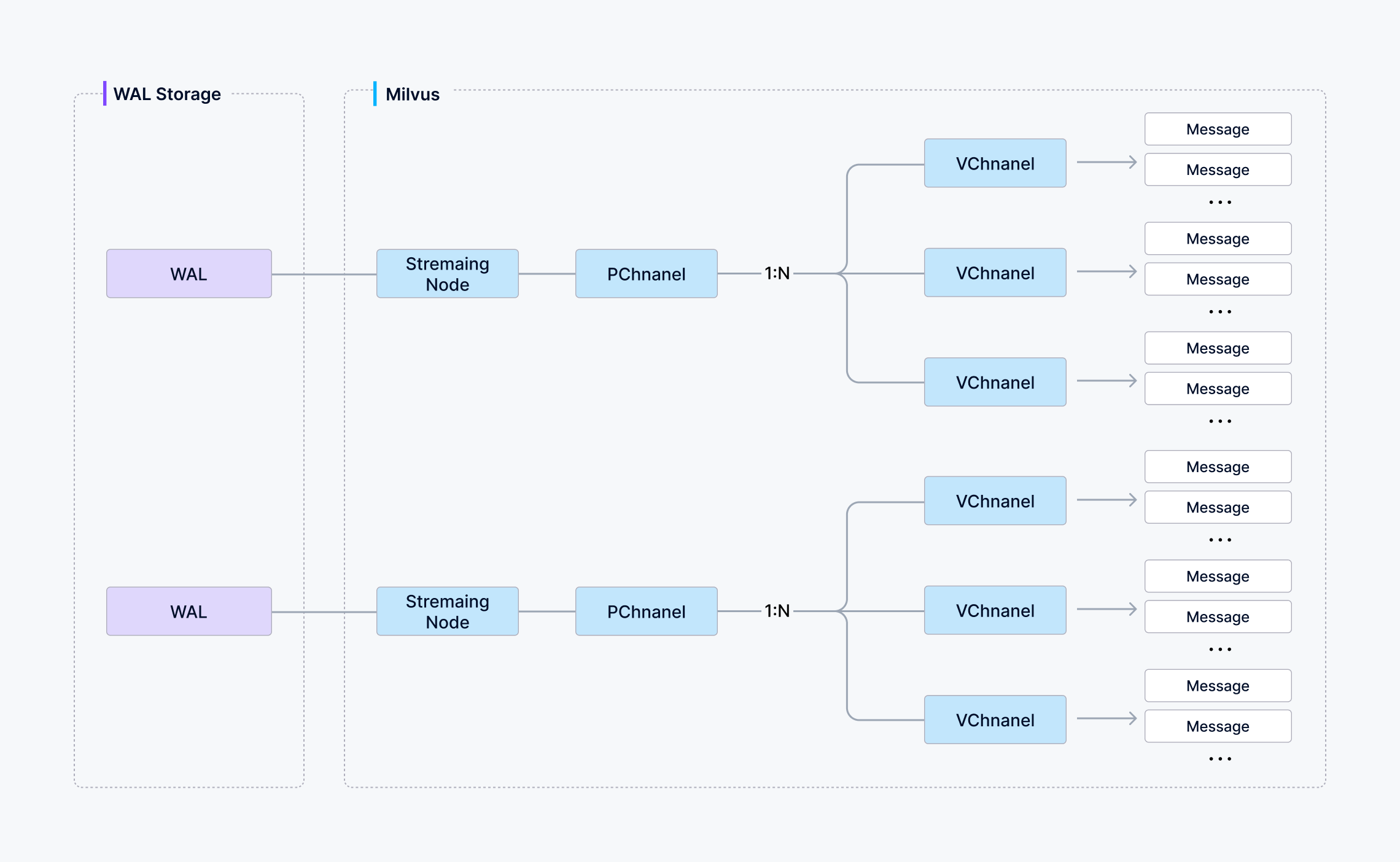
数据验证后,代理会根据指定的分片路由规则将写入的信息拆分成不同的数据包分片。
然后将一个分片(vchannel)的写入数据发送到pchannel 对应的流节点。
流节点为每个数据包分配一个时间戳 Oracle (TSO),以建立总的操作排序。
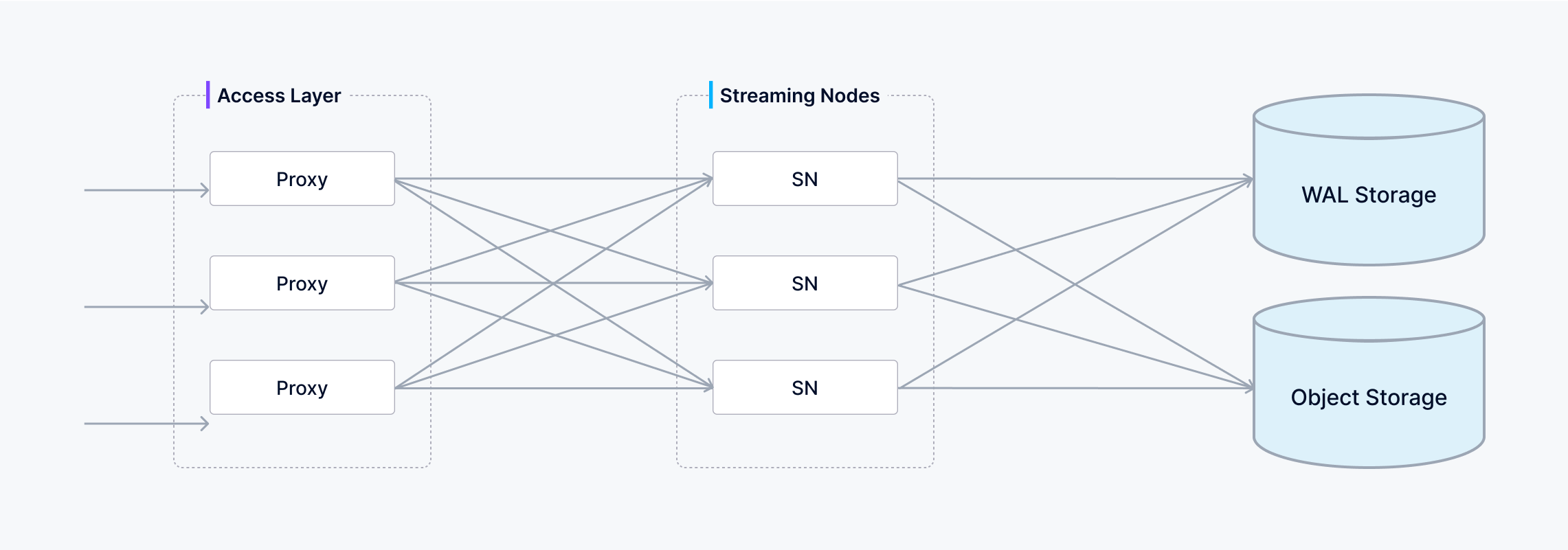
在将有效负载写入底层先写日志(WAL)之前,它会对有效负载执行一致性检查。一旦数据持久地提交到 WAL,就能保证不会丢失–即使发生崩溃,流节点也能重放 WAL 以完全恢复所有待处理操作。
与此同时,流节点还能异步地将已提交的 WAL 条目切分成不连续的段。有两种分段类型:
- 增长段:任何尚未预存到对象存储中的数据。
- 密封段:所有数据都已持久化到对象存储中,密封段的数据是不可变的。
从增长数据段过渡到密封数据段的过程称为刷新。一旦流节点摄取并写入了该分段的所有可用 WAL 条目,即底层先写日志中没有更多待处理记录时,流节点就会触发刷新,此时该分段就会最终确定并优化读取。
建立索引
索引建立由数据节点执行。
为了避免频繁为数据更新建立索引,Milvus 将 Collections 进一步划分为多个分段,每个分段都有自己的索引。

Milvus 支持为每个向量场、标量场和主场建立索引。索引构建的输入和输出都与对象存储有关:数据节点将要建立索引的日志快照从段落(在对象存储中)加载到内存,反序列化相应的数据和元数据以建立索引,索引建立完成后序列化索引,并将其写回对象存储。
索引构建主要涉及向量和矩阵操作,因此是计算和内存密集型操作。向量因其高维特性,无法用传统的树形索引高效地建立索引,但可以用这方面比较成熟的技术建立索引,如基于集群或图形的索引。无论其类型如何,建立索引都涉及大规模向量的大量迭代计算,如 Kmeans 或图遍历。
与标量数据的索引不同,建立向量索引必须充分利用 SIMD(单指令、多数据)加速。Milvus 天生支持 SIMD 指令集,例如 SSE、AVX2 和 AVX512。考虑到向量索引构建的 “打嗝 “和资源密集性质,弹性对 Milvus 的经济性而言变得至关重要。Milvus 未来的版本将进一步探索异构计算和无服务器计算,以降低相关成本。
此外,Milvus 还支持标量过滤和主字段查询。为了提高查询效率,Milvus 还内置了布鲁姆过滤索引、哈希索引、树型索引和反转索引等索引,并计划引入更多外部索引,如位图索引和粗糙索引。
数据查询
数据查询指的是在指定的 Collections 中搜索与目标向量最接近的k个向量,或搜索与向量在指定距离范围内的所有向量。向量会连同其相应的主键和字段一起返回。
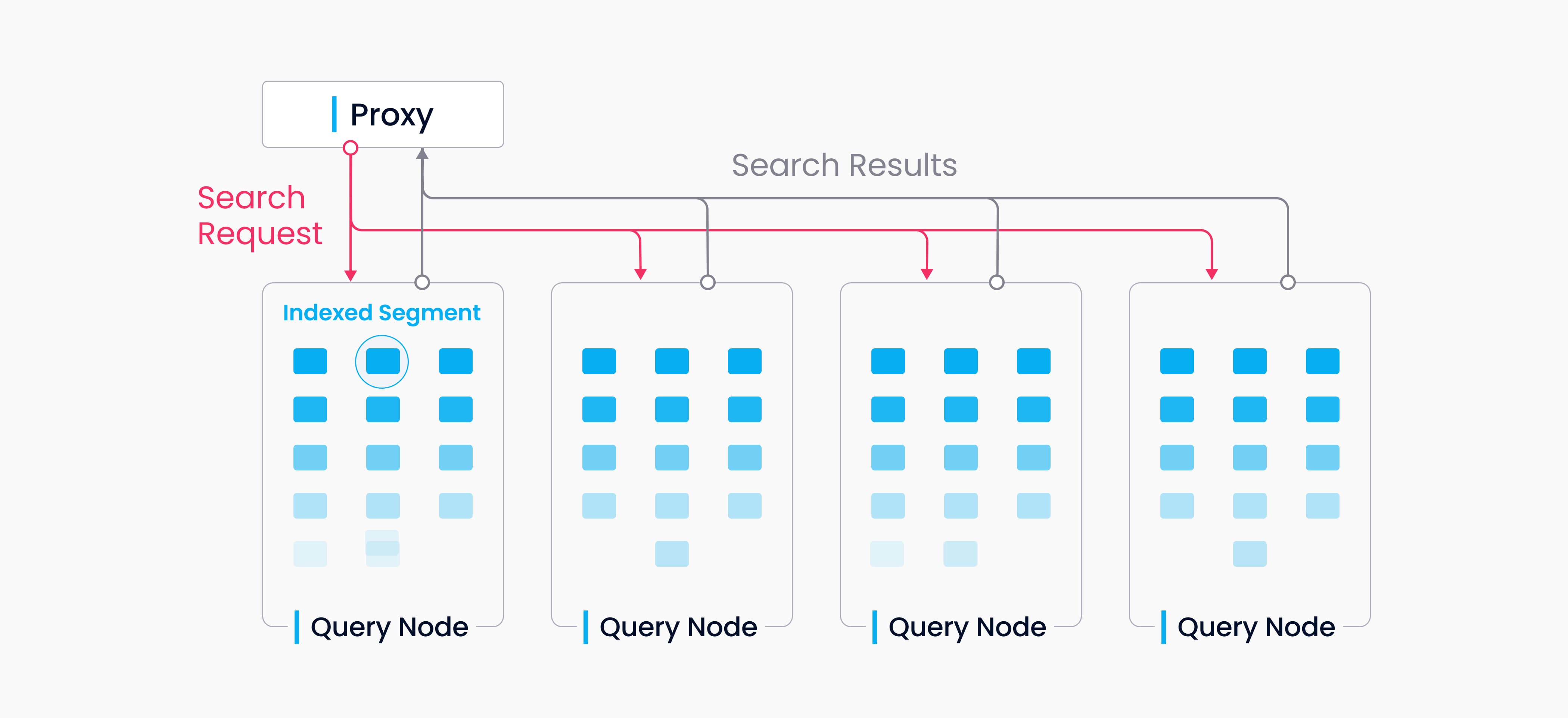
Milvus 中的 Collections 分成多个分段;流节点加载不断增长的分段并维护实时数据,而查询节点则加载封存的分段。
当收到查询/搜索请求时,代理会将请求广播给负责相关分片的所有流节点,以进行并发搜索。
当收到查询请求时,代理会同时请求持有相应分片的流节点执行搜索。
每个流节点生成一个查询计划,搜索其本地不断增长的数据,同时联系远程查询节点检索历史结果,然后将这些结果汇总为一个分片结果。
最后,代理收集所有分片结果,将其合并为最终结果,并返回给客户端。
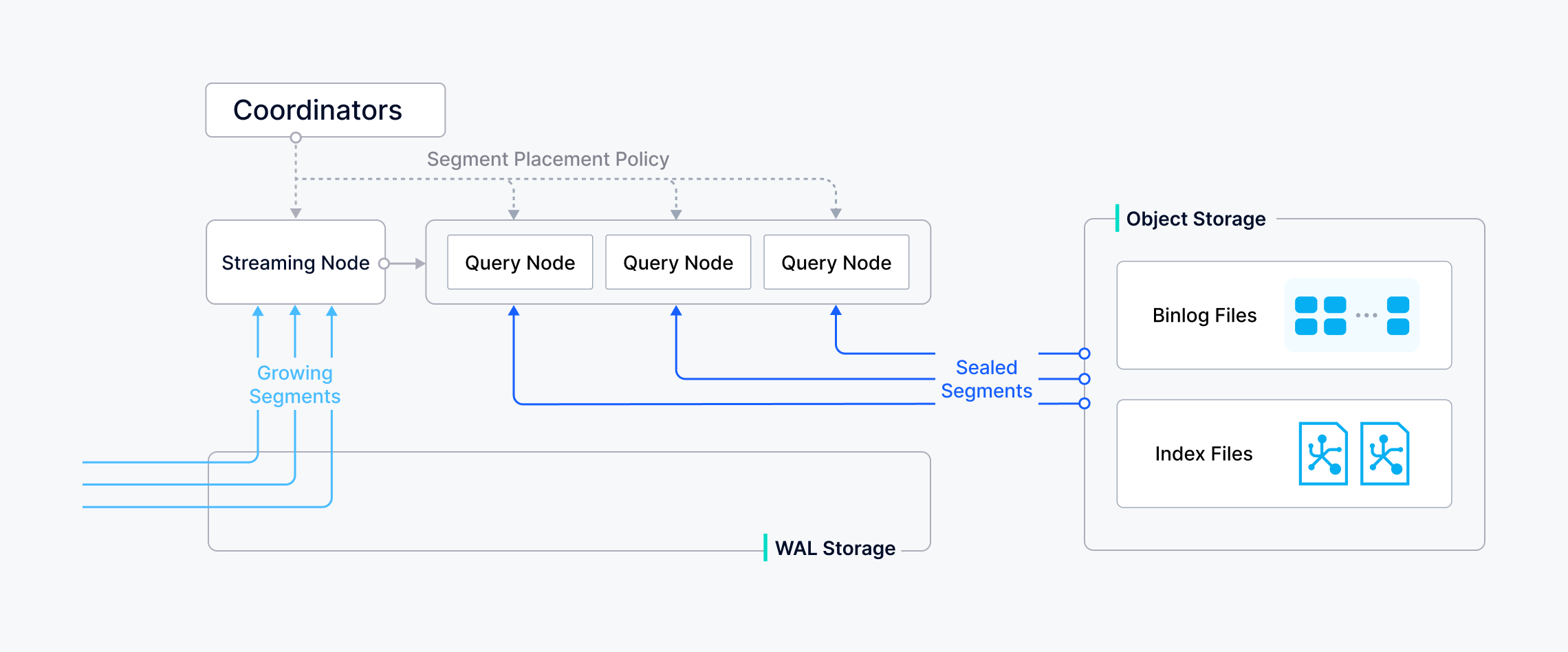
当流节点上的增长分段被刷新为密封分段时,或者当数据节点完成压缩时,协调器会启动移交操作,将增长数据转换为历史数据。
然后,协调器会在所有查询节点上平均分配密封分段,平衡内存使用率、CPU 开销和分段数,并释放任何冗余分段。
下一步
翻译自
想要更快、更简单、更好用的 Milvus SaaS服务 ?
Zilliz Cloud是基于Milvus的全托管向量数据库,拥有更高性能,更易扩展,以及卓越性价比 免费试用 Zilliz Cloud
反馈
此页对您是否有帮助?
参考资料
https://milvus.io/docs/zh/data_processing.md
