度量类型
相似度量用于衡量向量之间的相似性。选择合适的距离度量有助于显著提高分类和聚类性能。
目前, Milvus 支持这些类型的相似性度量:欧氏距离 (L2)、内积 (IP)、余弦相似度 (COSINE)、JACCARD,HAMMING 和BM25 (专门为稀疏向量的全文检索而设计)。
下表总结了不同字段类型与相应度量类型之间的映射关系。
| 字段类型 | 维度范围 | 支持的度量类型 | 默认度量类型 |
|---|---|---|---|
| FLOAT_VECTOR | 2-32,768 | COSINE,L2 、IP | COSINE |
| FLOAT16_VECTOR | 2-32,768 | COSINE,L2 、IP | COSINE |
| BFLOAT16_VECTOR | 2-32,768 | COSINE,L2 、IP | COSINE |
| INT8_VECTOR | 2-32,768 | COSINE,L2 、IP | COSINE |
| SPARSE_FLOAT_VECTOR | 无需指定维度。 | IP,BM25 (仅用于全文检索) | IP |
| BINARY_VECTOR | 8-32,768*8 | HAMMING,JACCARD 、MHJACCARD | HAMMING |
对于
SPARSE\_FLOAT\_VECTOR类型的向量场,仅在执行全文检索时使用BM25公制类型。有关详细信息,请参阅全文搜索。 对于BINARY_VECTOR类型的向量字段,维度值 (dim) 必须是 8 的倍数。
下表总结了所有支持的度量类型的相似性距离值特征及其取值范围。
| 度量类型 | 相似性距离值的特征 | 相似性距离值范围 |
|---|---|---|
| L2 | 值越小表示相似度越高。 | [0, ∞) |
| IP | 值越大,表示相似度越高。 | [-1, 1] |
| COSINE | 数值越大,表示相似度越高。 | [-1, 1] |
| JACCARD | 值越小,表示相似度越高。 | [0, 1] |
| MHJACCARD | 根据 MinHash 签名位估算 Jaccard 相似度;距离越小 = 越相似 | [0, 1] |
| HAMMING | 值越小表示相似度越高。 | [0,dim(向量) |
| BM25 | 根据术语频率、反转文档频率和文档规范化对相关性进行评分。 | [0, ∞) |
要在 “结构数组” 字段中索引向量字段,应根据存储在这些字段中的向量嵌入,将 MAX_SIM 作为上述度量类型集的前缀。例如:
- 对于存储
FLOAT_VECTOR,FLOAT16_VECTOR,BFLOAT16_VECTOR, 或INT8_VECTOR类型的向量嵌入的向量字段,可以使用MAX_SIM_COSINE,MAX_SIM_IP, 或MAX_SIM_L2作为度量类型。 - 对于存储
BINARY_VECTOR类型的向量嵌入的向量场,可以使用MAX_SIM_JACCADR或MAX_SIM_HAMMING作为度量类型。
欧氏距离(L2)
从本质上讲,欧氏距离测量的是连接两点的线段的长度。
欧氏距离的计算公式如下: ![欧氏公制]
其中 a = (a0,a1,...,an-1) 和 b = (b0,b1,...,bn-1) 是 n 维欧几里得空间中的两点。
这是最常用的距离度量,在数据连续时非常有用。
当选择欧氏距离作为距离度量时,Milvus 只计算应用平方根之前的值。
内积(IP)
两个 Embeddings 之间的 IP 距离定义如下:
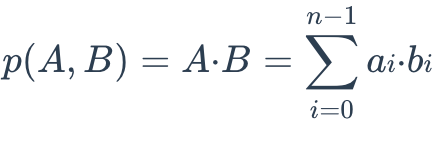
如果需要比较非标准化数据,或者需要考虑幅度和角度,IP 会更有用。
如果使用 IP 计算嵌入式之间的相似性,必须对嵌入式进行归一化处理。归一化后,内积等于余弦相似度。
假设 X’ 是由嵌入式 X 归一化而来:
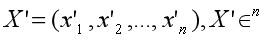
两个嵌入式之间的相关性如下:
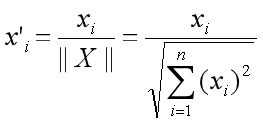
余弦相似性
余弦相似度使用两组向量之间角度的余弦来衡量它们的相似程度。你可以把两组向量看成从同一点(如 [0,0,…])出发,但指向不同方向的线段。
要计算两组向量 A = (a0,a1,...,an-1) 和 B = (b0,b1,...,bn-1) 之间的余弦相似度,请使用下面的公式:
余弦相似度总是在区间 [-1, 1] 内。例如,两个正比向量的余弦相似度为 1,两个正交向量的余弦相似度为 0,两个相反向量的余弦相似度为 -1。余弦越大,两个向量之间的夹角越小,说明这两个向量之间的相似度越高。
用 1 减去它们的余弦相似度,就可以得到两个向量之间的余弦距离。
JACCARD 距离
JACCARD 距离系数衡量两个样本集之间的相似性,其定义为定义集的交集的卡方值除以它们的联合的卡方值。它只能应用于有限样本集。
JACCARD 相似度系数公式:
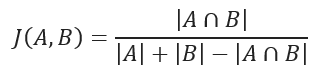
JACCARD 距离测量数据集之间的不相似性,用 1 减去 JACCARD 相似系数即可得到。
JACCARD 距离公式:
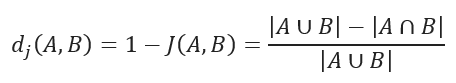
MHJACCARD
MinHash Jaccard(MHJACCARD) 是一种度量类型,用于在大型集合(如文档单词集、用户标签集或基因组 k-mer 集)上进行高效、近似的相似性搜索。MHJACCARD 不直接比较原始集,而是比较 MinHash 签名,MinHash 签名是专为高效估计 Jaccard 相似性而设计的紧凑表示法。
这种方法比计算精确的 Jaccard 相似性要快得多,尤其适用于大规模或高维场景。
适用向量类型
BINARY_VECTOR,其中每个向量存储一个 MinHash 签名。每个元素都对应于应用于原始集合的一个独立哈希函数下的最小哈希值。
距离定义 MHJACCARD 衡量两个 MinHash 签名中匹配位置的数量。匹配率越高,说明底层集越相似。
Milvus 报告:
- 距离 = 1 - 估计相似度(匹配率)
距离值从 0 到 1 不等:
- 0 表示 MinHash 签名完全相同(估计 Jaccard 相似度 = 1)
- 1 表示任何位置都不匹配(估计的 Jaccard 相似度 = 0)
有关技术细节的信息,请参阅 MINHASH_LSH。
HAMMING 距离
HAMMING 距离测量二进制数据字符串。两个长度相等的字符串之间的距离是比特不同的比特位置数。
例如,假设有两个字符串:1101 1001 和 1001 1101。
11011001 ⊕ 10011101 = 01000100。由于其中包含两个 1,因此 HAMMING 距离 d (11011001, 10011101) = 2。
BM25 相似性
BM25 是一种广泛使用的文本相关性测量方法,专门用于全文检索。它结合了以下三个关键因素:
- 术语频率 (TF):衡量术语在文档中出现的频率。虽然较高的频率通常表示较高的重要性,但 BM25 使用饱和参数 $k$ 来防止过于频繁的术语主导相关性得分。
- 反向文档频率 (IDF):反映术语在整个语料库中的重要性。在较少文档中出现的术语会获得较高的 IDF 值,这表明其对相关性的贡献更大。
- 文档长度归一化:较长的文档由于包含较多的术语,往往得分较高。BM25 通过对文档长度进行归一化处理来减轻这种偏差,参数 $b$ 控制这种归一化处理的强度。
BM25 评分的计算方法如下:
score(D, Q) = sum_{i=1}^{n} IDF(q_i) * (TF(q_i, D) * (k1 + 1)) / (TF(q_i, D) + k1 * (1 - b + b * |D| / avgdl))
参数描述
- $Q$:用户提供的查询文本。
- $D$:被评估的文档。
- $TF(q_i, D)$:术语频率,表示术语 $q_i$ 在文档 $D$ 中出现的频率。
- $IDF(q_i)$:反向文档频率,计算公式为
$IDF(q_i)=\log({N-n(q_i)+0.5\over n(q_i)+0.5} + 1)$,其中 $N$ 是语料库中的文档总数,$n(q_i)$ 是包含术语 $q_i$ 的文档数。 -
$ D $:文档长度 $D$(术语总数)。 - $avgdl$:语料库中所有文档的平均长度。
- $k_1$:控制词频对评分的影响。数值越大,词频越重要。典型的范围是 [1.2, 2.0],而 Milvus 允许的范围是 [0, 3]。
- $b$:控制长度归一化的程度,范围从 0 到 1。当值为 0 时,不进行归一化处理;当值为 1 时,进行完全归一化处理。
参考资料
https://milvus.io/docs/zh/metric.md
