
NLP 中文拼写检测纠正论文-02-2019-SOTA简繁中文拼写检查工具:FASPell Chinese Spell Checker (Chinese Spell Check / 中文拼写检错 / 中文拼写纠错 / 中文拼写检查) 论文翻译
拼写纠正系列
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计和开源实现。
FASPell
FASPell:一种基于DAE解码器范式的快速、适应性强、简单、强大的中文拼写检查器
作者: Yuzhong Hong, Xianguo Yu, Neng He, Nan Liu, Junhui Liu
单位: 爱奇艺智能平台部
电子邮件: {hongyuzhong, yuxianguo, heneng, liunan, liujunhui}@qiyi.com
摘要:
我们提出了一种中文拼写检查器——FASPell,基于一种新的范式,该范式由去噪自动编码器(DAE)和解码器组成。
与之前的最先进模型相比,这种新范式使我们的拼写检查器在计算上更快,能够方便地适应简体和繁体中文文本(无论是人类还是机器生成的),并且结构更加简化,同时在错误检测和修正方面仍然非常强大。这四个成就得以实现,主要是因为该新范式绕过了两个瓶颈。
首先,DAE通过利用无监督预训练的掩码语言模型(如BERT、XLNet、MASS等)的能力,减少了监督学习所需的中文拼写检查数据量(减少到 1的情况。为了将其简化为前面描述的最简单情况,我们根据上下文信心对每个原始字符的候选字符进行排序,并将排名相同的候选字符放入同一组(即总共c组)。
因此,我们可以为每组候选字符找到如前所述的过滤器。所有c个过滤器的组合进一步缓解了召回损害,因为更多的候选字符被考虑进来。
在图1的示例中,候选字符有c = 4组。我们从排名为1的组中获得正确的替代丰 → 主,从排名为2的组中获得另一个正确的替代苦 → 著,而从其他两组中则没有得到更多的替代。
- 图3
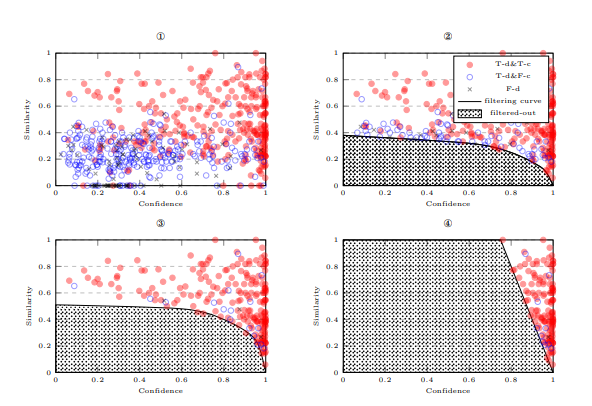
Figure 3: 所有四个图都展示了相同的信心-相似度候选图,其中候选字符被分类为真实检测和真实修正(T-d&T-c)、真实检测和错误修正(T-d&F-c)以及错误检测(F-d)。
但是,每个图展示了不同的候选过滤方式:
- 图①:没有过滤任何候选字符。
- 图②:过滤优化检测性能。
- 图③:如FASPell中所采用的,过滤优化修正性能。
- 图④:如之前的模型所采用的,候选字符通过设置加权信心和相似度的阈值进行过滤(例如:0.8 × 信心 + 0.2 × 相似度 < 0.8)。
需要注意的是,这四个图使用了我们OCR数据集(T rnocr)中的实际首选候选字符(使用视觉相似度计算),不过我们仅随机抽取了30%的候选字符进行绘制,以便在纸面上展示时更加清晰可见。
3 实验与结果
我们首先在3.1节中描述实验中采用的数据、指标和模型配置。然后,在3.2节中,我们展示了在人工编写的文本拼写检查上的表现,并将FASPell与以前的最先进模型进行比较;同时也展示了从OCR结果中收集的数据,证明该模型的适应性。在3.3节中,我们比较了FASPell与三个最先进模型的速度。在3.4节中,我们研究了超参数如何影响FASPell的性能。
3.1 数据、指标和配置
我们采用了基准数据集(均为繁体中文)和由SIGHAN13-15中文拼写检查共享任务提供的句子级准确率、精确率、召回率和F1值(Wu等,2013;Yu等,2014;Tseng等,2015)。此外,我们还从中文视频字幕的OCR结果中收集了4575个句子(其中4516个为简体中文)。
我们使用了Shi等(2017)提出的OCR方法。
详细的数据统计见表3。
- 表3:数据集统计
| 数据集 | 错误句子数 | 句子总数 | 平均长度 |
|---|---|---|---|
| T rn13 | 350 | 700 | 41.8 |
| T rn14 | 3432 | 3435 | 49.6 |
| T rn15 | 2339 | 2339 | 31.3 |
| T st13 | 996 | 1000 | 74.3 |
| T st14 | 529 | 1062 | 50.0 |
| T st15 | 550 | 1100 | 30.6 |
| T rnocr | 3575 | 3575 | 10.1 |
| T stocr | 1000 | 1000 | 10.2 |
我们使用了Devlin等(2018)提供的预训练掩蔽语言模型。其超参数和预训练设置可以在https://github.com/google-research/bert 中找到。
在我们主要实验(3.2节 - 3.3节)中使用的FASPell的其他配置见表4。在消融实验中,除非移除了CSD,否则使用相同的配置;如果移除CSD,则默认输出为排名第一的候选项。
需要注意的是,我们没有对OCR数据进行掩蔽语言模型的微调,因为在初步实验中,我们发现微调会导致这类数据的性能下降。
- 表4:FASPell的配置
| FT | CSD | 测试集 | r(轮数) | c(候选数) | FT步数 |
|---|---|---|---|---|---|
| U − T st13 | U − T st14 | U − T st15 | T rn13 | T rn14 | T rn15 |
说明:
- FT:表示微调的训练集。
- CSD:表示CSD训练集。
- r:表示每个字符的轮数。
- c:表示每个字符的候选数。
- U:表示来自SIGHAN13-15的所有拼写检查数据的并集。
3.2 性能
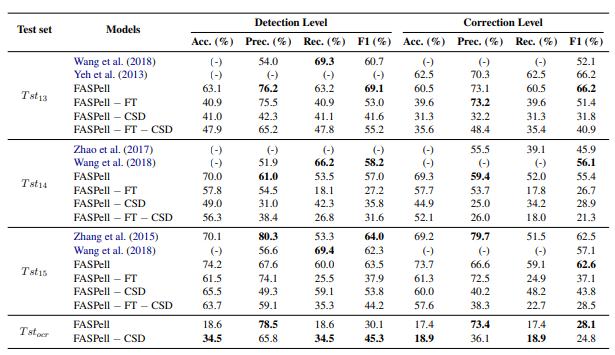
如表6所示,FASPell在检测级别和修正级别上都达到了最先进的F1性能。
注意:FASPell的速度是多轮平均值。
在精度方面,FASPell优于Wang等人(2018)的模型,在召回率方面则优于Zhang等人(2015)的模型。与Zhao等人(2017)的模型相比,FASPell在任何一个指标上都表现更好。
对于OCR数据,FASPell的精度也达到了可比水平。OCR数据上的召回率较低,部分原因是许多OCR错误即使是人类也很难纠正(Wang等,2018)。
表6还显示,FASPell的所有组件都对其良好的性能作出了有效贡献。没有进行微调和CSD的FASPell本质上就是预训练的掩蔽语言模型。对其进行微调可以提高召回率,因为FASPell可以学习常见的错误及其修正方式。CSD则通过最小化对召回率的损害来提高精度,因为这是CSD设计的基本原理。
- 表5:速度比较(毫秒/句)
| 测试集 | FASPell | Wang等人(2018) |
|---|---|---|
| T st13 | 446 | 680 |
| T st14 | 284 | 745 |
| T st15 | 177 | 566 |
- 表6:拼写检查性能(包括检测级别和修正级别)
此表展示了我们模型FASPell在检测级别和修正级别上的拼写检查表现。FASPell与之前的最先进模型表现相似。
需要注意的是,微调(FT)和CSD的确都有效地提升了其性能,具体表现可以从消融实验的结果中看到。(“− FT”表示移除微调;“− CSD”表示移除CSD。)
请根据实际数据填写表格内容。
3.3 过滤速度
首先,我们测量了中文拼写检查的过滤速度,单位为每句的绝对时间消耗(见表5)。
我们通过与Wang等人(2018)模型的速度对比进行此比较,因为他们已经报告了其绝对时间消耗。表5清晰地显示了FASPell明显更快。
其次,为了将FASPell与未报告绝对时间消耗的模型(如Zhang等人,2015;Zhao等人,2017)进行比较,我们分析了时间复杂度。FASPell的时间复杂度为 ( O(scmn + sc \log c) ),其中 ( s ) 是句子长度,( c ) 是候选数,( mn ) 用于计算编辑距离,( c \log c ) 用于对候选项进行排序。Zhang等人(2015)使用了比仅编辑距离更多的特征,因此他们模型的时间复杂度包含更多因素。此外,由于我们不使用混淆集,他们模型中每个字符的候选数实际上比我们的要大: ( x \times 10 ) 与 4。因此,FASPell比他们的模型更快。
Zhao等人(2017)通过在一个由句子中每个词汇的所有候选项构成的有向图中找到单源最短路径(SSSP)来过滤候选项。他们使用的算法的时间复杂度为 ( O(|V| + |E|) ),其中 ( |V| ) 是图中顶点的数量,( |E| ) 是图中边的数量(Eppstein,1998)。
将其转换为 ( s ) 和 ( c ) 的形式,他们模型的时间复杂度为 ( O(sc + c^s) )。
这意味着,对于长句子而言,他们的模型比FASPell慢得多。
3.4 超参数探索
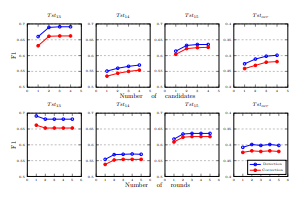
首先,我们仅改变表4中的候选数,以观察其对拼写检查性能的影响。如图4所示,当考虑更多候选项时,能够召回更多的检测和修正项,同时最大化精度。
因此,候选数的增加始终会导致F1值的提升。我们在表4中将候选数设置为 ( c = 4 ) 而不再更大,是因为这与时间消耗之间存在权衡。
其次,我们对表4中的拼写检查轮数做了相同的调整。我们可以从图4中观察到,在T st14和T st15上的修正性能在轮数为3时达到了峰值。对于T st13和T stocr,最佳轮数分别是1和2。较多的轮数有时有帮助,因为FASPell能够在每一轮检测中达到较高的精度,因此在上一轮未发现的错误可能会在下一轮被检测和修正,而不会错误地检测过多的非错误项。
4 结论
我们提出了一种中文拼写检查器——FASPell,它达到了最先进的性能。FASPell基于DAE解码器范式,仅需少量拼写检查数据,并且摒弃了麻烦的混淆集概念。以FASPell为例,我们展示了该范式的每个组件都是有效的。我们的代码和数据已经公开,地址为:https://github.com/iqiyi/FASPell。
未来的工作可能包括研究DAE解码器范式是否可以用于检测和修正语法错误或其他较少研究的中文拼写错误类型,例如方言口语(Fung等,2017)和插入/删除错误。
图4:候选数和拼写检查轮数对F1性能的影响
第一行的四个图展示了每个字符的候选数如何影响F1性能。第二行的四个图则展示了拼写检查轮数对性能的影响。
致谢
作者感谢匿名评审人提出的宝贵意见。
同时,我们也感谢爱奇艺(iQIYI)公司IT基础设施团队提供的硬件支持。
特别感谢早稻田大学(Waseda University)IPS研究生院的Yves Lepage教授,感谢他对本文的深刻建议。