拼写纠正系列
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计、论文和开源实现。
感受
这一篇和我的理念很类似,其实就是汉字的三个部分:音 形 义
TODO: 不过目前义这个部分我做的还比较弱,考虑添加一个关于单个字/词的解释词库。
论文+实现
论文地址: https://arxiv.org/pdf/2105.12306v1
源码地址:https://github.com/DaDaMrX/ReaLiSe
摘要
中文拼写检查(CSC)旨在检测和修正用户生成的中文文本中的错误字符。
大多数中文拼写错误是由于语义、语音或图形上相似的字符被误用。
以往的研究注意到这一现象,并尝试利用相似关系来完成这项任务。
然而,这些方法要么依赖启发式规则,要么使用手工制作的混淆集来预测正确的字符。本文提出了一种名为REALISE的中文拼写检查器,直接利用中文字符的多模态信息。
REALISE模型通过以下两个步骤解决CSC任务:
(1)捕捉输入字符的语义、语音和图形信息;
(2)选择性地混合这些模态的信息来预测正确的输出。在SIGHAN基准测试上的实验结果表明,所提出的模型显著优于强基线模型。
1 引言
中文拼写检查(CSC)任务旨在识别错误字符并生成候选修正。
由于其在搜索查询修正(Martins和Silva,2004;Gao等,2010)、光学字符识别(OCR)(Afli等,2016)、自动作文评分(Dong和Zhang,2016)等基本且广泛的应用中起到重要作用,因此受到了大量研究关注。近年来,由于大规模预训练语言模型的成功(Devlin等,2019;Liu等,2019;Yang等,2019),该任务取得了迅速的进展(Zhang等,2020;Cheng等,2020)。
在像英语这样的字母语言中,拼写错误通常是由于一个或多个字符错误,导致写出的单词不在字典中(Tachibana和Komachi,2016)。然而,在中文中,只要字符能够在计算机系统中输入,它们就被认为是有效的,这导致拼写错误实际上是在计算机语言处理中被误用的字符。考虑到汉字的构成,其中一些字符最初是象形字或形声字(Jerry,1988)。因此,在中文中,拼写错误不仅是语义上混淆的误用字符,还可能是语音或图形上相似的字符(Liu等,2010,2011)。表1展示了两个中文拼写错误的例子。第一个例子中,“平”(flat)所需的语音信息可以帮助我们得到正确的字符“瓶”(bottle),因为它们共享相同的发音“píng”。第二个例子不仅需要语音信息,还需要错误字符“轻”(light)的图形信息。正确的字符“经”(go)与“轻”具有相同的右部偏旁,并且发音相似(“qīng”和“jīng”)。
因此,考虑到中文的内在特性,在CSC任务中,充分利用中文字符的语音和图形知识,以及文本语义是至关重要的。
表1:中文拼写错误的两个示例及其候选修正
| 类型 | 示例句子 | 错误候选 | 正确候选 | 翻译 |
|---|---|---|---|---|
| 语音相似错误 | 晚饭后他递给我一平(píng, flat)红酒。 | 晚饭后他递给我一杯(bēi, cup)红酒。 ✗ | 晚饭后他递给我一瓶(píng, bottle)红酒。 ✓ | He handed me a bottle of red wine after dinner. |
| 图形相似错误 | 每天放学我都会轻(qīng, light)过这片树林。 | 每天放学我都会路(lù, pass)过这片树林。 ✗ | 每天放学我都会经(jīng, go)过这片树林。 ✓ | I go through this wood every day after school. |
在表格中,“Sent.” 是指示原句,“Cand.” 是候选修正,“Trans.” 是英文翻译。错误字符、候选字符和正确字符在颜色上有所区分:错误字符为红色,候选字符为橙色,正确字符为蓝色。
在本文中,我们提出了REALISE(阅读、听力和视觉),一种中文拼写检查器,它利用语义、语音和图形信息来纠正拼写错误。REALISE模型采用了三个编码器来学习文本、语音和视觉模态的有用表示。首先,BERT(Devlin et al., 2019)作为语义编码器的骨干,用于捕捉文本信息。对于语音模态,我们使用汉语拼音(pinyin),即中文字符发音的拼音化拼写系统,作为语音特征。我们设计了一个分层编码器来处理拼音字母,在字符级别和句子级别上分别进行处理。与此同时,对于视觉模态,我们通过多通道的字符图像来构建图形特征,每个通道对应一种特定的中文字体。然后,我们使用ResNet(He et al., 2016)块对这些图像进行编码,从而得到字符的图形表示。
在获得三种不同模态的表示后,一个挑战是如何将它们融合为一个紧凑的多模态表示。为此,我们设计了一个选择性模态融合机制,用于控制每种模态的信息流向混合表示的程度。此外,鉴于预训练-微调程序已经被证明在各种NLP任务中有效(Devlin et al., 2019; Dong et al., 2019; Sun et al., 2020),我们提出通过在对应模态中预测正确字符来预训练语音和图形编码器。
我们在SIGHAN基准数据集(Wu et al., 2013; Yu et al., 2014; Tseng et al., 2015)上进行了实验。通过利用多模态信息,REALISE大幅超越了所有之前的最先进模型。与之前使用混淆集(Lee et al., 2019)来捕获字符相似性关系的方法(如SOTA SpellGCN(Cheng et al., 2020))相比,REALISE在检测级别和修正级别的F1值分别提高了平均2.4%和2.6%。进一步的分析表明,我们的模型在处理那些未在手工混淆集中定义的错误时表现更好。这表明,利用中文字符的语音和图形信息能更好地捕捉易被误用的字符。
总之,本文的贡献包括:
(i) 我们提出在中文拼写检查任务中除了文本语义外,还利用中文字符的语音和图形信息;
(ii) 我们引入了选择性融合机制来整合多模态信息;
(iii) 我们提出了语音和视觉预训练任务,进一步提升模型性能;
(iv) 据我们所知,所提出的REALISE模型在SIGHAN中文拼写检查基准测试中取得了最佳结果。
2 相关工作
2.1 中文拼写检查
中文拼写检查(CSC)任务是检测和纠正中文句子中的拼写错误。
早期的研究设计了各种规则来处理不同类型的错误(Chang 等, 2015;Chu 和 Lin, 2015)。
随后,传统的机器学习算法被引入到该领域,如条件随机场(Conditional Random Field)和隐马尔可夫模型(Hidden Markov Model)(Wang 和 Liao, 2015;Zhang 等, 2015)。随后,基于神经网络的方法在中文拼写检查中取得了显著进展。
Wang 等(2018)将 CSC 任务视为序列标注问题,并使用双向 LSTM 来预测正确的字符。
随着大规模预训练语言模型(如 BERT(Devlin 等, 2019))的成功,Hong 等(2019)提出了 FASpell 模型,该模型使用基于 BERT 的去噪自编码器来生成候选字符,并利用一些经验度量来选择最可能的候选字符。
此外,Soft-Masked BERT 模型(Zhang 等, 2020)采用级联架构,其中 GRU 用于检测错误位置,BERT 用于预测正确的字符。
一些先前的工作(Yu 和 Li, 2014;Wang 等, 2019;Cheng 等, 2020)使用手工制作的中文字符混淆集(Lee 等, 2019),旨在通过发现易错字符的相似性来纠正错误。
Wang 等(2019)利用指针网络(Vinyals 等, 2015)从混淆集中选择正确的字符。
Cheng 等(2020)提出了 SpellGCN 模型,该模型通过图卷积网络(GCNs)(Kipf 和 Welling, 2016)在混淆集上建模字符相似性。
然而,字符混淆集是预定义且固定的,无法覆盖所有的相似关系,也无法区分中文字符之间的相似性差异。
在本工作中,我们摒弃了预定义的混淆集,直接利用多模态信息来发现所有中文字符之间微妙的相似关系。
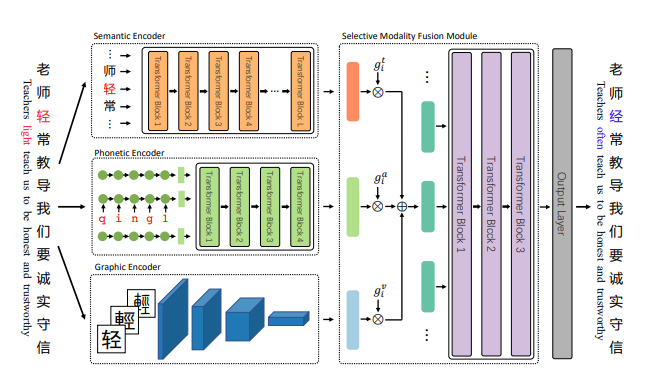
图1:REALISE模型的架构概览。语义、语音和图形编码器分别用于捕捉文本、声音和视觉模态的信息。融合模块选择性地融合来自三个编码器的信息。
在示例输入中,为了纠正错误字符“轻”(qīng,轻),我们不仅需要上下文的文本信息,还需要该字符本身的语音和图形信息。
2.2 多模态学习
近年来,许多研究致力于整合来自不同模态的信息,以提高性能。
例如,多模态情感分析(Zadeh 等人,2016;Zhang 等人,2019)、视觉问答(Antol 等人,2015;Chao 等人,2018)和多模态机器翻译(Hitschler 等人,2016;Barrault 等人,2018)等任务已经取得了很大进展。
最近,提出了多模态预训练模型,如 VL-BERT(Su 等人,2020)、Unicoder-VL(Li 等人,2020)和 LXMERT(Tan 和 Bansal,2019)。
为了将汉字的视觉信息融入语言模型,Meng 等人(2019)设计了 Tianzige-CNN,以促进一些自然语言处理任务,如命名实体识别和句子分类。
据我们所知,本文是首个利用多模态信息来解决中文拼写检查任务的研究。
3 REALISE 模型
在本节中,我们介绍了 REALISE 模型,该模型利用语义、语音和图形信息来区分汉字的相似性并纠正拼写错误。
如图 1 所示,首先采用多个编码器从文本、声音和视觉模态中捕获有价值的信息。
然后,我们开发了一个选择性模态融合模块,以获得上下文感知的多模态表示。最后,输出层预测错误修正的概率。
3.1 语义编码器
我们采用 BERT(Devlin 等人,2019)作为语义编码器的骨干。
BERT 提供了丰富的上下文词表示,并在大规模语料上进行了无监督预训练。
输入的标记 ( X = (x_1, \dots, x_N) ) 首先通过输入嵌入投影到 ( H_t^0 )。
然后,Transformer(Vaswani 等人,2017)编码器层的计算可以表示为:
[ H_t^l = \text{Transformer}^l(H_t^{l-1}), l \in [1, L] ] 其中,L 是 Transformer 层的数量。每一层由一个多头注意力模块和一个带有残差连接(He 等人,2016)以及层归一化(Ba 等人,2016)的前馈网络组成。
最后一层的输出 ( H_t = H_t^L = (h_t^1, \dots, h_t^N) ) 被用作输入标记在文本模态中的上下文化语义表示。
3.2 语音编码器
汉语拼音(pinyin)是将汉字“拼音化”的拼音系统,用于表示汉字的发音。我们在本文中使用拼音来计算语音表示。
一个汉字的拼音由三个部分组成:声母、韵母和声调。声母(共 21 个)和韵母(共 39 个)用英语字母表示。5 种声调(以“a”字母为例,{a, ¯a, ´a, ˇa, a `})可以映射为数字 {1, 2, 3, 4, 0}。尽管所有汉字的拼音词汇表大小是一个固定数值,但我们在 REALISE 中使用字母序列来捕捉汉字之间细微的语音差异。例如,“中”(中)和“棕”(棕)的拼音分别为“zhong”和“z¯ong”。这两个字符的发音非常相似,但含义完全不同。我们因此将拼音表示为符号序列,例如:“中”的拼音表示为 {z, h, o, n, g, 1}。我们将输入句子中第 i 个字符的拼音表示为 ( p_i = (p_{i,1}, \dots, p_{i,|p_i|}) ),其中 ( |p_i| ) 是拼音 ( p_i ) 的长度。
在 REALISE 中,我们设计了一个层次化的语音编码器,它由字符级编码器和句子级编码器组成。
字符级编码器 用于建模基本发音并捕捉字符之间细微的发音差异。
它是一个单层的单向 GRU(Cho 等人,2014),用于编码第 i 个字符 ( x_i ) 的拼音:
[ \tilde{h}i^a,j = \text{GRU}(\tilde{h}_i^a,j-1, E(p{i,j})) ]
其中,( E(p_{i,j}) ) 是拼音符号 ( p_{i,j} ) 的嵌入,( \tilde{h}_i^a,j ) 是 GRU 的第 j 个隐藏状态。最后的隐藏状态被用作字符级的语音表示 ( x_i )。
句子级编码器 是一个 4 层的 Transformer,隐藏层大小与语义编码器相同。
它的目的是为每个汉字获得上下文化的语音表示。由于独立的语音向量在顺序上没有被区分,因此我们预先给每个向量添加了位置嵌入。
然后,我们将这些语音向量组合起来,并应用 Transformer 层来计算音频模态下的上下文化表示,记为 ( H_a = (h_a^1, h_a^2, \dots, h_a^N) )。
需要注意的是,由于 Transformer 架构的存在,这种表示也会被归一化处理。
3.3 图形编码器
我们使用 ResNet(He 等人,2016)作为图形编码器。
图形编码器由 5 层 ResNet 模块(记为 ResNet5)组成,后接一层归一化操作(Ba 等人,2016)。
我们将这一过程公式化如下:
[
\tilde{h}_i^v = \text{ResNet5}(I_i)
]
[
h_i^v = \text{LayerNorm}(\tilde{h}_i^v)
]
其中,( I_i ) 是输入句子中第 i 个字符 ( x_i ) 的图像,LayerNorm 表示层归一化操作。
为了有效提取图形信息,ResNet5 中的每个模块都会将图像的宽度和高度减半,同时增加通道数。
因此,最终的输出是一个长度等于输出通道数的向量,即高度和宽度都变为 1。
此外,我们将输出通道数设置为与语义编码器中的隐藏层大小相同,以便后续的模态融合。
我们将输入句子在视觉模态中的表示记为 ( H_v = (h_v^1, h_v^2, \dots, h_v^N) )。
第 i 个字符 ( x_i ) 的图像是从预设的字体文件中读取的。由于汉字的书写字体在几千年的演变中不断变化,为了尽可能捕捉字符之间的图形关系,我们选择了三种字体:简体和繁体的黑体字(Heiti)以及小篆。三种字体对应于字符图像的三个通道,图像大小设置为 32 × 32 像素。
3.4 选择性模态融合模块
在应用了上述的语义、语音和图形编码器之后,我们获得了在文本、语音和视觉模态下的表示向量 ( H_t )、( H_a ) 和 ( H_v )。
为了预测最终的正确汉字,我们开发了一个选择性模态融合模块,将这些来自不同模态的向量进行融合。
该模块在两个层级上融合信息,即字符级和句子级。
首先,对于每种模态,使用选择性门控单元来控制信息流入混合多模态表示的程度。例如,如果一个字符因与正确字符发音相似而拼写错误,那么更多的语音模态信息应该流入混合表示。门控值通过一个全连接层和一个 sigmoid 函数来计算。输入包括三种模态的字符表示以及语义编码器输出 ( H_t ) 的均值,以捕捉输入句子的整体语义。形式上,我们将文本、语音和视觉模态的门控值分别表示为 ( g_t )、( g_a ) 和 ( g_v )。第 i 个字符的混合多模态表示 ( \tilde{h}_i ) 计算如下:
[ \overline{h}t = \frac{1}{N} \sum{i=1}^{N} h_t^i ] [ g_t^i = \sigma(W_t \cdot [h_t^i, h_a^i, h_v^i, \overline{h}_t] + b_t) ] [ g_a^i = \sigma(W_a \cdot [h_t^i, h_a^i, h_v^i, \overline{h}_t] + b_a) ] [ g_v^i = \sigma(W_v \cdot [h_t^i, h_a^i, h_v^i, \overline{h}_t] + b_v) ] [ \tilde{h}_i = g_t^i \cdot h_t^i + g_a^i \cdot h_a^i + g_v^i \cdot h_v^i ]
其中,( W_t )、( W_a )、( W_v )、( b_t )、( b_a )、( b_v ) 是可学习的参数,( \sigma ) 是 sigmoid 函数,( [·] ) 表示向量的拼接。
接着,我们应用 Transformer 来完全学习句子级别的语义、语音和视觉信息。所有字符的混合表示被打包到 ( H^0 = [\tilde{h}_1, \tilde{h}_2, \dots, \tilde{h}_N] ),并根据以下公式推导出第 i 个字符应该是什么的概率分布 ( \hat{y}_i ):
[ H^l = \text{Transformer}^l(H^{l-1}), l \in [1, L_0] ] [ \hat{y}_i = \text{softmax}(W_o h_i + b_o), h_i \in H^{L_0} ]
其中,( L_0 ) 是 Transformer 层的数量,( W_o ) 和 ( b_o ) 是可学习的参数。
3.5 声学与视觉预训练
尽管声学和视觉信息对 CSC(中文拼写检查)任务至关重要,同样重要的是如何将这些信息与正确的字符关联。
为了学习声学-文本和视觉-文本之间的关系,我们提出了对语音编码器和图像编码器进行预训练。
对于语音编码器,我们设计了一个输入法预训练目标,即给定输入拼音序列,编码器应该恢复出相应的汉字序列。
这类似于中文输入法的工作方式。我们在编码器顶部添加一个线性层,将隐藏状态转换为汉字词汇表上的概率分布。我们使用训练数据中带有拼写错误的句子的拼音来对语音编码器进行预训练,并使其恢复正确的汉字序列。
对于图像编码器,我们设计了一个光学字符识别(OCR)预训练目标。
给定汉字图像,图像编码器学习视觉信息以预测相应的汉字字符,这类似于 OCR 任务,但我们的识别仅限于字符级别,并且针对的是打印字体。在预训练过程中,我们同样在顶部添加一个线性层以进行分类。
最后,我们加载语义编码器、语音编码器和图像编码器的预训练权重,并使用 CSC 训练数据进行最终的训练过程。
表 2:使用的数据集统计
| 数据集 | 句子数 | 平均长度 | 错误数 |
|---|---|---|---|
| SIGHAN13 | 700 | 41.8 | 343 |
| SIGHAN14 | 3,437 | 49.6 | 5,122 |
| SIGHAN15 | 2,338 | 31.3 | 3,037 |
| Wang271K | 271,329 | 42.6 | 381,962 |
| 总计 | 277,804 | 42.6 | 390,464 |
测试集
| 数据集 | 句子数 | 平均长度 | 错误数 |
|---|---|---|---|
| SIGHAN13 | 1,000 | 74.3 | 1,224 |
| SIGHAN14 | 1,062 | 50.0 | 771 |
| SIGHAN15 | 1,100 | 30.6 | 703 |
| 总计 | 3,162 | 50.9 | 2,698 |
说明:所有训练数据已合并用于训练 REALISE 模型。测试集则单独用于评估模型的性能。
4 实验
在本节中,我们介绍了在 SIGHAN 基准数据集(Wu et al., 2013; Yu et al., 2014; Tseng et al., 2015)上的实验细节和结果。
然后,通过进行消融实验和分析验证我们的模型的有效性。
4.1 数据和评估指标
遵循先前的研究(Wang et al., 2019; Cheng et al., 2020),我们使用 SIGHAN 训练数据和生成的伪数据(Wang et al., 2018,称为 Wang271K)作为训练集。我们在 SIGHAN 测试集上评估我们的模型,具体来说,包括 Lin 2013、2014 和 2015 数据集(分别称为 SIGHAN13、SIGHAN14 和 SIGHAN15)。表 2 显示了数据统计。原始的 SIGHAN 数据集为繁体中文,按照先前的工作(Wang et al., 2019; Cheng et al., 2020; Zhang et al., 2020),我们使用 OpenCC 工具将其转换为简体中文。
结果在“检测级别”和“修正级别”上进行报告。
在检测级别,如果句子中的所有拼写错误都被成功检测到,则认为该句子是正确的。
在修正级别,模型不仅需要检测出错误,还必须将所有错误字符修正为正确的字符。我们在这两个级别上报告了准确率、精确度、召回率和 F1 分数。
表 3: 我们的模型与所有基线模型在 SIGHAN 测试集上的表现
| 数据集 | 方法 | 检测级别 Acc | 检测级别 Pre | 检测级别 Rec | 检测级别 F1 | 修正级别 Acc | 修正级别 Pre | 修正级别 Rec | 修正级别 F1 |
|---|---|---|---|---|---|---|---|---|---|
| SIGHAN13 | Sequence Labeling (Wang et al., 2018) | - | 54.0 | 69.3 | 60.7 | - | - | - | 52.1 |
| FASpell (Hong et al., 2019) | 63.1 | 76.2 | 63.2 | 69.1 | 60.5 | 73.1 | 60.5 | 66.2 | |
| BERT (Cheng et al., 2020) | - | 79.0 | 72.8 | 75.8 | - | 77.7 | 71.6 | 74.6 | |
| SpellGCN (Cheng et al., 2020) | - | 80.1 | 74.4 | 77.2 | - | 78.3 | 72.7 | 75.4 | |
| SpellGCN† (Our reimplementation) | 78.8 | 85.7 | 78.8 | 82.1 | 77.8 | 84.6 | 77.8 | 81.0 | |
| BERT† | 77.0 | 85.0 | 77.0 | 80.8 | 75.2 | 83.0 | 75.2 | 78.9 | |
| REALISE† | 82.7 | 88.6 | 82.5 | 85.4 | 81.4 | 87.2 | 81.2 | 84.1 | |
| SIGHAN14 | Sequence Labeling (Wang et al., 2018) | - | 51.9 | 66.2 | 58.2 | - | - | - | 56.1 |
| FASpell (Hong et al., 2019) | 70.0 | 61.0 | 53.5 | 57.0 | 69.3 | 59.4 | 52.0 | 55.4 | |
| SpellGCN (Cheng et al., 2020) | - | 65.1 | 69.5 | 67.2 | - | 63.1 | 67.2 | 65.3 | |
| BERT | 75.7 | 64.5 | 68.6 | 66.5 | 74.6 | 62.4 | 66.3 | 64.3 | |
| REALISE | 78.4 | 67.8 | 71.5 | 69.6 | 77.7 | 66.3 | 70.0 | 68.1 | |
| SIGHAN15 | KUAS (Chang et al., 2015) | 53.2 | 57.5 | 24.6 | 34.4 | 51.5 | 53.7 | 21.1 | 30.3 |
| NTOU (Chu and Lin, 2015) | 42.2 | 42.2 | 41.8 | 42.0 | 39.0 | 38.1 | 35.2 | 36.6 | |
| NCTU-NTUT (Wang and Liao, 2015) | 60.1 | 71.7 | 33.6 | 45.7 | 56.4 | 66.3 | 26.1 | 37.5 | |
| HanSpeller++ (Zhang et al., 2015) | 70.1 | 80.3 | 53.3 | 64.0 | 69.2 | 79.7 | 51.5 | 62.5 | |
| LMC (Xie et al., 2015) | 54.6 | 63.8 | 21.5 | 32.1 | 52.3 | 57.9 | 16.7 | 26.0 | |
| Sequence Labeling (Wang et al., 2018) | - | 56.6 | 69.4 | 62.3 | - | - | - | 57.1 | |
| FASpell (Hong et al., 2019) | 74.2 | 67.6 | 60.0 | 63.5 | 73.7 | 66.6 | 59.1 | 62.6 | |
| Soft-Masked BERT (Zhang et al., 2020) | 80.9 | 73.7 | 73.2 | 73.5 | 77.4 | 66.7 | 66.2 | 66.4 | |
| SpellGCN (Cheng et al., 2020) | - | 74.8 | 80.7 | 77.7 | - | 72.1 | 77.7 | 75.9 | |
| BERT | 82.4 | 74.2 | 78.0 | 76.1 | 81.0 | 71.6 | 75.3 | 73.4 | |
| REALISE | 84.7 | 77.3 | 81.3 | 79.3 | 84.0 | 75.9 | 79.9 | 77.8 |
-
在 SIGHAN13 数据集上,REALISE 在所有评估指标上都优于其他模型,特别是在修正级别上,取得了 84.1 的 F1 分数。
- 在 SIGHAN14 和 SIGHAN15 数据集上,REALISE 也在检测和修正级别都达到了最高的准确度和 F1 分数,展示了其在拼写纠错任务中的优越性。
- 相较于 BERT 和 SpellGCN,REALISE 在各项任务上都有显著的提高,尤其是在 检测级别 和 修正级别 的 F1 分数上。
4.2 实现细节
REALISE 模型使用 PyTorch 框架 (Paszke et al., 2019) 和 Transformer 库 (Wolf et al., 2020) 实现。具体细节如下:
- 语义编码器:其架构与 BERTBASE 模型相同 (Devlin et al., 2019),即 12 层 Transformer 编码器,每层 12 个注意力头,隐藏层大小为 768。我们使用 BERT-wwm 模型 (Cui et al., 2019) 的权重初始化语义编码器。
- 语音句子级编码器:该编码器的层数设置为 4,并且位置编码使用 BERT 的位置编码初始化。
- 选择性模态融合模块:该模块包含 3 层 Transformer,即 ( L_0 = 3 ),预测矩阵 ( W_o ) 与语义编码器的词嵌入矩阵共享。
- 嵌入和隐藏状态:所有嵌入和隐藏状态的维度为 768。
- 图像处理:我们使用 Pillow 库来提取中文字符图像。对于特殊标记(如 BERT 的 [CLS] 和 [SEP]),我们使用全零的张量作为它们的图像输入。
- 训练细节:我们使用 AdamW 优化器 (Loshchilov 和 Hutter, 2017),训练 10 个 epochs,学习率设为 ( 5 \times 10^{-5} ),批大小为 32。模型采用学习率预热并线性衰减的策略。
SIGHAN13 测试集上的问题
在 SIGHAN13 测试集上,由于标注质量相对较差,很多辅助词(如 “的”、”地” 和 “得”)没有被正确标注 (Cheng et al., 2020)。因此,即使模型表现良好,也可能得到较差的分数。为了缓解这个问题,Cheng et al. (2020) 提出了一种方法,即在测试前对模型进行 SIGHAN13 训练集的微调。但我们认为这种做法并不理想,因为它可能会降低模型性能。因此,我们采用了一种简单而有效的后处理方法:
- 后处理方法:我们将检测和纠正出的 “的”、”地” 和 “得” 字符从模型输出中移除,然后再与 SIGHAN13 测试集的真实标注进行评估。
### 4.3 基线模型
我们将 REALISE 模型与以下基线进行比较:
- KUAS (Chang et al., 2015)
- NTOU (Chu 和 Lin, 2015)
- NCTU-NTUT (Wang 和 Liao, 2015)
- HanSpeller++ (Zhang et al., 2015)
- LMC (Xie et al., 2015)
这些方法主要利用启发式或传统的机器学习算法,如 n-gram 语言模型、条件随机场 (CRF) 和 隐马尔可夫模型 (HMM)。
- Sequence Labeling (Wang et al., 2018):将 CSC 看作序列标注问题,并使用 BiLSTM 模型。
- FASpell (Hong et al., 2019):使用去噪自编码器 (DAE) 生成候选字符。
- Soft-Masked BERT (Zhang et al., 2020):使用检测模型来帮助纠正模型学习正确的上下文。
- SpellGCN (Cheng et al., 2020):将预定义的字符混淆集通过图卷积网络 (GCN) 引入 BERT 基础的纠正模型。
- BERT (Devlin et al., 2019):直接在 CSC 训练数据上微调 BERTBASE 模型。
4.4 主要结果
表 3 显示了在 SIGHAN13/14/15 测试集上的检测水平和纠正水平的评估分数。
REALISE 模型在所有测试集上显著优于所有之前的最先进模型。
可以看到,通过从声学和视觉模态中提取有价值的信息,REALISE 在与 BERT 的比较中,能够保持一致且大幅的提升。
具体而言,在纠正水平上,REALISE 在 SIGHAN13 上的 F1 分数超过 BERT 5.2%,在 SIGHAN14 上超过 3.8%,在 SIGHAN15 上超过 4.4%。在 SIGHAN13 上,通过简单的后处理方法(在第 4.2 节中描述)大大改善了模型的表现。
BERT 在 CSC 任务中有多个成功应用,如 FASpell 和 SpellGCN,它们也考虑了中文字符相似性。这些方法试图将相似性作为筛选候选字符的信心,或者通过预定义的混淆集构建相似性图。而在我们的方法中,多模态编码器直接应用于从声学和视觉模态中提取更具信息量的表示。
与 SpellGCN (Cheng et al., 2020)(最先进的 CSC 模型)相比,我们的 REALISE 模型在检测水平上平均提高了 2.4% 的 F1,在纠正水平上平均提高了 2.6% 的 F1。这表明,与其他基于 BERT 的扩展方法相比,显式利用中文字符的多模态信息对 CSC 任务更有利。
通过第 4.2 节中描述的简单后处理方法,SIGHAN13 测试集上每个模型的结果都有了显著的提高。
与 BERT 和 SpellGCN 比较后,我们可以看到,经过后处理,REALISE 模型领先于所有基线模型。
- Table 4
| Model | Acc | Pre | Rec | F1 |
|---|---|---|---|---|
| Detection Level | ||||
| BERT | 78.4 | 74.6 | 74.5 | 74.5 |
| REALISE | 82.0 | 77.9 | 78.5 | 78.1 |
| - Phonetic | 81.2 | 76.4 | 77.7 | 77.0 |
| - Graphic | 81.4 | 77.3 | 77.2 | 77.2 |
| - Multi-Fonts | 81.2 | 76.3 | 77.9 | 77.0 |
| - Pretraining | 81.5 | 76.5 | 78.1 | 77.2 |
| - Selective-Fusion | 81.3 | 76.8 | 77.4 | 77.1 |
| Correction Level | ||||
| BERT | 76.9 | 72.3 | 72.3 | 72.3 |
| REALISE | 81.0 | 76.5 | 77.0 | 76.7 |
| - Phonetic | 80.2 | 74.8 | 76.1 | 75.4 |
| - Graphic | 80.5 | 75.8 | 75.6 | 75.7 |
| - Multi-Fonts | 80.3 | 74.9 | 76.4 | 75.5 |
| - Pretraining | 80.6 | 75.2 | 76.8 | 75.9 |
| - Selective-Fusion | 80.5 | 75.4 | 76.0 | 75.7 |
表 4:REALISE 模型在 SIGHAN 测试集上的消融实验结果。
我们对 REALISE 模型应用了以下修改:移除语音编码器(- Phonetic),移除图形编码器(- Graphic),仅使用一种字体构建图形输入(- Multi-Fonts),移除声学和视觉预训练(- Pretraining),用简单的求和替代选择性模态融合机制(- Selective-Fusion)。
4.5 消融实验
我们通过进行消融实验,探索 REALISE 中各个组件的贡献,实验设置如下:
1) 移除语音编码器,
2) 移除图形编码器,
3) 仅使用一种字体(简体中文中的哥特字体)构建图形编码器,
4) 移除声学和视觉预训练目标,
5) 用简单的求和替代选择性模态融合机制。
表 4 显示了在三个 SIGHAN 测试集上的平均得分。
本文的主要动机是通过结合声学和视觉信息来发现字符相似性关系。如果移除语音或图形编码器,我们可以看到模型在两个层面上的性能有所下降,但仍然显著优于 BERT。这表明检查模型可以从多模态信息中获益。无论我们移除哪个组件,REALISE 的性能都会下降,这充分证明了我们模型中每个部分的有效性。
- F2
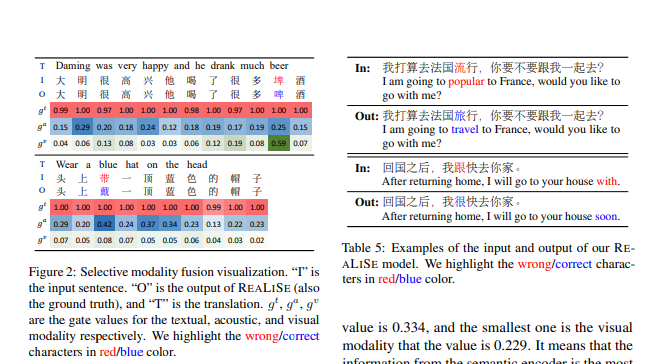
图 2:选择性模态融合可视化。“I”是输入句子。“O”是REALISE的输出(也是地面真实值),而“T”是翻译。
( g_t ),( g_a ),( g_v ) 分别表示文本、声学和视觉模态的门值。我们用红色/蓝色突出显示错误/正确的字符。
- T5
表 5:我们REALISE模型的输入和输出示例。我们用红色/蓝色突出显示错误/正确的字符。
4.6 Selective Modality Fusion模块分析
图2展示了两个例子来分析选择性模态融合模块。在第一个例子中,“埤”的声学和视觉选择性门控值(即 gₐ 和 gᵥ)明显大于大多数其他字符,因为“埤(pí)”和“啤(pí)”发音相同且右部部件“卑”相同。这表明,选择性融合模块能够判断是否将语音或图形信息引入到混合表示中。
第二个例子展示了类似的趋势,对于“带(dài)”和“戴(dài)”的发音也出现了类似的情况。更多的选择性融合可视化内容见附录A.2。
此外,我们还计算了SIGHAN15数据集上每个模态对于错误字符的平均门控值。
其中,文本模态的门控值最大,几乎等于1.0。其次是声学模态,平均值为0.334,最小的是视觉模态,其值为0.229。
这表明,来自语义编码器的信息对于纠正拼写错误是最重要的。
声学模态比视觉模态更重要,这与发音相似导致的拼写错误比形状相似导致的错误更为频繁的事实一致(Liu et al., 2010)。
4.7 案例研究
在表5中的第一个例子中,“流”是错误字符。如果忽略汉字的相似性,可以发现有多个候选字符可以替换“流”字。
例如,可以将其替换为“游”,其英文翻译是“我在法国将要游行”。然而,REALISE的输出是最优的,因为“流(liú)”和“旅(lǚ)”的发音相似。
在第二个例子中,不仅语音信息,视觉信息对于将“跟(gēn)”纠正为“很(hěn)”也是至关重要的。
具体来说,这两个字符在发音上共享相同的韵母“en”,并且右部部件“艮”相同。
上述例子中的错误未被SpellGCN纠正,因为它们未在手工定义的混淆字符对中(Lee et al., 2019)。
具体来说,在SIGHAN15测试集中,有16%的错误-纠正字符对不在预定义的混淆集里。
SpellGCN纠正了其中64.6%的错误,但REALISE在此任务上表现更好,纠正率为73.5%。
此外,对于预定义集中的容易混淆字符对,SpellGCN纠正了82.5%,而REALISE纠正了85.8%。这表明,利用中文字符的多模态信息有助于模型在捕捉字符相似性关系时具有更好的泛化能力。
5 结论
本文提出了一种名为REALISE的中文拼写检查模型。由于中文拼写错误常常在语义、语音或图形上与正确字符相似,REALISE通过利用文本、声学和视觉模态的信息来检测和纠正这些错误。REALISE模型通过量身定制的语义、语音和图形编码器来捕获这些模态中的信息。
此外,提出了一种选择性模态融合机制,用于控制这些模态的信息流。
实验结果表明,在SIGHAN基准测试集上,REALISE模型相较于仅使用文本信息的基准模型具有显著优势,这验证了利用声学和视觉信息对中文拼写检查任务的帮助。
参考资料
https://arxiv.org/pdf/2105.12306v1
