拼写纠正系列
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计、论文和开源实现。
论文 & 源码
论文:https://aclanthology.org/2020.findings-emnlp.184.pdf
摘要
中文拼写检查(CSC)是一个检测和修正中文自然语言拼写错误的任务。
现有方法尝试将中文字符之间的相似性知识纳入模型,但通常将其作为外部输入资源或仅作为启发式规则。
本文提出将发音和形状相似性知识通过专门的图卷积网络(SpellGCN)融入语言模型,用于中文拼写检查。该模型在字符之间构建图,SpellGCN 被训练为将此图映射为一组相互依赖的字符分类器。
这些分类器应用于由另一个网络(如 BERT)提取的表示,从而使整个网络可以端到端地进行训练。我们在三个人工标注的数据集上进行了实验。
实验结果表明,本文的方法相比于之前的模型在性能上有显著的提升。
1 引言
拼写错误在我们的日常生活中非常常见,通常由人工书写、自动语音识别和光学字符识别系统引起。在这些错误中,字符拼写错误常常由于字符之间的相似性而发生。在中文中,许多字符在发音和形状上非常相似,但语义却大不相同。
根据 Liu 等人(2010)的研究,约 83% 的错误与发音相似性有关,48% 的错误与形状相似性有关。中文拼写检查(CSC)任务旨在检测和修正这种语言误用。尽管近年来有所发展,CSC 仍然是一个具有挑战性的任务。
特别是,中文拼写检查与英文拼写检查存在很大不同,原因在于中文的语言特点。中文由许多表意的字符组成,没有单词分隔符,每个字符的意义在不同上下文中变化巨大。因此,CSC 系统需要识别语义并聚合周围的信息以进行必要的修改。
先前的方法多采用生成模型的思路。它们使用语言模型(Liu et al., 2013, 2010; Yu 和 Li, 2014)或序列到序列模型(Wang et al., 2019)。为了融合字符之间相似性的外部知识,其中一些方法利用了混淆集,其中包含一组相似字符对。
例如,Yu 和 Li(2014)提出通过检索混淆集生成多个候选项,并通过语言模型进行筛选。Wang 等人(2019)使用指针网络从混淆集中复制相似字符。这些方法试图利用相似性信息来限制候选项,而不是显式地建模字符之间的关系。
本文提出了一种新型的拼写检查卷积图网络(SpellGCN),该网络捕捉发音/形状的相似性并探索字符之间的先验依赖关系。具体来说,分别构建了两个图,用于表示发音和形状之间的关系。SpellGCN 以这些图作为输入,并在相似字符之间的交互作用下为每个字符生成一个向量表示。
这些表示随后被构建为一个字符分类器,结合由另一个骨干模块(如 BERT)提取的语义表示。
我们使用 BERT(Devlin 等人,2019)作为骨干模块,因为其强大的语义能力。
通过将图表示与 BERT 结合,SpellGCN 可以利用相似性知识并生成正确的修正。如表 1 中的示例所示,SpellGCN 能够在发音约束下正确地修改句子。
我们在三个公开基准数据集上进行了实验,结果表明,SpellGCN 显著提升了 BERT 的性能,超越了所有竞争模型,优势明显。
总结
我们的贡献如下:
-
提出了一种新型的端到端可训练的 SpellGCN,将发音和形状相似性融入语义空间。我们对其核心组件(如专门的图卷积和注意力组合操作)进行了深入研究。
-
我们从定量和定性两个方面评估了 SpellGCN 的性能。实验结果表明,我们的方法在三个基准数据集上取得了最佳成绩。
2 相关工作
中文拼写检查(CSC)任务是一个长期存在的问题,已经引起了研究界的广泛关注。
近年来的相关研究包括(Jia et al., 2013;Xin et al., 2014;Yu 和 Li, 2014;Tseng et al., 2015;Fung et al., 2017;Wang et al., 2019;Hong et al., 2019),以及其他相关课题,例如语法错误修正(GEC)(Rao et al., 2018;Ji et al., 2017;Chollampatt et al., 2016;Ge et al., 2018)。CSC 主要聚焦于检测和修正字符错误,而 GEC 还包括需要删除和插入的错误。
早期的 CSC 研究使用了无监督的语言模型(Liu et al., 2013;Yu 和 Li, 2014),通过评估句子或短语的困惑度来检测和修正错误。然而,这些模型未能根据输入句子来调整修正内容。为了解决这个问题,许多研究采用了判别性序列标注方法(Wang et al., 2018)。
为了提高灵活性和性能,也有研究采用了序列到序列(seq2seq)模型(Wang et al., 2019;Ji et al., 2017;Chollampatt et al., 2016;Ge et al., 2018),以及 BERT(Hong et al., 2019)等模型。
近年来,研究者们开始关注利用字符相似性的外部知识。
相似性知识通常通过字典形式保存,即混淆集,其中存储了相似的字符对。
Yu 和 Li(2014)首次利用字典检索潜在错误的相似候选字符。Wang 等人(2019)将复制机制融入递归神经模型中,当给定相似字符作为输入时,他们的模型通过复制机制直接将字符复制到目标句子中。
从某种程度上讲,这些模型在建模相似字符之间的关系时遇到了困难,因为相似性信息仅用于候选项选择,而没有明确地建模字符之间的关系。
为了捕捉发音/形状的相似性并探索字符之间的先验依赖关系,本文提出使用图卷积网络(GCN)(Kipf 和 Welling, 2017)来建模字符之间的相互依赖关系,并将其与 BERT 的预训练模型相结合,用于 CSC 任务。
GCN 已在多个任务中用于建模关系。Yan 等人(2019)将其应用于关系抽取任务,其中关系构成了一个层次树。Li 等人(2018);Cheng 等人(2018)将其用于建模时空数据以预测交通流量。GCN 也被用于建模多标签任务中的标签关系(Chen et al., 2019)。
本文首次成功将 GCN 应用于 CSC 任务中。与其他任务中的对象关系建模不同,CSC 中的字符之间的关系更为特殊:尽管它们在形状和发音上相似,但语义上却是完全不同的。因此,我们深入研究了 SpellGCN 的效果,并提出了几个关键技术。
3 方法
在本节中,我们详细阐述了我们提出的中文拼写检查(CSC)方法。
首先,介绍了问题的形式化。
接着,我们讨论了SpellGCN的动机,并对其进行了详细描述。最后,展示了该方法在CSC任务中的应用。
3.1 问题形式化
中文拼写检查任务旨在检测并修正中文中的错误。
给定一个文本序列 X = {x_1, x_2, …, x_n},其中包含 n 个字符,模型以 X 作为输入,
输出目标字符序列 Y = {y_1, y_2, …, y_n}。
我们将该任务形式化为一个条件生成问题,通过建模并最大化条件概率 p(Y|X)。
3.2 动机
我们提出的方法框架如图1所示。
该框架由两个组件组成:字符表示提取器和SpellGCN。字符表示提取器为每个字符提取一个表示向量。在表示提取器之上,SpellGCN用于建模字符之间的相互依赖关系。它通过交互生成包含相似字符信息的目标向量。
如表1所示,一个简单的语言模型能够提供语义上可行的修正,但却很难满足发音约束。例如,“月消费最”在语义上是合理的,但与“换经费产”和“环境非常”的发音差异较大。这表明,字符之间的相似性信息是必要的,模型需要学习生成相关的修正候选。以往的方法已经考虑了字符相似性,但通常将相似字符视为潜在的候选项,忽视了它们在发音和形状方面的相互关系。本文的工作首次尝试解决这一问题,旨在将符号空间(发音和形状相似性知识)与语义空间(语言语义知识)融合到一个模型中。
为了实现这一目标,我们利用图神经网络(GNN)的能力,直接注入相似性知识。基本思想是通过聚合相似字符之间的信息来更新表示。直观地说,当模型具备我们提出的方法时,它将能够感知符号之间的相似性。
在各种GNN模型中,我们在实现中选择了图卷积网络(GCN)。由于图中最多包含5000个汉字,轻量级的GCN更适合我们的问题。接下来,我们将详细描述提出的SpellGCN模型。
3.3 SpellGCN 结构
SpellGCN 需要两个相似性图 ( A_p ) 和 ( A_s ),分别表示发音和形状相似性,这些图是从开源的混淆集(Wu et al., 2013)中构建的。为了简化表达,如果没有必要,省略上标,( A ) 表示其中任意一个相似性图。
每个相似性图是一个大小为 ( N \times N ) 的二进制邻接矩阵,构建于混淆集中 ( N ) 个字符之间。矩阵中的元素 ( A_{i,j} \in {0, 1} ) 表示第 ( i ) 个字符和第 ( j ) 个字符是否存在于混淆集中的相似字符对。
SpellGCN 的目标是学习一个映射函数,将第 ( l ) 层的输入节点嵌入 ( H_l \in \mathbb{R}^{N \times D} )(其中 ( D ) 是字符嵌入的维度)映射到一个新的表示 ( H_{l+1} ),这个过程通过由图 ( A ) 定义的卷积操作实现。该映射函数包含两个主要子组件:图卷积操作和注意力图组合操作。
图卷积操作
图卷积操作用于从图中邻近字符中吸收信息。在每一层中,我们采用了轻量级的GCN卷积层(Kipf 和 Welling, 2017):
f(A, H_l) = A * Ĥ_l * W_l^g
其中,( W_l^g \in \mathbb{R}^{D \times D} ) 是一个可训练的矩阵,( \hat{A} \in \mathbb{R}^{N \times N} ) 是邻接矩阵 ( A ) 的归一化版本。归一化方法的定义可以参考原论文(Kipf 和 Welling, 2017)。注意,我们使用 BERT 提取的字符嵌入作为初始节点特征 ( H_0 ),并且省略了卷积后的非线性激活函数。由于我们采用了 BERT 作为特征提取器,它有自己学习的语义空间,因此我们去除了激活函数,以使得最终的表示保持与原空间一致,而不是完全不同的空间。实验表明,使用 ReLU 等非线性激活函数会导致性能下降,因此不使用。
注意力图组合操作
图卷积操作处理单一图的相似性问题。为了结合发音和形状相似性图,我们采用了注意力机制(Bahdanau 等, 2015)。
对于每个字符,我们的组合操作表示如下:
C_l^i = Σ_{k ∈ {s,p} } α_{i,k} * f_k(A_k, H_l)^i
其中,( C_l \in \mathbb{R}^{N \times D} ) 是组合后的表示,( f_k(A_k, H_l)^i ) 是第 ( k ) 个图的卷积表示的第 ( i ) 行,( \alpha_{i,k} ) 是第 ( i ) 个字符的标量,表示图 ( k ) 的权重。权重 ( \alpha_{i,k} ) 由下式计算:
α_{i,k} = exp(w_a * f_k(A_k, H_l)^i / β) / Σ_{k'} exp(w_a * f_{k'}(A_{k'}, H_l)^i / β)
其中,( w_a \in \mathbb{R}^D ) 是在各层中共享的可学习向量,( \beta ) 是一个超参数,用于控制注意力权重的平滑度。我们发现 ( \beta ) 对注意力机制至关重要。
累积输出
经过图卷积和注意力组合操作后,我们获得了第 ( l ) 层的表示 ( C_l )。为了保持提取器的原始语义,所有先前层的输出会被累加作为最终输出:
H_{l+1} = C_l + Σ_{i=0}^{l} H_i
通过这种方式,SpellGCN 能够专注于捕获字符相似性的知识,而将语义推理的责任留给提取器。
希望每一层都能学会聚合特定跳数的信息。在实验中,如果没有包含 ( H_0 ),模型的性能会下降。
3.4 SpellGCN 在中文拼写检查中的应用
在这一部分,我们介绍如何将 SpellGCN 应用于 CSC 任务。
受近期图卷积网络(GCN)在关系建模中的应用启发(Chen 等, 2019;Yan 等, 2019),我们使用 SpellGCN 的最终输出作为目标字符的分类器。
来自混淆集的相似性图
SpellGCN 中使用的相似性图是从(Wu 等, 2013)提供的混淆集构建的。
混淆集是一个预定义的集合,包含了大多数中文字符的相似字符,这些字符被划分为五个类别:
(1) 形状相似,
(2) 发音和声调相同,
(3) 发音相同但声调不同,
(4) 发音相似且声调相同,
(5) 发音相似但声调不同。由于发音相似性比形状相似性更加细致,我们将发音相似性整合到一个图中。因此,我们构建了两个图,分别对应发音和形状的相似性。
通过提取器进行字符表示
用于最终分类的字符表示由提取器生成。我们可以使用任何能够输出字符表示向量的模型 V = {v_1, v_2, ..., v_n} (其中 v_i ∈ ℝ^D),对于 n 个字符 X = {x_1, x_2, …, x_n}。
在我们的实验中,我们采用 BERT 作为主干模型,它接受 ( X ) 作为输入,并使用最后一层的输出作为字符表示 ( V )。
我们使用基础版本的 BERT,它包含 12 层,12 个自注意力头,隐藏层大小为 768。
SpellGCN 作为字符分类器
给定字符 ( x_i ) 的表示向量 ( v_i ),模型需要通过一个全连接层来预测目标字符,该层的权重 ( W \in \mathbb{R}^{M \times D} ) 由 SpellGCN 的输出配置(其中 ( M ) 是提取器词汇表的大小):
p(\hat{y_i} | X) = softmax(W v_i)
具体而言,SpellGCN 的输出向量在我们的任务中充当分类器的角色。我们使用 SpellGCN 最后一层的输出 ( H_L ) (其中 ( L ) 是层数)来对混淆集中的字符进行分类。由于混淆集仅覆盖词汇表的子集,对于那些未被混淆集覆盖的字符,我们使用提取器的词嵌入作为分类器。
这样,如果字符属于混淆集,则表示 ( u_i \in {1, …, N} ) 是提取器词汇表中第 ( i ) 个字符的混淆集索引,权重矩阵 ( W ) 可以表示为:
W_i =
{
H_L^{u_i}, 如果第 \( i \) 个字符 ∈ 混淆集
E_i, 否则
}
其中 ( E \in \mathbb{R}^{M \times D} ) 是提取器的嵌入矩阵。简而言之,如果字符在混淆集中,我们使用来自 SpellGCN 的嵌入。如果字符不在混淆集中,则像在 BERT 中一样使用嵌入向量。
为了计算效率,我们没有将包含所有提取器词汇表字符的大型紧凑图建模为一个图,而是选择了这种实现方法,因为混淆集中的字符约有 5K 个,而提取器的词汇表中有超过 2 万个字符。
总体目标
目标是最大化目标字符的对数似然:
L = Σ_{X,Y} Σ_i log p(\hat{y_i} = y_i | X)
3.5 预测推理
CSC 任务的评估由两个子任务组成,即检测和修正。
一些之前的工作(如 Yu 和 Li,2014;Liu 等,2013)分别为这两个子任务使用了两个模型。
在本工作中,我们简单地使用具有最高概率的字符 \arg \max \hat{y_i} p(\hat{y_i} | X 作为修正任务的预测结果。
检测任务通过检查预测结果是否与目标字符 ( y_i ) 匹配来完成。
4 实验
在本节中,我们详细描述了我们的实验。
首先,我们介绍了训练数据和测试数据,以及评估指标。
接着,我们展示了 SpellGCN 的主要实验结果。随后,进行了消融实验,以分析提出的各个组件的效果,接着是一个案例研究。最后,我们提供了定量结果。
4.1 数据集
训练数据
训练数据由三个训练数据集(Wu 等,2013;Yu 等,2014;Tseng 等,2015)组成,共有 10K 个数据样本。
根据 (Wang 等,2019) 的做法,我们还包括了额外的 271K 样本作为训练数据,这些样本是通过自动化方法生成的(Wang 等,2018)。
测试数据
为了评估所提出方法的性能,我们使用了来自 SIGHAN 2013、SIGHAN 2014 和 SIGHAN 2015 基准的三个测试数据集(Wu 等,2013;Yu 等,2014;Tseng 等,2015),如 (Wang 等,2019) 中所述。我们也遵循相同的数据预处理过程,即将这些数据集中的字符转换为简体中文,使用 OpenCC 工具。数据的统计信息列在表 2 中。
基准模型
我们将我们的方法与五个典型的基准方法进行比较。
- LMC (Xie 等,2015):该方法利用混淆集替换字符,然后通过 N-gram 语言模型评估修改后的句子。
表 2: 使用的数据资源的统计信息
| 数据集 | 行数 | 平均长度 | 错误数 |
|---|---|---|---|
| (Wang 等,2018) | 271,329 | 44.4 | 382,704 |
| SIGHAN 2013 | 350 | 49.2 | 350 |
| SIGHAN 2014 | 6,526 | 49.7 | 10,087 |
| SIGHAN 2015 | 3,174 | 30.0 | 4,237 |
| 总计 | 281,379 | 44.4 | 397,378 |
| 数据集 | 行数 | 平均长度 | 错误数 |
|---|---|---|---|
| SIGHAN 2013 | 1000(1000) | 74.1 | 1,227 |
| SIGHAN 2014 | 1,062(526) | 50.1 | 782 |
| SIGHAN 2015 | 1,100(550) | 30.5 | 715 |
| 图类型 | 字符数 | 边数 |
|---|---|---|
| 发音相似性图 | 4,753 | 112,687 |
| 形状相似性图 | 4,738 | 115,561 |
注:#Line列中的括号中数字表示包含错误的句子数。
基准模型
- LMC (Wang 等,2018):该方法提出了一个管道,采用序列标注模型进行错误检测。错误字符被标记为1(否则为0)。
- PN (Wang 等,2019):该方法结合了指针网络,考虑了来自混淆集的额外候选字符。
- FASpell (Hong 等,2019):该模型利用基于相似度度量的专门候选选择方法。此度量使用一些经验方法(例如编辑距离),而不是预定义的混淆集。
- BERT (Devlin 等,2019):该方法在BERT的基础上使用词嵌入作为softmax层进行CSC任务。我们使用相同的设置训练了该模型,即不使用SpellGCN的对比模型。
评估指标
我们报告了精确度、召回率和F1分数作为评估指标,这些指标在CSC任务中常用。
对于检测和纠正子任务,这些指标分别在字符级和句子级提供评估。
除了字符级的评估外,我们还报告了检测和纠正子任务的句子级评估指标,这对于实际应用更为重要。在句子级评估中,我们认为一个句子只有在其中所有错误都被纠正时才被认为是正确标注的(参见Hong 等,2019)。
在字符级评估中,我们使用Wang 等(2019)提供的评估脚本计算指标。我们还通过官方评估指标工具对BERT和SpellGCN进行了评估,结果包括假阳性率(FTR)、准确度以及精确度/召回率/F1分数。
超参数设置
我们的代码基于BERT的开源仓库。我们使用AdamW (Loshchilov 和 Hutter, 2018) 优化器对模型进行微调,训练了6个epoch,批次大小为32,学习率为5e-5。SpellGCN的层数为2,并使用了因子为3的注意力结合操作。
所有实验进行了4次运行,报告了平均指标。
代码和训练好的模型将在审核后公开发布(目前,代码已附在补充文件中)。
表3: 我们的方法和基准模型的表现(%)
| 数据集 | 方法 | D-P | D-R | D-F | C-P | C-R | C-F | D-P | D-R | D-F | C-P | C-R | C-F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SIGHAN 2013 | LMC (Xie 等,2015) | 79.8 | 50.0 | 61.5 | 77.6 | 22.7 | 35.1 | (-) | (-) | (-) | (-) | (-) | (-) |
| SL (Wang 等,2018) | 54.0 | 69.3 | 60.7 | (-) | (-) | 52.1 | (-) | (-) | (-) | (-) | (-) | (-) | |
| PN (Wang 等,2019) | 56.8 | 91.4 | 70.1 | 79.7 | 59.4 | 68.1 | (-) | (-) | (-) | (-) | (-) | (-) | |
| FASpell (Hong 等,2019) | (-) | (-) | (-) | (-) | (-) | (-) | 76.2 | 63.2 | 69.1 | 73.1 | 60.5 | 66.2 | |
| BERT | 80.6 | 88.4 | 84.3 | 98.1 | 87.2 | 92.3 | 79.0 | 72.8 | 75.8 | 77.7 | 71.6 | 74.6 | |
| SpellGCN | 82.6 | 88.9 | 85.7 | 98.4 | 88.4 | 93.1 | 80.1 | 74.4 | 77.2 | 78.3 | 72.7 | 75.4 | |
| SIGHAN 2014 | LMC (Xie 等,2015) | 56.4 | 34.8 | 43.0 | 71.1 | 50.2 | 58.8 | (-) | (-) | (-) | (-) | (-) | (-) |
| SL (Wang 等,2018) | 51.9 | 66.2 | 58.2 | (-) | (-) | 56.1 | (-) | (-) | (-) | (-) | (-) | (-) | |
| PN (Wang 等,2019) | 63.2 | 82.5 | 71.6 | 79.3 | 68.9 | 73.7 | (-) | (-) | (-) | (-) | (-) | (-) | |
| FASpell (Hong 等,2019) | (-) | (-) | (-) | (-) | (-) | (-) | 61.0 | 53.5 | 57.0 | 59.4 | 52.0 | 55.4 | |
| BERT | 82.9 | 77.6 | 80.2 | 96.8 | 75.2 | 84.6 | 65.6 | 68.1 | 66.8 | 63.1 | 65.5 | 64.3 | |
| SpellGCN | 83.6 | 78.6 | 81.0 | 97.2 | 76.4 | 85.5 | 65.1 | 69.5 | 67.2 | 63.1 | 67.2 | 65.3 | |
| SIGHAN 2015 | LMC (Xie 等,2015) | 83.8 | 26.2 | 40.0 | 71.1 | 50.2 | 58.8 | (-) | (-) | (-) | (-) | (-) | (-) |
| SL (Wang 等,2018) | 56.6 | 69.4 | 62.3 | (-) | (-) | 57.1 | (-) | (-) | (-) | (-) | (-) | (-) | |
| PN (Wang 等,2019) | 66.8 | 73.1 | 69.8 | 71.5 | 59.5 | 69.9 | (-) | (-) | (-) | (-) | (-) | (-) | |
| FASpell (Hong 等,2019) | (-) | (-) | (-) | (-) | (-) | (-) | 67.6 | 60.0 | 63.5 | 66.6 | 59.1 | 62.6 | |
| BERT | 87.5 | 85.7 | 86.6 | 95.2 | 81.5 | 87.8 | 73.7 | 78.2 | 75.9 | 70.9 | 75.2 | 73.0 | |
| SpellGCN | 88.9 | 87.7 | 88.3 | 95.7 | 83.9 | 89.4 | 74.8 | 80.7 | 77.7 | 72.1 | 77.7 | 75.9 |
- D:检测任务,C:纠正任务
- P:精确度,R:召回率,F:F1分数
- 表中的结果来自我们自己的实现,最佳结果用粗体标出。
- 我们对SIGHAN13进行了额外的微调,训练了6个epoch,因为SIGHAN13的语料分布与其他数据集不同,例如“的”、“得”和“地”在该数据集中很少有区分。
表4: 使用官方工具评估BERT和SpellGCN在SIGHAN 2014和SIGHAN 2015上的表现
| 数据集 | 方法 | FPR | D-A | C-A | D-P | D-R | D-F | C-P | C-R | C-F |
|---|---|---|---|---|---|---|---|---|---|---|
| SIGHAN 2014 | BERT | 15.3 | 76.8 | 75.7 | 81.9 | 68.9 | 74.9 | 81.4 | 66.7 | 73.3 |
| SpellGCN | 14.1 | 77.7 | 76.9 | 83.1 | 69.5 | 75.7 | 82.8 | 67.8 | 74.5 | |
| SIGHAN 2015 | BERT | 13.6 | 83.0 | 81.5 | 85.9 | 78.9 | 82.3 | 85.5 | 75.8 | 80.5 |
| SpellGCN | 13.2 | 83.7 | 82.2 | 85.9 | 80.6 | 83.1 | 85.4 | 77.6 | 81.3 |
- FPR:假阳性率(False Positive Rate)
- A:准确度(Accuracy)
- D-A:检测准确度(Detection Accuracy)
- C-A:纠正准确度(Correction Accuracy)
- D-P:检测精确度(Detection Precision)
- D-R:检测召回率(Detection Recall)
- D-F:检测F1分数(Detection F1 Score)
- C-P:纠正精确度(Correction Precision)
- C-R:纠正召回率(Correction Recall)
- C-F:纠正F1分数(Correction F1 Score)
4.3 主要结果
表3展示了所提方法在三个CSC数据集上的表现,并与五个典型的CSC系统进行了比较。
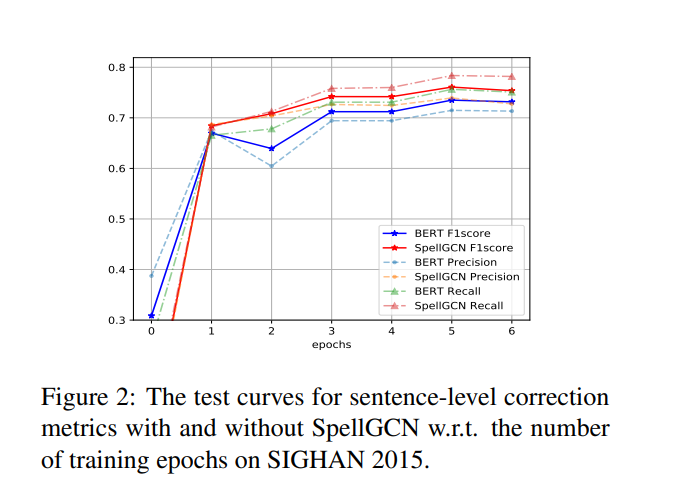
使用SpellGCN时,模型在所有测试集上的表现均优于原始BERT,这验证了其有效性。随着训练数据量的增加,性能提升显著(参见图2中的对比)。
这表明相似性知识对于CSC至关重要,单纯通过增加数据量是难以学习到的。
从修正子任务中的句子级F1得分指标(即最后一列的C-F得分)来看,相对于之前的最佳结果(FASPell),分别提升了9.2%、9.7%和13.3%。然而,需要注意的是,FASpell是在不同的训练数据上训练的,而本文遵循了PN论文中提到的设置(Wang et al., 2019)。理想情况下,我们的方法与FASpell兼容,当采用FASpell时,可以取得更好的结果。
FASpell使用了与官方评估工具包中的句子级假阳性和假阴性计数策略不同的度量标准。
为了公平比较,我们使用了PGNet和FASpell的脚本来计算他们的度量标准。我们进一步在表4中添加了BERT和SpellGCN的官方评估结果。事实上,SpellGCN在使用PGNet/FASpell脚本和官方评估工具包进行评估时,都始终能够提高性能。
我们将在修订中添加FPR结果。FPR得分为14.1%(SpellGCN)对比15.3%(BERT)在SIGHAN 14上,以及13.2%(SpellGCN)对比13.6%(BERT)在SIGHAN 15上。在SIGHAN 13上的FPR统计意义不大,因为几乎所有测试句子都包含拼写错误。
图2:在SIGHAN 2015上,训练轮次与句子级修正指标(有无SpellGCN)的测试曲线。
4.4 消融研究
在本小节中,我们分析了几个组件的影响,包括层数和注意力机制。消融实验使用了10K的训练数据。
层数的影响:一般而言,GCN的性能会随着层数的不同而变化。
我们研究了SpellGCN层数对CSC性能的影响。在此次比较中,层数从1到4进行变化,结果如图3所示。
为了清晰起见,我们报告了三个测试数据集上的字符级C-F得分。
结果表明,SpellGCN能够利用多层结构。通过多层结构,SpellGCN可以在更多的跳数中聚合信息,因此能够获得更好的性能。
然而,当层数超过3时,F1得分会下降。
这是合理的,因为(Yan et al., 2019)中提到的过度平滑问题。
当GCN层数增加时,相似性图中相邻字符的表示会变得越来越相似,因为它们的表示都是通过邻居节点的表示计算得出的。

注意力机制的影响
我们研究了如何更好地结合SpellGCN层中的图。
这里,我们将注意力机制与求和池化和均值池化进行比较,并使用了第3.3节中提到的不同超参数β。
实验基于SIGHAN 2013测试集,在2层SpellGCN上进行。表5中的结果表明,求和池化在CSC任务中失败。
我们认为,求和池化与GCN的归一化不一致,无法有效地结合来自不同通道(即图)的信息。
均值池化是可行的,但被注意力机制超越。这表明,对于每个字符节点的自适应组合是有益的。我们在注意力操作中引入了超参数β,因为点积的结果可能会变得非常大,从而使softmax函数进入梯度极小的区域。根据这些结果,我们选择了在SpellGCN中使用β为3的注意力机制。
发音示例:
- “fang ˘ → fan”,”w ´ ang ` → wang `
-
输入:…走路真的麻坊,我也没有喝的东西,在家汪了…
BERT修正:…走路真的麻木,我也没有喝的东西,在家呆了…
SpellGCN修正:…走路真的麻烦,我也没有喝的东西,在家忘了… - 发音:y¯in→y˘ing
-
输入:…因为妈妈或爸爸在看录音机…帮小孩子解决问题…
BERT修正:…因为妈妈或爸爸在看录音机…帮小孩子解决问题…
SpellGCN修正:…因为妈妈或爸爸在看录影机…帮小孩子解决问题… - 字形:向→尚
- 输入:…不过在许多传统文化的国家,女人向未得到平等…
BERT修正:…不过在许多传统文化的国家,女人从未得到平等…
SpellGCN修正:…不过在许多传统文化的国家,女人尚未得到平等…
表6:几个预测结果示例。每个块的第一行是输入句子,第二行是BERT修正结果,最后一行是SpellGCN修正结果。我们通过橙色/蓝色标出错误/正确的字符。
4.5 个案研究
我们展示了几个修正结果,以证明SpellGCN的特性。除了表1中的示例外,表6中给出了几个预测结果。从这些案例中,我们可以看出,SpellGCN能够根据发音和字形约束,将错误字符修正为正确字符。例如,在第一个案例中,“麻坊(fang)”被检测为错误并修改为“麻烦(fan)”。如果没有发音相似性约束,“麻木(mu)”成为最可能的答案。令人惊讶的是,在第二个案例中,我们的SpellGCN成功地修改了一个合乎上下文的字符。输入句子“看录音机”的意思是“watch the audio recorder”,而我们的模型将其修正为“看录影机”,意思是“watch the video recorder”。我们认为SpellGCN在表示空间中注入了“音”和“影”之间的先验相似性,从而使模型得出了更高的“影”的后验概率。在最后一个案例中,我们展示了一个在字形约束下的修正结果。在混淆集中,“向”与“尚”相似,因此使用SpellGCN能够恢复正确的结果。
4.6 字符嵌入可视化
先前的实验已经在定量上详细探索了SpellGCN的性能。为了定性研究SpellGCN是否学习了有意义的表示,我们深入分析了由SpellGCN生成的目标嵌入空间W。
在图4中,我们使用t-SNE(Maaten和Hinton,2008)展示了带有发音“chang”和“s ı”的字符嵌入。
BERT学习的嵌入捕捉了语义相似性,但未能为CSC任务建模发音上的相似性。这是合理的,因为这种相似性知识在建模中缺失。
相比之下,我们的SpellGCN成功地将这一先验知识注入到嵌入中, resulting in a pattern of clusters。带有这两种不同发音的字符嵌入形成了两个聚类,分别对应于“chang”和“s ´ `ı”。
由于这一特性,该模型倾向于识别相似字符,从而能够在发音约束下恢复正确答案。
图5展示了在字形相似性上的相同情况,其中两组字形与“长”和“祀”相似的字符散布在不同区域。这验证了SpellGCN在建模字形相似性方面的能力。

5 结论
我们提出了SpellGCN用于CSC(Chinese Spelling Check),将发音和字形相似性融入语言模型中。
通过实证比较和分析实验的结果,验证了其有效性。
除了CSC,SpellGCN还可以推广到其他情况,其中具有特定的先验知识,并可以通过类似的方式利用特定的相似性图来处理其他语言。
我们的方法还可以适配于语法错误修正任务,尤其是在需要插入和删除的情况下,通过使用更灵活的提取器,如Levenshtein Transformer(Gu等,2019)。
我们将这一方向留待未来的工作中。
参考资料
https://aclanthology.org/2020.findings-emnlp.184.pdf
