拼写纠正系列
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计、论文和开源实现。
论文 & 源码
论文:https://arxiv.org/pdf/2005.07421
摘要
拼写错误修正是一个重要且具有挑战性的任务,因为其令人满意的解决方案本质上需要具备人类级别的语言理解能力。在本文中,我们不失一般性地考虑了中文拼写错误修正(CSC)。
当前该任务的最先进方法基于BERT语言表示模型,在句子的每个位置从候选列表中选择一个字符进行修正(包括不修正)。
然而,这种方法的准确性可能是次优的,因为BERT本身缺乏足够的能力来检测每个位置是否存在错误,这显然与其预训练时采用的掩码语言建模方式有关。
在这项工作中,我们提出了一种新颖的神经网络架构来解决上述问题,该架构包含一个用于错误检测的网络和一个基于BERT的错误修正网络,前者通过我们称之为“软掩码”技术与后者相连接。
我们使用的“软掩码BERT”方法是通用的,可以应用于其他语言检测修正问题。
在两个数据集上的实验结果表明,我们提出的方法在性能上显著优于包括仅基于BERT的基准方法。
1 引言
拼写错误修正是一个重要的任务,旨在纠正文本中的拼写错误,既可以在单词级别,也可以在字符级别进行修正(Yu 和 Li,2014;Yu 等,2014;Zhang 等,2015;Wang 等,2018b;Hong 等,2019;Wang 等,2019)。
它对于许多自然语言处理应用至关重要,例如搜索(Martins 和 Silva,2004;Gao 等,2010)、光学字符识别(OCR)(Afli 等,2016;Wang 等,2018b)和作文评分(Burstein 和 Chodorow,1999)。在本文中,我们考虑了中文拼写错误修正(CSC),重点是在字符级别进行修正。
拼写错误修正也是一个非常具有挑战性的任务,因为要完全解决该问题,系统需要具备人类级别的语言理解能力。
这个问题至少面临两个挑战,如表1所示。
- Table 1: Examples of Chinese spelling errors
Wrong: 埃及有金子塔。Egypt has golden towers.
Correct: 埃及有金字塔。Egypt has pyramids.
Wrong: 他的求胜欲很强,为了越狱在挖洞。
He has a strong desire to win and is digging for prison breaks
Correct: 他的求生欲很强,为了越狱在挖洞。
He has a strong desire to survive and is digging for prison breaks
首先,拼写错误修正需要使用世界知识。
在第一句话中,字符“字”被误写为“子”,其中“金子塔”指的是金字塔,而“金字塔”才是正确的表达。
人类可以通过参考世界知识来纠正这一错误。
其次,有时也需要进行推理。
在第二句话中,第4个字符“生”被误写为“胜”。
实际上,“胜”和周围的字符形成了一个新的有效词语“求胜欲”(渴望获胜),而不是预期的“求生欲”(求生的欲望)。
为了处理CSC或更广泛的拼写错误修正任务,已经提出了许多方法。
之前的方法主要可以分为两类:一种是基于传统机器学习,另一种是基于深度学习(Yu 等,2014;Tseng 等,2015;Wang 等,2018b)。
例如,Zhang 等(2015)提出了一个统一的CSC框架,包含错误检测、候选生成和最终候选选择,采用传统机器学习方法。Wang 等(2019)提出了一种带有复制机制的Seq2Seq模型,将输入句子转化为一个修正拼写错误的新句子。
近年来,BERT(Devlin 等,2018)这一语言表示模型已成功应用于许多语言理解任务,包括CSC(参见Hong 等,2019)。
在基于BERT的最先进方法中,首先使用一个大规模无标注数据集对字符级BERT进行预训练,然后使用带标注的数据集进行微调。标注数据可以通过数据增强获得,其中拼写错误示例是通过使用一个大的混淆表生成的。
最后,模型用于从给定句子的每个位置的候选列表中预测最可能的字符。这种方法强大,因为BERT具有一定的语言理解能力。我们的实验结果表明,然而,这种方法的准确性仍然可以进一步提高。一个观察结果是,模型的错误检测能力不足,一旦检测到错误,模型更容易进行正确的修正。
我们假设这可能是由于BERT预训练时采用了掩码语言建模方法,在该方法中,只有大约15%的字符被掩码,因此它只学习掩码标记的分布,并倾向于选择不进行任何修正。这个现象很普遍,并且代表了在某些任务中使用BERT(如拼写错误修正)所面临的一个基本挑战。
为了应对上述问题,我们在本文中提出了一种新颖的神经网络架构,称为软掩码BERT(Soft-Masked BERT)。软掩码BERT包含两个网络,一个是基于BERT的修正网络,另一个是错误检测网络。修正网络与仅使用BERT的方法类似。
错误检测网络是一个Bi-GRU网络,它预测每个位置是否存在错误的概率。然后,该概率被用于对该位置的字符嵌入进行软掩码处理。软掩码是一种扩展了传统“硬掩码”的方法,当错误概率为1时,软掩码退化为硬掩码。
每个位置的软掩码嵌入被输入到修正网络中,修正网络使用BERT进行错误修正。通过这种方法,我们可以在端到端的联合训练过程中,借助检测网络的帮助,强制模型学习正确的上下文以进行错误修正。
我们进行了实验,将软掩码BERT与包括仅使用BERT的方法在内的多个基准进行比较。
我们使用了SIGHAN的基准数据集,并创建了一个名为News Title的大型高质量评估数据集。
该数据集包含新闻标题,大小是以前数据集的十倍。实验结果表明,软掩码BERT在两个数据集上的准确性指标上显著优于基准方法。
本工作的贡献包括:
(1)提出了用于CSC问题的创新神经网络架构软掩码BERT;
(2)通过实验证明了软掩码BERT的有效性。
2 我们的方法
2.1 问题与动机
中文拼写错误修正(CSC)可以形式化为以下任务:给定一个由 n 个字符(或单词)组成的序列 X = (x_1, x_2, \dots, x_n),目标是将其转化为另一个具有相同长度的字符序列 Y = (y_1, y_2, \dots, y_n),其中 X 中的错误字符被替换为正确字符,得到 Y。
该任务可以视为一个序列标注问题,其中模型是一个映射函数 f: X \to Y。然而,这个任务相对较简单,因为通常只需替换少量字符,大多数字符可以直接复制。
当前最先进的CSC方法是使用BERT来完成这一任务。我们的初步实验表明,如果标定出错误字符,方法的性能会有所提升(参见第3.6节)。
一般来说,基于BERT的方法倾向于不进行修正(或者仅仅复制原始字符)。
我们的解释是,BERT在预训练时只有15%的字符被掩码用于预测,导致模型没有足够的能力进行错误检测。这一现象促使我们设计了一个新的模型。
2.2 模型
我们提出了一种新颖的神经网络模型,称为 软掩码BERT(Soft-Masked BERT),用于CSC任务,如图1所示。软掩码BERT由基于Bi-GRU的检测网络和基于BERT的修正网络组成。
检测网络预测错误的概率,而修正网络则预测错误修正的概率,前者通过软掩码将其预测结果传递给后者。
更具体地说,我们的方法首先为输入句子中的每个字符创建一个嵌入,称为输入嵌入。
接着,它将嵌入序列作为输入,利用检测网络输出该序列字符的错误概率。然后,通过错误概率对输入嵌入和[MASK]嵌入进行加权求和,计算出的嵌入会以软方式掩盖序列中的可能错误。接着,我们的方法将这些软掩码后的嵌入序列作为输入,使用修正网络输出错误修正的概率,修正网络是一个基于BERT的模型,其最终层包含对所有字符的softmax函数。此外,输入嵌入和最终层嵌入之间还有一个残差连接。
图1展示了软掩码BERT的架构,接下来我们将详细描述该模型的各个部分。
- Figure 1: Architecture of Soft-Masked BERT
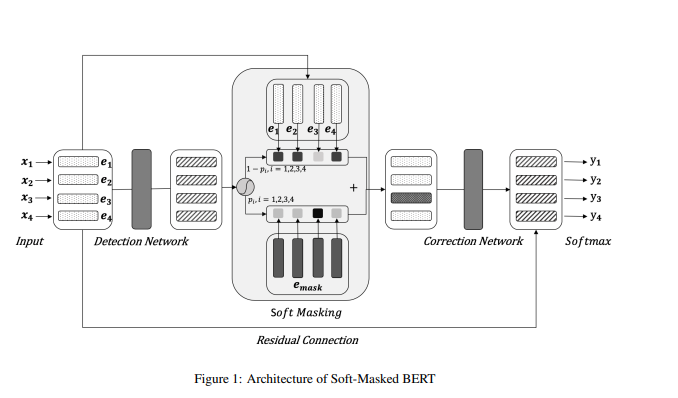
2.3 检测网络
检测网络是一个顺序二元标注模型。
输入是嵌入序列 E = (e_1, e_2, \dots, e_n),其中 e_i 表示字符 x_i 的嵌入,该嵌入是字符的词嵌入、位置嵌入和段嵌入之和,类似于BERT中的做法。输出是一个标签序列 G = (g_1, g_2, \dots, g_n),其中 g_i 表示第 i 个字符的标签,1 表示该字符错误,0 表示正确。对于每个字符,有一个概率 p_i 表示其为 1 的可能性,p_i 越高,字符错误的可能性越大。
在本研究中,我们将检测网络实现为一个双向GRU(Bi-GRU)。对于序列中的每个字符,错误概率 p_i 被定义为:
p_i = P_d(g_i = 1 | X) = σ(W_d h_d_i + b_d) (1)
其中 P_d(g_i = 1 | X) 表示检测网络给定的条件概率,σ 是sigmoid函数,h_d_i 表示Bi-GRU的隐藏状态,W_d 和 b_d 是参数。
进一步地,隐藏状态定义为:
→h_d_i = GRU(→h_d_{i-1}, e_i) (2)
←h_d_i = GRU(←h_d_{i+1}, e_i) (3)
h_d_i = [→h_d_i ; ←h_d_i] (4)
其中 [→h_d_i ; ←h_d_i] 表示从两个方向拼接GRU隐藏状态,GRU是GRU函数。
软掩码是输入嵌入和掩码嵌入的加权和,权重由错误概率决定。第 i 个字符的软掩码嵌入 e’_i 被定义为:
e'_i = p_i · e_mask + (1 - p_i) · e_i (5)
其中 e_i 是输入嵌入,e_mask 是掩码嵌入。
如果错误的概率较高,则软掩码嵌入 e’_i 趋近于掩码嵌入 e_mask;
否则,它会接近输入嵌入 e_i。
2.4 修正网络
修正网络是一个基于BERT的顺序多类标注模型。
输入是软掩码嵌入序列 E' = (e'_1, e'_2, \dots, e'_n),输出是字符序列 Y = (y_1, y_2, \dots, y_n)。
BERT由12个相同的块堆叠而成,输入整个序列。每个块包含一个多头自注意力操作,后跟一个前馈网络,定义如下:
MultiHead(Q, K, V) = Concat(head_1 ; ... ; head_h) W_O (6)
head_i = Attention(Q W_Q_i, K W_K_i, V W_V_i) (7)
FFN(X) = max(0, X W_1 + b_1) W_2 + b_2 (8)
其中 Q, K, V 是表示输入序列或前一个块输出的相同矩阵,MultiHead、Attention 和 FFN 分别表示多头自注意力、自注意力和前馈网络,W_O, W_{Q_i}, W_{K_i}, W_{V_i}, W_1, W_2, b_1, b_2 是参数。我们将BERT最终层的隐藏状态序列记作 H_c = (h^c_1, h^c_2, \dots, h^c_n)。
对于序列中的每个字符,错误修正的概率定义为:
P_c(y_i = j | X) = softmax(W h'_i + b)[j] (9)
其中 P_c(y_i = j | X) 是字符 x_i 被修正为候选列表中字符 j 的条件概率,softmax 是softmax函数,h’_i 表示隐藏状态,W 和 b 是参数。这里,隐藏状态 h’_i 通过与残差连接的线性组合得到:
h'_i = h^c_i + e_i (10)
其中 h^c_i 是最终层的隐藏状态,e_i 是字符 x_i 的输入嵌入。
修正网络的最后一层使用softmax函数,从候选字符列表中选择具有最大概率的字符作为字符 x_i 的输出。
2.5 学习
软掩码BERT的学习是端到端进行的,前提是BERT已经预训练,并且提供了包含原始序列和修正序列对的训练数据,记作 D = {(X_1, Y_1), (X_2, Y_2), \dots, (X_N, Y_N)}。
一种创建训练数据的方式是使用混淆表反复生成包含错误的序列 x_i ,给定没有错误的序列 Y_i,其中 i = 1, 2, \dots, N。
学习过程通过优化两个目标来驱动,分别对应错误检测和错误修正:
L_d = - ∑_{i=1}^{n} log P_d(g_i | X) (11)
L_c = - ∑_{i=1}^{n} log P_c(y_i | X) (12)
其中 L_d 是检测网络的训练目标,L_c 是修正网络(以及最终决策)的训练目标。两个函数通过线性组合作为学习过程中的整体目标:
L = λ · L_c + (1 - λ) · L_d (13)
其中 λ ∈ [0, 1] 是系数。
3 实验结果
3.1 数据集
我们使用了SIGHAN数据集,这是一个用于中文拼写检查(CSC)的基准数据集。
SIGHAN是一个较小的数据集,包含1,100篇文本和461种错误类型(字符)。这些文本来自《对外汉语水平考试》中的作文部分,题目范围较窄。
我们采用了SIGHAN的标准数据集划分,即训练集、开发集和测试集。
我们还创建了一个更大的数据集用于测试和开发,称为“新闻标题”数据集。我们从今日头条(Toutiao)这个包含政治、娱乐、体育、教育等各类内容的中文新闻应用中采样新闻标题。为了确保数据集中包含足够数量的错误句子,我们从质量较低的文本中进行了采样,因此该数据集的错误率高于通常的数据集。三人分别进行了五轮标注,仔细修正了标题中的拼写错误。该数据集包含15,730篇文本,其中有5,423篇包含错误,错误类型为3,441种。我们将数据集分为测试集和开发集,每个集包含7,865篇文本。
此外,我们还遵循了拼写检查(CSC)中的常见做法,自动生成了一个训练数据集。我们首先爬取了约500万条新闻标题。然后创建了一个混淆表,每个字符与其可能的同音错误字符相对应。接下来,我们随机替换文本中15%的字符来人工生成错误,其中80%是表中同音字符,20%是随机字符。这是因为在实际中,中文拼写错误约80%是同音字错误,主要由于人们使用拼音输入法。
3.2 基线方法
为了进行对比,我们采用了以下几种方法作为基线,并报告了原文中的结果。
- NTOU:使用n-gram模型和基于规则的分类器的方法(Tseng et al., 2015)。
- NCTU-NTUT:利用词向量和条件随机场的方法(Tseng et al., 2015)。
- HanSpeller++:一个统一的框架,采用隐马尔可夫模型生成候选词,并使用过滤器对候选词进行重排序(Zhang et al., 2015)。
- Hybrid:一个基于BiLSTM模型的方法,训练数据来自生成的数据集(Wang et al., 2018b)。
- Confusionset:一个Seq2Seq模型,包含指针网络和复制机制(Wang et al., 2019)。
- FASPell:采用Seq2Seq模型的拼写检查方法,利用BERT作为去噪自编码器和解码器(Hong et al., 2019)。
- BERTPretrain:使用预训练BERT的方法。
- BERT-Finetune:使用微调BERT的方法。
3.3 实验设置
在评估指标方面,我们采用了句子级别的准确率、精确率、召回率和F1值,正如大多数先前的工作中所使用的那样。我们在检测和修正两个方面评估了方法的准确性。显然,修正比检测更具挑战性,因为后者依赖于前者。
在实验中使用的预训练BERT模型来自https://github.com/huggingface/transformers。在BERT的微调过程中,我们保持了默认的超参数,并仅使用Adam优化器微调了参数。
为了减少训练技巧的影响,我们没有使用动态学习率策略,而是在微调过程中保持学习率为 2 \times 10^{-5}。Bi-GRU的隐藏单元大小为256,所有模型的批次大小为320。
在SIGHAN实验中,对于所有基于BERT的模型,我们首先使用500万训练样本进行了微调,然后继续使用SIGHAN中的训练样本进行微调。
为了提高效率,我们删除了训练数据中未发生变化的文本。在新闻标题实验中,模型仅使用500万训练样本进行了微调。
开发集用于SIGHAN和新闻标题的超参数调优。每个数据集都选择了最优的超参数 λ 值。
3.4 主要结果
表 2 展示了所有方法在两个测试数据集上的实验结果。
Table 2: Performances of Different Methods on CSC
| Test Set | Method | Detection | Correction | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Acc. | Prec. | Rec. | F1 | Acc. | Prec. | Rec. | F1 | ||
| SIGHAN | NTOU (2015) | 42.2 | 42.2 | 41.8 | 42.0 | 39.0 | 38.1 | 35.2 | 36.6 |
| NCTU-NTUT (2015) | 60.1 | 71.7 | 33.6 | 45.7 | 56.4 | 66.3 | 26.1 | 37.5 | |
| HanSpeller++ (2015) | 70.1 | 80.3 | 53.3 | 64.0 | 69.2 | 79.7 | 51.5 | 62.5 | |
| Hybrid (2018b) | - | 56.6 | 69.4 | 62.3 | - | - | - | 57.1 | |
| FASPell (2019) | 74.2 | 67.6 | 60.0 | 63.5 | 73.7 | 66.6 | 59.1 | 62.6 | |
| Confusionset (2019) | - | 66.8 | 73.1 | 69.8 | - | 71.5 | 59.5 | 64.9 | |
| BERT-Pretrain | 6.8 | 3.6 | 7.0 | 4.7 | 5.2 | 2.0 | 3.8 | 2.6 | |
| BERT-Finetune | 80.0 | 73.0 | 70.8 | 71.9 | 76.6 | 65.9 | 64.0 | 64.9 | |
| Soft-Masked BERT | 80.9 | 73.7 | 73.2 | 73.5 | 77.4 | 66.7 | 66.2 | 66.4 | |
| News Title | BERT-Pretrain | 7.1 | 1.3 | 3.6 | 1.9 | 0.6 | 0.6 | 1.6 | 0.8 |
| BERT-Finetune | 80.0 | 65.0 | 61.5 | 63.2 | 76.8 | 55.3 | 52.3 | 53.8 | |
| Soft-Masked BERT | 80.8 | 65.5 | 64.0 | 64.8 | 77.6 | 55.8 | 54.5 | 55.2 |
从表中可以看出,所提出的模型 Soft-Masked BERT 在两个数据集上都显著优于基线方法。
特别是在 新闻标题 数据集上,Soft-Masked BERT 在所有评估指标上表现都远优于基线方法。
在新闻标题数据集上,修正召回率的最佳结果超过了 54%,这意味着超过 54% 的错误能够被发现,且修正精度也优于 55%。
HanSpeller++ 在 SIGHAN 数据集上取得了最高的精度,这显然是因为它可以通过大量手工制作的规则和特征来消除错误检测。
尽管使用规则和特征是有效的,但该方法的开发成本较高,且在泛化和适应性上可能存在困难。从某种意义上说,它与其他基于学习的方法(包括 Soft-Masked BERT)并不完全可比。除了 Confusionset 之外,所有方法的结果都是基于句子级别的,而不是字符级别的。(字符级别的结果可能看起来更好。)尽管如此,Soft-Masked BERT 仍然表现得显著更好。
使用 BERT 的三种方法,Soft-Masked BERT、BERT-Finetune 和 FASPell,相比其他基线方法表现更好,而 BERT-Pretrain 的表现较差。结果表明,没有经过微调的 BERT(即 BERT-Pretrain)效果不佳,而经过微调的 BERT(即 BERT-Finetune 等)能够显著提升性能。这里我们看到了 BERT 另一个成功的应用,它能够获得一定量的语言理解知识。此外,Soft-Masked BERT 在两个数据集上都远远超过了 BERT-Finetune。
结果表明,错误检测对 BERT 在拼写检查中的应用至关重要,且软掩码确实是一种有效的手段。
3.5 超参数的影响
我们展示了 Soft-Masked BERT 在 新闻标题 测试数据上的结果,以说明超参数和数据量的影响。
表 3 展示了使用不同大小训练数据的 Soft-Masked BERT 和 BERT-Finetune 的结果。
Table 3: Impact of Different Sizes of Training Data
| Train Set | Method | Detection | Correction | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Acc. | Prec. | Rec. | F1 | Acc. | Prec. | Rec. | F1 | ||
| 500,000 | BERT-Finetune | 71.8 | 49.6 | 48.2 | 48.9 | 67.4 | 36.5 | 35.5 | 36.0 |
| Soft-Masked BERT | 72.3 | 50.3 | 49.6 | 50.0 | 68.2 | 37.9 | 37.4 | 37.6 | |
| 1,000,000 | BERT-Finetune | 74.2 | 54.7 | 51.3 | 52.9 | 70.0 | 41.6 | 39.0 | 40.3 |
| Soft-Masked BERT | 75.3 | 56.3 | 54.2 | 55.2 | 71.1 | 43.6 | 41.9 | 42.7 | |
| 2,000,000 | BERT-Finetune | 77.0 | 59.7 | 57.0 | 58.3 | 73.1 | 48.0 | 45.8 | 46.9 |
| Soft-Masked BERT | 77.6 | 60.0 | 58.5 | 59.2 | 73.7 | 48.4 | 47.3 | 47.8 | |
| 5,000,000 | BERT-Finetune | 80.0 | 65.0 | 61.5 | 63.2 | 76.8 | 55.3 | 52.3 | 53.8 |
| Soft-Masked BERT | 80.8 | 65.5 | 64.0 | 64.8 | 77.6 | 55.8 | 54.5 | 55.2 |
从中可以看出,当训练数据量为 500 万时,Soft-Masked BERT 取得了最佳结果,表明使用更多的训练数据能够提高性能。此外,Soft-Masked BERT 始终优于 BERT-Finetune。
较大的 λ 值意味着在错误修正中的权重较高。错误检测比错误修正更容易,因为前者本质上是一个二分类问题,而后者是一个多分类问题。
表 5 展示了在不同 λ 值下 Soft-Masked BERT 的结果。
最高的 F1 分数出现在 λ 为 0.8 时,这意味着检测和修正之间达到了一个良好的平衡。
Table 5: Impact of Different Values of λ
| λ | Detection | Correction | ||||||
|---|---|---|---|---|---|---|---|---|
| Acc. | Prec. | Rec. | F1 | Acc. | Prec. | Rec. | F1 | |
| 0.8 | 72.3 | 50.3 | 49.6 | 50.0 | 68.2 | 37.9 | 37.4 | 37.6 |
| 0.5 | 72.3 | 50.0 | 49.3 | 49.7 | 68.0 | 37.5 | 37.0 | 37.3 |
| 0.2 | 71.5 | 48.6 | 50.4 | 49.5 | 66.9 | 35.7 | 37.1 | 36.4 |
3.6 消融实验
我们对 Soft-Masked BERT 在两个数据集上进行了消融实验。
表 4 显示了新闻标题数据集上的结果(由于篇幅限制,我们省略了 SIGHAN 的结果,结果趋势类似)。
Table 4: Ablation Study of Soft-Masked BERT on News Title
| Method | Detection | Correction | ||||||
|---|---|---|---|---|---|---|---|---|
| Acc. | Prec. | Rec. | F1 | Acc. | Prec. | Rec. | F1 | |
| BERT-Finetune + Force (Upper Bound) | 89.9 | 75.6 | 90.3 | 82.3 | 82.9 | 58.4 | 69.8 | 63.6 |
| Soft-Masked BERT | 80.8 | 65.5 | 64.0 | 64.8 | 77.6 | 55.8 | 54.5 | 55.2 |
| Soft-Masked BERT-R | 81.0 | 75.2 | 53.9 | 62.8 | 78.4 | 64.6 | 46.3 | 53.9 |
| Rand-Masked BERT | 70.9 | 46.6 | 48.5 | 47.5 | 68.1 | 38.8 | 40.3 | 39.5 |
| BERT-Finetune | 80.0 | 65.0 | 61.5 | 63.2 | 76.8 | 55.3 | 52.3 | 53.8 |
| Hard-Masked BERT (0.95) | 80.6 | 65.3 | 63.2 | 64.2 | 76.7 | 53.6 | 51.8 | 52.7 |
| Hard-Masked BERT (0.9) | 77.4 | 57.8 | 60.3 | 59.0 | 72.4 | 44.0 | 45.8 | 44.9 |
| Hard-Masked BERT (0.7) | 65.3 | 38.0 | 50.9 | 43.5 | 58.9 | 24.2 | 32.5 | 27.7 |
在 Soft-Masked BERT-R 中,移除了模型中的残差连接。在 Hard-Masked BERT 中,当检测网络给出的错误概率超过某个阈值(如 0.95、0.9 或 0.7)时,当前字符的嵌入被设置为 [MASK] 令牌的嵌入,否则嵌入保持不变。在 Rand-Masked BERT 中,错误概率被随机化为一个介于 0 和 1 之间的值。可以看到,Soft-Masked BERT 的所有主要组件对于实现高性能都是必需的。
我们还尝试了 BERT-Finetune + Force 方法,其性能可以视为上界。
在这种方法中,我们让 BERT-Finetune 仅在有错误的位置进行预测,并从其余候选列表中选择一个字符。结果表明,Soft-Masked BERT 仍然有很大的提升空间。
4. 相关工作
迄今为止,已经进行了一些关于拼写错误修正(SEC)的研究,这在许多应用中发挥着重要作用,包括搜索(Gao et al., 2010)、光学字符识别(OCR)(Afli et al., 2016)和作文评分(Burstein 和 Chodorow, 1999)。
中文拼写错误修正(CSC)是一个特殊的案例,但由于其与中文分词的结合,增加了其难度,且已获得大量的研究(Yu et al., 2014;Yu 和 Li, 2014;Tseng et al., 2015;Wang et al., 2019)。
早期的CSC研究遵循了错误检测、候选生成和最终候选选择的流程。一些研究者使用无监督方法,结合语言模型和规则(Yu 和 Li, 2014;Tseng et al., 2015),另一些则将其视为序列标注问题,使用条件随机场或隐马尔可夫模型(Tseng et al., 2015;Zhang et al., 2015)。近年来,深度学习方法被应用于拼写错误修正(Guo et al., 2019;Wang et al., 2019),例如,使用BERT作为编码器的Seq2Seq模型(Hong et al., 2019),该模型将输入的句子转换为修正拼写错误后的新句子。
BERT(Devlin et al., 2018)是一种语言表示模型,其架构基于Transformer编码器。BERT首先在非常大的语料库上以自监督的方式进行预训练(使用掩码语言建模和下一句预测)。然后,它使用少量标注数据进行下游任务的微调。
自从BERT问世以来,它在几乎所有语言理解任务中都表现出了卓越的性能,例如在GLUE挑战中(Wang et al., 2018a)。BERT展示了强大的语言理解能力,能够有效地获取和利用语言知识。最近,其他语言表示模型也已提出,例如XLNET(Yang et al., 2019)、Roberta(Liu et al., 2019)和ALBERT(Lan et al., 2019)。在本研究中,我们将BERT扩展为Soft-Masked BERT用于拼写错误修正,据我们所知,之前并未提出过类似的架构。
5. 结论
在本文中,我们提出了一种新的神经网络架构用于拼写错误修正,特别是中文拼写错误修正(CSC)。
我们的模型称为Soft-Masked BERT,由基于BERT的检测网络和修正网络组成。检测网络识别给定句子中可能错误的字符,并对其进行软掩码处理。修正网络以软掩码字符作为输入,进行字符修正。软掩码技术是通用的,且在其他检测-修正任务中也可能具有潜在的应用价值。
在两个数据集上的实验结果表明,Soft-Masked BERT显著超越了仅使用BERT的现有最先进方法。
作为未来的工作,我们计划将Soft-Masked BERT扩展到其他问题,如语法错误修正,并探索实现检测网络的其他可能性。
参考资料
https://arxiv.org/pdf/2005.07421
