拼写纠正系列
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计、论文和开源实现。
论文 & 源码
https://www.mdpi.com/2076-3417/11/13/5832
摘要
中文拼写错误修正是自然语言处理领域的一个热门研究课题。
研究人员已经提出了许多优秀的解决方案,从最初的基于规则的解决方案到当前的深度学习方法。
目前,阿里巴巴团队提出的SpellGCN在字符级精度上超过SIGHAN2013,达到了98.4%的最佳结果。
然而,当我们将该算法应用于实际的错误修正任务时,发现它会产生许多错误的修正结果。
我们认为,这可能是因为用于模型训练的语料库中包含的错误比用于模型修正的文本要多得多。
针对这一问题,我们提出在错误修正任务中进行后处理操作。我们利用初始模型的输出作为候选字符,提取字符自身及其上下文的多种特征,然后使用分类模型来筛选初始模型的错误修正结果。
本文提出的后处理思路可以应用于大多数中文拼写错误修正模型,从而提高它们在实际错误修正任务中的表现。
关键词:自然语言处理;中文拼写错误修正;后处理;实际应用
1. 引言
在人们输入的文本中,错误是不可避免的。
因此,研究人员提出了大量的错误修正算法,以尽量减少文本中的错误。
作为一种古老的书写系统,中文有数万个不同的字符,其中大多数是图形变体。然而,现代的中文输入法大多基于拼音。因此,中文拼写错误包括两种不同的错误模式:语音错误和视觉错误。与英语相比,中文文本没有字符边界,错误的多样性给中文拼写错误修正(CSC)带来了显著的挑战。
语言模型在中文文本错误修正算法中发挥着至关重要的作用。
早期,CSC大多利用n-gram语言模型或字符向量模型,直到2018年双向编码器表示的Transformer(BERT [1])的引入,为CSC提供了强大的基础。
自那时以来,各种基于BERT的算法,如FASPell [2]、Soft-Mask [3]和SpellGCN [4],不断推动CSC技术的进步,创下了新的高记录。
根据其论文,SpellGCN在SIGHAN 2013数据集上的精度达到98.4%,召回率为88.4%,F1得分为93.1 [5]。
受到这一结果的鼓舞,我们决定将SpellGCN应用于我们的在线文本编辑系统中。
然而,其实际表现并未达到预期。该模型将大量正确的字符替换为其认为更合理的字符,而这种替换在错误修正系统中是不可接受的。
CSC模型是在特定的CSC语料库上训练的,该语料库中的错误比我们日常使用的文本要多。
因此,在错误修正阶段,模型可能会对文本的错误率(文本中错误句子的百分比)进行错误估计,导致每个输入字符发生变化的可能性增大。
另一方面,模型是一个简单的反射模型,选择最后一层概率最高的字符作为输出,而没有进一步考虑。
然而,在中文句子中的每个位置都可能有多个适合的字符,正确的输出不一定就是必要的修正。如何让模型避免在实际应用中发生这些错误修正就变得非常重要。
受机器翻译后编辑的启发,我们提出了一种针对中文拼写错误修正任务的后处理操作。
我们采用最先进的CSC模型SpellGCN作为第一步,利用其输出作为候选字符,然后使用第二个模型来决定是否采纳该候选错误修正。
后处理模型是一个简单的分类模型,它使用候选字符和原始字符的多种特征作为输入,如topP、topK、pro、rank等。我们还考虑了其上下文特征,如不确定性和相似性。
通过采用后处理操作,CSC系统可以显著提高错误修正的精度,但会略微降低召回率。
整体的F1得分可以提高10%以上。研究人员可以将我们的方法应用于各种依赖概率输出选择的模型,以提高其在实际错误修正任务中的表现。
2. 相关工作
早期,研究人员采用了将规则和语言模型结合的方式来解决中文文本中的错误修正问题。
他们依赖于混淆集来修改句子中的常见错误。混淆集中的每个元素都是一个字典,键是易错的汉字或词语,值包含了一系列与键在音形上相似的字符或词语。
在错误处理过程中,句子被分割成多个字符和词语。如果混淆集中包含了这些字符或词语的元素,研究人员便从值中选择一个来替换错误的字符或词语。
随后,他们使用语言模型对替换后的句子进行评分,并选择得分最高的句子作为错误修正结果[6,7]。
然而,拼写错误会影响句子的分词结果,从而降低错误修正的效果。Chiu和Wu提出了噪声信道模型[8]来解决这一限制。Zhong和Wang利用拼写错误的单词通常会被拆分成两个或更多个字符的现象,使用单源最短路径(SSSP)算法来修正中文拼写错误[9]。在Yang和Zhao的工作中,他们使用最小化路径分割[10]来解决这个问题。
随着深度学习研究的发展和计算能力的不断提升,研究人员开始使用神经网络来解决中文错误修正问题。Qiu和Qu在他们的研究中使用了两个阶段来解决CSC问题。
首先,他们使用混淆集和语言模型来确定句子中的疑似错误位置,然后使用序列到序列(Sequence-to-Sequence)模型[11]来修正这些错误[12]。
与此同时,Duan和Wang将长短期记忆网络(LSTM [13])与条件随机场(CRF [14])相结合,通过序列标注完成中文文本错误检测[15]。
此后,他们结合了序列到序列模型和注意力机制,基于Bi-LSTM模型实现了中文文本的错误修正[16][17]。
Lu Xie和Li将词语的发音和结构作为模型输入,结合Bi-LSTM和CRF来发现句子中的错误,之后使用掩蔽语言模型来修正疑似错误[18]。
在原有的LSTM模型基础上,Wang和Duan通过引入融合单元形式,将发音和混淆集信息添加到模型中,帮助实现文本错误修正[19]。
Wang和Liu重新思考了注意力机制[20],将混淆集结合起来,将中文错误修正任务看作预测问题。他们引入了更多的全局信息作为新的注意力机制分布,并使用LSTM来预测目标字符[21]。
近年来,预训练语言模型在许多自然语言处理任务中发挥了重要作用,取得了显著的进展。这些模型通过在大量无监督语料上进行训练,学习到足够的语义知识。对这些模型在专业语料上的微调可以在缓解标注语料不足问题的同时,获得良好的性能。Google团队提出的双向编码器表示(BERT)[1]一经推出,在各种自然语言处理任务中就取得了领先的成绩。因此,研究人员开始将BERT及其变体应用于中文拼写错误修正任务。字节跳动团队去除了软掩蔽机制,使用Bi-GRU来柔性覆盖错误,并通过掩蔽语言模型修正整个句子[3]。阿里巴巴团队将中文字符的信息(包括字形和语音信息)引入到BERT模型的最上层,并扩展了训练数据。该算法在错误修正任务中取得了新的最先进结果[4]。
考虑到汉字的特殊性,越来越多的研究者开始关注汉字的语音和形态信息,并以不同的方式将这些信息添加到CSC算法中。Han和Wang等人仍然将中文错误检测任务视为基于Bi-LSTM的序列标注任务[16]。他们将汉字的发音和字形结构作为模型的输入,显著提升了模型的错误检测能力[22]。Wang和Zhong等人则使用词向量方法作为模型预测的判断依据[23]。
在原始模型输出结果之后,iQiyi团队通过人工设定的过滤曲线对这些结果进行了筛选[21]。
这一方法与我们的方法类似,但需要人工选择过滤曲线,因此工作量较大[2]。
Nguyen和Ngo等人提出了适应性过滤器,使用分层嵌入[24]来过滤掩蔽语言模型给出的建议修改。
3. 动机
在中文拼写错误纠正的研究领域,我们通常会在一些公共数据集上测试算法的能力,这些数据集包含了大量的错误(如SIGHAN [5,25,26])。
截至目前,阿里巴巴团队提出了SpellGCN,并在SIGHAN13-15数据集上获得了SOTA(最先进的)F1分数(字符级纠错F1分数分别为93.1%、85.6%和89.4%)。
然而,令人意外的是,当我们将该模型应用于现实中的错误文本纠正时,它产生了许多不必要的纠正。
经过仔细分析错误样本后,我们认为文本错误率的差异(文本中错误句子的百分比)导致了这一结果。
在机器学习理论中,通常假设训练集和测试集的数据是独立同分布(IID)的,即所有样本都属于同一分布。然而,为了提高训练过程的效率,CSC算法的训练数据可能包含比通常更多的错误,这会打破IID假设,导致推理过程中的表现不佳。
为了说明这一现象,我们对SpellGCN在《三重门》手稿上的表现进行了详细测试。
《三重门》[27]是韩寒所著的一部著名小说,然而其原创性曾遭到广泛质疑。在2012年与方舟子的著名辩论之后,韩寒发布了《三重门》手稿,以证明其原创性。这份手稿中仍存在许多拼写错误,在出版前需要进行校对。小说或新闻稿的出版前校对是中文拼写错误纠正最常见的应用场景。根据我们的了解,作为唯一一份已发布的未编辑原创手稿,《三重门》手稿是测试CSC算法在实际应用中表现的一个极好的数据集。首先,我们选择了手稿的前10页,其中包含17个拼写错误。然后,我们将文本分为110个句子(错误率为0.15),其中16个句子包含错误。
这些句子的平均长度为37.4个字符。接下来,我们使用SpellGCN对这些句子进行了纠正,并将模型的超参数设置保持与官方开源实现一致。
在本次实验中,我们使用了精度(Precision)、召回率(Recall)、F1分数和假阳性率(FPR)作为评估指标。
我们选择了模型在SIGHAN15测试集(错误率为0.5)上的结果指标作为对比。
该测试集包含1100个句子,其中550个句子包含错误。如表1所示,当SpellGCN在《三重门》上进行拼写错误纠正时,结果指标明显低于该模型在SIGHAN15测试集上的结果,且FPR值接近后者的两倍。这一现象是由数据分布不均和较低的错误率引起的。提高算法模型在实际错误纠正任务中的表现,将有助于推动这类方法在中文拼写错误纠正领域的应用。
表 1. SpellGCN 在 Triple Door 上的 CRC 结果(字符级别)。P、R、F 分别表示精度、召回率和 F1 分数。我们还给出了句子级别的纠正假阳性率(FPR)。FPR 值表示错误纠正句子占总正确句子的比例。
| 检测 (Detection) | 纠正 (Correction) | D-P | D-R | D-F | C-P | C-R | C-F | FPR |
|---|---|---|---|---|---|---|---|---|
| SIGHAN15 | 85.9 | 80.6 | 83.1 | 85.4 | 77.6 | 81.3 | 13.2 | |
| Triple Door | 21.1 | 47.1 | 29 | 15.8 | 35.3 | 21.7 | 26.6 |
4. 方法
在本节中,我们首先提出了一种方法来解决当前错误纠正算法的局限性,然后详细阐述了我们方法的实现过程。
4.1 后处理
我们引入了一种后处理操作,帮助算法在实际的错误纠正任务中尽可能避免不必要的替换。
后处理是许多自然语言处理任务中的普遍操作。
通常,在机器翻译中,后编辑 [28] 会纠正模型的首次翻译内容,从而提高最终翻译效果。
在过去的一年里,许多摘要文本总结算法已经应用后处理来防止事实错误 [29]。
在中文拼写错误纠正领域,对语言模型纠正结果的进一步处理逐渐成为一种常见的方法,例如FASPell [2]和可适应过滤 [24]。
从人工智能的角度来看,无论神经网络多么复杂,它始终只是一个简单的反射模型。因此,模型的推理能力总是有限的。
我们可以通过添加规划和策略来提高模型的性能。后处理操作是从简单的反射模型到更复杂模型的第一步。
正如第3节所提到的,SpellGCN和其他SOTA模型在实际应用中的表现如此差的核心原因是,训练集和应用场景中的数据不符合独立同分布的假设。
然而,我们不能使用与应用场景相同分布的数据来训练模型,因为包含少量错误的训练数据会导致训练过程极其低效,模型无法学习足够的错误纠正信息。
因此,我们只能将模型训练与推理分开,并通过后处理操作来弥合两者之间的差距。
尽可能让模型模仿人类行为是使机器变得更智能的秘诀之一。
通常,在进行中文拼写错误纠正时,“两步”纠错方法是人类的标准行为。
在第一步中,人类确定句子中疑似错误的候选集。候选集包含对错误字符的所有可能修改。
在第二步中,人类分析之前获得的候选字符与原字符之间的关系。然后,人类会替换这两个字符,以判断句子的意思是否发生了变化。
他们会反复进行第二步,最终选择最合适的候选字符作为正确答案。
当前的大多数算法只完成了人类在纠错任务中的第一步,然后从候选集里选择概率值最高的字符作为纠正结果。
因此,我们在现有的错误纠正模型后添加了后处理操作。
这一操作是一个分类过程。其输入是错误纠正模型给出的建议纠正结果,输出则决定是否采纳该建议。如果该分类模型足够准确,它可能会稍微降低文本纠错的召回率,但能显著提高其精度。
4.2 后处理的实现
一个卓越的分类模型应该关注以下几点:特征集和分类模型本身。我们首先在下一节中阐述后处理所需的特征。随后,我们介绍所选择的分类器及我们方法的输出。
4.2.1 特征集
在分析了中文拼写错误纠正的特点以及人类在处理这些问题时的行为后,我们最终确定了十多个特征,作为分类器筛选候选字符的依据。
此外,我们还给出了替换建议特征的示意图(例如:水 → 苹,如图1所示)。
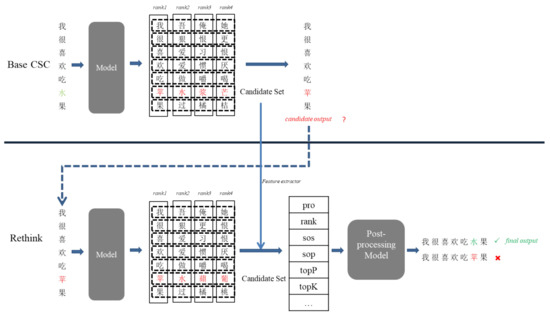
- 图1. 引入后处理操作的示例
图中的上半部分是基础模型,该模型在纠正句子后进行了不必要的更改,将“水”替换为“苹”。然而,在PoP模型(下半部分)中,我们提出的方法避免了这一更改。
概率和排序
在中文拼写错误纠正任务中,模型为句子中每个原始字符给出一个候选集(1),该集包含所有可能的字符,词汇表的大小为V。
基于给定的上下文,模型通过softmax函数获得每个字符在候选集中的概率。所有字符的概率总和为1。理论上,概率较高的字符更有可能成为目标字符。
如第2节所提到的,许多基于BERT的算法简单地选择概率值最大的字符作为纠正输出。
我们同意字符的概率应该是最重要的特征之一,但它不应该是唯一的特征。概率的排序也很重要。
不同的概率值会影响分类结果。
例如,有两个候选纠正字符,它们的概率分别为pro1 = 0.9和pro2 = 0.3。
在这种情况下,分类模型倾向于将前者(pro1 = 0.9)判断为正确,而将后者(pro2 = 0.3)判断为错误,因为pro1 ≫ pro2。为了让模型不再受到概率量化值差异的影响,我们按照概率值从大到小对候选集中的每个字符进行排序(rank = 1, 2, 3, 4, …)。
在前面的例子中,这两个正确字符的排名值都是rank = 1,因为它们具有最高的概率,满足分类模型中同类样本具有相同特征的特性。
由于中文文本中的错误为纠正提供了有用信息,我们将原始字符视为候选字符,并在该位置查找候选集,以获得其对应的概率和排名。
在这种情况下,候选字符的特征值为canPro = 0.5和canRank = 1,而原始拼写错误的特征分别为originalPro = 0.1和originalRank = 89。
模型认为该候选字符是合理的纠正。而当这两个特征分别为0.48和2时,模型必须仔细考虑该纠正是否合适。
我们使用pro和rank特征来表示概率值和概率的排名值;图2展示了这两个特征计算的示例。
公式:
𝐶=[𝑐1,𝑐2,𝑐3,...],𝑙𝑒𝑛(𝐶)=𝑉;∑𝑖=1𝑉𝑝(𝑐𝑖)=1
- Figure 2. Across the candidate set, our approach obtains some features of 水 and 苹: pro, rank, topK, topP.

语音和形态相似性 Phonetic and Morphological Similarity
汉字是最古老的书写语言之一,经过三千年的发展与演变,从最初的象形字到今天的简化字。
每个汉字的形状和发音或多或少与其本身的意义相关。具有相关意义的汉字之间往往会有相似的发音或形态。
通过观察中文文本中的错误,我们可以发现,大多数错误的情况是错误字符和正确字符属于近音字或近形字的范畴。
因此,发音和形态的相似度是判断候选字符是否合理的一个重要因素。
我们引入了两个特征,sos 和 sop,用来衡量候选字符与原始字符在形状和发音上的相似性。
为了获得清晰的数值表达,我们构建了一个汉字拆解和发音统计文件,然后通过FASPell [2]中描述的启发式方法计算这两个特征值,如图3所示。
- Figure 3. Our method calculates the phonetic similarity (sop) and glyph similarity (sos) between 水 and 苹 based on the edit distance.

文本生成的启发
文本生成是自然语言处理中的另一个热门研究话题。
文本生成和拼写检查都试图输出正确且高质量的文本。
在文本生成的早期阶段,研究者直接使用模型最后一层中概率值最大的字符作为生成结果。
这种生成方法导致了生成文本的多样性较低。
因此,研究者引入了采样方法来提高生成文本的多样性。
然而,采样方法可能会带来另一个问题:概率非常低的字符不可避免地会被采样,这对生成文本的整体流畅性极为有害。
Top-k采样 [30] 和 top-p采样 [31] 是两种改进的采样算法。
它们通过截断低概率的词汇(按累计排名或概率)来提高生成文本的质量。
受到文本生成任务的启发,我们引入了topP和topK这两个属性,以帮助最终输出结果摆脱字符的频率。
根据文本生成任务中的具体实现,我们重新定义了这两个属性的计算方法。
首先,我们通过将候选集(1)中的所有字符替换为其对应的概率,构建了一个概率集(公式中的大写英文字母P表示该集)。
原始字符的排名值加一即为topK的值,因为它们的定义非常接近。
然后,我们将所有高于字符概率值的概率值(公式中的小写英文字母p表示该值)加总,包括字符本身,作为topP的值,如图3所示。
公式:
𝑡𝑜𝑝𝐾=𝑟𝑎𝑛𝑘+1 (2)
𝑡𝑜𝑝𝑃=∑𝑝𝑖,𝑝𝑖⊂𝑃,𝑝𝑖≥𝑝 (3)
错误不确定性
由于中文文本自身的特点,我们发现将一些正确字符替换为其他多个字符,仍然可以确保整个句子的语法正确,但原始句子的意义却发生了改变。
当这种情况发生时,即使有其他合理的候选字符,原始字符不应被替换。
因此,仅仅依赖于概率值最高的字符来判断错误字符是极其不准确的。
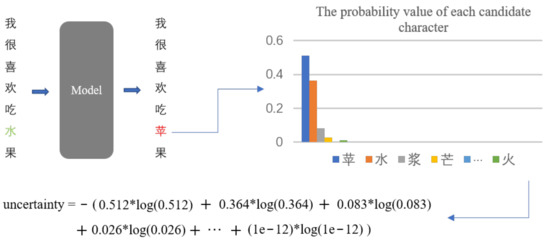
我们提出了一个极端假设:如果句子中特定位置的所有字符的概率相同,则意味着在该位置的每个字符都是合理的。
在这种情况下,该位置的不确定性最大 [32],错误的可能性最小。
因此,我们引入了不确定性特征来表示错误的概率。我们通过以下公式计算这个值,如图4所示。
公式:
𝑢𝑛𝑐𝑒𝑟𝑡𝑎𝑖𝑛𝑡𝑦=−∑𝑝𝑖∗log𝑝𝑖,𝑝𝑖⊂𝑃
- Figure 4. Our method calculates the character (水) position’s error uncertainty (uncertainty) in the original sentence.
句子相似度
一个合格的纠错不会改变句子的意思,或者应该尽量使句子语义的变化最小。
因此,我们引入了相似度属性来表示拼写纠正前后句子的语义相似度。
Fivez 等人 [33] 使用了一种类似的方法,计算候选字符和拼写错误上下文之间的加权余弦相似度。
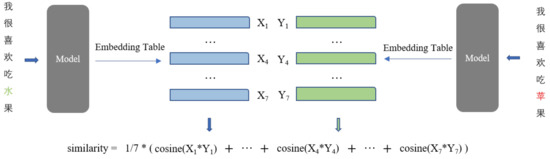
在我们的中文拼写错误纠正系统中,我们将句子中的每个字符映射到一个向量,该向量基于词嵌入表进行生成。
我们用 Xi 和 Yi 分别表示输入句子和输出句子中第 i 个字符的向量,这两个句子都包含 N 个字符。
然后,我们计算这两个向量之间的余弦相似度,作为每对字符的相似度值。
最后,我们将所有字符对的余弦相似度取平均值,作为输入句子和输出句子之间的语义相似度,如图5所示。
公式:
𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦=1𝑁∑𝑖=1𝑁𝑐𝑜𝑠𝑖𝑛𝑒(𝐗𝐢∗𝐘𝐢) (5)
- Figure 5. Our method calculates the semantic similarity (similarity) when the model changes 水 to 苹. This process need the cosine function and model’s embedding table.
替换与重新评估
如第4.1节所述,人类通常遵循两个步骤来解决中文拼写错误纠正任务。
在第一步中,他们确定句子中拼写错误的候选字符。
在第二步中,他们分析每个候选字符的替换是否会改变句子的语义,从而选择最合适的候选字符。
然而,当前的算法类似于人类解决错误纠正任务的第一步。
尽可能贴合人类行为是使机器变得更智能的路径。
因此,结合人类的第二步来纠正文本错误是一个关键点。
我们使用输出的候选字符替换原始句子,然后将其作为模型的新输入,重复计算概率(pro)、排名(rank)、topK和topP,如图1下部分所示。
- F1
4.2.2 分类器
我们依赖分类器来判断错误纠正模型建议的替换是否合理。
候选集实际上由正确替换和不正确替换组成,因此分类器实际上是一个二分类器。
在具体实现中,用于训练分类器的样本具有三个特点:
(a) 特征与标签之间的关系是非线性映射;
(b) 可以参与训练的样本数量相对较少;
(c) 训练样本具有较高的冗余性。
因此,我们选择了具有多项式核的支持向量机(SVM)[34]作为分类器,用来筛选出那些不合理的替换建议。
在训练模型之前,我们将训练样本分为两类(正类——正确替换;负类——不正确替换),并确保两类样本的数量基本相同。
4.2.3 最终输出
在将包含错误的句子输入到模型后,模型根据输入句子的语义推断出每个位置的目标字符,从而实现中文拼写错误纠正的目的。
激活函数 softmax 被引入到模型的最后一层,以确定目标字符在词汇表中的概率分布。
现有的算法通常从候选集(1)中选择具有最大概率值的字符作为最终输出(6)。
当具有最大概率的候选字符与原始字符不一致时,我们也称之为替换建议。
我们通过设置 θ 来过滤候选集,从而实现最简单的后处理操作。
公式中的大写英文字母 X 代表原始中文字符。只有当具有最大概率值的候选字符大于给定的 θ 时,它才会成为正确的输出,否则我们保留初始字符(7)。
我们将 θ 设置为 0.5,并将其作为后处理操作的基准。
与上述两种输出结果不同,我们的方法基于更丰富的信息筛选不必要的替换建议。
首先,我们获取每个原始字符与具有最大概率值的候选字符之间的所有特征,这些候选字符构成了替换建议。
然后,我们依赖训练好的 SVM 来判断该建议的类别。
只有当该建议属于正类时,它才是最终输出。
否则,我们保留原始字符(8)。
𝑜𝑢𝑡𝑝𝑢𝑡=𝑐𝑖, 𝑚𝑎𝑥(𝑝(𝑐𝑖))(6)
𝑜𝑢𝑡𝑝𝑢𝑡2=𝑐𝑖,if 𝑚𝑎𝑥(𝑝(𝑐𝑖)) ≥ Θ 𝑋,𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒 (7)
𝑜𝑢𝑡𝑝𝑢𝑡3=𝑐𝑖,𝑚𝑎𝑥(𝑝(𝑐𝑖)),𝑐𝑖⊂𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 𝑋,𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒 (8)
4.3 后处理示例
图 1 显示了我们方法的一个示例。
基础模型对可能包含错误的句子给出了替换建议。
尽管修改后的句子没有语法问题,但它改变了原始句子的语义。
因此,模型给出的建议并不正确,应当被丢弃。
在我们的方法中,我们获取了在 4.2.2 节中介绍的所有特征,使用训练好的分类器来筛选这个建议,并根据判断结果拒绝这个错误的建议。
这有效地防止了语言模型修改句子中原本正确的字符。
5. 实验
在本节中,我们介绍了实验的具体细节。
首先,我们描述了所有实验数据集、三种基准模型和评估指标。 接着,我们不仅提供了详细的实验结果,还分析和讨论了实验过程中不同超参数设置的影响。
5.1 实验数据
训练数据:实验中的训练数据来自 SIGHAN13-15 数据集,我们还引入了通过自动生成 [35] 构造的额外 271,000 条数据。
用于处理分类器的训练数据来自 SIGHAN2013 [5]、SIGHAN2014 [25] 和 SIGHAN2015 [26] 基准中的一部分。
测试数据:为了评估每个算法的性能,我们使用了官方 SIGHAN13-15 数据集的剩余部分。
在实验中,我们对所有数据进行了预处理:
(a) 将句子中的所有繁体字替换为简体字;
(b) 筛选出长度超过 128 的句子。
下面是数据资源的详细统计信息,见表 2。
- 表 2. 使用的数据资源统计信息。
Train-PoP 是用于训练分类器的数据,来自原始的三个 SIGHAN 测试集。我们从每个测试集中选择了 500 个句子来构建训练集。
| 数据类型 (Data) | 句子数 (Line) | 平均长度 (Avg. Length) | 错误数 (Errors) |
|---|---|---|---|
| Wang et al.[35] | 271,329 | 42.5 | 381,962 |
| SIGHAN13 | 350 | 49.3 | 350 |
| SIGHAN14 | 6528 | 49.7 | 10,089 |
| SIGHAN15 | 3174 | 29.0 | 4,238 |
| Total | 281,381 | 42.6 | 386,639 |
| 测试数据 (Test Data) | |||
| SIGHAN13 | 498 | 77.5 | 634 |
| SIGHAN14 | 562 | 50.1 | 694 |
| SIGHAN15 | 600 | 35.9 | 702 |
| Total | 1660 | 53.2 | 2,030 |
| Train-PoP | 1500 | 48.4 | 1,821 |
5.2. 基准模型
我们通过与三个基本基准模型进行比较来展示我们的方法。
-
BERT [1]: 使用字符嵌入技术作为模型顶层的 softmax 层,我们使用上述训练数据对该模型进行微调。
-
SpellGCN [4]: 在模型的上层引入图编码,将近音和近形的汉字信息融入模型中。我们使用与论文中相同的设置来训练该模型。
-
基于概率过滤: 基于模型输出的最后一层概率,我们通过设置阈值引入简单的过滤操作。在实验中,我们将该阈值设置为 0.5。当候选字符的概率高于该阈值时,我们将其视为有效候选字符。否则,保持原字符(见公式 7)。
5.3. 评估指标
在中文拼写错误修正领域,我们常用 精确度 (Precision)、召回率 (Recall)、F1 分数 (F1 score) 和 假阳性率 (False Positive Rate, FPR) 来评估算法性能。
前三个指标包括字符级别和句子级别。
在句子级别评估中,只有当句子中的所有错误都被正确检测或修正时,才能认为该句子是正确的。FPR 值表示在所有正确句子中,假修正句子的比例。
5.4. 实验设置
为了公平比较,我们实验中的所有模型都基于 BERT-Base,即一个 12 层 Transformer,隐藏层大小为 768,具有 12 个注意力头和 GLEU [36] 激活函数。我们对 BERT 进行了微调,并训练了 SpellGCN,使用 AdamW [37] 优化器进行了 6 轮训练,批次大小为 32,学习率为 (5 \times 10^{-5})。对于基本的后处理模型,我们设置了 θ = 0.5 来过滤概率低于此值的候选字符。
在我们的后处理操作中,我们选择了所有特征来训练 SVM,其阈值也使用默认值(θ = 0.5)。
5.5 实验结果
表 3 显示了使用基于概率过滤的方法并未改善实验结果。
我们观察到在 SIGHAN13-15 测试集上的实验结果,在经过基本后处理操作后,所有模型的指标值均未发生变化。
这个结果表明,在我们设置概率阈值为 θ = 0.5 时,只有一小部分候选集被过滤掉。
因此,我们必须设计更详细的后处理操作,以避免仅依赖概率值带来的不准确性。
- 表 3. 后处理操作对两个基准模型测试结果的影响
表 3. 两个基本模型经过后处理操作后的测试结果。我们记录了两个不同子任务(错误检测和错误修正)在字符级和句子级上的不同测试指标。
P、R、F分别表示精确度、召回率和F1值。在句子级测试中,我们还引入了假阳性率(FPR)。
通过与原始模型进行实验比较,我们突出显示了引入后处理操作后的改进结果。
FP 表示通过概率过滤,PoP 表示后处理。
| 测试集 | 模型 | D-P | D-R | D-F | C-P | C-R | C-F | FPR |
|---|---|---|---|---|---|---|---|---|
| SIGHAN13 | BERT | 83.3 | 90.7 | 86.9 | 81.6 | 88.8 | 85.0 | 77.0 |
| SpellGCN | 84.6 | 89.6 | 87.0 | 83.6 | 88.5 | 86.0 | 78.6 | |
| BERT-FP | 83.7 | 90.5 | 87.0 | 82.1 | 88.9 | 85.3 | 77.4 | |
| SpellGCN-FP | 84.8 | 89.1 | 86.9 | 83.9 | 88.2 | 86.0 | 78.4 | |
| BERT-PoP | 92.4 | 82.8 | 87.4 | 90.5 | 81.1 | 85.5 | 83.9 | |
| SpellGCN-PoP | 91.7 | 85.6 | 88.6 | 90.5 | 84.5 | 87.4 | 84.4 | |
| SIGHAN14 | BERT | 78.6 | 79.3 | 78.9 | 76.6 | 77.4 | 77.0 | 66.7 |
| SpellGCN | 79.4 | 77.1 | 78.3 | 77.9 | 75.7 | 76.8 | 65.8 | |
| BERT-FP | 78.6 | 78.6 | 78.6 | 77.4 | 77.4 | 77.4 | 67.0 | |
| SpellGCN-FP | 79.7 | 76.6 | 78.2 | 78.7 | 75.7 | 77.2 | 66.1 | |
| BERT-PoP | 86.3 | 64.2 | 73.6 | 83.7 | 62.3 | 71.4 | 68.1 | |
| SpellGCN-PoP | 84.7 | 67.4 | 75.1 | 83.5 | 66.4 | 74.0 | 66.8 | |
| SIGHAN15 | BERT | 78.6 | 80.2 | 79.4 | 74.6 | 76.1 | 75.4 | 67.3 |
| SpellGCN | 79.1 | 80.0 | 79.4 | 75.1 | 75.6 | 75.3 | 67.9 | |
| BERT-FP | 79.1 | 79.7 | 79.4 | 75.6 | 76.1 | 75.9 | 67.1 | |
| SpellGCN-FP | 79.0 | 79.2 | 79.1 | 75.2 | 75.4 | 75.3 | 67.8 | |
| BERT-PoP | 87.0 | 70.0 | 77.3 | 81.9 | 65.5 | 72.8 | 71.8 | |
| SpellGCN-PoP | 84.8 | 73.4 | 78.6 | 80.1 | 69.3 | 74.2 | 71.2 |
- D-P:错误检测的精确度 (Precision)
- D-R:错误检测的召回率 (Recall)
- D-F:错误检测的F1分数 (F1)
- C-P:错误修正的精确度 (Precision)
- C-R:错误修正的召回率 (Recall)
- C-F:错误修正的F1分数 (F1)
- FPR:假阳性率 (False Positive Rate)
BERT 和 SpellGCN 在后处理操作后都在精度上有了显著的提升。
在字符级别的精度上,这两个模型的提升基本上为 6% 到 10%。
然而,模型在 F1 分数上的变化在 SIGHAN13-15 数据集上有所不同。
在 SIGHAN13 测试集上,除了召回率外,所有其他指标都有所提升,特别是在句子级别,检测和纠正的 F1 分数提高了大约 5%。
在 SIGHAN14 测试集上,召回率显著下降,这导致 F1 分数无论是在字符级别还是句子级别都下降了大约 5%。
在 SIGHAN15 测试集上,后处理操作对精度和召回率的影响相对平衡,因此句子级别的 F1 分数基本没有变化。
后处理操作能够显著降低模型的假阳性率 (FPR)。假阳性率衡量模型不必要的纠正,这也是当前算法在实际错误纠正应用中的限制。
两个模型的假阳性率下降了 3% 到 6%。这一点对于减少不必要的模型纠正起到了重要作用。
6. 讨论
在两个模型中引入后处理操作后,所有数据集的精度都有所提高。
首先,基本模型会为句子中的每个字符确定替换候选项。然后,后处理操作结合特征和分类器,能够有效地筛选出不必要的纠正。因此,模型的假阳性率也显著降低。
与之前的错误纠正算法相比,尽管后处理操作提高了模型的精度,但也导致了召回率的略微下降,因为后处理操作在筛选竞争者替换项时会过滤掉正确的替换项,这对高召回任务不利。
然而,在中文拼写错误纠正任务中,纠正的精确性比纠正所有潜在错误更为关键。因此,精度更高的模型比召回率更高的模型更为适用。
我们还发现后处理操作在三个不同测试集上的表现差异较大。
例如,在 SIGHAN2013 测试集中,除了召回率外,所有指标均有所提升,而在其他测试集上,F1 分数有所下降。我们认为,这种现象是由于三个数据集中的错误分布不均所导致的。作为证据,SIGHAN2014 测试集中有大量代词错误(如 “他” 与 “he”、”她” 与 “she”),这类错误对错误纠正模型和后处理操作来说非常具有挑战性。
我们的方法基于这样的观察:模型的训练文本与实际应用文本之间的分布不一致,因此现有的算法会产生许多错误的纠正。
在我们引入后处理操作的两阶段过程中,基本模型在第一阶段生成替换建议,然后在第二阶段引入后处理操作。
该方法的优势之一在于,无需修改一个已经可用的中文拼写错误纠正模型,即可减少因训练文本与实际应用文本不匹配而导致的不正确错误纠正。
后处理操作具有较强的泛化能力。
因此,除了本文提到的 BERT 和 SpellGCN,研究人员还可以根据不同的任务选择更多样的基础模型。
7. 消融实验
在这一部分,我们分析了多个组件对分类器性能的影响,包括不同特征子集的选择以及 SVM 阈值的设置。消融实验使用了包含 290 个正样本和相同数量负样本的测试集进行。然后,我们测试了后处理操作在不同错误率下对模型性能的影响。
我们使用模型的 F1 值作为来自两个子任务(错误检测和错误纠正)的比较指标。
不同特征子集:
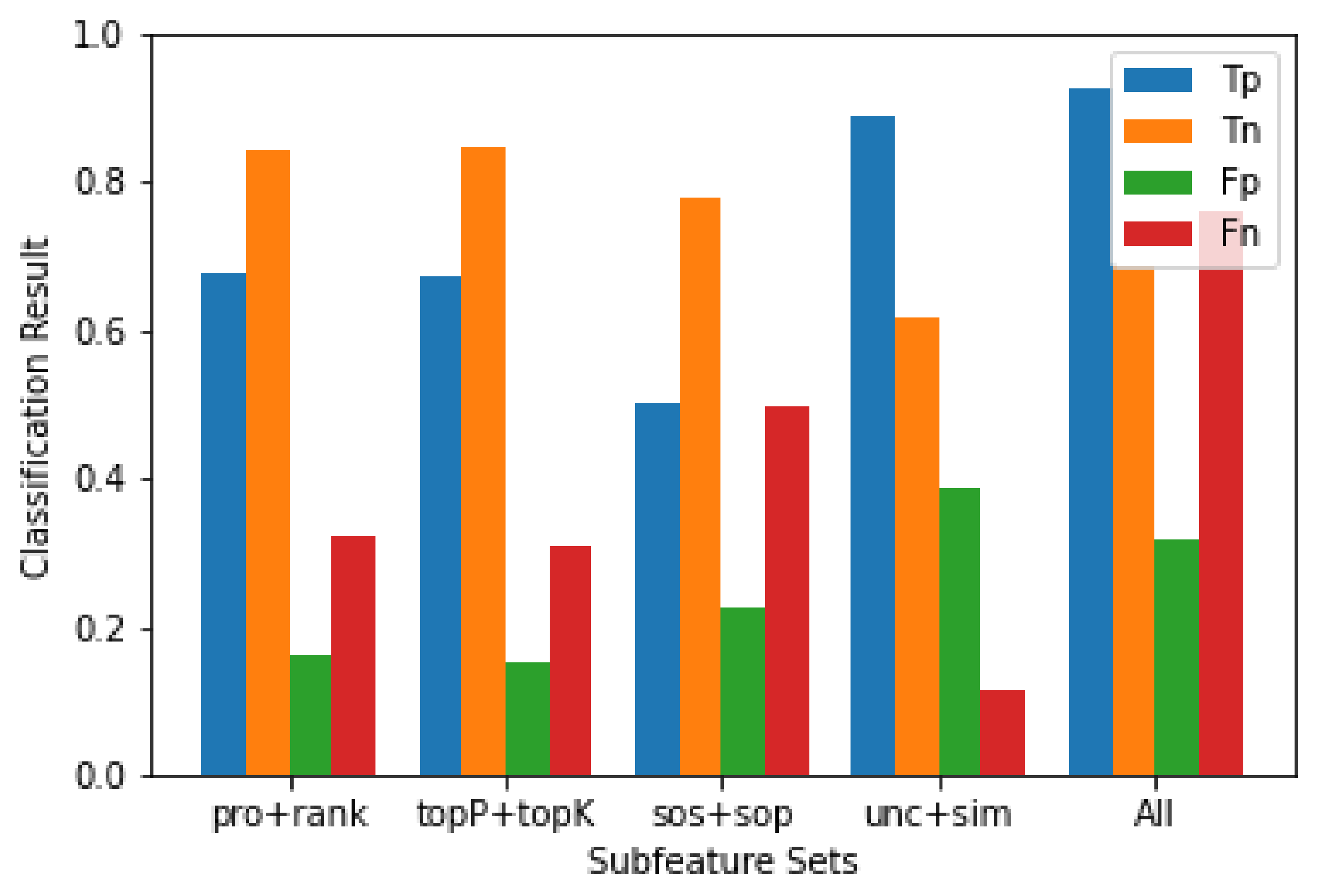
图 6 显示了在选择不同特征子集时,训练后的分类器在测试集上的具体表现。
与文本生成相关的概念具有积极的效果。
由于分类结果使用了基于概率的特征,因此子集(pro 和 rank)与使用文本生成特征(topP 和 topK)时的结果相同。同时,在所有使用不同子集训练的分类器中,这两个分类器在负样本的识别能力上表现更好。
通过使用不确定性和句子相似度训练的分类器能够比其他子特征分类器更好地识别正样本。
然而,它对负样本的识别能力是最低的。当我们将所有特征结合在一起时,得到的分类器在正负样本之间达到了理想的效果。
- 图 6. 在包含 290 个正样本和 290 个负样本的测试集上,不同特征子集的分类器表现。左至右使用的特征子集分别为 pro + rank、topP + topK、sos + sop、不确定性 + 相似度(unc+sim)以及所有特征(All)。分类器在测试集上的分类结果使用不同的颜色标记。
不同错误率:
最后,我们分析了后处理操作在不同错误率下的效果。
为了模拟现实生活中的中文错误文本,我们使用了 2018 NLPCC 比赛提供的官方训练集来构建这些文本。NLPCC [38] 是一个中文误诊比赛,其数据分布与 SIGHAN 数据集相似。比赛数据中的无错误句子完全正确。
我们从训练集中随机选择了 3000 个正确句子作为我们的额外数据。
表 4 给出了这些数据的详细信息。我们使用 BERT 和后处理的 BERT 来纠正这些额外的数据,并展示结果。
然后,我们从这些句子中选择一部分,并将其与测试数据结合,构建了具有不同错误率(50%、40%、30%、20% 和 10%)的文本。最后,我们应用了我们的 BERT-PoP 模型以及基线模型来纠正这些文本,并记录了句子级别纠正的 F1 分数。结果如图 7 所示。
图 7. 在不同错误率下(文本中错误句子的百分比),后处理操作后模型的 F1 分数。其中,三种颜色代表不同的测试集。图的左侧是错误检测的指标结果,右侧是错误纠正的指标结果。实线表示原始模型的结果,虚线表示添加后处理操作后的结果。
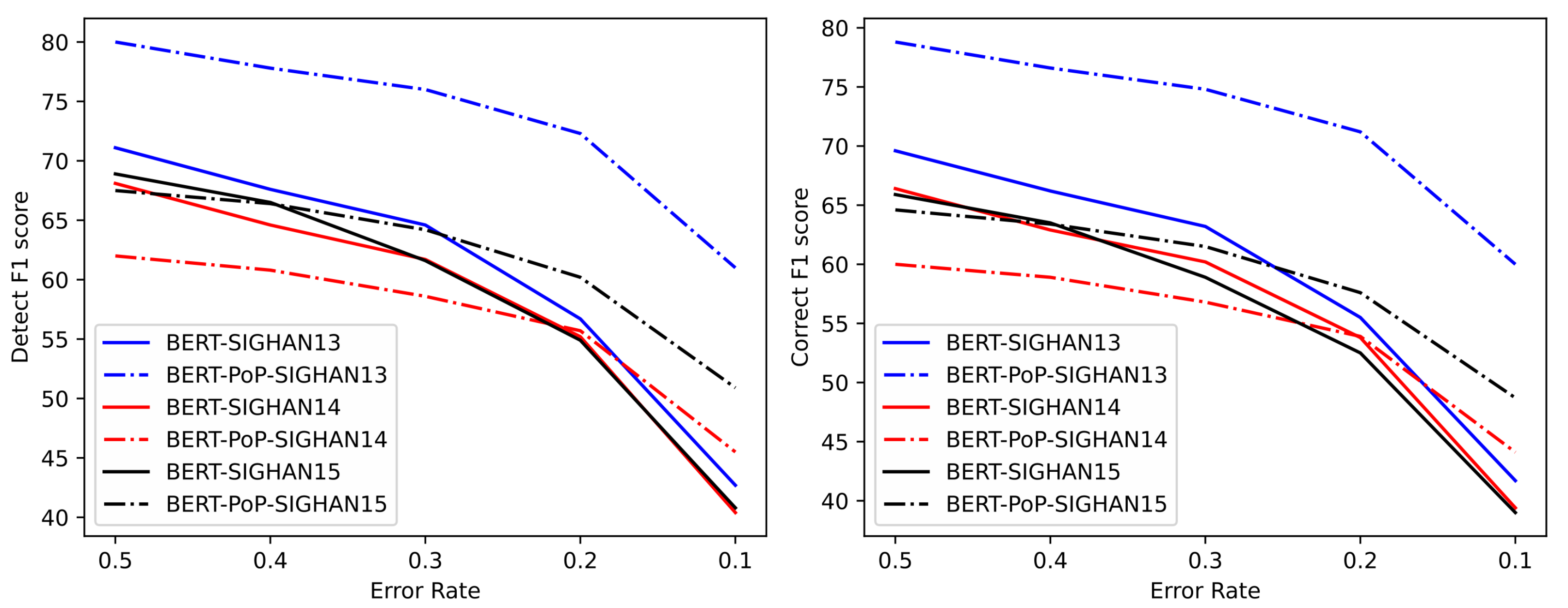
表 4. 额外数据的统计信息。我们从 2018 NLPCC 比赛的训练集中选择了 3000 个句子。
Extra Data Line Avg.length Errors
NLPCC[38] 3000 18.8 0
随着文本错误率的降低,更高的模型精度将导致优秀的 F1 分数。
图 7 显示,当文本的错误率低于 20% 时,BERT-PoP 的 F1 分数高于 BERT。
当文本的错误率低于 10% 时,模型的 F1 分数可以提高 10% 或更多。因此,当文本错误率较低时,后处理操作显著提升了模型的性能。
不同 SVM 阈值:
根据不同阈值,分类器在测试集上的结果如表 5 所示。
从中可以看出,阈值越高,精度越高。同时,这也会减少分类器的召回率和准确率。
因此,我们应该根据实际情况设置阈值。当需要较高精度时,分类器的阈值需要设置为较高的值;相反,当需要较高召回率时,分类器的阈值则需要调低。
表 5. 测试集上 SVM 的不同阈值。默认的阈值为 0.5。
| 阈值 (Threshold) | 准确率 (Accuracy) | 精度 (Precision) | 召回率 (Recall) |
|---|---|---|---|
| θ=0.4 | 80.8 | 85.3 | 91.3 |
| θ=0.5 | 78.8 | 86.6 | 86.2 |
| θ=0.6 | 75.5 | 87 | 80.9 |
8. 结论
本文提出了现有中文拼写错误纠正算法在实际应用中的局限性。现有模型会进行大量不必要的替换,导致较高的假阳性率(FPR)。为了解决这一问题,我们提出了一种后处理操作的方法。
该后处理操作基于多个精心选择的特征,如 sos、sop、topP、topK 等。这些特征可以充分利用汉字的发音、形状和语义。与传统的混淆集不同,我们将这些特征直接集成到模型中。
更具体地说,使用 SVM 模型做出最终的纠正决策。后处理操作可以广泛应用于各种错误纠正模型,并在中文拼写错误纠正应用中显著提高模型的性能,尤其是在文本中只有少量错误的情况下。
在未来的研究中,我们将设计更多有价值的特征,以防止分类模型过滤掉正确的纠正,这可能缓解后处理后召回率下降的影响。
此外,我们还将深入研究如何结合汉字的特性,解决模型无法准确纠正代词错误的问题。
其他
作者贡献
概念化:W.G. 和 Z.C.;方法论:W.G. 和 Z.C.;数据整理:W.G.;原始草稿准备:W.G.;审阅与编辑:Z.C.。两位作者已阅读并同意发布的版本。
资助
本研究未获得外部资助。
伦理委员会声明
不适用。
知情同意声明
不适用。
数据可用性声明
不适用。
利益冲突声明
作者声明没有利益冲突。
小结
希望本文对你有所帮助,如果喜欢,欢迎点赞收藏转发一波。
我是老马,期待与你的下次相遇。
参考资料
https://arxiv.org/pdf/2005.07421
