拼写纠正系列
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计、论文和开源实现。
论文 & 源码
论文:https://aclanthology.org/2021.findings-acl.216.pdf
源码:https://github.com/destwang/DCN
摘要
中文拼写检查(CSC)任务旨在检测和修正中文文本中的拼写错误。大多数当前在CSC任务上取得先进成果的工作都采用了基于BERT的非自回归语言模型,这些模型依赖于输出独立性假设。然而,不恰当的独立性假设阻碍了BERT模型学习目标词元之间的依赖关系,导致生成的文本出现不连贯的问题。
为了解决这一问题,我们提出了一种新的架构,称为动态连接网络(Dynamic Connected Networks,DCN)。
该方法通过拼音增强候选字符生成器生成候选汉字,并利用基于注意力的网络建模两个相邻汉字之间的依赖关系。
实验结果表明,我们提出的方法在三个人工标注的数据集上实现了新的最先进性能。
1 引言
中文拼写检查(CSC)是一个重要的任务,可广泛应用于光学字符识别(OCR)(Wang et al., 2018; Hong et al., 2019)和作文评分等自然语言处理应用中。同时,CSC任务也是一个具有挑战性的任务,需要具备人类水平的自然语言理解能力(Liu et al., 2010, 2013; Xin et al., 2014)。近年来,基于BERT的非自回归语言模型在CSC任务中取得了最先进的性能(Hong et al., 2019; Zhang et al., 2020; Cheng et al., 2020)。这些工作通过使用CSC训练数据微调BERT模型。在训练阶段,所有目标汉字作为标签参与训练。在推理阶段,模型会从候选集中的每个位置预测最可能的汉字。当最可能的汉字与输入汉字不同时,输入的错误字符将被视为拼写错误,并被更正为最可能的字符。基于BERT强大的泛化能力(Devlin et al., 2019),这些工作已经比其他模型取得了更好的性能。
然而,这些CSC任务的工作依赖于错误的独立性假设,这可能会导致生成不连贯的问题。具体来说,它们假设预测的词元彼此独立,而这种假设在自然语言中通常并不成立(Yang et al., 2019; Gu and Kong, 2020)。对于CSC任务,一个拼写错误可能有多个修正。忽视修正的上下文可能会导致修正冲突。如表1所示,“户秃”可能被修正为“糊涂”或“尴尬”。由于每个词元的独立性,非自回归语言模型可能将其修正为“尴涂”这一不连贯的字符。这个不连贯问题在非自回归机器翻译中被称为多模态问题(Gu et al., 2018)。
为了解决这个问题,我们提出了一种新的架构,称为动态连接网络(Dynamic Connected Networks,DCN),该方法能够建模两个相邻候选汉字之间的依赖关系。具体而言,我们使用RoBERTa模型(Liu et al., 2019; Cui et al., 2019)作为基础模型,也可以替换为其他模型。首先,我们利用RoBERTa和拼音增强候选生成器来融合语音信息,并在每个位置生成k个候选汉字。对于每两个相邻的候选汉字,DCN通过动态连接评分器(DCScorer)学习一个可变的连接评分,以确定它们之间的依赖关系的强度。DCScorer通过将当前和下一个位置的上下文表示和候选汉字嵌入同时输入到注意力层来计算连接分数。最终,模型生成k^n个候选路径,我们使用Viterbi算法(Rabiner, 1989)快速找到得分最高的路径,作为最终的修正结果。
条件随机场(CRF)(Lafferty et al., 2001)也可以建模输出标签的依赖关系,但它不适用于语言建模或CSC任务。汉字之间的依赖关系更多地与上下文相关,且比其他任务(如命名实体识别,NER)的标签关系更为复杂。因此,CRF中固定的转移矩阵能力有限。此外,汉字的数量通常超过5K,使得转移矩阵过大,难以学习。相比之下,DCN的输出候选(标签)和连接评分是动态的,会根据上下文发生变化。这赋予了我们的模型强大的学习依赖关系的能力。
我们在SIGHAN 2013、SIGHAN 2014和SIGHAN 2015基准数据集上进行了实验。实验结果表明,我们提出的方法在这三个人工标注的数据集上显著优于现有的最先进模型。
总结
我们的贡献如下:
-
我们提出了一种新的端到端动态连接网络(DCN),能够缓解非自回归语言模型在CSC任务中的不连贯问题。
-
我们提出了一种简单而有效的拼音增强候选生成器,将语音信息融入到生成更好的候选汉字。
-
实验结果表明,我们提出的方法在三个人工标注的数据集上取得了最先进的性能。
为便于复现,本论文的代码可在https://github.com/destwang/DCN获取。
2 相关工作
中文拼写检查(CSC)是一个具有挑战性的任务,需要具备人类水平的语言理解能力。
随着深度学习技术的发展,CSC任务最近取得了更多进展。CSC任务与语法错误纠正(GEC)任务相似(Dahlmeier and Ng, 2012)。
它们的区别在于,CSC仅关注中文拼写错误,而GEC还包括需要插入和删除的错误。
GEC任务中的大多数模型使用自回归的Seq2Seq模型来纠正句子。类似地,Seq2Seq模型也可以用于CSC任务。Wang et al. (2019) 提出了一个自回归的指针网络,该网络从混淆集生成汉字,而不是从整个词汇中生成。尽管自回归Seq2Seq模型具有纠正拼写错误的能力,但它通常较慢。由于输入和输出非常相似,完全重新生成序列会显得“浪费”时间(Malmi et al., 2019)。
由于CSC任务中的输入和输出包含相同数量的汉字,并且正确与错误的汉字一一对应,因此更直观的方法是使用非自回归语言模型(如BERT)直接纠正中文拼写错误。
Hong et al. (2019) 提出了FASPell模型,该模型基于BERT模型预测候选字符,并利用语音和视觉相似性信息选择候选字符。
Zhang et al. (2020) 提出了一个名为Soft-Masked BERT的模型,包含一个检测网络和一个基于BERT的修正网络。
Cheng et al. (2020) 提出了通过专门的图卷积网络将语音和视觉相似性知识融入BERT中。
Bao et al. (2020) 设计了一个基于块的框架,并扩展了传统的混淆集,引入了语义候选项,以涵盖不同类型的错误。
尽管上述提到的非自回归方法在CSC任务中已经取得了最先进的性能,但这些方法仍然存在非自回归模型中的不连贯问题(Gu et al., 2018; Gu and Kong, 2020)。在本文中,我们提出了一种新型模型DCN,它学习相邻汉字之间的依赖关系,缓解了这一不连贯问题。
3 我们的方法
3.1 问题
给定一个输入文本序列 X = {x₁, x₂, …, xₙ},CSC(Chinese Spelling Check,中文拼写检查)任务的目标是自动纠正中文句子中的错误部分,并生成一个正确的目标序列 Y = {y₁, y₂, …, yₙ}。由于输入句子 X 和输出句子 Y 含有相同数量的标记(中文字符),因此预训练的非自回归语言模型(如 BERT)非常适合用于 CSC 任务。
然而,由于非自回归语言模型基于输出独立性的假设,它们会导致输出的中文字符错配,从而产生不连贯的问题。这个问题在非自回归机器翻译(Gu et al., 2018, 2019;Gu 和 Kong, 2020)以及预训练语言模型(Yang et al., 2019)中也有所提到。
图1:DCN架构示意图
图中展示了如何通过动态连接评分器(Dynamic Connected Scorer)计算候选词“糊”和“涂”之间的连接分数。
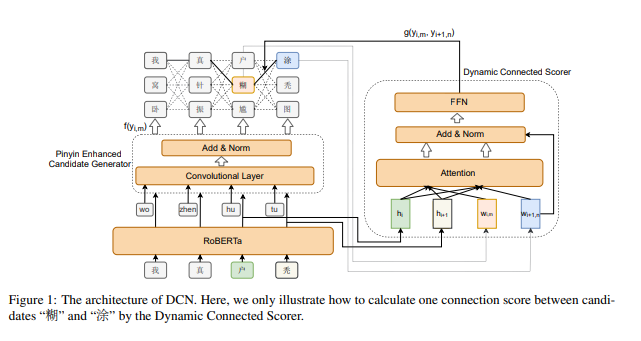
3.2 动态连接网络(DCN)
为了解决上述的不连贯性问题,我们提出了一种新的模型——动态连接网络(Dynamic Connected Networks,DCN),该模型能够学习输出中文字符之间的依赖关系,并缓解不连贯性问题。
模型结构如图1所示。
我们使用RoBERTa(Liu et al., 2019;Cui et al., 2019)模型作为基础模型。
首先,RoBERTa与拼音增强候选生成器一起生成一系列候选字符,并从中采样k个字符作为候选(候选生成方法将在下一小节中详细讨论)。
对于每一对相邻的候选字符,我们通过动态连接评分器(DCScorer)学习连接分数,来确定它们之间的依赖强度。最终的修正分数将通过连接分数和每个位置上候选生成器的预测分数联合预测计算得出。
DCScorer需要同时考虑当前和下一个位置的候选字符的上下文信息。
因此,我们使用注意力机制来学习当前候选上下文表示 p 和下一个候选上下文表示 q。
两个相邻候选之间的依赖强度通常与当前和下一个位置的RoBERTa隐藏表示相关,因此,注意力机制中的键(Key)和值(Value)仅包含这两个隐藏表示。DCScorer的形式定义如下:
pi,m = Attention(Qi,mWQ, KiWK, ViWV)
qi,n = Attention(Qi+1,nWQ, KiWK, ViWV)
Ki = Vi = [hi, hi+1]
Qi,m = wi,m
Qi+1,n = wi+1,n
其中,i是字符位置,m和n分别是当前和下一个位置候选的索引。Attention表示注意力机制,Q、K、V分别表示查询(Query)、键(Key)和值(Value),W表示在注意力层中需要学习的参数。h是最后一个Transformer块的隐藏表示,w表示候选词的嵌入表示。
我们将候选词嵌入表示加入到候选上下文表示中,然后将输出输入到层归一化(LayerNorm)中,得到两个表示p₀ᵢ,ₘ和q₀ᵢ₊₁,ₙ:
p₀ᵢ,ₘ = LayerNorm(pi,m + wi,m)
q₀ᵢ₊₁,ₙ = LayerNorm(qi,n + wi+1,n)
我们将这两个向量拼接并输入到由Vaswani等人(2017)使用的前馈网络(FFN)层中。然后,我们使用线性层计算两个候选之间的连接分数:
s = FFN(Concat(p₀ᵢ,ₘ, q₀ᵢ₊₁,ₙ))
g(yi,m, yi+1,n) = sv
其中,v是一个可训练的权重向量,g(yi,m, yi+1,n)是第i位置的第m个候选与第i+1位置的第n个候选之间的连接分数。
由于我们将k²对候选组合输入DCScorer,因此我们将在每个位置生成k²个分数。最终,模型将生成kⁿ条候选路径,每条路径的分数通过以下公式计算:
S(X, Y) = Σₙᵢ₌₁ f(yi,m) + Σₙ₋₁ᵢ₌₁ g(yi,m, yi+1,n)
其中,y是候选字符,f(yi,m)是拼音增强候选生成器对第i位置的第m个候选的预测分数。
3.3 候选字符生成
我们通过基于RoBERTa的拼音增强候选生成器生成候选中文字符。
拼音增强候选生成器
根据统计数据,超过80%的拼写错误与语音相似性有关(Liu et al., 2010)。由于语音错误占中文字符错误的很大比例,引入拼音信息的合适方法将有助于生成候选字符并纠正拼写错误。
从单个中文拼音转换到中文字符存在很大的歧义性。因为一个拼音通常对应多个中文字符,导致很难正确转换。然而,当有多个连续的拼音时,我们对将拼音转换为正确中文字符的信心会更高。例如,中文字符“户”和“糊”的拼音是“hu”,而“秃”和“涂”的拼音是“tu”。当“hu”和“tu”一起出现时,它们很可能会被转换为“糊涂”,表示“困惑”。这也是中文拼音输入法中使用的基本假设。
基于此,我们提出了一种拼音增强候选生成器,可以有效减少歧义并生成更好的中文字符。其架构如图1所示。具体来说,我们采用卷积层对连续拼音进行编码,并将卷积层的输出、RoBERTa的隐藏表示和字符嵌入一起相加。
然后,我们将求和结果输入到层归一化(LayerNorm)中,并通过线性层得到预测分数f(yi,m)。公式如下:
ci = Conv(p''i-1, p''i, p''i+1)
oi = LayerNorm(ci + wi + hi)
f(yi,m) = oiv'ₘ
其中,p’‘表示拼音嵌入,wi是中文字符嵌入,hi是RoBERTa的最后一个隐藏表示,v’ₘ是第m个候选的可训练权重向量。
拼音有多种表示方式,我们发现将每个拼音(不带声调)作为单独的嵌入表示能够取得较好的效果。
我们还尝试通过多层感知机(MLP)和GRU(Chung et al., 2014)编码器来编码拼音,将拼音的每个字母当作嵌入向量。
但由于它们未能取得更好的结果,我们在后续实验中仅将每个拼音表示为单独的嵌入。
候选采样方法
鉴于中文字符数量庞大,我们为学习过程采样候选字符。我们尝试了几种采样方法,发现从词汇表中选择具有前k个预测分数的字符效果最佳。
这也表明,更难的候选字符可以作为负训练样本,有效提高模型的区分能力。
因此,所有主要的实验结果都是基于前k个采样。
3.4 学习
损失函数
给定序列Y的概率可以通过以下公式进行近似:
p(Y | X) = exp(S(X,Y)) / Σₓₖ exp(S(X,Yₖ))
其中,Yₖ表示由候选字符生成的路径。
损失函数是概率分布的最大似然估计,表示为:
Loss =
{ -log(p(Y | X)), S(X, Y) < Smax(X, Yₖ)
{ 0, S(X, Y) ≥ Smax(X, Yₖ)
损失函数类似于LSTM-CRF中使用的损失函数(Huang et al., 2015)。它仅学习被采样的负候选字符及其之间的依赖关系,这可能会不当地降低潜在候选的排序。这可能导致更相似的候选字符排名较低。为了避免上述问题,我们通过在损失函数中设置约束,当金标准分数高于或等于所有候选路径的最大分数时,将其损失设为0。
预训练
中文字符之间的依赖关系可以通过大规模的训练语料库得到更充分的学习。本文中,我们使用中文维基百科数据对我们提出的模型进行预训练,如表2所示。我们随机替换15%的字符,其中70%为MASK标记,15%为来自混淆集的字符,15%为随机字符。我们利用SIGHAN 2013(Wu et al., 2013)发布的混淆集,该集合包含了发音相似性和形状相似性的字符。基于RoBERTa模型,我们冻结了主要参数,仅对拼音增强候选生成器和动态连接评分器进行微调。
3.5 预测
在预测阶段,拼音增强候选生成器从词汇表中生成前k个候选字符。
最终,将生成kⁿ条路径。为了快速选择具有最高分数的路径,我们使用基于动态规划的Viterbi算法(Rabiner, 1989)解码输出序列。
表2: 数据集统计
训练集
| 数据集 | 行数 | 平均长度 | 错误句子数 |
|---|---|---|---|
| Wikipedia | 7,756,725 | 47.0 | - |
| (Wang et al., 2018) | 271,329 | 44.4 | 271,329 |
| SIGHAN 2013 | 700 | 49.2 | 350 |
| SIGHAN 2014 | 3,435 | 49.7 | 3,432 |
| SIGHAN 2015 | 2,339 | 30.0 | 2,339 |
测试集
| 数据集 | 行数 | 平均长度 | 错误句子数 |
|---|---|---|---|
| SIGHAN 2013 | 1,000 | 74.1 | 996 |
| SIGHAN 2014 | 1,062 | 50.1 | 529 |
| SIGHAN 2015 | 1,100 | 30.5 | 550 |
4 实验
4.1 实验设置
数据集
我们使用了大规模自动生成的语料库(Wang et al., 2018)作为训练数据。
此外,还包括了SIGHAN 2013、SIGHAN 2014和SIGHAN 2015的训练集。
对于预训练方法,我们使用了已转换为简体中文字符的中文Wikipedia文本。
我们在SIGHAN 2013、SIGHAN 2014和SIGHAN 2015的测试集上评估我们提出的模型。与以往的工作类似,我们通过OpenCC将传统字符转换为简体字符。
为了更合理地评估我们的模型,我们从SIGHAN训练集随机选取了500个句子,并结合这些500个句子的相应修正结果作为验证集。所有数据集的统计信息见表2。
评估指标
为了与现有的最先进模型进行比较,我们采用了广泛使用的句子级精确度、召回率和F1分数作为评估方法,该方法已在Hong et al. (2019)和Cheng et al. (2020)中使用。
基准模型
我们将我们的模型与几种最先进的模型进行了比较:
- FASPell (Hong et al., 2019): 该模型利用语音和视觉相似度信息来选择候选字符。
- Soft-Masked BERT (Zhang et al., 2020): 该方法结合了基于BERT的检测网络和修正网络。
- SpellGCN (Cheng et al., 2020): 该模型通过一个专门的图卷积网络将语音和视觉相似度知识引入BERT。
- 基于Chunk的方法 (Bao et al., 2020): 该方法利用基于块的框架,并扩展传统的混淆集,增加语义候选项,以覆盖不同类型的错误。
模型超参数
我们在本论文中使用RoBERTawwm (Cui et al., 2019)作为我们的基础模型。
我们使用AdamW (Loshchilov and Hutter, 2019)优化器,学习率为5e-5。
训练批次大小设置为32,所有实验训练12个epochs。为了更好地学习字符之间的依赖关系,我们在前2个epochs使用MASK标记学习DCN模型,与预训练方法相同。训练时候的候选数k设置为5,预测时候设置为8。
Pinyin Enhanced Candidate Generator的卷积窗口大小设置为3。所有隐藏表示的维度为768。
我们从{2e-5, 3e-5, 5e-5}中搜索学习率,并在验证集上选择最优模型。
4.2 实验结果
表3展示了在SIGHAN 2013、SIGHAN 2014和SIGHAN 2015数据集上的实验结果。为了比较,我们报告了句子级精确度、召回率和F1分数。
| 数据集 | 模型 | 检测级精确度 (D-P) | 检测级召回率 (D-R) | 检测级F1分数 (D-F) | 修正级精确度 (C-P) | 修正级召回率 (C-R) | 修正级F1分数 (C-F) |
|---|---|---|---|---|---|---|---|
| SIGHAN 2013 | FASPell (Hong et al., 2019) | 76.2 | 63.2 | 69.1 | 73.1 | 60.5 | 66.2 |
| BERT (Cheng et al., 2020) | 79.0 | 72.8 | 75.8 | 77.7 | 71.6 | 74.6 | |
| SpellGCN (Cheng et al., 2020) | 80.1 | 74.4 | 77.2 | 78.3 | 72.7 | 75.4 | |
| SpellGCN* | 85.2 | 77.7 | 81.2 | 83.4 | 76.1 | 79.6 | |
| RoBERTa (我们的模型) | 85.4 | 77.7 | 81.3 | 83.9 | 76.4 | 79.9 | |
| RoBERTa-DCN (我们的模型) | 86.2 | 78.4 | 82.1 | 84.6 | 76.9 | 80.5 | |
| RoBERTa-Pretrain-DCN (我们的模型) | 86.8 | 79.6 | 83.0 | 84.7 | 77.7 | 81.0 | |
| SIGHAN 2014 | FASPell (Hong et al., 2019) | 61.0 | 53.5 | 57.0 | 59.4 | 52.0 | 55.4 |
| BERT (Cheng et al., 2020) | 65.6 | 68.1 | 66.8 | 63.1 | 65.5 | 64.3 | |
| SpellGCN (Cheng et al., 2020) | 65.1 | 69.5 | 67.2 | 63.1 | 67.2 | 65.3 | |
| RoBERTa (我们的模型) | 64.2 | 68.4 | 66.2 | 62.7 | 66.7 | 64.6 | |
| RoBERTa-DCN (我们的模型) | 67.6 | 68.6 | 68.0 | 64.9 | 65.9 | 65.4 | |
| RoBERTa-Pretrain-DCN (我们的模型) | 67.4 | 70.4 | 68.9 | 65.8 | 68.7 | 67.2 | |
| SIGHAN 2015 | FASPell (Hong et al., 2019) | 67.6 | 60.0 | 63.5 | 66.6 | 59.1 | 62.6 |
| Soft-Masked BERT (Zhang et al., 2020) | 73.7 | 73.2 | 73.5 | 66.7 | 66.2 | 66.4 | |
| BERT (Cheng et al., 2020) | 73.7 | 78.2 | 75.9 | 70.9 | 75.2 | 73.0 | |
| SpellGCN (Cheng et al., 2020) | 74.8 | 80.7 | 77.7 | 72.1 | 77.7 | 75.9 | |
| RoBERTa (我们的模型) | 74.7 | 77.3 | 76.0 | 72.1 | 74.5 | 73.3 | |
| RoBERTa-DCN (我们的模型) | 76.6 | 79.8 | 78.2 | 74.2 | 77.3 | 75.7 | |
| RoBERTa-Pretrain-DCN (我们的模型) | 77.1 | 80.9 | 79.0 | 74.5 | 78.2 | 76.3 |
备注: D-P: 检测级精确度,D-R: 检测级召回率,D-F: 检测级F1分数,C-P: 修正级精确度,C-R: 修正级召回率,C-F: 修正级F1分数。
4.2 实验结果
实验结果如表3所示。
我们提出的RoBERTa-DCN模型在三个SIGHAN测试集上具有最佳的检测和纠正性能。
FASPell和SpellGCN模型使用复杂的技术来结合语音学和视觉信息,取得了相对较好的性能。
我们的DCN模型则更专注于处理不一致问题,并建模输出标记之间的依赖关系。
我们提出的模型通过简单地使用拼音增强候选生成器来建模语音信息,从而超越了FASPell和SpellGCN,这也说明了DCN的有效性。
当我们使用维基数据进行预训练DCN时,模型的效果得到了进一步提升。
这表明建模输出中文字符之间的依赖关系非常重要。如果使用更多数据来学习这些依赖关系,DCN可能会取得更好的性能。
软掩码BERT同时使用了检测网络和纠正网络。相比之下,我们的DCN模型直接预测目标序列,并将输入序列和目标序列之间的不同标记视为检测结果。如实验结果所示,与软掩码BERT相比,我们的方法在检测和纠正上分别提高了5.5%和9.9%。
为了与其他一些最先进的工作进行对比,我们还使用SIGHAN 2015的官方评估工具对我们提出的模型进行了评估,结果见表4。
基于Chunk的方法通过一系列方法构建候选集,虽然在精度上取得了良好的性能,但该方法的召回率相对较低,我们方法的F分数显著超过了基于Chunk的方法,超过了10%。
同样,我们的模型也比SpellGCN取得了更好的结果。
表4:SIGHAN 2015官方工具评估的性能
| 模型 | 检测级别 | 纠正级别 | ||||||
|---|---|---|---|---|---|---|---|---|
| D-Acc | D-P | D-R | D-F | C-Acc | C-P | C-R | C-F | |
| Chunk-based method (Bao et al., 2020) | 76.8 | 88.1 | 62.0 | 72.8 | 74.6 | 87.3 | 57.6 | 69.4 |
| BERT (Cheng et al., 2020) | 83.0 | 85.9 | 78.9 | 82.3 | 81.5 | 85.5 | 75.8 | 80.5 |
| SpellGCN (Cheng et al., 2020) | 83.7 | 85.9 | 80.6 | 83.1 | 82.2 | 85.4 | 77.6 | 81.3 |
| RoBERTa (Ours) | 83.2 | 86.6 | 78.6 | 82.4 | 81.8 | 86.2 | 75.8 | 80.7 |
| RoBERTa-DCN (Ours) | 84.2 | 86.4 | 81.1 | 83.7 | 82.8 | 86.0 | 78.4 | 82.0 |
| RoBERTa-Pretrain-DCN (Ours) | 84.6 | 88.0 | 80.2 | 83.9 | 83.2 | 87.6 | 77.3 | 82.1 |
表5:候选生成方法的效果
| 采样方法 | D-F | C-F |
|---|---|---|
| 词汇的Top-k | 89.7 | 88.7 |
| 多项分布采样 | 88.1 | 87.6 |
| 随机采样 | 12.2 | 7.3 |
| 混淆集的Top-k | 35.8 | 34.7 |
4.3 候选生成的效果
DCN的性能随着候选生成策略和采样候选字符的数量而变化。
我们比较了四种采样方法对训练的影响,分别是从词汇表中采样top-k候选字符、从混淆集采样top-k候选字符、从词汇表中随机采样以及从多项分布中采样。对于多项分布采样,概率是从拼音增强候选生成器(Pinyin Enhanced Candidate Generator,PECGenerator)的Softmax输出中获得的。所有后续实验都在验证集上进行,实验结果如表5所示。
从表5中可以看出,词汇表的top-k方法具有最佳性能。
多项分布采样也表现良好,而随机采样和混淆集的top-k方法则未能取得良好的性能。这意味着采样一些困难的候选字符更有利于模型训练,从而提高模型的区分能力。
我们还进行了关于候选数量影响的实验。
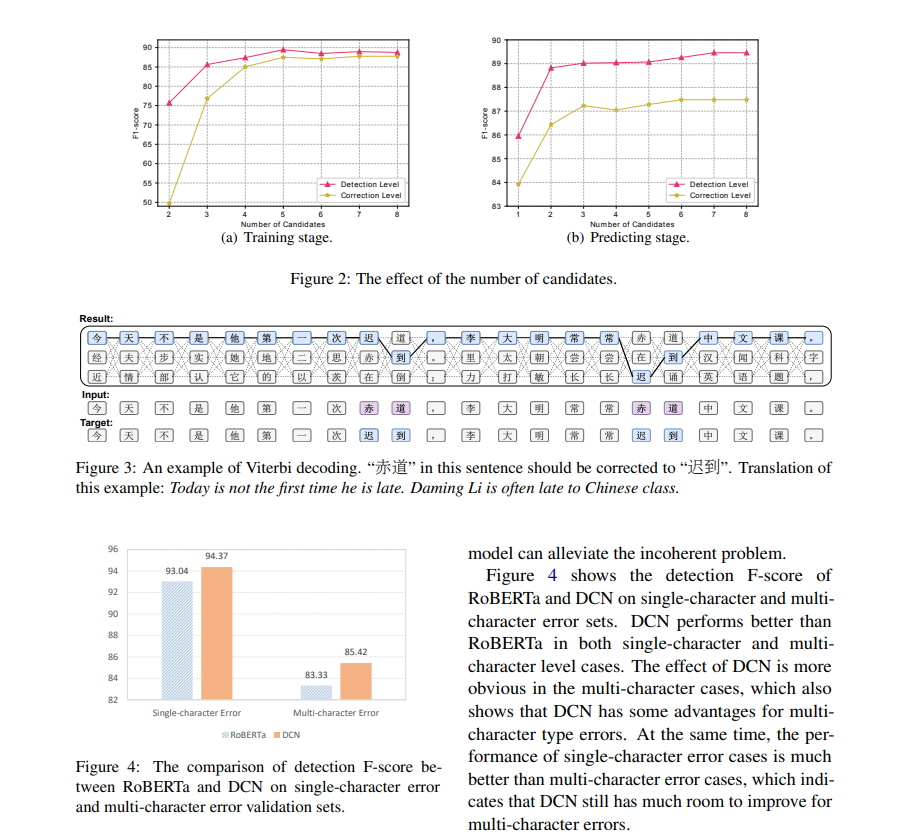
图2(a)展示了随着训练候选数量增加,效果变化的曲线。随着候选数量的增加,效果在开始时逐渐提高,但当预测候选数量超过5时,效果不再有显著提升。
图2(b)展示了在将训练候选数量固定为5时,增加预测候选数量的性能。
随着预测候选数量的增加,性能持续提升。
表6:DCN在验证集上的消融实验
| 模型 | D-P | D-R | D-F | C-P | C-R | C-F |
|---|---|---|---|---|---|---|
| RoBERTa-DCN | 89.8 | 89.6 | 89.7 | 88.8 | 88.6 | 88.7 |
| - PECGenerator | 87.7 | 88.4 | 88.1 | 86.7 | 87.4 | 87.1 |
| - DCScorer | 87.4 | 88.4 | 87.9 | 86.8 | 87.8 | 87.3 |
| - 加权损失 | 87.6 | 89.0 | 88.3 | 86.8 | 88.2 | 87.5 |
| RoBERTa | 86.1 | 89.2 | 87.6 | 85.5 | 88.6 | 87.0 |
PECGenerator是拼音增强候选生成器。加权损失指的是损失条件下的情况。
当我们移除PECGenerator时,RoBERTa通过预测候选字符来生成候选字符。当移除DCScorer时,模型选择top-1预测结果作为正确字符。
4.4 消融实验
我们进行了一系列实验,以确定DCN模型中哪些组件发挥了更重要的作用。
表6展示了实验结果。
当我们移除拼音增强候选生成器(PECGenerator)时,检测和纠正的F分数分别下降了约1.5%。这表明,语音信息在候选生成方法中起着重要作用。
当我们移除动态连接得分器(dynamic connected scorer)时,检测F分数下降了近2%,这表明中文字符之间的依赖关系对CSC任务非常重要。
同样,加权损失也帮助我们的模型提高了性能。
图2:候选数量的影响
(a) 训练阶段
随着训练候选数量的增加,效果逐渐提高,但当候选数量超过5时,效果不再有显著的提升。
(b) 预测阶段
当训练候选数量固定为5时,增加预测候选数量后,性能持续提升。
表6:DCN在验证集上的消融实验
| 模型 | D-P | D-R | D-F | C-P | C-R | C-F |
|---|---|---|---|---|---|---|
| RoBERTa-DCN | 89.8 | 89.6 | 89.7 | 88.8 | 88.6 | 88.7 |
| - PECGenerator | 87.7 | 88.4 | 88.1 | 86.7 | 87.4 | 87.1 |
| - DCScorer | 87.4 | 88.4 | 87.9 | 86.8 | 87.8 | 87.3 |
| - 加权损失 | 87.6 | 89.0 | 88.3 | 86.8 | 88.2 | 87.5 |
| RoBERTa | 86.1 | 89.2 | 87.6 | 85.5 | 88.6 | 87.0 |
PECGenerator是拼音增强候选生成器。加权损失指的是损失条件下的情况。
4.5 案例研究与分析
我们发现,DCN模型在连续错误的处理上比原始RoBERTa模型表现得更好。
图3展示了一个连续错误的例子。
原始的RoBERTa模型无法很好地检测该错误,只能部分纠正,因为连续错误会相互影响。
相比之下,DCN能够完全纠正这些错误。
该例子的最佳路径如图所示,正确的中文字符“迟到”并没有排在第一位,但包含“迟到”的路径得分最高,因为这些路径比其他候选组合更流畅。这个例子也展示了我们的模型能够缓解不一致问题。
图4展示了RoBERTa和DCN在单字符错误和多字符错误集上的检测F分数。
DCN在单字符错误和多字符错误两种情况下的表现均优于RoBERTa,尤其在多字符错误的情况中,DCN的效果更加明显,这也表明DCN在处理多字符类型错误时具有一些优势。
同时,单字符错误的表现远优于多字符错误,这表明DCN在多字符错误方面仍有很大的改进空间。
通过对比RoBERTa和带有候选生成器的RoBERTa的结果,我们发现,96.7%的正确字符位于RoBERTa的前5个候选中。
相比之下,98.6%的正确字符位于带有候选生成器的RoBERTa的前5个候选中。
这一结果表明,拼音增强候选生成器可以生成更好的候选字符。
- F2-F3-F4
5 结论
本文提出了一种新型模型DCN,用于解决CSC任务中的不一致问题。
为了更好地融合语音信息,我们提出了一种简单而有效的拼音增强候选生成器。
实验结果表明,我们提出的模型在三个数据集上达到了当前最先进的性能。
DCN还可以应用于其他任务,如非自回归机器翻译。至于未来的工作,如何更好地利用语音和视觉信息仍然需要进一步讨论。
致谢
本研究得到了中国国家重点研发计划(No. 2018YFC0832302)的支持。感谢匿名评审员和王小雪博士的深入评论和建议。
小结
希望本文对你有所帮助,如果喜欢,欢迎点赞收藏转发一波。
我是老马,期待与你的下次相遇。
参考资料
https://blog.csdn.net/qq_36426650/article/details/122796348
