拼写纠正系列
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计、论文和开源实现。
论文 & 源码
论文:https://aclanthology.org/2021.findings-acl.122.pdf
源码:-
摘要
最近,利用BERT框架进行中文拼写错误纠正(CSC)取得了进展。
然而,大多数现有方法仅基于局部上下文信息来纠正单词,而没有考虑句子中错误单词的影响。
对错误上下文信息施加注意力可能会误导并降低CSC的整体性能。
为了解决这个问题,我们提出了一种全局注意力解码器(Global Attention Decoder, GAD)方法用于CSC。
具体来说,所提出的方法学习潜在正确输入字符与潜在错误字符候选之间的全局关系。
通过获取丰富的全局上下文信息,减轻局部错误上下文信息的影响。
此外,我们设计了一种基于混淆集指导替换策略(Confusion Set Guided Replacement Strategy, BERT CRS)的BERT模型,以缩小BERT与CSC之间的差距。
BERT CRS生成的候选字符的正确概率超过99.9%。
为了验证我们提出的框架的有效性,我们在三个人工标注的数据集上进行了测试。
实验结果表明,我们的方法在所有数据集上都以最多6.2%的优势超越了所有竞争模型,达到了当前最先进的水平。
1 引言
拼写错误纠正在人类语言处理(NLP)领域中起着重要作用。
一个良好的拼写错误系统是提高上层应用性能的关键。
拼写错误纠正旨在检测并纠正错误的字符/单词。
这些拼写错误主要来自人类写作、语音识别和光学字符识别(OCR)系统(Afli 等,2016)。
在中文中,错误类型通常源于字符/单词的语音、视觉和语义相似性。
根据(Cheng 等,2020)的研究,大约83%的错误与语音相似性相关,48%的错误与视觉相似性相关。尽管许多研究取得了显著进展,中文拼写错误纠正(CSC)仍然是一项具有挑战性的任务。
此外,由于中文由表意字符组成且没有单词分隔符,来自如英语等语言的方法很难直接应用于中文。
此外,同一字符在不同上下文中的含义可能会发生较大变化。
为了解决这个问题,许多方法已被提出用于CSC任务,主要分为两类:
1)基于语言模型的方法(Yeh 等,2013;Yu 和 Li,2014;Xie 等,2015);
2)基于序列到序列(seq2seq)模型的方法(Wang 等,2019,2018)。
特别是随着预训练BERT模型的出现,许多方法(Hong 等,2019;Zhang 等,2020;Cheng 等,2020)取得了显著进展。
几乎所有方法都利用了混淆集,其中包含一组在语音和视觉上相似的字符。具体来说,(Yu 和 Li,2014)提出基于混淆集生成候选字符,并通过语言模型找到最佳候选。
(Cheng 等,2020)引入了卷积图网络,利用混淆集捕捉字符之间的相似性和先验依赖关系。
(Wang 等,2019)提出了一种指针网络,用于从混淆集中生成字符。
之前的方法基于局部上下文预测每个字符或单词,而这些局部上下文可能包含噪声信息(如其他错误)。
迄今为止,尚未提出缓解这些噪声信息影响的方法。
在本文中,我们首先介绍了一种基于混淆集指导替换策略(BERT CRS)的BERT模型,该模型缩小了BERT和CSC任务之间的差距。
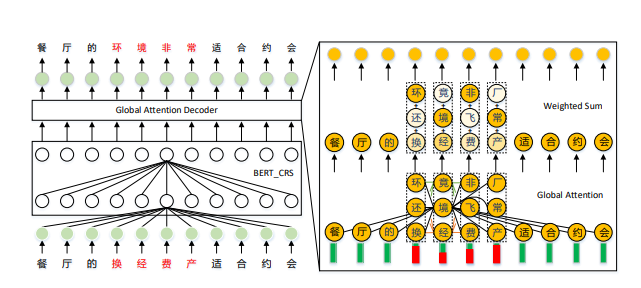
接着,我们提出了一种新颖的全局注意力解码器(GAD),该解码器基于BERT CRS模型(见图1),通过学习丰富的全局上下文表示来缓解纠正过程中错误上下文信息的影响。
具体来说,为了解决局部错误上下文信息的影响,我们引入了额外的潜在错误字符候选及由BERT CRS生成的隐藏状态。
接下来,全局注意力组件学习候选字符之间的关系,以获取全局隐藏状态和候选字符的潜在全局注意力权重。
然后,采用加权求和操作对每个字符的候选进行加权,以生成丰富的全局上下文隐藏状态。
最后,通过全连接层生成正确的字符。
如表1所示,我们提出的方法能够正确地纠正所有拼写错误。
值得强调的是,本文提出方法的以下几个方面:
-
为了缩小BERT和CSC之间的差距,我们引入了基于混淆集指导替换策略的BERT模型,其中包含一个决策网络和一个全连接层,分别模拟CSC的检测和纠正子任务。
-
我们提出了一种全局注意力解码器模型,该模型学习潜在正确输入字符与潜在错误字符候选之间的全局关系。通过学习丰富的全局上下文信息,能够有效地缓解局部错误上下文信息的影响。
-
在三个基准数据集上的实验表明,我们的方法在所有数据集上超越了当前最先进的技术方法,性能提升幅度最高可达6.2%。
通过学习丰富的全局上下文信息,减轻了局部噪声上下文信息的影响。
- 表 1
**输入**
餐厅的换经费产适合约会
The restaurant’s swap property is suitable for dates
**BERT CRS**
餐厅的环经非常适合约会
The restaurant’s ring is perfect for dates
**+GAD**
餐厅的环境非常适合约会
The restaurant environment is perfect for dates
表1: 来自SIGHAN 2014(Yu 等,2014)的一个示例数据,错误字符和正确字符分别用红色和绿色标记。
由于“经”在其上下文中与“费”高度相关,BERT CRS难以纠正此错误。
GAD方法学习了输入错误字符“换”和“经”候选中的“环”和“境”之间的全局关系(见图1)。
通过学习丰富的全局上下文信息,减轻了局部噪声上下文信息的影响。
- 图1: 我们提出的全局注意力解码器方法的框架。为了说明模型的有效性,错误单词和检测概率用红色标记。
例如,”换经费产”及其对应的错误检测概率显示在右下角。注意力权重通过右侧的色调表示。
2 相关工作
至今为止,中文拼写错误纠正(CSC)任务已有大量研究。接下来,我们将讨论不同阶段的算法。
N-gram阶段
早期的CSC研究遵循错误检测、候选生成和候选选择的流程。
几乎所有提出的方法(Yeh 等,2013;Yu 和 Li,2014;Xie 等,2015;Tseng 等,2015)都使用了无监督的n-gram语言模型来检测错误。
接着,引入了混淆集(即字符相似性的外部知识)来限制候选集。最后,选择具有最高n-gram语言模型概率的最佳候选作为纠正字符。
具体来说,(Yeh 等,2013)提出了一种基于倒排索引的n-gram方法,用于将潜在的拼写错误字符映射到相应的字符。
(Xie 等,2015)利用混淆集替换字符,然后通过联合二元语法和三元语法语言模型评估修改后的句子。
在(Jia 等,2013;Xin 等,2014)中,采用图模型表示句子,并在图上执行单源最短路径(SSSP)算法来纠正拼写错误。
其他方法将其视为序列标注问题,使用条件随机场或隐马尔可夫模型(Tseng 等,2015;Wang 等,2018)。
深度学习阶段
随着深度学习方法的发展(Vaswani 等,2017;Zhang 等,2020;Hong 等,2019;Wang 等,2019;Song 等,2017;Guo 等,2016),所有NLP任务都取得了显著进展。
BERT(Devlin 等,2018)、XLNET(Yang 等,2019)、Roberta(Liu 等,2019)和ALBERT(Lan 等,2019)在几乎所有NLP任务中都表现优异。
混淆集仍然是当前CSC任务研究中的一个重要部分,但已经进行了更多的升级。
具体来说,在(Hong 等,2019)中,使用了预训练的掩蔽语言模型作为编码器。一个置信度相似度解码器利用相似度分数来选择候选字符,而不是使用混淆集。
(Vaswani 等,2017)提出了一种专用的图卷积网络,将语音和视觉相似性知识融入到BERT模型中。
在(Zhang 等,2020)中,介绍了一种基于GRU的检测网络,并通过软掩蔽技术将其与基于BERT的纠正网络连接起来。
其他研究(Wang 等,2019)使用了带有复制机制的Seq2Seq模型,该模型在生成新句子时考虑了来自混淆集的额外候选字符。
3 提出的方法
在本节中,我们首先详细描述问题的形式化。
然后,我们简要说明如何通过我们的BERT CRS模型缩小BERT(Devlin 等,2018)与中文拼写错误纠正(CSC)之间的差距。最后,我们介绍我们新提出的全局注意力解码器(GAD)框架。
3.1 问题形式化
CSC旨在检测和纠正中文文本中的错误。
给定一个序列 X = {x1, x2, …, xn},其中 n 表示字符的数量,我们的BERT CRS模型将其编码为一个连续的表示空间 V = {v1, v2, …, vn},其中 vi ∈ Rd 是第 i 个字符的上下文特征,且 d 是特征的维度。这里,决策网络 Φd 对 V 进行建模,以拟合一个序列 Z = {z1, z2, …, zn},其中 zi 表示第 i 个字符的检测标签,若 zi = 1,则表示该字符是错误的;若 zi = 0,则表示该字符是正确的。BERT CRS 上方的全连接层作为纠正网络 Φc 对 V 进行建模,以拟合一个序列 Y = {y1, y2, …, yn},其中 yi 是第 i 个字符的纠正标签。
与简单的全连接层作为解码器不同,我们的 GAD 模型通过建模额外的候选字符 c = {c1, c2, …, cn} 来减轻局部错误上下文信息的影响,其中 c 代表潜在的正确输入字符和潜在错误字符的候选集,定义如下:
ci =
{
{ci1, ci2, ..., cik}, 若 P(zi = 1) ≥ t
xi, 若 P(zi = 1) < t
}
其中 k 是候选字符的数量,t 是字符的错误概率阈值。
3.2 BERT CRS方法用于CSC
在这一部分,我们借鉴了前人的研究(Devlin 等,2018;Liu 等,2019;Cui 等,2020),并引入了一种利用混淆集的替换策略,缩小BERT与CSC模型之间的差距。
我们称该模型为BERT CRS(基于混淆集指导的替换策略的BERT)。
与BERT任务不同,BERT CRS有几个修改之处:
-
我们取消了NSP任务,采用了一个决策网络来检测错误信息,这与CSC的检测子任务类似。
-
类似于MacBERT(Cui 等,2020),我们不使用[MASK]标记进行掩蔽,而是通过替换语音和视觉相似的字符来引导替换策略,用于掩蔽目的。极少数情况下,如果没有混淆字符,我们将使用[MASK]标记。这一策略类似于CSC的纠正子任务。
-
我们用23%的输入字符进行掩蔽。为了保持检测目标(0为不替换,1为替换)的平衡,我们设置了35%、30%、30%和5%的概率,分别用于不掩蔽、替换为混淆字符、使用[MASK]标记掩蔽以及替换为随机词汇。计算后,替换和掩蔽的概率与BERT的掩蔽概率大致相同。
通过混淆集指导的替换策略训练的模型,得到的前k个候选字符几乎都来自混淆集,这为我们的GAD模型做好了准备。
学习过程
与RoBERTa(Liu 等,2019)类似,混淆集指导的替换策略在训练过程中采用动态方法。
错误检测和纠正在学习过程中同时优化。
错误检测损失 Ld 和纠正损失 Lc 的目标函数分别为:
Ld = - Σ (i=1 to n) log P(zi | Φd(V)) (公式2)
Lc = - Σ (i=1 to n) log P(yi | Φc(V)) (公式3)
总体目标函数为:
L = Lc + λ × Ld (公式4)
其中 Ld 和 Lc 分别是错误检测和纠正损失的目标,L 是总的目标函数,线性组合了 Ld 和 Lc,而 λ ∈ [0, 1] 表示检测损失 Ld 的系数。
特别地,λ = 0 表示不考虑检测损失。
3.3 全局注意力解码器 (GAD)
在本文中,我们提出了一种全局注意力解码器(GAD)模型,用于减轻局部错误上下文信息的影响。
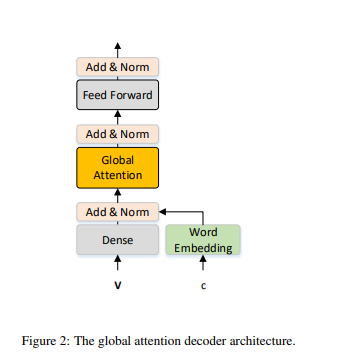
我们的 GAD 是变换器层(Vaswani 等,2017)的扩展,如图 2 所示。
- Figure 2: The global attention decoder architecture
自注意力机制
相对来说,自注意力机制是变换器层的一部分,它将前一层的输出或输入嵌入层作为输入,得到具有更高语义表示的隐藏状态,如图 1 的左部分所示。
自注意力方法中,第 i 个位置的第 l 层的标记表示 VAl_i 定义如下:
VAl_i = Σ (p=1 to n) a_p_i * V(l-1)_p * WV (公式5)
其中,a_p_i 是从第 i 个标记到第 p 个标记的注意力权重,Σ (p=1 to n) a_p_i = 1,V(l-1)_p 是第 (l-1) 层的第 p 个标记表示,WV 是可学习的投影矩阵。
这一策略能够有效地编码丰富的标记和句子级别的特征。
然而,拼写错误信息也会被编码到 CSC 的隐藏状态中,施加错误上下文信息的注意力可能会误导模型,导致整体性能下降。
全局注意力
与仅使用局部输入信息(见公式 5)不同,我们考虑潜在的正确输入以及潜在错误字符的候选集,学习它们之间的潜在关系,从而减轻局部错误上下文带来的影响。
具体地,如图 2 所示,我们考虑了两个输入源:
- 上下文表示 V,其中包含丰富的语义信息
- 由 Φc 纠正网络生成的 Top-k 候选字符 c。为了减少学习过程中 GAD 的混淆,我们仅为潜在错误字符生成候选集(见公式 1)。
为了建模这两种不同的信息,我们首先使用 BERT CRS 中的词嵌入 E 将候选集嵌入到连续表示中。然后,引入全连接层和层归一化层,将 V 和 E(c) 转换为输入状态 GI:
GI = LayerNorm(Dense(V) + E(c)) (公式6)
我们的全局注意力用于学习候选集 c 之间的潜在关系。全局注意力组件中,第 i 个标记的第 j 个候选字符的标记表示 GAi,j 定义如下:
GAi,j = Σ (p=1 to n) Σ (q=1 to k) a_p,q_i,j * GIp,q * WV_g (公式7)
其中,WV_g 是可学习的投影矩阵,a_p,q_i,j 是从第 i 个标记的第 j 个候选字符到第 p 个标记的第 q 个候选字符的注意力权重,GIp,q 是第 p 个标记的第 q 个候选字符的输入状态。我们在同一标记的候选集之间采用掩蔽策略:
a_p,q_i,j = 0, 如果 i = p 且 j ≠ q (公式8)
并且 Σ (p=1 to n) Σ (q=1 to k) a_p,q_i,j = 1。
最后,全局注意力状态 GAi 在全局注意力组件中的第 i 个位置的定义如下:
GAi = Σ (j=1 to k) βi,j * GAi,j (公式9)
其中,βi,j 是第 i 个标记第 j 个候选字符的全局注意力权重,量化了特征 GAi,j 的全局相关性,εp,q_i,j 和 εi,j 分别表示 a_p,q_i,j 和 βi,j 的未归一化相关分数。类似于标准的变换器层,使用前馈和层归一化将 GA 编码为最终的全局连续表示。
此外,我们在全局注意力中采用了变换器层中使用的多头技术。
学习过程
给定由我们的 BERT CRS 生成的隐藏状态 V 和候选字符 c,GAD 模型在学习过程中拟合正确的序列 Y。
Lg = - Σ (i=1 to n) log P(yi | Φg(V)) (公式10)
其中,Φg 是我们的 GAD 网络,Lg 表示我们的 GAD 总体目标。
4 实验
在本节中,我们将在中文拼写错误纠正(CSC)任务上评估我们的算法。
首先,我们展示了训练数据、测试数据和评估指标。接着,我们介绍了与之前最先进的基线方法的对比结果。然后,我们进行消融实验,分析所提出组件的有效性。最后,我们进行案例研究。
4.1 数据集
我们考虑了三个公开可用的 SIGHAN 数据集,分别来自 2013 年(Wu 等,2013)、2014 年(Yu 等,2014)和 2015 年(Tseng 等,2015)的中文拼写检查竞赛。根据 Cheng 等(2020)的方法,我们采用了 SIGHAN 数据集的标准训练和测试数据划分。同时,我们也遵循了相同的数据预处理方法,将数据集中的字符从繁体字转换为简体字,使用了 OpenCC 工具。
对于训练数据集,我们还收集了来自新闻、维基百科和百科全书问答领域的 300 万个未标记语料,用于预训练我们的 BERT CRS 模型。根据 Wang 等(2019)的研究,我们还包括了 27 万个样本作为有标签的训练数据,这些数据是通过自动化方法生成的(Wang 等,2018)。数据的统计信息见表 2。
4.2 基线方法
为了评估我们提出的算法性能,我们将其与以下基线方法进行比较:
- JBT (Xie 等,2015): 该方法利用混淆集替换字符,然后通过联合二元和三元语言模型(LM)评估修改后的句子。
- Hybrid (Wang 等,2018): 该方法提出了一种管道方法,其中采用双向 LSTM 序列标注模型进行检测。
- Seq2Seq (Wang 等,2019): 该方法引入了一个带有复制机制的 Seq2Seq 模型,以考虑来自混淆集的额外候选字符。
- FASpell (Hong 等,2019): 该模型通过使用相似性度量选择候选字符,而不是预定义的混淆集,改变了方法的范式。
- Soft-Masked BERT (Zhang 等,2020): 该方法提出了一种检测网络,通过软掩码技术连接错误纠正模型。
- SpellGCN (Cheng 等,2020): 该模型通过一个专门的图卷积网络将语音学和视觉相似性知识融入到语言模型中,用于中文拼写纠正(CSC)。
- BERT (Devlin 等,2018): 使用 BERT 的词嵌入作为 CSC 任务中的纠正解码器。
4.3 实验结果
表 3 显示了我们与其他方法在字符级检测和纠正任务上的性能比较。
通过在检测和纠正层面评估模型的准确性,我们可以看到,BERT CRS 模型与之前的最先进模型的性能相当。
而加入全局注意力解码器(GAD)后,模型的性能有了显著提升。
| 测试集 | 模型 | 检测层预召回率 (%) | 检测层 F1 (%) | 纠正层预召回率 (%) | 纠正层 F1 (%) |
|---|---|---|---|---|---|
| SIGHAN13 | JBT (Xie 等,2015) | 79.8 | 61.5 | 77.6 | 35.1 |
| Hybrid (Wang 等,2018) | 54.0 | 60.7 | - | 52.1 | |
| Seq2Seq (Wang 等,2019) | 56.8 | 70.1 | 79.7 | 68.1 | |
| SpellGCN (Cheng 等,2020) | 82.6 | 85.7 | 98.4 | 93.1 | |
| BERT (Cheng 等,2020) | 80.6 | 84.3 | 98.1 | 92.3 | |
| BERT CRS | 85.5 | 87.3 | 98.9 | 93.4 | |
| +GAD | 85.8 | 87.6 | 99.0 | 93.5 | |
| SIGHAN14 | JBT (Xie 等,2015) | 56.4 | 43.0 | 71.1 | 58.8 |
| Hybrid (Wang 等,2018) | 51.9 | 58.2 | - | 56.1 | |
| Seq2Seq (Wang 等,2019) | 63.2 | 71.6 | 79.3 | 73.7 | |
| SpellGCN (Cheng 等,2020) | 83.6 | 81.0 | 97.2 | 85.5 | |
| BERT (Cheng 等,2020) | 82.9 | 80.2 | 96.8 | 84.6 | |
| BERT CRS | 84.6 | 82.9 | 97.4 | 87.4 | |
| +GAD | 85.1 | 82.9 | 98.0 | 87.6 | |
| SIGHAN15 | JBT (Xie 等,2015) | 83.8 | 40.0 | 71.1 | 58.8 |
| Hybrid (Wang 等,2018) | 56.6 | 62.3 | - | 57.1 | |
| Seq2Seq (Wang 等,2019) | 66.8 | 69.8 | 71.5 | 69.9 | |
| SpellGCN (Cheng 等,2020) | 88.9 | 88.3 | 95.7 | 89.4 | |
| BERT (Cheng 等,2020) | 87.5 | 86.6 | 95.2 | 87.8 | |
| BERT CRS | 88.1 | 88.0 | 96.1 | 89.9 | |
| +GAD | 88.6 | 88.2 | 96.3 | 90.1 |
从表 3 可以看出,加入全局注意力解码器(GAD)后,我们的模型在所有测试集上都表现出了最佳的检测和纠正性能,特别是在 F1 值上,明显优于其他方法。
4.3 实现细节
训练细节:
我们的代码基于 Transformers 库。
首先,我们在 300 万未标记语料上对 BERT CRS 模型进行了微调,使用了预训练的全词遮掩 BERT 模型。
训练过程运行了 5 个周期,批次大小为 1024,学习率为 5e-5,最大序列长度为 512。
接着,我们在所有标记的训练数据上对 BERT CRS 模型进行了微调,运行了 6 个周期,批次大小为 32,学习率为 2e-5。然后,我们固定了 BERT CRS 模型,并设置候选数量 k 和错误检测概率 t 分别为 4 和 0.25。最后,我们对 GAD 模型进行了微调,训练了 3 个周期,批次大小为 32,学习率为 5e-5。针对 SIGHAN 13 数据集,我们进行了额外的 6 个周期的微调,因为 SIGHAN 13 数据集的分布与其他数据集有所不同,例如 “的”、”得” 和 “地” 在这个数据集中很少有区分。
评估指标:
为了评估模型的性能,我们采用了字符级和句子级准确率、精确率、召回率和 F1 值,这些是 CSC 任务中常用的评估指标。
此外,我们还使用了官方的评估工具,该工具提供了句子级的假阳性率(FRT)、精确率、召回率、F1 值和准确率。
实验结果:
表 4 显示了我们与其他方法在句子级别检测和纠正任务上的性能比较。通过比较不同模型在检测层和纠正层的句子级 F1 值,我们可以看到,BERT CRS 模型在检测和纠正任务中表现优异,加入 GAD 后,性能进一步提升。
| 测试集 | 模型 | 检测层精确率 (%) | 检测层召回率 (%) | 检测层 F1 (%) | 纠正层精确率 (%) | 纠正层召回率 (%) | 纠正层 F1 (%) |
|---|---|---|---|---|---|---|---|
| SIGHAN13 | FASpell (Hong 等,2019) | 76.2 | 63.2 | 69.1 | 73.1 | 60.5 | 66.2 |
| SpellGCN (Cheng 等,2020) | 80.1 | 74.4 | 77.2 | 78.3 | 72.7 | 75.4 | |
| BERT (Cheng 等,2020) | 79.0 | 72.8 | 75.8 | 77.7 | 71.6 | 74.6 | |
| BERT CRS | 84.8 | 79.5 | 82.1 | 83.9 | 78.7 | 81.2 | |
| +GAD | 85.7 | 79.5 | 82.5 | 84.9 | 78.7 | 81.6 | |
| SIGHAN14 | FASpell (Hong 等,2019) | 61.0 | 53.5 | 57.0 | 59.4 | 52.0 | 55.4 |
| SpellGCN (Cheng 等,2020) | 65.1 | 69.5 | 67.2 | 63.1 | 67.2 | 65.3 | |
| BERT (Cheng 等,2020) | 65.6 | 68.1 | 66.8 | 63.1 | 65.5 | 64.3 | |
| BERT CRS | 65.4 | 72.7 | 68.9 | 63.4 | 70.4 | 66.7 | |
| +GAD | 66.6 | 71.8 | 69.1 | 65.0 | 70.1 | 67.5 | |
| SIGHAN15 | FASpell (Hong 等,2019) | 67.6 | 60.0 | 63.5 | 66.6 | 59.1 | 62.6 |
| Soft-Masked BERT (Zhang 等,2020) | 73.7 | 73.2 | 73.5 | 66.7 | 66.2 | 66.4 | |
| SpellGCN (Cheng 等,2020) | 74.8 | 80.7 | 77.7 | 72.1 | 77.7 | 74.8 | |
| BERT (Cheng 等,2020) | 73.7 | 78.2 | 75.9 | 70.9 | 75.2 | 73.0 | |
| BERT CRS | 74.0 | 80.2 | 77.2 | 72.2 | 77.8 | 74.8 | |
| +GAD | 75.6 | 80.4 | 77.9 | 73.2 | 77.8 | 75.4 |
从表 4 可以看出,BERT CRS 模型在所有测试集上都表现出较强的性能,加入 GAD 后,模型的性能进一步得到提升,特别是在纠正层的精确率和 F1 值上。
4.4 主要结果
我们将我们的模型与现有的最先进方法进行了比较,使用了三个测试数据集,结果如表 3 和表 4 所示,分别展示了字符级别和句子级别的比较。BERT CRS 在三个数据集上的表现优于几乎所有其他方法,并且与 GAD 结合后,取得了最佳的性能。
具体来说,在相同数量的标注训练数据下,在字符级指标上,我们的方法相较于之前的最佳结果(SpellGCN)在纠正层的 F1 值上分别提升了 0.4%、2.1%、0.7%。在句子级指标上,我们的模型在纠正层 F1 值上超越了 SpellGCN,分别提升了 6.2%、2.2%、0.6%。此外,Soft-Masked BERT 使用了 500 万个生成的额外训练数据,而我们的模型在 SIGHAN15 测试数据集上大幅超越了它。
我们进一步考虑了在 SIGHAN15 数据集上,BERT CRS 和 GAD 与 BERT 和 SpellGCN 的官方评估结果。
正如表 6 所示,我们提出的 BERT CRS+GAD 相较于 SpellGCN 在纠正层的 F1 值上提升了 0.2%,同时 FPR(假阳性率)分别为 13.1%(BERT CRS+GAD)与 13.2%(SpellGCN)。
4.5 消融实验
在此子实验中,我们探讨了几个关键参数的影响,包括 BERT CRS 中的系数 λ 和学习率 lr,以及 GAD 中候选数量 k 的影响。
| 模型 | 参数 | 值 | F1 (%) |
|---|---|---|---|
| BERT CRS | λ | 1 | 72.0 |
| 0.5 | 73.4 | ||
| 0.1 | 74.8 | ||
| lr 2e-5 | 74.8 | ||
| 5e-5 | 74.6 | ||
| GAD | k | 3 | 75.4 |
| 4 | 75.1 | ||
| 5 | 74.7 |
BERT CRS 的影响:
BERT CRS 引入了基于混淆集的替换策略,使用 BERT 模型。
与 BERT 模型相比,在表 3 中的字符级别指标上,BERT CRS 在纠正层 F1 值上分别提高了 6.6%、2.5%、1.8%。在表 4 中的句子级别指标上,我们分别在 SIGHAN 13、SIGHAN 14 和 SIGHAN 15 数据集上的 F1 值分别为 81.2%、66.7%、74.8%,而 BERT 模型的 F1 值分别为 74.6%、64.3%、73.0%。
我们还展示了系数 λ 和学习率在微调过程中对所有标注数据的影响,如表 5 所示。
首先,我们固定学习率为 2e-5,并调整 λ ∈ [0.1, 0.5, 1] 在 SIGHAN15 上的表现。当 λ=0.1 时,达到最佳性能。
此外,不同的 λ 值会导致较大变化,即如果过多关注检测损失,性能会不尽如人意。这种情况可能是由于微调过程中的检测标签不平衡导致的。
因此,在后续实验中,我们设置 λ=0.1。学习率的调整也显示,当选择 2e-5 时,效果最佳。
GAD 的影响:
将 GAD 与 BERT CRS 模型结合后,模型在字符级和句子级指标上的性能都有所提高,如表 3 和表 4 所示。
特别是在句子级指标上,BERT CRS+GAD 在纠正层的 F1 值上分别超越了 BERT CRS 0.4%、0.8% 和 0.6%。
我们还研究了候选数量 k 的影响。由于 k 是决定候选字符覆盖范围的关键参数,它会影响算法的性能。
我们研究了不同 k 值(k ∈ [3, 4, 5])在 SIGHAN15 上的表现。如表 5 所示,更多候选项可能会导致性能下降。
根据统计,在所有测试数据中有 161,365 个错误字符,k 值为 3、4、5 时,分别有 106、75、64 个错误字符不在候选中。
BERT CRS 模型生成的候选项有 99.9% 的概率覆盖正确的字符。考虑到候选项的覆盖率与性能之间的权衡,我们在实验中选择了 k = 4。
4.6 案例研究
为了进一步分析我们的方法,我们展示了一些在测试数据上的纠错结果(见表 7)。
在表 7 中,选择了三种类型的拼写错误:
1)连续字符错误;
2)单字符错误;
3)无字符错误。
对于连续字符错误的实例,例如,“介绍”被错误拼写为“借少”(borrow less)。由于错误字符的影响,BERT CRS 难以完全纠正这些错误。然而,BERT CRS+GAD 缓解了局部错误上下文的影响,能够正确纠正所有错误。
对于单字符错误的实例,例如,“抱”被错误拼写为“包”(pack),我们的 BERT CRS+GAD 相比 BERT CRS 能学习到更丰富的全局上下文信息,从而纠正错误。在无字符错误的情况下,例如,“提议”与“建议”是同义词,BERT CRS 会发生错误。通过 GAD,我们能够更好地利用全局上下文信息,缓解局部错误上下文的影响,达到更好的纠错效果。
表 7 中的示例展示了 CSC(拼写纠错)的结果,红色标记为错误字符,绿色标记为正确字符。
表中的第一行是输入句子,第二行和第三行分别是 BERT CRS 和 BERT CRS+GAD 的纠正结果,其余为正确句子的英文翻译。
连续字符错误:
- 输入句子:…语言。去外国可以认识很多的人,就可以借少
- BERT CRS:…语言。去外国可以认识很多的人,就可以借绍
- BERT CRS+GAD:…语言。去外国可以认识很多的人,就可以介绍
- 正确翻译:… you can meet a lot of people abroad, and introduce these languages.
单字符错误:
- 输入句子:我把小猫抱起来,赶紧包出去到马路边求救…
- BERT CRS:我把小猫抱起来,赶紧跑出去到马路边求救…
- BERT CRS+GAD:我把小猫抱起来,赶紧抱出去到马路边求救…
- 正确翻译:I picked up the kitten and hurried out to the side of the road for help.
无字符错误:
- 输入句子:…课堂之前可以先有一些提议或许参考的资料…
- BERT CRS:…课堂之前可以先有一些建议或许参考的资料…
- BERT CRS+GAD:…课堂之前可以先有一些提议或许参考的资料…
- 正确翻译:Some suggestions or reference materials can be available before the class.
这些案例证明了我们的 GAD 能够学习丰富的全局上下文信息,缓解局部错误上下文对 CSC 的影响。
我们还展示了一些错误的案例,以进一步分析我们的模型。
例如,对于句子“希望您帮我素取公平,得到他们适当的赔偿”(I hope you can help me x for justice and get proper compensation from them),其中“x”是不可理解的错误单词。我们的 GAD 将“素取”修改为“争取”(strive for),虽然这是上下文中合适的表达,但真实答案应为“诉取”(sue for),因为上下文包含了诉讼的含义。
我们的 GAD 模型也缺乏对强关联上下文的推理能力,正如(Zhang et al., 2020)中所描述的。
5 结论
本文提出了一种新型的全局注意力解码器(GAD)。
在潜在的正确输入字符和潜在错误字符的候选集条件下,GAD 改造了自注意力机制,学习它们的全局关系,并获得丰富的全局上下文信息,以减轻错误上下文带来的影响。
此外,设计了一种基于混淆集的替换策略(BERT CRS)来缩小 BERT 与拼写错误纠正之间的差距。
在三个数据集上的实验结果表明,我们的 BERT CRS 优于几乎所有之前的最先进方法,并且与 GAD 结合后,取得了更高的性能。
小结
希望本文对你有所帮助,如果喜欢,欢迎点赞收藏转发一波。
我是老马,期待与你的下次相遇。
参考资料
https://blog.csdn.net/qq_36426650/article/details/122796348
