中文分词
HMM 的应用场景有很多,我们首先来谈一谈如何实现中文分词。
本文假设读者已经对HMM有所了解,很多地方会直接提出相关概念。
理解前向算法,维特比算法是关键,关于无监督学习HMM的Baum-Welch算法在本文中没有使用,至少了解它的作用即可。
中文分词的难处
总所周知,在汉语中,词与词之间不存在分隔符(英文中,词与词之间用空格分隔,这是天然的分词标记),词本身也缺乏明显的形态标记,因此,中文信息处理的特有问题就是如何将汉语的字串分割为合理的词语序。
例如,英文句子:you should go to kindergarten now 天然的空格已然将词分好,只需要去除其中的介词“to”即可;
而“你现在应该去幼儿园了”这句表达同样意思的话没有明显的分隔符,中文分词的目的是,得到“你/现在/应该/去/幼儿园/了”。
那么如何进行分词呢?
主流的方法有三种:
第1类是基于语言学知识的规则方法,如:各种形态的最大匹配、最少切分方法;
第2类是基于大规模语料库的机器学习方法,这是目前应用比较广泛、效果较好的解决方案.用到的统计模型有N元语言模型、信道—噪声模型、最大期望、HMM等。
第3类也是实际的分词系统中用到的,即规则与统计等多类方法的综合。
模型准备
本质上看,分词可以看做一个为文本中每个字符分类的过程,例如我们现在定义两个类别:
E代表词尾词,B代表非词尾词,于是分词“你/现在/应该/去/幼儿园/了”可以表达为:你E现B在E应B该E去E幼B儿B园E了B,分类完成后只需要对结果进行“解读”就可以得到分词结果了。
序列构建
那么如何找到这个分类序列EBEBEEBBEB呢?
我们可以求得所有可能出现的分类序列的出现概率然后选择其中概率最大的一个,用数学表达为:
argmax C P(C1,C2,C3….Ci) (1)
其中C代表一个分类标识,这里,C 属于 {E,B} 进一步的:
P(C1,C2,C3….Ci) = P(C1)P(C2,C3…..Ci|C1)=P(C1)P(C2|C1)P(C3…..Ci|C1,C2)=
P(C1)P(C2|C1)P(C3|C2,C1)P(C4|C3,C2,C1)…P(Ci|Ci-1….C1)
这里,我们假设第i个分类标记只依赖于第i-1个标记,那么我们可以得到分类标记的马尔科夫链了:
P(C1,C2,C3….Ci) = P(C1)P(C2|C1)P(C3|C2)…P(Ci|Ci-1)
我们称 P(Cj|Ci) 为i到j的状态转移概率,可以通过在大量预料中使用统计的方法求得。
如果我们用(1)这个模型为上例找到了EBEBEEBBEB这个序列,看似好像是一个好的解决方案,不难想到的问题是,对于任何一个10个字符组成的文本,我们都会得到这个相同的序列,也即相同的分词结果,这太可怕了!
问题在于我们只考虑了分类标记而没有考虑被分词的对象,也即每一个具体的字符,我们称这些字符为观察值,用O表示,现在把它们考虑进来,我们要找的是:
argmax C P(C1,C2,C3….Ci | O1, O2, O3……Oi) = P(C|O)(1)
解码问题
给定了O的情况下,最有可能出现的C的序列,也是HMM的“解码问题”,根据贝叶斯公式有:
P(C|O) = P(O|C)P(C) / P(O)
由于P(O)对于每一种序列来说都是一样的,因此可以去掉,因此,(1)等价于 :
argmax C P(O|C)P(C) (2)
P(C)的求法上面已经讲过了,对于 P(O|C),HMM有两个假设:
(a)已知类地序列,观察值在统计上是独立的;
(b)某类的概率密度函数不依赖其他类。也就是说依赖性仅仅存在于产生类的序列,而在类内,观察值服从类自己的规则。
因此对于:
P(O|C) = P(O1, O2, O3……Oi | C1,C2,C3….Ci )
根据假设a,观察序列具有统计意义上的独立性,因此:P(O1, O2, O3……Oi | C1,C2,C3….Ci )=P(O1|C) * P(O2|C)……P(Oi|C)
根据假设b,对于Oi的分类Ci与Cj没有依赖关系,所以有:P(O1|C) * P(O2|C)……P(Oi|C) = P(O1|C1) * P(O2|C2)……P(Oi|Ci)
同样的 P(Oi|Ci) 可以通过在大量预料中使用统计的方法求得。
至此我们在一个马尔科夫链上加入了观察值数据,构造了一个HMM,这个模型已经可以具备一定的分词能力啦!
尽管没有用到,顺便回顾一下HMM要解决的第一个问题“评估”,也即求一个给定观察序列的概率,即:P(O),
用全概率公式展开有:P(O) = sigmaO P(O|C)P(C)(sigmaO代表对O的集合求和),同样需要计算P(O|C),因此计算上和“解码”有相似之处。
模型 (1) 介绍
关于模型(1),在论文HMM Tutorial中写的是:
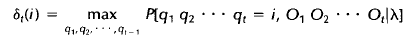
图中O是观察值,q是代表分类序列,λ指HMM模型,可见作者用的是qO的联合概率,而(1)中用的是O作为条件的条件概率。
这个模型和模型(2)是相等的,因此所求的的序列也和模型(1)相等。
个人认为,从理解来看,既然给定了O,是不是把O作为条件概率更合适呢?
算法的性能开销
上文中始终未提到前向算法与Viterbi算法,主要是因为想特意强调一下数学解不等同于算法解。算法解考虑进了计算的性能问题,算法是为计算机设计的。
首先看一下“评估”问题中的时间开销。
穷举法的不可行性
回顾一下公式:
P(O) = sigmaO P(O|C)P(C) = sigmaO P(C1)P(O1|C1)P(C2|C1)P(O2|C2)…P(Ci|Ci-1)P(Oi|Ci)
如果我们使用枚举的方法来求解,那么对于C来说,设有N种状态,序列长度为T,那么所有可能的隐藏序列组合为N^T(N的T次方)个,对于每一个序列需要的乘法次数为2T次,而加法需要T次,那么总共需要的计算次数为 2T*N^T 的级数(精确的,需要 (2T-1)N^T次乘法,N^T-1次加法)。
例如 N=5,T=100,那么需要约 2*100*5^100 约10^72 次计算,显然我们需要一个更好的算法。
例子
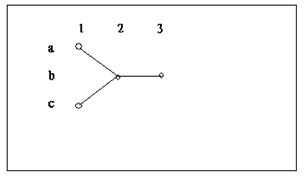
考虑上图这个简单的例子,图中描述了两个隐藏序列:abb,cbb。
为了求得P(O),使用枚举算法有:
Pia * P(O1|a)*Pab*P(O2|b)*Pbb*P(O3|b) + Pic * P(O1|c)*Pcb*P(O2|b)*Pbb*P(O3|b)
向前算法
Pi代表初始概率,使用前向算法有:
(Pia* P(O1|a) *Pab + Pic * P(O1|c)*Pcb) *P(O2|b)*Pbb* P(O3|b)
其中前向算法中的第一个大括号中的式子为局部概率a2(b),可以清楚的看到枚举算法用了10次乘法和1次加法,而前向算法把乘法次数减少到了7次,原因就是前向算法使用了大家熟知的乘法分配律提取了公因式。
看起来好像提升不多,不过当计算量大的话这种提升就很可观了。
事实上,前向算法将计算次数减低到了N^2*T的级数,那么对于N=5,T=100只需要约3000次计算即可。
维特比算法
现在使用上面的例子考虑一下Viterbi算法,使用枚举算法我们需要计算:
Pia * P(O1|a)*Pab*P(O2|b)*Pbb*P(O3|b) 和 Pic * P(O1|c)*Pcb*P(O2|b)*Pbb* P(O3|b)
并比较求得其中较大的一个,而使用Viterbi算法,我们首先比较:
Pia *P(O1|a)*Pab 与 Pic * P(O1|c)*Pcb 的大小,选出较大的一个再乘以 Pbb* P(O3|b)
10次乘法一次比较,减少到5词乘法一次比较。
对比
总结一下,前向算法和Viterbi算法分别从两种角度向我们展现了降低计算复杂度的方法。
一种是提取公因式减少计算次数,例如计算(1+2+3)* 5 和 1*+2*5+3*5,从数学角度来看只是表达的不同,但对于计算者(无论是人还是计算机)来说,少的计算次数意味着更小的计算时间开销;
另一种是,去掉不必要计算,要找到最大的隐藏序列,如果在子序列上都不能取得最大还有必要去计算全序列吗?
纯 HMM 分词
资源介绍
先介绍一下使用的资源,分词使用的语料来自于SIGHAN Bakeoff 2005的 icwb2-data.rar,《中文分词入门之资源》里有很详细的介绍:
/icwb2-data.rar/training/msr_training.utf8 用以训练HMM,其中包含已分词汇约2000000个
/icwb2-data.rar/testing/pku_test.utf8 测试集
/icwb2-data.rar/scripts/score 一个perl脚本,测试分词效果
字符标注模型
我们使用经典的字符标注模型,首先需要确定标注集,在前面的介绍中,我们使用的是{B,E}的二元集合,研究表明基于四类标签的字符标注模型明显优于两类标签,原因是两类标签过于简单而损失了部分信息。
四类标签的集合是 {B,E,M,S},其含义如下:
B:一个词的开始
E:一个词的结束
M:一个词的中间
S:单字成词
举例:你S现B在E应B该E去S幼B儿M园E了S
数据统计构建
用四类标签为 msr_training.utf8 做好标记后,就可以开始用统计的方法构建一个HMM。
我们打算构建一个2-gram(bigram)语言模型,也即一个1阶HMM,每个字符的标签分类只受前一个字符分类的影响。
现在,我们需要求得HMM的状态转移矩阵 A 以及混合矩阵 B。
其中:
Aij = P(Cj|Ci) = P(Ci,Cj) / P(Ci) = Count(Ci,Cj) / Count(Ci)
Bij = P(Oj|Ci) = P(Oj,Ci) / P(Ci) = Count(Oj,Ci) / Count(Ci)
公式中C = {B,E,M,S},O = {字符集合},Count代表频率。
数据平滑技术
在计算Bij时,由于数据的稀疏性,很多字符未出现在训练集中,这导致概率为0的结果出现在B中,为了修补这个问题,我们采用加1的数据平滑技术,即:
Bij = P(Oj|Ci) = (Count(Oj,Ci) + 1)/ Count(Ci)
这并不是一种最好的处理技术,因为这有可能低估或高估真实概率。
更加科学的方法是使用复杂一点的 Good—Turing 技术,这项技术的的原始版本是图灵当年和他的助手Good在破解德国密码机时发明的。
状态转移矩阵-A
求得的矩阵A如下:
| B | M | E | S | |
|---|---|---|---|---|
| B | 0.0 | 0.19922840916814916 | 0.8007715908318509 | 0.0 |
| M | 0.0 | 0.47583202978061256 | 0.5241679702193874 | 0.0 |
| E | 0.6309567616935934 | 0.0 | 0.0 | 0.36904323830640656 |
| S | 0.6343402140354506 | 0.0 | 0.0 | 0.36565844303914763 |
矩阵中出现的概率为0的元素表明B-B, B-S, M-B, M-S, E-M, E-E, S-M, S-E这8种组合是不可能出现的。
这是合乎逻辑的。
混合矩阵-B
求得的矩阵B,部分如下:
| - | o1 | o2 | o3 | o4 |
|---|---|---|---|---|
| B | 7.8127868094E-7 | 1.460991186336E-4 | 0.007293548529516 | 6.047041844505E-4 |
| M | …… | …… | …… | …… |
| E | …… | …… | …… | …… |
| S | …… | …… | …… | …… |
我们设定初始向量Pi = {0.5, 0.0, 0.0, 0.5}(M和E不可能出现在句子的首位)。
至此,HMM模型构建完毕。
其实用统计方法构建HMM并不复杂,麻烦的是写程序,特别是需要将分类标签和字符集合进行编码,这是个极其繁琐的过程。
java 编码
我用的JAVA写程序,因此使用的 Jahmm 这个开源项目来进行相关的计算,对于一个HMM模型,现在我们可以写入一个观察序列,用Viterbi算法获得一个隐藏序列(分词结果)。
具体做法是(举例为虚构):
(1) 对测试集按标点符号,空格,换行符拆分为一条一条的只包含字符的单句:
中共中央总书记
国家主席
(2)将句子转化为对应的编码,也即观察序列:
101 121 101 47 1010 32 1992
332 3241 893 2111
(3)输入观察序列,使用Viterbi算法输出隐藏序列(0:B,1:M,2:E,3:S)
0112333
0202
(4)输出最终分词结果:
中共中央/总/书/记
国家/主席
测评
现在我们在对测试集pku_test.utf8分词,并用perl脚本进行评测,结果如下
=== SUMMARY:
=== TOTAL INSERTIONS: 5627
=== TOTAL DELETIONS: 10639
=== TOTAL SUBSTITUTIONS: 18194
=== TOTAL NCHANGE: 34460
=== TOTAL TRUE WORD COUNT: 104372
=== TOTAL TEST WORD COUNT: 99360:
=== TOTAL TRUE WORDS RECALL: 0.724 正确切分出的词的数目/应切分出的词的总数
=== TOTAL TEST WORDS PRECISION: 0.760 正确切分出的词的数目/切分出的词的总数
=== F MEASURE: 0.742 F1 = 2 * Precision*Recall / (Precision + Recall)
=== OOV Recall Rate: 0.250 未登录词召回率
精度为:76%,召回为:72.4%。一个不太让人满意的结果,我们来看看他都干了些什么:
改判/被/告人/死/刑立/即/执行
这是一个较典型的例子,可见分词结果中出现了“告人”,“刑立”等字典中不存在的词,这些是由于HMM分词的“自由度”太大造成的,当然这种较大的“自由度”也有好处,比如:
检察院/鲍绍坤/检察/长
看!HMM成功的识别出一个人名,这是基于词典的分词方法做不到的。
实际上,在 ICTCLAS系统中(2004)就是用的HMM来识别人名。
提高精度的方式,就是将词典的混合HMM分词器。
优先以字典为准。
jieba 分词的源码分词
我们直接以 jieba 分词的 FinalSeg 类,简单梳理下实现方式,并给出自己的实现。
感觉这个可以进一步抽象,所有的数据可以用户自定义,包括初始化状态。
基本属性
private static FinalSeg singleInstance; // 单例加载模型
private static final String PROB_EMIT = "/prob_emit.txt"; //发射概率矩阵(混合矩阵)
private static char[] states = new char[] { 'B', 'M', 'E', 'S' }; // 初始化状态
private static Map<Character, Map<Character, Double>> emit;
private static Map<Character, Double> start;
private static Map<Character, Map<Character, Double>> trans;
private static Map<Character, char[]> prevStatus;
private static Double MIN_FLOAT = -3.14e100;;
模型加载
上一个状态
一个有穷状态机。
prevStatus = new HashMap<Character, char[]>();
prevStatus.put('B', new char[] { 'E', 'S' });
prevStatus.put('M', new char[] { 'M', 'B' });
prevStatus.put('S', new char[] { 'S', 'E' });
prevStatus.put('E', new char[] { 'B', 'M' });
这里存放的是前一个状态。
比如,开始状态(B)前一个状态只能是结束(E),或者是单个词(S)。
初始化状态
start.put('B', -0.26268660809250016);
start.put('E', -3.14e+100);
start.put('M', -3.14e+100);
start.put('S', -1.4652633398537678);
M/E 不可能出现在开头,所以概率最低。
状态转换矩阵
这里和上文提到的状态是一一对应的,只是数据值有些差异。
Map<Character, Double> transB = new HashMap<Character, Double>();
transB.put('E', -0.510825623765990);
transB.put('M', -0.916290731874155);
trans.put('B', transB);
Map<Character, Double> transE = new HashMap<Character, Double>();
transE.put('B', -0.5897149736854513);
transE.put('S', -0.8085250474669937);
trans.put('E', transE);
Map<Character, Double> transM = new HashMap<Character, Double>();
transM.put('E', -0.33344856811948514);
transM.put('M', -1.2603623820268226);
trans.put('M', transM);
Map<Character, Double> transS = new HashMap<Character, Double>();
transS.put('B', -0.7211965654669841);
transS.put('S', -0.6658631448798212);
trans.put('S', transS);
混合矩阵
这里是直接从文本中加载统计概率,司机上非常的简单。
emit = new HashMap<Character, Map<Character, Double>>();
Map<Character, Double> values = null;
while (br.ready()) {
String line = br.readLine();
String[] tokens = line.split("\t");
if (tokens.length == 1) {
values = new HashMap<Character, Double>();
emit.put(tokens[0].charAt(0), values);
}
else {
values.put(tokens[0].charAt(0), Double.valueOf(tokens[1]));
}
}
我们直接看一下对应的文本就可以知道为什么这么加载:
节选一部分:
M
耀 -8.47651676173
蘄 -14.3722960587
这里的 M 代表中间,下面是相关字对应的概率。
最后的加载结果其实是,比如根据 emit.get('M') 获取后面的 Map 信息。
map.key = 中文
map.value = 统计概率
分词方法入口
public void cut(String sentence, List<String> tokens) {
StringBuilder chinese = new StringBuilder();
StringBuilder other = new StringBuilder();
for (int i = 0; i < sentence.length(); ++i) {
char ch = sentence.charAt(i);
if (CharacterUtil.isChineseLetter(ch)) {
if (other.length() > 0) {
processOtherUnknownWords(other.toString(), tokens);
other = new StringBuilder();
}
chinese.append(ch);
}
else {
if (chinese.length() > 0) {
viterbi(chinese.toString(), tokens);
chinese = new StringBuilder();
}
other.append(ch);
}
}
if (chinese.length() > 0)
viterbi(chinese.toString(), tokens);
else {
processOtherUnknownWords(other.toString(), tokens);
}
}
这里就是针对句子中的符号,分为两大类:中文,非中文
非中文
private void processOtherUnknownWords(String other, List<String> tokens) {
Matcher mat = CharacterUtil.reSkip.matcher(other);
int offset = 0;
while (mat.find()) {
if (mat.start() > offset) {
tokens.add(other.substring(offset, mat.start()));
}
tokens.add(mat.group());
offset = mat.end();
}
if (offset < other.length())
tokens.add(other.substring(offset));
}
其中
public static Pattern reSkip = Pattern.compile("(\\d+\\.\\d+|[a-zA-Z0-9]+)");
这个正则表达式会将英文,数字,数字+英文,空格,其他符号等分成不同的组。
但是有一个小问题:
(1)it's time 这里的 's 会被拆分开。
核心维特比算法
直接看这一串代码可能会比较蒙圈,建议学习下 HMM viterbi 算法
public void viterbi(String sentence, List<String> tokens) {
Vector<Map<Character, Double>> v = new Vector<Map<Character, Double>>();
Map<Character, Node> path = new HashMap<Character, Node>();
v.add(new HashMap<Character, Double>());
for (char state : states) {
Double emP = emit.get(state).get(sentence.charAt(0));
if (null == emP)
emP = MIN_FLOAT;
v.get(0).put(state, start.get(state) + emP);
path.put(state, new Node(state, null));
}
for (int i = 1; i < sentence.length(); ++i) {
Map<Character, Double> vv = new HashMap<Character, Double>();
v.add(vv);
Map<Character, Node> newPath = new HashMap<Character, Node>();
for (char y : states) {
Double emp = emit.get(y).get(sentence.charAt(i));
if (emp == null)
emp = MIN_FLOAT;
Pair<Character> candidate = null;
for (char y0 : prevStatus.get(y)) {
Double tranp = trans.get(y0).get(y);
if (null == tranp)
tranp = MIN_FLOAT;
tranp += (emp + v.get(i - 1).get(y0));
if (null == candidate)
candidate = new Pair<Character>(y0, tranp);
else if (candidate.freq <= tranp) {
candidate.freq = tranp;
candidate.key = y0;
}
}
vv.put(y, candidate.freq);
newPath.put(y, new Node(y, path.get(candidate.key)));
}
path = newPath;
}
double probE = v.get(sentence.length() - 1).get('E');
double probS = v.get(sentence.length() - 1).get('S');
Vector<Character> posList = new Vector<Character>(sentence.length());
Node win;
if (probE < probS)
win = path.get('S');
else
win = path.get('E');
while (win != null) {
posList.add(win.value);
win = win.parent;
}
Collections.reverse(posList);
int begin = 0, next = 0;
for (int i = 0; i < sentence.length(); ++i) {
char pos = posList.get(i);
if (pos == 'B')
begin = i;
else if (pos == 'E') {
tokens.add(sentence.substring(begin, i + 1));
next = i + 1;
}
else if (pos == 'S') {
tokens.add(sentence.substring(i, i + 1));
next = i + 1;
}
}
if (next < sentence.length())
tokens.add(sentence.substring(next));
}
分词中文资源
backoff
bakeoff2005 可以下载相关资源。
我们可以找到如下一行:“The complete training, testing, and gold-standard data sets, as well as the scoring script, are available for research use”,在这一行下面提供了三个版本的icwb2-data。
下载解压后,通过README就可以很清楚的了解到它包含哪些中文分词资源,特别需要说明的是这些中文分词语料库分别由台湾中央研究院(Academia Sinica)、香港城市大学(City University of Hong Kong)、北京大学(Peking University)及微软亚洲研究院(Microsoft Research)提供,其中前二者是繁体中文,后二者是简体中文,以下按照README简要介绍icwb2-data:
资源说明
1) 介绍(Introduction):
本目录包含了训练集、测试集及测试集的(黄金)标准切分,同时也包括了一个用于评分的脚本和一个可以作为基线测试的简单中文分词器。
(This directory contains the training, test, and gold-standard data used in the 2nd International Chinese Word Segmentation Bakeoff. Also included is the script used to score the results submitted by the bakeoff participants and the simple segmenter used to generate the baseline and topline data.)
2) 文件列表(File List)
在gold目录里包含了测试集标准切分及从训练集中抽取的词表(Contains the gold standard segmentation of the test data along with the training data word lists.)
在scripts目录里包含了评分脚本和简单中文分词器(Contains the scoring script and simple segmenter.)
在testing目录里包含了未切分的测试数据(Contains the unsegmented test data.)
在training目录里包含了已经切分好的标准训练数据(Contains the segmented training data.)
在doc目录里包括了bakeoff的一些指南(Contains the instructions used in the bakeoff.)
3) 编码(Encoding Issues)
文件包括扩展名”.utf8”则其编码为UTF-8(Files with the extension “.utf8” are encoded in UTF-8 Unicode.)
文件包括扩展名”.txt”则其编码分别为(Files with the extension “.txt” are encoded as follows):
前缀为as_,代表的是台湾中央研究院提供,编码为Big Five (CP950);
前缀为hk_,代表的是香港城市大学提供,编码为Big Five/HKSCS;
前缀为msr_,代表的是微软亚洲研究院提供,编码为 EUC-CN (CP936);
前缀为pku_,代表的北京大学提供,编码为EUC-CN (CP936);
EUC-CN即是GB2312(EUC-CN is often called “GB” or “GB2312” encoding, though technically GB2312 is a character set, not a character encoding.)
4) 评分(Scoring)
评分脚本“score”是用来比较两个分词文件的,需要三个参数(The script ‘score’ is used to generate compare two segmentations. The script takes three arguments):
-
训练集词表(The training set word list)
-
“黄金”标准分词文件(The gold standard segmentation)
-
测试集的切分文件(The segmented test file)
以下利用其自带的中文分词工具进行说明。
在scripts目录里包含一个基于最大匹配法的中文分词器mwseg.pl,以北京大学提供的人民日报语料库为例,用法如下:
./mwseg.pl ../gold/pku_training_words.txt < ../testing/pku_test.txt > pku_test_seg.txt
其中第一个参数需提供一个词表文件pku_training_word.txt,输入为pku_test.txt,输出为pku_test_seg.txt。
利用score评分的命令如下:
./score ../gold/pku_training_words.txt ../gold/pku_test_gold.txt pku_test_seg.txt > score.txt
其中前三个参数已介绍,而score.txt则包含了详细的评分结果,不仅有总的评分结果,还包括每一句的对比结果。
这里只看最后的总评结果:
= SUMMARY:
=== TOTAL INSERTIONS: 9274
=== TOTAL DELETIONS: 1365
=== TOTAL SUBSTITUTIONS: 8377
=== TOTAL NCHANGE: 19016
=== TOTAL TRUE WORD COUNT: 104372
=== TOTAL TEST WORD COUNT: 112281
=== TOTAL TRUE WORDS RECALL: 0.907
=== TOTAL TEST WORDS PRECISION: 0.843
=== F MEASURE: 0.874
=== OOV Rate: 0.058
=== OOV Recall Rate: 0.069
=== IV Recall Rate: 0.958
### pku_test_seg.txt 9274 1365 8377 19016 104372 112281 0.907 0.843 0.874 0.058 0.069 0.958
说明这个中文分词器在北大提供的语料库上的测试结果是:召回率为90.7%,准确率为84.3%,F值为87.4%等。
SIGHAN Bakeoff公开资源的一个重要意义在于这里提供了一个完全公平的平台,任何人都可以拿自己研究的中文分词工具进行测评,并且可以和其公布的比赛结果对比,是驴子是马也就一目了然了。
拓展阅读
应用
参考资料
《统计学习方法》,李航
《机器学习》,Tom M.Mitchell
《统计学自然语言处理》
