# 一、实验预览
实验四要求我们实现基于 2pl 协议的事务, 先来说一下在 simpleDB 中是如何实现事务的:
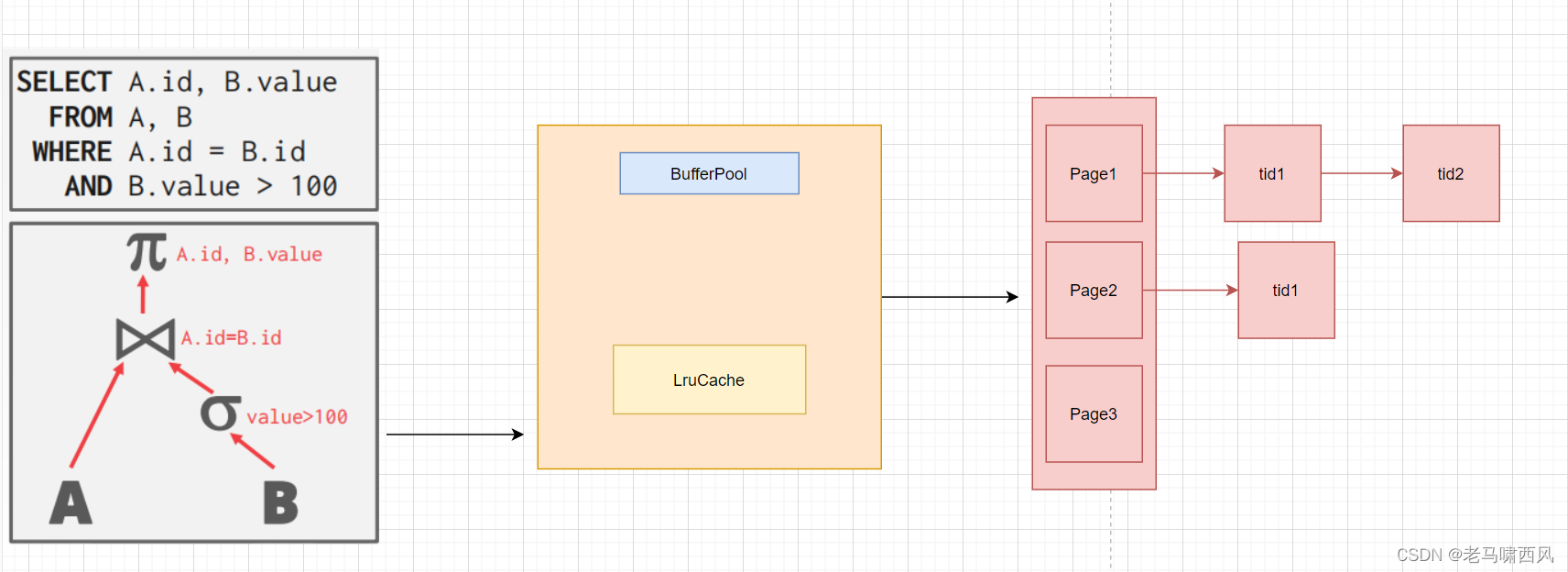
在SimpleDB中,每个事务都会有一个Transaction对象,我们用TransactionId来唯一标识一个事务,TransactionId在Transaction对象创建时自动获取。
事务开始前,会创建一个Transaction对象,trasactionId 会被传入到 sql 执行树的每一个 operator 算子中,加锁时根据加锁页面、锁的类型、加锁的事务id去进行加锁。
比如, 底层的 A, B seqScan 算子, 就会给对应的 page 加读锁.
我们知道, page 是通过 bufferPool.getPage() 来统一获取的, 因此, 加锁的逻辑就在 bufferPool.getPage() 中
具体的方法就是实现一个 lockManager, lockManager 包含每个 page 和其持有其锁的事务的队列
当事务完成时,调用 transactionComplete 去完成最后的处理。
transactionComplete 会根据成功还是失败去分别处理,如果成功,会将事务id对应的脏页写到磁盘中,如果失败,会将事务id对应的脏页淘汰出 bufferpool 并从磁盘中获取原来的数据页。
脏页处理完成后,会释放事务id在所有数据页中加的锁。
lab4要做的是让SimpleDB支持事务,所以实验前需要对事务的基本概念有了解,并知道ACID的特点。
lab4是基于严格两阶段封锁协议去实现原子性和隔离性的,所以开始前也需要了解两阶段封锁协议是如何实现事务的。
对于一致性和持久性,这里假设暂时不会发送断电等异常,所以暂时不需要崩溃恢复,不需要undo log从,后面lab6会有专门的崩溃恢复的解决方案。
事务的基本概念
事务是一组原子执行的数据库操作(例如,插入、删除和读取);
也就是说,要么所有动作都完成,要么都不完成,对于数据库的外部观察者来说,这些动作不是作为单个不可分割动作的一部分完成的并不明显。
ACID 特性:
为了帮助您了解事务管理在 SimpleDB 中的工作原理,我们简要回顾了它如何确保满足 ACID 属性:
-
原子性:严格的两阶段锁定和仔细的缓冲区管理确保原子性。
-
一致性:数据库凭借原子性是事务一致的。 SimpleDB 中没有解决其他一致性问题(例如,关键约束)。
-
隔离:严格的两相锁定提供隔离。
-
持久性:FORCE 缓冲管理策略确保持久性(见下文第 2.3 节)
这里提到了ACID在SimpleDB中如何去实现。
ACID实现的前提是严格两阶段封锁协议(Strict two-phase locking)。
所以我们需要先了解两阶段封锁协议。
两阶段封锁协议
首先是封锁协议:我们将要求在系统中的每一个事务遵从封锁协议,封锁协议的一组规则规定事务何时可以对数据项们进行加锁、解锁。
对于两阶段封锁协议:两阶段封锁协议要求每个事务分两个节点提出加锁和解锁申请:
-
增长阶段:事务可以获得锁,但不能释放锁;
-
缩减阶段:事务可以释放锁,但不能获得新锁。
也即,在事务执行过程中, 其可以不断的获得锁, 但是获得锁之后不能随意释放, 必须等 commit 或者 rollback 的时候, 才能释放锁。
严格两阶段封锁协议不仅要求封锁是两阶段,还要求事务持有的所有排他锁必须在事务提交后方可释放。
这个要求保证未提交事务所写的任何数据在该事务提交之前均已排他方式加锁,防止了其他事务读这些数据。
强两阶段封锁协议。它要求事务提交之前不释放任何锁。
在该条件下,事务可以按其提交的顺序串行化。
锁转换:在两阶段封锁协议中,我们允许进行锁转换。
我们用升级表示从共享到排他的转换,用降级表示从排他到共享的转换。
锁升级只能发送在增长阶段,锁降级只能发生在缩减阶段。
Recovery and Buffer Management
此外, 为了简化工作, 我们更推荐实现一个 NO STEAL/FORCE 的 buffer management policy.
也即:
-
在事务提交前不需要将脏页写回磁盘
-
事务提交时将脏页写回磁盘
为了进一步简化您的生活,您可以假设 SimpleDB 在处理 transactionComplete 命令时不会崩溃。
请注意,这三点意味着您不需要在本实验中实施基于日志的恢复,因为您永远不需要撤消任何工作(您永远不会驱逐脏页)并且您永远不需要重做任何工作(您强制更新 在提交时不会在提交处理期间崩溃)。
因为是在事务提交后才将脏页写入磁盘的,所以不需要实现 redo log;
因为我们保证在提交事务的时候不会发送故障,所以不需要实现 undo log;
Granting Locks
-
一个事务读一个对象,必须持有共享锁;
-
一个事务写一个对象,必须持有排它锁;
-
多个事务可以对同一个对象加共享锁;
-
一个对象只能被一个事务加排它锁;
-
如果只有一个事务在一个对象上加共享锁,那么共享锁可能升级为排它锁
当一个事务申请锁不能立刻获得,此时应该阻塞。
ps: 确切地说,很适合使用读写锁。
二、Guideline
Exercise1 Granting Locks
在 BufferPool 中编写获取和释放锁的方法。
假设您正在使用页面级锁定,您将需要完成以下操作:
-
修改
getPage()以在返回页面之前阻止并获取所需的锁。 -
实现
unsafeReleasePage()。 此方法主要用于测试和交易结束时。 -
实现
holdsLock()以便练习 2 中的逻辑可以确定页面是否已被事务锁定。
您可能会发现定义一个负责维护有关事务和锁的状态的 LockManager 类很有帮助,但设计决定取决于您。
在您的代码通过 LockingTest 中的单元测试之前,您可能需要实施下一个练习。
因为在 simpleDB 中, 所有 page 都是通过 bufferPool 来获取的, 因此, exercise1需要做的是在getPage获取数据页前进行加锁,这里我们使用一个LockManager来实现对锁的管理,LockManager中主要有申请锁、释放锁、查看指定数据页的指定事务是否有锁这三个功能,其中加锁的逻辑比较麻烦,需要基于严格两阶段封锁协议去实现。
事务 tx 对指定的页面加锁时,思路如下:
-
锁管理器中没有任何锁或者该页面没有被任何事务加锁,可以直接加读/写锁;
-
查看这个持有这个 page 的 lock 的事务中, 是否有和当前事务相同的, 有的话, 检查是否是锁升级
-
检查是否存在独占锁
-
允许加读锁 (因为page 存在其他的 lock, 只能加读锁)
相关定义
- lock 定义:
public class Lock {
private TransactionId tid;
private int lockType;
public Lock(final TransactionId tid, final int lockType) {
this.tid = tid;
this.lockType = lockType;
}
}
- lockManager
public class LockManager {
private final Map<PageId, List<Lock>> lockMap;
public LockManager() {
this.lockMap = new ConcurrentHashMap<>();
}
// 获取锁, lockType == 0代表读锁, 1代表写锁
public synchronized boolean acquireLock(final PageId pageId, final TransactionId tid, final int lockType) {
// 1.If page is unlock, just return true
if (!this.lockMap.containsKey(pageId)) {
final Lock lock = new Lock(tid, lockType);
final List<Lock> locks = new ArrayList<>();
locks.add(lock);
this.lockMap.put(pageId, locks);
return true;
}
final List<Lock> locks = this.lockMap.get(pageId);
// 2.Check whether this txn holds a lock
for (final Lock lock : locks) {
if (lock.getTid().equals(tid)) {
if (lock.getLockType() == lockType) {
return true;
}
if (lock.getLockType() == 1) {
return true;
}
if (lock.getLockType() == 0 && locks.size() == 1) {
lock.setLockType(1);
return true;
}
return false;
}
}
// 3.Check whether exists a writeLock
if (locks.size() > 0 && locks.get(0).getLockType() == 1) {
return false;
}
// 4.There already exists another locks, so we just can get a readLock
if (lockType == 0) {
final Lock lock = new Lock(tid, lockType);
locks.add(lock);
return true;
}
return false;
}
// 释放锁
public synchronized boolean releaseLock(final PageId pageId, final TransactionId tid) {
if (!this.lockMap.containsKey(pageId)) {
return false;
}
final List<Lock> locks = this.lockMap.get(pageId);
for (int i = 0; i < locks.size(); i++) {
final Lock lock = locks.get(i);
if (lock.getTid().equals(tid)) {
locks.remove(lock);
this.lockMap.put(pageId, locks);
if (locks.size() == 0) {
this.lockMap.remove(pageId);
}
return true;
}
}
return false;
}
//判断是否持有锁
public synchronized boolean holdsLock(final PageId pageId, final TransactionId tid) {
if (!this.lockMap.containsKey(pageId)) {
return false;
}
final List<Lock> locks = this.lockMap.get(pageId);
for (int i = 0; i < locks.size(); i++) {
final Lock lock = locks.get(i);
if (lock.getTid().equals(tid)) {
return true;
}
}
return false;
}
}
其中锁管理器的代码是lab4整个实验的核心,后续的 exercise 基本都是基于这个锁管理器去做的,所以这里必须要考虑清楚各种情况,把思路整理清楚再写代码。
有了锁管理器后, getPage() 只要实现加锁功能即可
final int lockType = perm == Permissions.READ_ONLY ? 0 : 1;
while (!this.lockManager.acquireLock()) {
.....
}
Exercise2 Lock Lifetime
exercise2 主要是要让我们考虑什么时候要加锁,什么时候要解锁,其实和exercise1是连成一块的。
> Ensure that you acquire and release locks throughout SimpleDB. Some (but
> not necessarily all) actions that you should verify work properly:
>
> - Reading tuples off of pages during a SeqScan (if you
> implemented locking in `BufferPool.getPage()`, this should work
> correctly as long as your `HeapFile.iterator()` uses
> `BufferPool.getPage()`.)
> - Inserting and deleting tuples through BufferPool and HeapFile
> methods (if you
> implemented locking in `BufferPool.getPage()`, this should work
> correctly as long as `HeapFile.insertTuple()` and
> `HeapFile.deleteTuple()` use
> `BufferPool.getPage()`.)
>
> You will also want to think especially hard about acquiring and releasing
> locks in the following situations:
>
> - Adding a new page to a `HeapFile`. When do you physically
> write the page to disk? Are there race conditions with other transactions
> (on other threads) that might need special attention at the HeapFile level,
> regardless of page-level locking?
> - Looking for an empty slot into which you can insert tuples.
> Most implementations scan pages looking for an empty
> slot, and will need a READ_ONLY lock to do this. Surprisingly, however,
> if a transaction *t* finds no free slot on a page *p*, *t* may immediately release the lock on *p*.
> Although this apparently contradicts the rules of two-phase locking, it is ok because
> *t* did not use any data from the page, such that a concurrent transaction *t’* which updated
> *p* cannot possibly effect the answer or outcome of *t*.
主要是让我们检查一下前面申请锁的时候,使用getPage方法获取数据页时申请锁,传入的锁类型是否正确。
insertTuple 应该是读写模式:
final HeapPage page = (HeapPage) Database.getBufferPool().getPage(tid, new HeapPageId(getId(), i), Permissions.READ_WRITE);
deleteTuple 也应该是读写模式
Exercise3 Implementing NO STEAL
> Modifications from a transaction are written to disk only after it
> commits. This means we can abort a transaction by discarding the dirty
> pages and rereading them from disk. Thus, we must not evict dirty
> pages. This policy is called NO STEAL.
> You will need to modify the `evictPage` method in `BufferPool`.
> In particular, it must never evict a dirty page. If your eviction policy prefers a dirty page
> for eviction, you will have to find a way to evict an alternative
> page. In the case where all pages in the buffer pool are dirty, you
> should throw a `DbException`. If your eviction policy evicts a clean page, be
> mindful of any locks transactions may already hold to the evicted page and handle them
> appropriately in your implementation.
前面我们提到,为了支持原子性,我们对脏页的处理是在事务提交时才写入磁盘,或者事务中断时将脏页恢复成磁盘文件原来的样子。
在之前我们实现的LRU缓存淘汰策略中,我们并没有对脏页加以区分。
exercise4 要我们在淘汰数据页时不能淘汰脏页,如果bufferpool全部是脏页则抛出异常,我们只需要修改淘汰页面时的代码:
首先, 在 load page from disk 的时候, 如果缓存页数超过了 Lrucache, 因该调用 evictPage() 函数:
evict 的逻辑是:
-
从 lru 中获取逆序的 iterator
-
遍历一遍, 看看哪一个的 dirty == null, 并将其淘汰
-
这样就可以保证, dirty 的页面不会被驱逐出缓存
private Page loadPageAndCache(final PageId pid) throws DbException {
final DbFile dbFile = Database.getCatalog().getDatabaseFile(pid.getTableId());
final Page dbPage = dbFile.readPage(pid);
if (dbPage != null) {
this.lruCache.put(pid, dbPage);
if (this.lruCache.getSize() == this.lruCache.getMaxSize()) {
evictPage();
}
}
return dbPage;
}
final Iterator<Page> pageIterator = this.lruCache.reverseIterator();
while (pageIterator.hasNext()) {
final Page page = pageIterator.next();
if (page.isDirty() == null) {
discardPage(page.getId());
return;
}
}
throw new DbException("All pages are dirty in buffer pool");
Exercise4 Transactions
> In SimpleDB, a `TransactionId` object is created at the
> beginning of each query. This object is passed to each of the operators
> involved in the query. When the query is complete, the
> `BufferPool` method `transactionComplete` is called.
>
> Calling this method either *commits* or *aborts* the
> transaction, specified by the parameter flag `commit`. At any point
> during its execution, an operator may throw a
> `TransactionAbortedException` exception, which indicates an
> internal error or deadlock has occurred. The test cases we have provided
> you with create the appropriate `TransactionId` objects, pass
> them to your operators in the appropriate way, and invoke
> `transactionComplete` when a query is finished. We have also
> implemented `TransactionId`.
实现流程
SimpleDB是如何实现事务的?
在SimpleDB中,每个事务都会有一个Transaction对象,我们用TransactionId来唯一标识一个事务,TransactionId在Transaction对象创建时自动获取。
事务开始前,会创建一个Transaction对象,后续的操作会通过传递TransactionId对象去进行,加锁时根据加锁页面、锁的类型、加锁的事务id去进行加锁。
当事务完成时,调用transactionComplete去完成最后的处理。
transactionComplete 会根据成功还是失败去分别处理,如果成功,会将事务id对应的脏页写到磁盘中,如果失败,会将事务id对应的脏页淘汰出bufferpool并从磁盘中获取原来的数据页。
脏页处理完成后,会释放事务id在所有数据页中加的锁。
实现
transactionComplete 实现如下:
public void transactionComplete(TransactionId tid, boolean commit) {
// some code goes here
// not necessary for lab1|lab2
try {
if (commit) {
// 如果提交, 则把所有页刷盘
flushPages(tid);
} else {
// 如果失败, 则重新加载所有页
reLoadPages(tid);
}
// 最后, 释放持有的锁
this.lockManager.releaseLockByTxn(tid);
} catch (Exception e) {
e.printStackTrace();
}
}
Exercise5 Deadlocks and Aborts
> It is possible for transactions in SimpleDB to deadlock (if you do not
> understand why, we recommend reading about deadlocks in Ramakrishnan & Gehrke).
> You will need to detect this situation and throw a
> `TransactionAbortedException`.
>
> There are many possible ways to detect deadlock. A strawman example would be to
> implement a simple timeout policy that aborts a transaction if it has not
> completed after a given period of time. For a real solution, you may implement
> cycle-detection in a dependency graph data structure as shown in lecture. In this
> scheme, you would check for cycles in a dependency graph periodically or whenever
> you attempt to grant a new lock, and abort something if a cycle exists. After you have detected
> that a deadlock exists, you must decide how to improve the situation. Assume you
> have detected a deadlock while transaction *t* is waiting for a lock. If you’re
> feeling homicidal, you might abort **all** transactions that *t* is
> waiting for; this may result in a large amount of work being undone, but
> you can guarantee that *t* will make progress.
> Alternately, you may decide to abort *t* to give other
> transactions a chance to make progress. This means that the end-user will have
> to retry transaction *t*.
>
> Another approach is to use global orderings of transactions to avoid building the
> wait-for graph. This is sometimes preferred for performance reasons, but transactions
> that could have succeeded can be aborted by mistake under this scheme. Examples include
> the WAIT-DIE and WOUND-WAIT schemes.
什么时候会发生死锁?
-
如果两个事务t0,t1,两个数据页p0,p1,t0有了p1的写锁然后申请p0的写锁,t1有了p0的写锁然后申请p1的写锁,这个时候会发生死锁;
-
如果多个事务t0,t1,t2,t3同时对数据页p0都加了读锁,然后每个事务都要申请写锁,这种情况下只能每一个事务都不可能进行锁升级,所以需要有其中三个事务进行中断或者提前释放读锁,由于我们实现的是严格两阶段封锁协议,这里只能中断事务让其中一个事务先执行完。
死锁的解决方案?
一般有两种解决方案:
-
超时。对每个事务设置一个获取锁的超时时间,如果在超时时间内获取不到锁,我们就认为可能发生了死锁,将该事务进行中断。
-
循环等待图检测。我们可以建立事务等待关系的等待图,当等待图出现了环时,说明有死锁发生,在加锁前就进行死锁检测,如果本次加锁请求会导致死锁,就终止该事务。
我实现的是较为简单的第一种方案:
public boolean tryAcquireLock(final PageId pageId, final TransactionId tid, final int lockType, final int timeout) {
final long now = System.currentTimeMillis();
while (true) {
if (System.currentTimeMillis() - now >= timeout) {
return false;
}
if (acquireLock(pageId, tid, lockType)) {
return true;
}
}
}
参考资料
https://github.com/CreatorsStack/CreatorDB/blob/master/document/lab4-resolve.md
