
LC450. 删除二叉搜索树中的节点 delete-node-in-a-bst
LC450. 删除二叉搜索树中的节点 delete-node-in-a-bst
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
一般来说,删除节点可分为两个步骤:
首先找到需要删除的节点;
如果找到了,删除它。
示例 1:
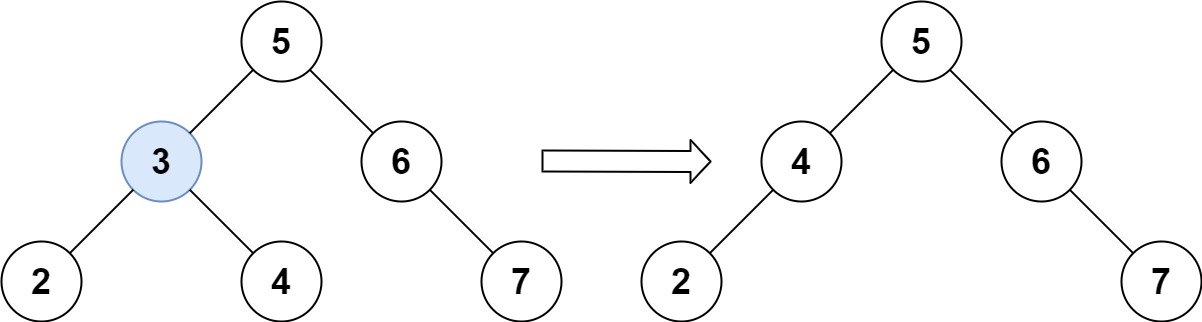
输入:root = [5,3,6,2,4,null,7], key = 3
输出:[5,4,6,2,null,null,7]
解释:给定需要删除的节点值是 3,所以我们首先找到 3 这个节点,然后删除它。
一个正确的答案是 [5,4,6,2,null,null,7], 如下图所示。
另一个正确答案是 [5,2,6,null,4,null,7]。
示例 2:
输入: root = [5,3,6,2,4,null,7], key = 0
输出: [5,3,6,2,4,null,7]
解释: 二叉树不包含值为 0 的节点
示例 3:
输入: root = [], key = 0
输出: []
提示:
节点数的范围 [0, 104].
-10^5 <= Node.val <= 10^5
节点值唯一
root 是合法的二叉搜索树
-10^5 <= key <= 10^5
进阶: 要求算法时间复杂度为 O(h),h 为树的高度。
v1-毁灭-创造
思路
我们前面解决了 LC700 和 LC701。
这一题拆分 2 步:
1)遍历获得所有的节点
2)转换为 LC701 如何构建一颗 BST 问题。
之所以这么做,是因为遍历+构建相对比较简单
实现
这里只演示一下递归版本,其他实现方式类似。
public TreeNode deleteNode(TreeNode root, int key) {
List<Integer> list = new ArrayList<>();
traveseTree(root, key, list);
if(list.size() == 0) {
return null;
}
// 循环构建
TreeNode newRoot = new TreeNode(list.get(0));
for(int i = 1; i < list.size(); i++) {
insertBST(newRoot, list.get(i));
}
return newRoot;
}
private TreeNode insertBST(TreeNode root, int key) {
if(root == null) {
return new TreeNode(key);
}
if(root.val < key) {
// 去右子树
root.right = insertBST(root.right, key);
} else {
root.left = insertBST(root.left, key);
}
return root;
}
// travese
private void traveseTree(TreeNode root, int key, List<Integer> list) {
if(root == null) {
return;
}
int val = root.val;
// 待删除节点不需要入list
if(val != key) {
list.add(val);
}
traveseTree(root.left, key, list);
traveseTree(root.right, key, list);
}效果
4ms 击败 0.23%
复杂度
时间复杂度:
平均情况:O(n log n)
最坏情况:O(n^2)
空间复杂度:
O(n)(存 list) + 递归栈 O(h),最坏 O(n)
反思
这个解法虽然解法,但是性能实在是很差。
如果用例加强一些,估计就挂了。
v2-原地删除
思路
这个是这一题的常规解法,但是相对复杂了很多。
删除一个节点,我们需要分具体的场景。
整体上递归和查找的模板是一致的,不过删除的细节确实多。
删除场景
在 BST 里删除一个节点时,分三种情况:
叶子节点:直接删掉,O(1)。
只有一个子节点:用它的唯一子节点替换它,O(1)。
有两个子节点(关键点):
这时不能直接删,否则会破坏 BST 的有序性。
正确做法:
- 找 右子树的最小值(后继 successor) 或 左子树的最大值(前驱 predecessor)。
- 用这个值替换当前节点,再去删除那个 successor / predecessor 节点。
后继+前驱
- 右子树的最小值(后继 successor)
最小值,一直找右节点。
private TreeNode findMin(TreeNode node) {
while (node.left != null) {
node = node.left; // 一直往左走
}
return node;
}- 左子树的最大值(前驱 predecessor)
最大值,一直找右节点。
private TreeNode findMax(TreeNode node) {
while (node.right != null) {
node = node.right; // 一直往右走
}
return node;
}为什么两个子节点这么复杂?
举个栗子,现在我们要删除 节点 5(根节点),它有 两个子节点(左子树根 3,右子树根 8)。
5
/ \
3 8
/ \ / \
2 4 6 9直接删除 5,用 3 或者 8 替代,都会不符合 BST 约束。
方案 A:找后继(successor)
1)找后继:右子树中最小的节点(在中序遍历里,紧跟当前节点之后的那个数)。
在我们的例子里:
5 的右子树是,右子树里最小值是 6。
8
/ \
6 92)操作:
用 6 替换 5 的值。
然后去右子树里删除原本的 6 节点。
3)结果
满足 BST
6
/ \
3 8
/ \ \
2 4 9方案 B:找前驱(predecessor)
1)找前驱:左子树中最大的节点(在中序遍历里,紧跟当前节点之前的那个数)。
在我们的例子里:
5 的左子树是,左子树里最大值是 4。
3
/ \
2 42)操作:
用 4 替换 5 的值。
然后去左子树里删除原本的 4 节点。
3)结果
满足 BST
4
/ \
3 8
/ / \
2 6 9核心目的:它们就是“刚刚好”能接替被删节点的位置的值。
实现
看懂了上面的过程,我们的实现也不算很难。
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
if(root == null) {
return null;
}
// 小->右
if(root.val < key) {
root.right = deleteNode(root.right, key);
} else if(root.val > key) {
// 大->左
root.left = deleteNode(root.left, key);
} else {
// 相等,拆分为3个CASE
// 1. 叶子,直接删除
if(root.left == null && root.right == null) {
return null;
}
//2. 一个叶子,返回另一个边子节点
if(root.left == null) {
return root.right;
}
if(root.right == null) {
return root.left;
}
//3. 两个子节点
// 找到左子树的最大值
TreeNode leftMaxNode = findMax(root.left);
root.val = leftMaxNode.val;
// 删掉左边的最大节点值
root.left = deleteNode(root.left, leftMaxNode.val);
}
return root;
}
private TreeNode findMax(TreeNode node) {
// 一直看右边
while(node.right != null) {
node = node.right;
}
return node;
}
}这里找左边最大值,和找右边最小值是类似的。
效果
0ms 100%
复杂度
| 情况 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 平均(树平衡) | O(log n) | O(log n) |
| 最坏(链表) | O(n) | O(n) |
v3-迭代版本
思路
迭代的话,我们需要维护一下 parent 父亲节点。
前面和 LC700 类似的,先找到目标节点。
找到后序操作和 v2 类似。
但是感觉迭代还是过于复杂了,虽然本质上差不多。
实现
public TreeNode deleteNode(TreeNode root, int key) {
// 哨兵节点,简化处理根节点删除
TreeNode dummy = new TreeNode(0);
dummy.left = root;
TreeNode parent = dummy;
TreeNode cur = root;
// 迭代,寻找目标节点
while(cur != null) {
if(cur.val == key) {
break;
}
parent = cur;
if(cur.val > key) {
cur = cur.left;
} else {
cur = cur.right;
}
}
// 没找到
if(cur == null) {
return root;
}
// 拆分为3个CASE
// 1. 叶子,直接删除
if(cur.left == null && cur.right == null) {
// 看待删除的节点是哪边?
if(parent.left == cur) {
parent.left = null;
} else {
parent.right = null;
}
} else if(cur.left == null || cur.right == null) {
//2. 一个叶子,返回另一个边子节点
TreeNode child = cur.left == null ? cur.right : cur.left;
if(parent.left == cur) {
parent.left = child;
} else {
parent.right = child;
}
} else {
//3. 两个子节点
// 双子节点:用左子树最大值替换
TreeNode predParent = cur;
TreeNode pred = cur.left;
while (pred.right != null) {
predParent = pred;
pred = pred.right;
}
cur.val = pred.val;
// 删掉左边的最大节点值
// 为什么只看 pred.left? 因为我们上面找的是左边的最大值,这个节点不可能有右子树。
if(predParent.left == pred) {
predParent.left = pred.left;
} else {
predParent.right = pred.left;
}
}
return dummy.left;
}效果
0ms 100%
复杂度
| 操作 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 查找目标节点 | O(h) | O(1) |
| 删除叶子/单子节点 | O(1) | O(1) |
| 删除双子节点(找前驱/后继) | O(h) | O(1) |
| 总复杂度 | O(h) | O(1) |
反思
迭代的复杂度,来源于我们需要自己维护一个 parent 父节点指针,不然不好做删除操作。
原理一样,但是实现的体感差别很大。